C++ opencv 将图片从HWC转CHW数据格式
1. opencv的读取格式
众所周知,opencv读取图片后,在内存中数据是以HWC的顺序进行排列的,但是在深度学习模型中,一般需要将其转为CHW格式(准确来说是NCHW)再进行推断。
在python中,opencv读取后的数据类型是numpy的ndarray,这个时候只要调用numpy的transpose方法就可以解决了:
img_np_t = img_np.transpose(2, 0, 1)
然而,在C++中就没这么简单了,虽然在opencv 4.6之后出了一个函数transposeND,但是却有一个限制,即输入必须是单通道的矩阵,因此也无法直接调用。
2. 数据格式与内存
2.1. 数据格式
假设有一张图片img,有三个通道(m1,m2, m3),每个通道有2行2列,如下图所示:
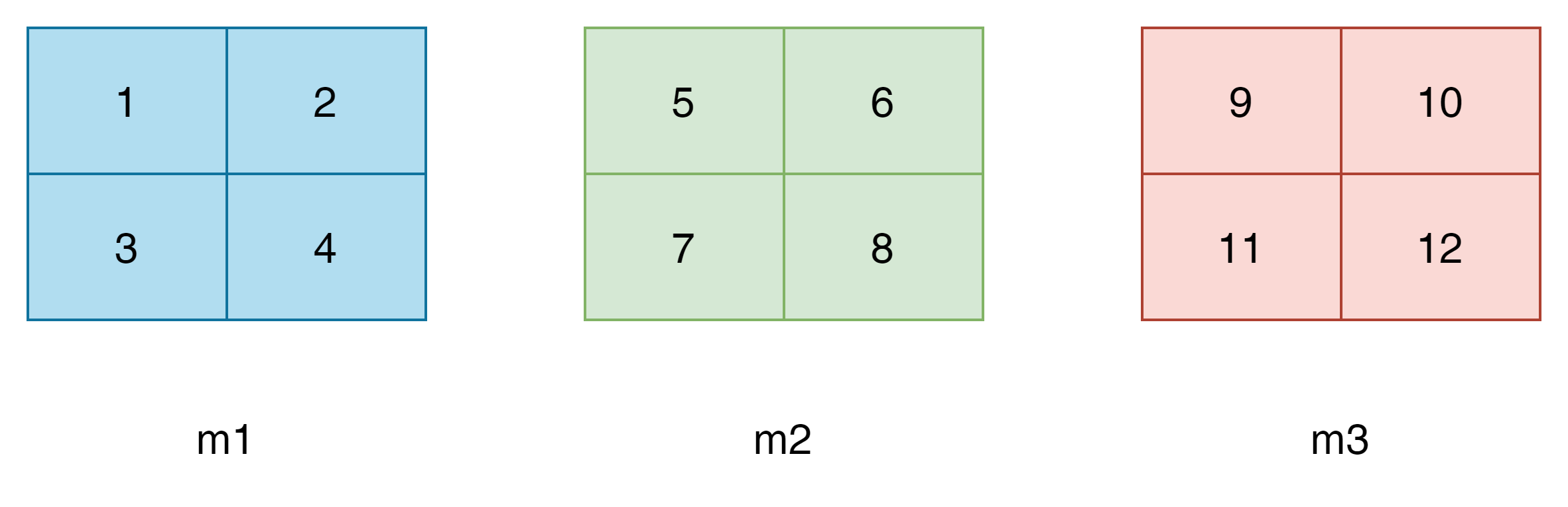
图1
如果这三个通道是以CHW格式(3*2*2)排列的,则排列后效果如下:
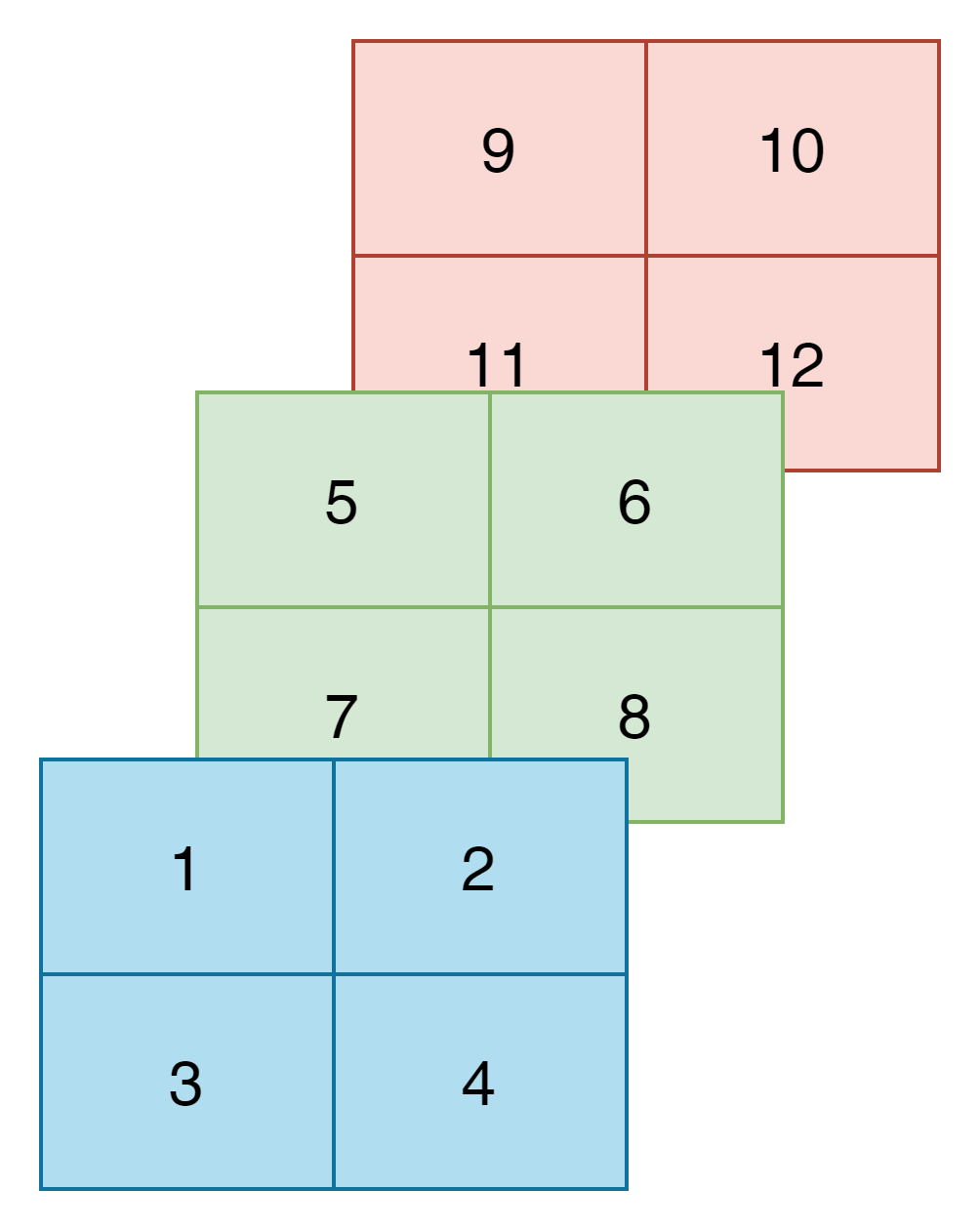
图2
如果这三个通道是以HWC(2*2*3)格式排列的,则排列后效果如下:
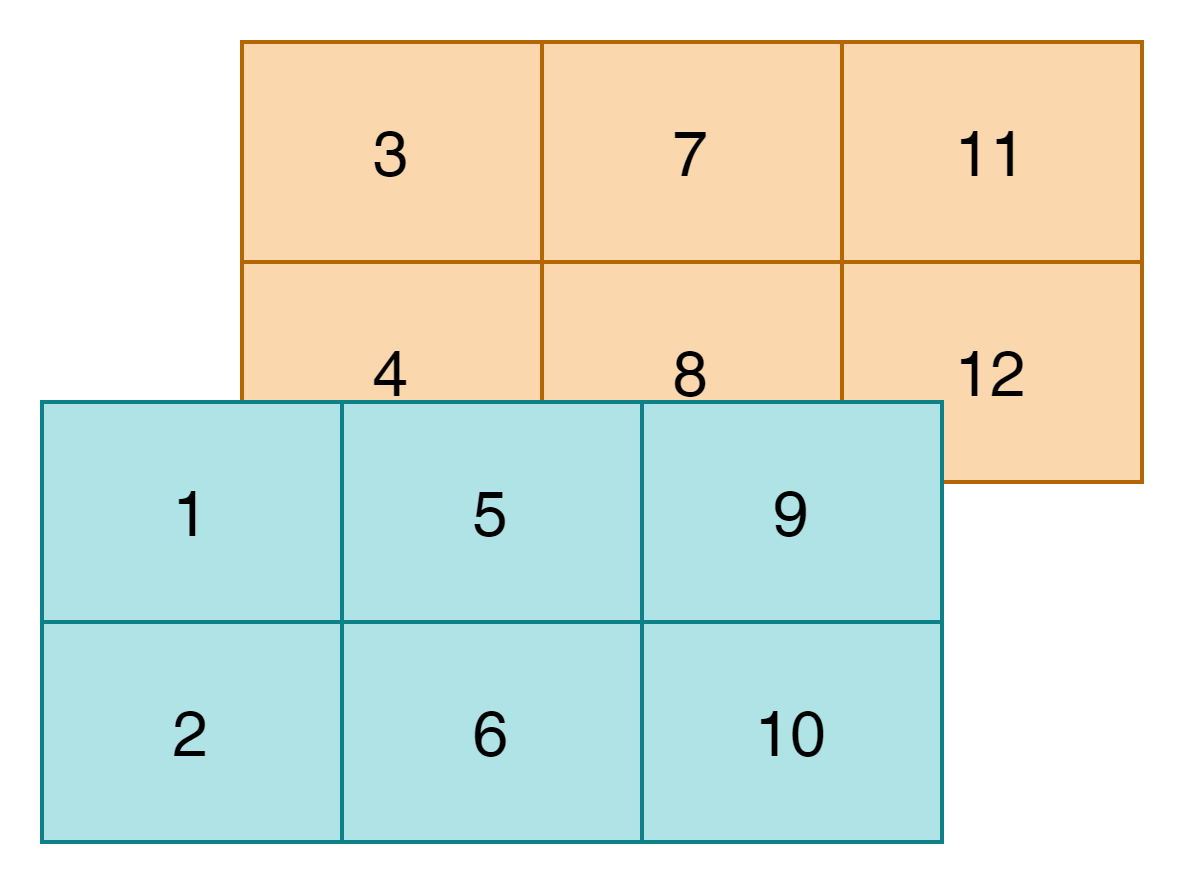
图3
可以看出区别还是挺大的,我们的目的就是实现下面的转换:
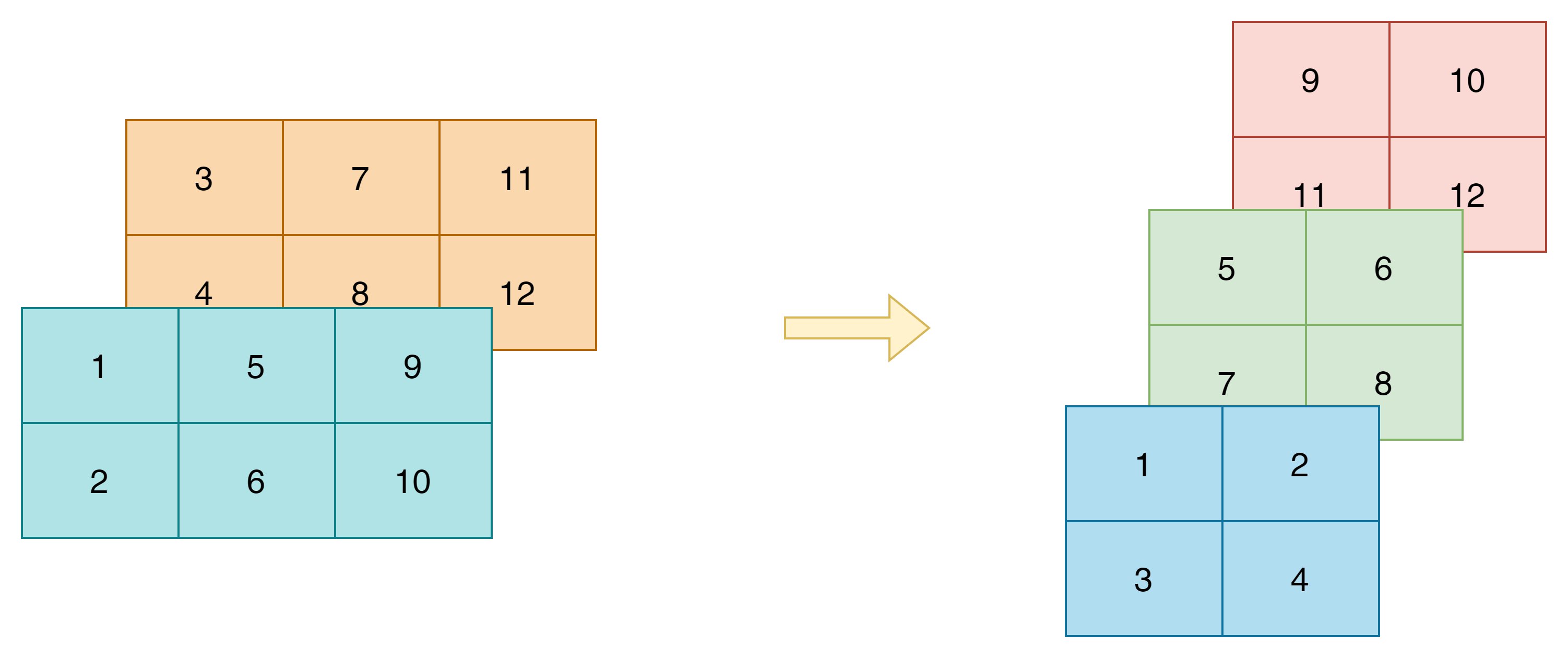
图4
