20210326-软件工程作业-3-编程作业
| 这个作业属于哪个课程 | 软工-2018级计算机1班 |
|---|---|
| 这个作业要求在哪里 | 202103226-1 编程作业 |
| 这个作业的目标 | 实践中学习软件工程 |
| 学号 | 20188385 |
Gitee仓库地址
解题思路描述
看完题目描述,第一时间就想到了HashMap,单词-数量;这不就一键值对嘛。一把嗦秒杀!这会不会太轻松了,于是自己开始整(zuo)活(si)就想着能不能不用HashMap解决,用纯字节流完成,性能会不会更好。用KMP搞了半天,结果大翻车,彻底暴露了我这个算法菜鸡的本质。最后还是老老实实的用HashMap了。
决定用HashMapd话思路就很清晰了,先把文本一个个字节进行一定的处理和判断后一个个单词放进HashMap里面,键为单词字符串,值为频次。全部放进去之后,问题来了,频次高者优先输出很好办,在频次相同时如何按照单词字典序输出呢?一番搜索后,学习到了TreeMap这个类,它的底层是红黑树,默认插入进去的Key为Sting类时,就会按照字典序排序。太好了!这下所有问题都解决了,啪的一下,做一些输出处理,完成了。
代码规范链接
计算模块接口的设计与实现过程
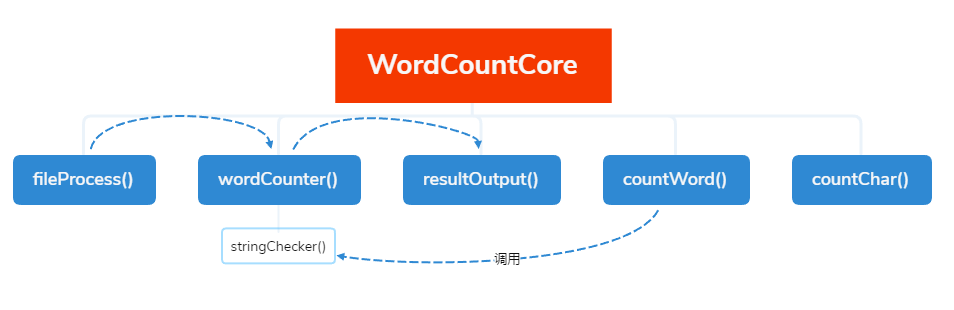
fileProcess()
该方法实现读取文件,判断是否为纯ASCII编码文件,并做了非字母数字过滤,最后返回的是纯数字字母的字符串数组。
1 public static String[] fileProcess(String filePath) throws IOException { 2 StringBuilder buffer = new StringBuilder(); 3 InputStream