

[DeepLearning] 为什么需要随机梯度下降 Why SGD instead of GD
[DeepLearning] 为什么需要随机梯度下降 Why SGD instead of GD
Why (English Version)
Here is the update formulation of GD, and it's easy to see that the update would be used based on all the samples.
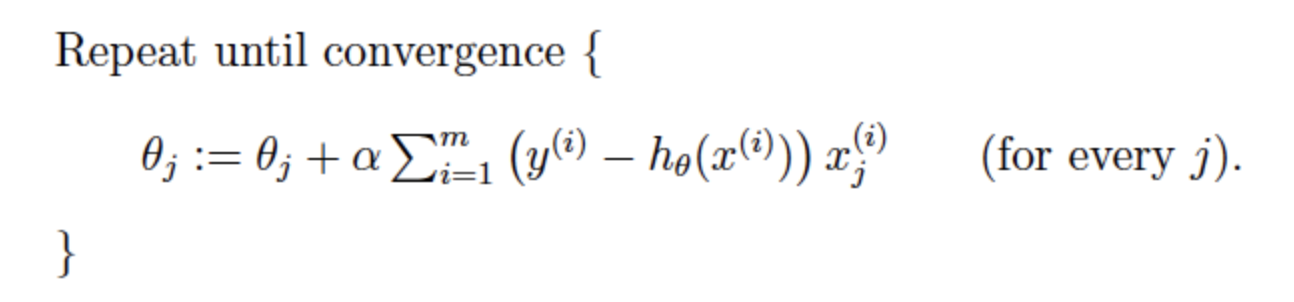
Here is the update formula of SGD. The main diiferences here are the sum. It means it only uses the 1 samples to update the \(\theta\). Therefore, it would be easier to calculate. (The Zhihu answer shows the for i=1 to m here and I think it's ok without it)
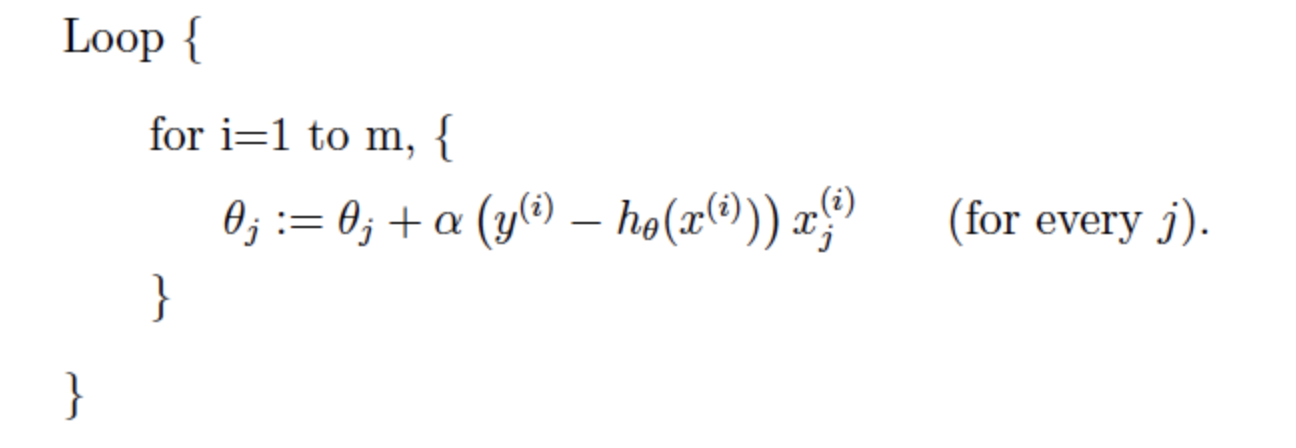
However, it would be harder for SGD to achieve convergence because the 'only one' sample. It would contain some noise.
What's more, there's a method in the middle which is called mini-batch. It means you can't choose one sample very accurately and you can't choose all the samples because of the size, so you can have a relatively small batch to have the two methods together. The update formula is like this:
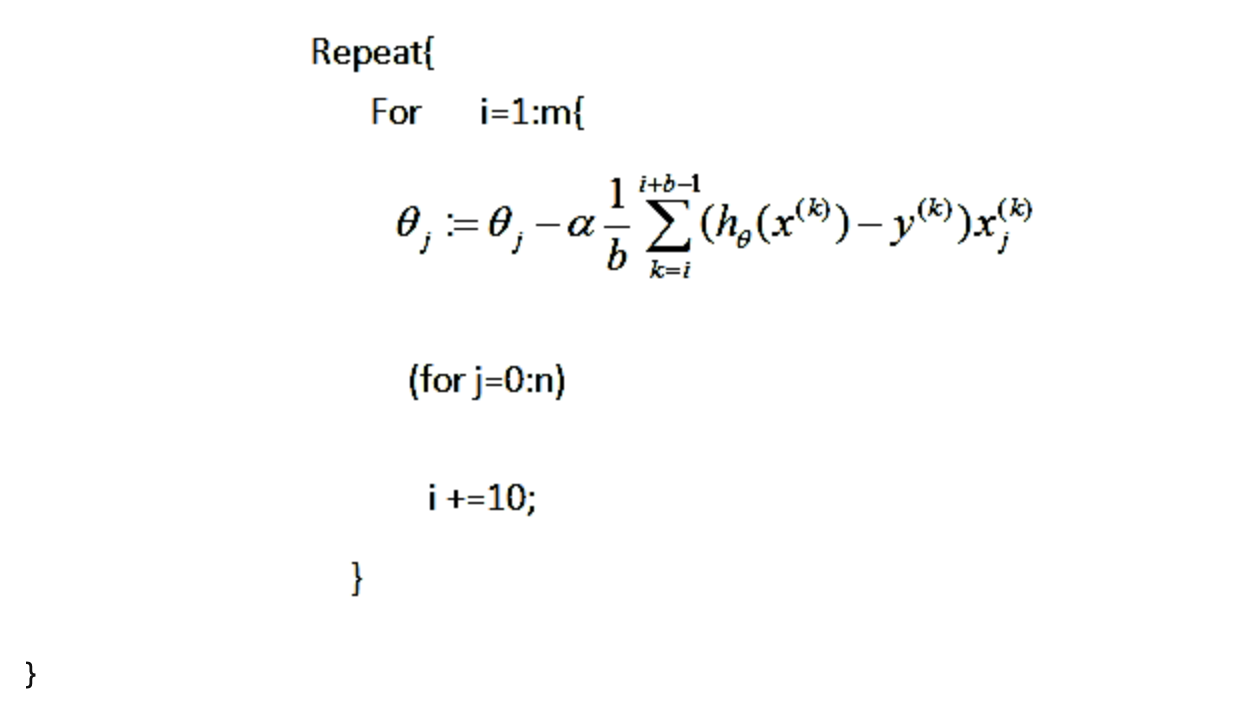
References
[1] zhihu The answer of @yzhihao(Evan)
[2] jianshu The answer of @JxKing
[3] csdn The answer of @code_caq