file = new FileInputStream(filePath); 4 int size = file.available(); 5 6 for (int i = 0; i<size;i++){ 7 char byt = (char)file.read(); 8 //Check illegal character 9 if (byt > 127){ 10 System.out.println("[-]Input pure ASCII file only!"); 11 System.exit(1); 12 } 13 //Convenient for split 14 if(byt == '\n'){ 15 byt = ' '; 16 } 17 //Filter exclude number and letter 18 else if(byt == '\r' || 19 byt>='!' && byt<='/' || 20 byt>=':' && byt<='@' || 21 byt>='[' && byt<='`' || 22 byt>='{' 23 ){ 24 continue; 25 } 26 buffer.append(byt); 27 } 28 29 String text = buffer.toString().toLowerCase(); 30 String[] division = text.split(" "); 31 return division; 32 }
wordCounter()
词频计数的核心方法,将字符串一个个填到TreeMap里,内置的红黑树将Key排好序,直接按Value从大到小拿出十个就好了,拿出来的Key-Value放在有序的LinkedHashMap内。
1 public static LinkedHashMap<String,Integer> wordCounter(String[] division){ 2 TreeMap<String,Integer> counter = new TreeMap<>(); 3 LinkedHashMap<String,Integer> result = new LinkedHashMap<>(); 4 5 for (String s : division) { 6 if(stringChecker(s)){ 7 continue; 8 } 9 if (counter.containsKey(s)) { 10 Integer count = counter.get(s); 11 counter.put(s, count + 1); 12 } else { 13 counter.put(s, 1); 14 } 15 } 16 17 for (int i = 0; i<10; i++){ 18 String maxWord = ""; 19 Integer maxNum = 0; 20 for (String word : counter.keySet()){ 21 Integer currentNum = counter.get(word); 22 if(currentNum > maxNum){ 23 maxNum = currentNum; 24 maxWord = word; 25 } 26 } 27 counter.remove(maxWord); 28 result.put(maxWord, maxNum); 29 } 30 return result; 31 }
resultOutput()
输出结果到文件,由于LinkedHashMap是有序的,只要遍历拿出数据写入文件就行了。
countWord()
此方法和wordCounter方法很类似,只要把符合要求的字符串计数返回就完成了。
countChar()
这个就更简单了,读取文件后,file类就有字节数属性,直接返回。
计算模块接口部分的性能测试和改进
测试文本为Game Of Thrones部分小说。约三百万字节
使用JProFiler进行性能测试
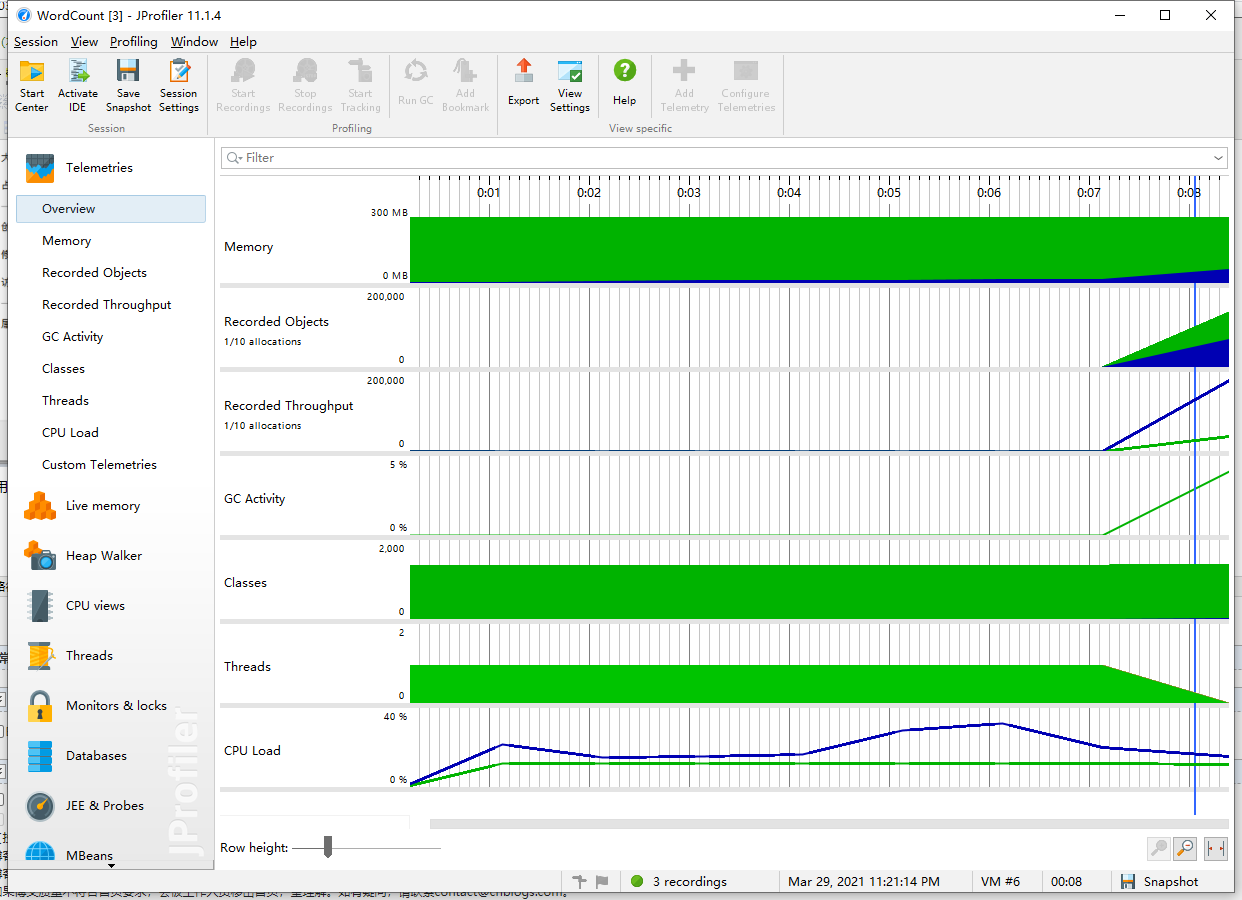
我的笔记本是四核CPU,程序运行时占用约25%的CPU,可以认为占满了一整个CPU内核,程序运行了约8秒后结束。
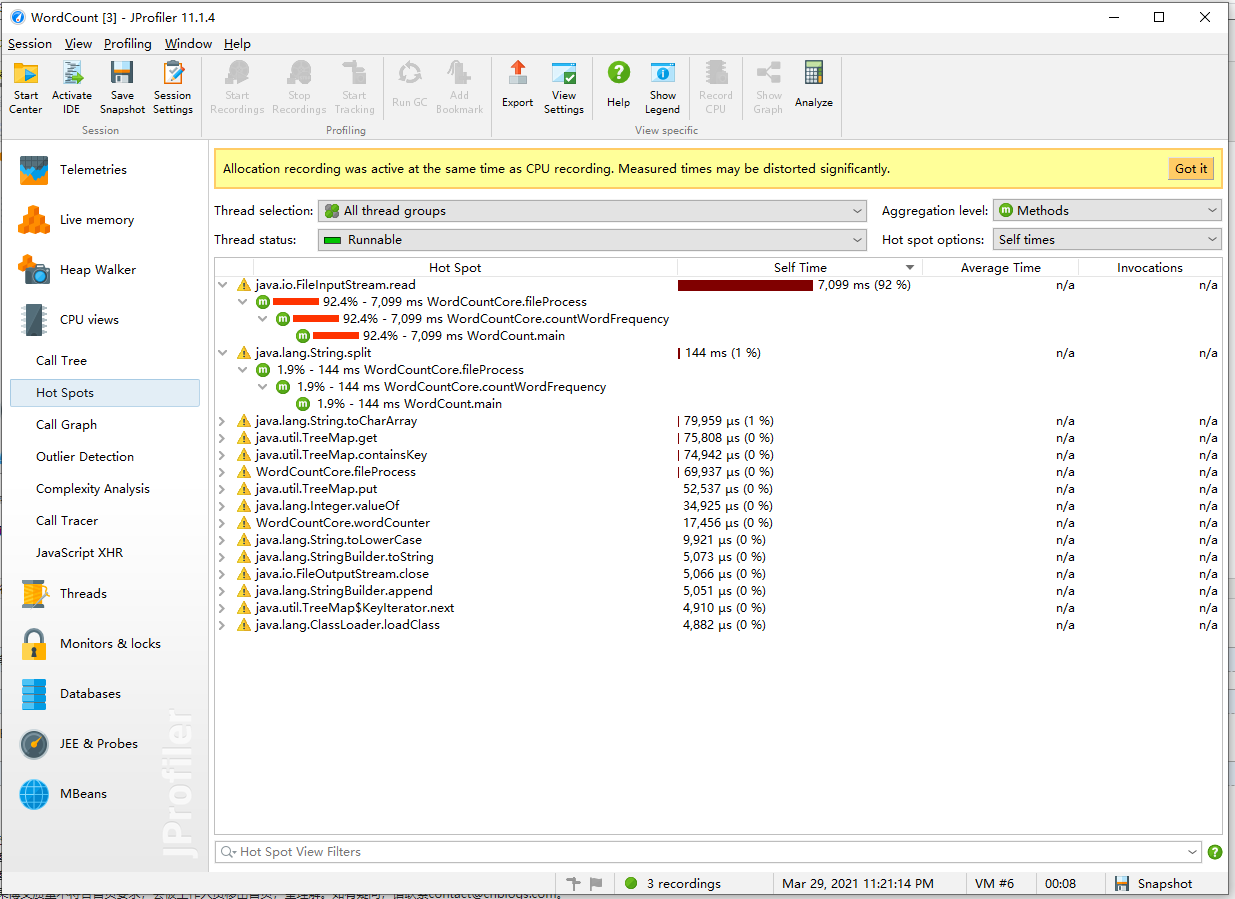
观察处理器占用后发现,fileProcess占用了超过90%的时间,猜测是fileProcess方法使用了太多if语句,因此CPU的乱序执行和分支预测效率都很低下,运行速度因此拖慢。
但我没有想到更好的办法来减少语句执行的数量,除非放弃输入检查,那么也放弃了单词统计的严格性。
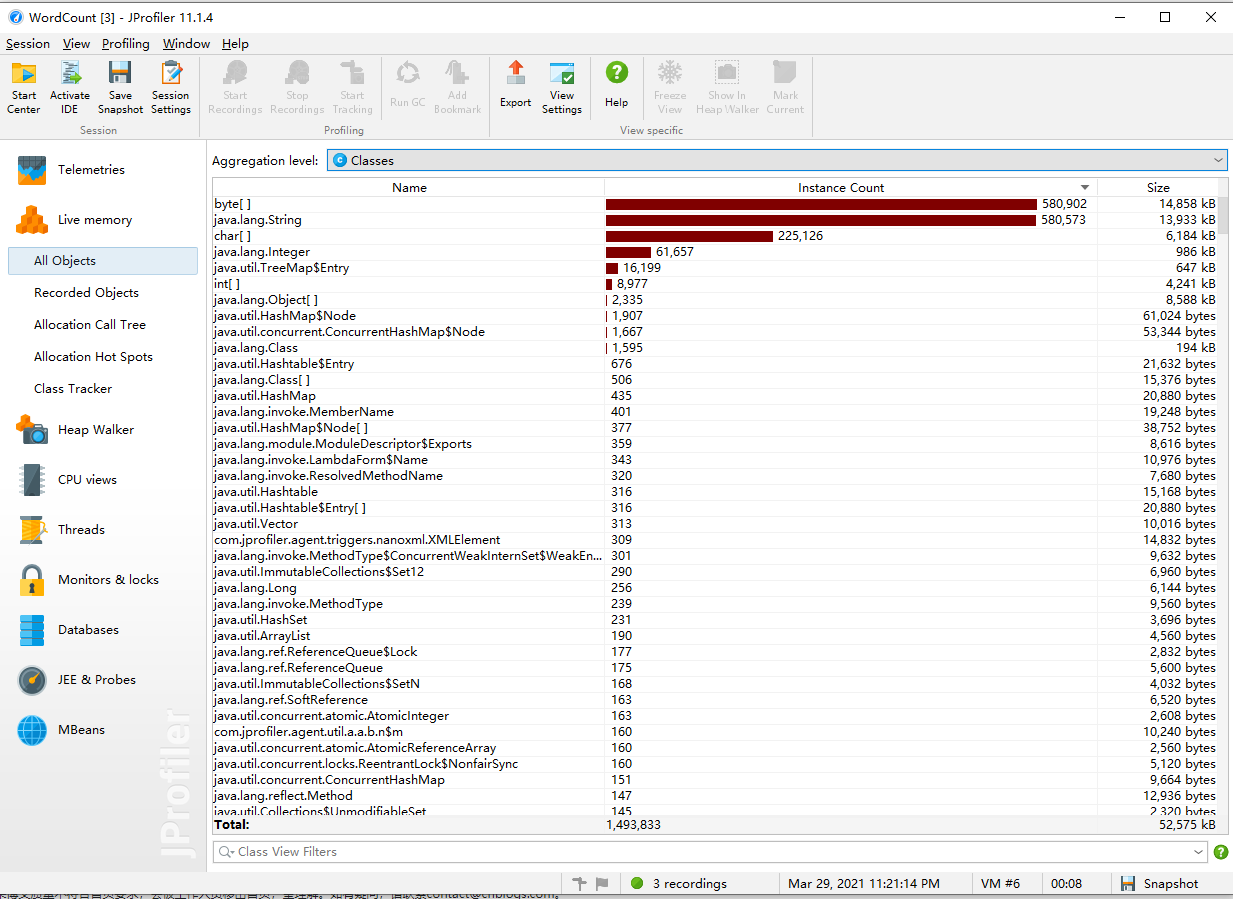
内存占用方面,String和byte大小类似是因为读取文件时采用了StringBuffer,这里是方便做后续处理,在输入完毕后的阶段JVM也对byte[]进行了GC操作,总内存占用不到输入文件的两倍,总体来说上内存占用还是比较理想的。
最大的优化的方向就是在输入的过程中,将byte[]直接处理转换为String[]但时间效率是否受影响就不得而知了。
计算模块部分单元测试展示

由于不知道如何实现脚本单元测试覆盖率,故按照要求标准手动测试。
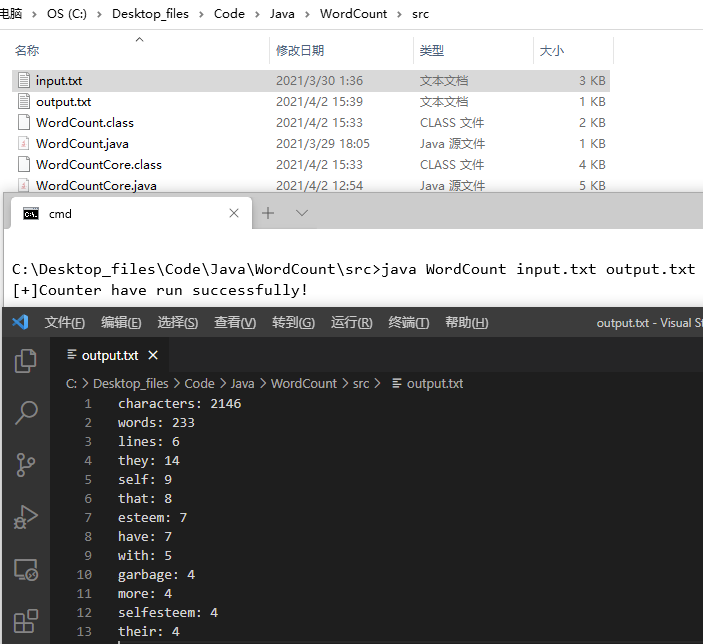
lord居然在权游小说词频前10,怪不得我看完电视剧版就学会了一句Yes,my lord!
附加测试,当单词频数相同时,按字典序输出。
计算模块部分异常处理说明
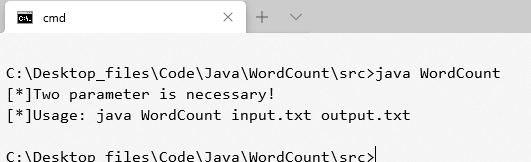
不输入参数运行,正常提示消息。
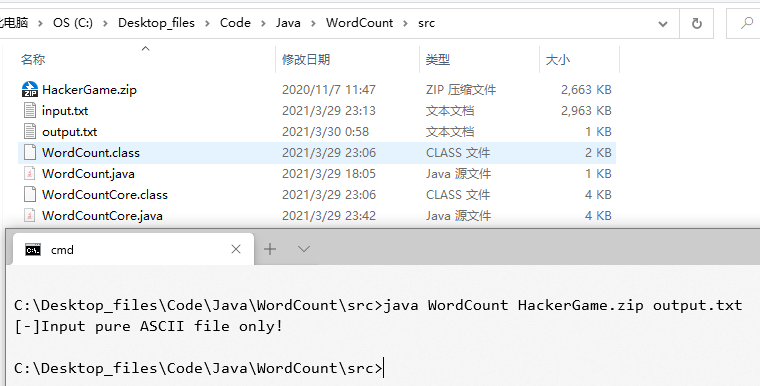
尝试导入一个压缩包,正常报错退出。
假装输错文件名,正常捕获异常。
PSP表格
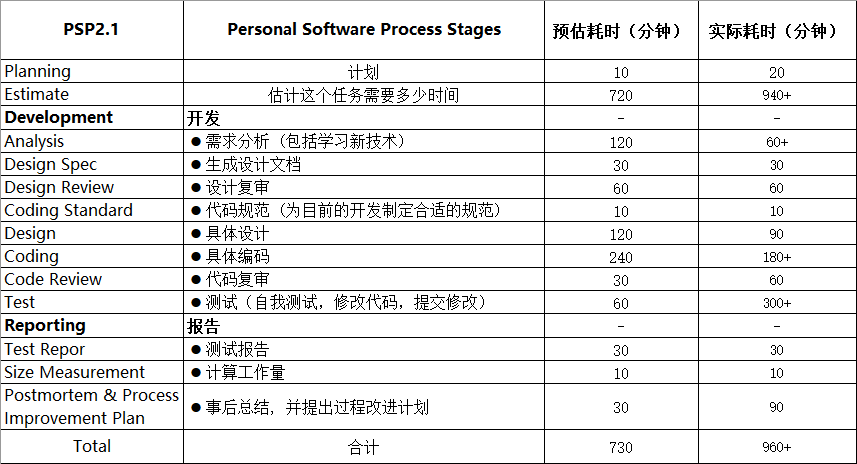
注:加号代表在实际操作时未准确计时,只是一个保守的估计。
心路历程与收获
这个作业最大的感受就是有点杀鸡用牛刀的感觉。我非常能理解PSP表格中各个项目对应软件开发的各个流程。但我认为PSP更适合做需要长期维护的项目,而不是像这次作业的算法练习题。例如算法题不需要非常详细的设计文档,往往三言两语就能将核心思想交代清楚、算法题不需要反复的review,因为算法题往往目标是更高效的计算某个东西而不是更好的代码可读性(当然这也是非常重要的,但许多算法高手写出来的代码通常可读性较差)和更好的可维护性等等。
在这次实践中也学习到了Java中Map家族类的一些属性和方法,并且发现使用Java内置包的方法真的速度很快,我最初会以为核心方法wordCounter耗时应该是最长的,结果测试出来后反而是我写的过滤判断慢,使用红黑树的TreeMap排序真的很快。这次的作业总体来说难度不算太大(比数独简单),但也充分地体现了在软件工程中实践的一些流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号