2.2. 内存
以上面的m1为例,无论m1的形状为2*2还是1*4,只要行数*列数的结果一样,他们在内存中的排列顺序都是一样的,我们可以创建一个简易程序,然后看看在内存中的排列:
int main() { cv::Mat m1 = (cv::Mat_<uchar>(2, 2) << 1, 2, 3, 4); cv::Mat m1_2 = (cv::Mat_<uchar>(1, 4) << 1, 2, 3, 4); return 0; }
无论m1还是m1_2,查看它们在内存中存储的数据(data指针指向的地址),都是以01 02 03 04这种方式进行排列的,如下图所示:
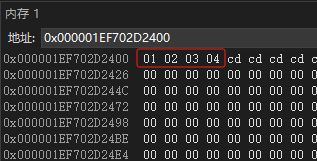
图5
因此我们可以看看img的不同排列在内存中的实际情况。
CHW:
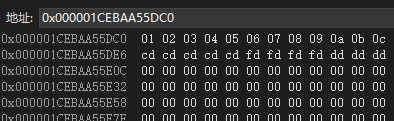
图6
HWC:
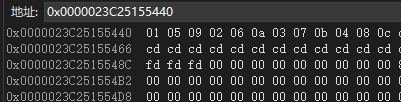
图7
因此,要从HWC转为CHW,本质上就是需要将HWC中的内存排列转为CHW中的内存排列。
3. 转换
总的来说,转换有两步:
- 分离图片通道;
- 按照通道顺序拼接数据。
在具体实现方面,分离图片通道数据这里使用split函数,拼接数据使用hconcat。
hconcat函数(文档)的主要作用,是将多个矩阵,沿着1轴的方向进行拼接,效果如下:
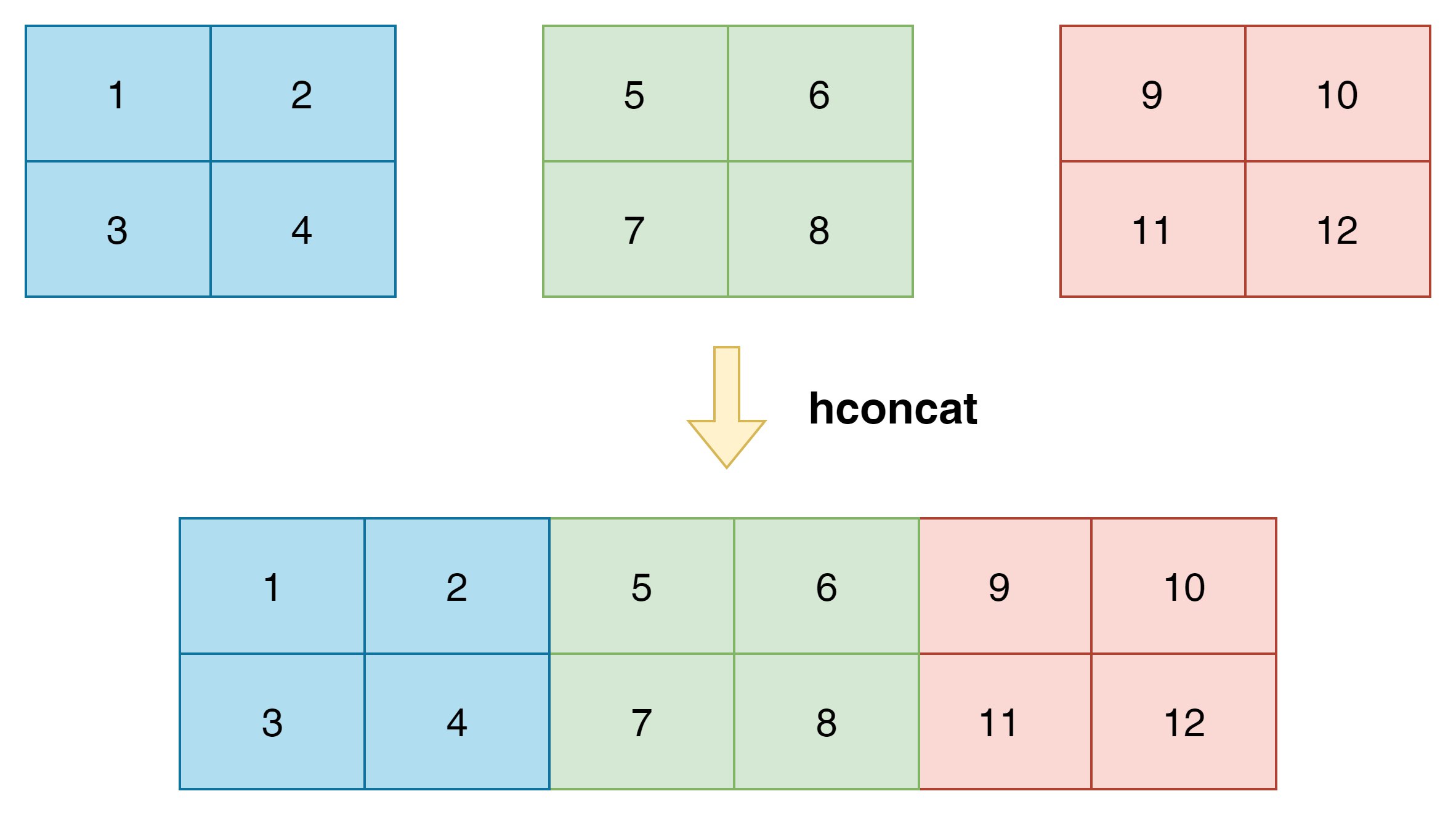
图8
在内存中的详情如下:
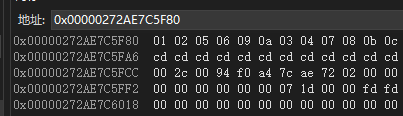
图9
明显不是我们想要的结果。
因此,在分离通道之后,我们还需要将通道数据展平(flatten),然后再使用hconcat进行拼接,实际的代码如下:
cv::Mat hwc2chw(const cv::Mat& src_mat) { std::vector<cv::Mat> bgr_channels(3); cv::split(src_mat, bgr_channels); for (size_t i = 0; i < bgr_channels.size(); i++) { bgr_channels[i] = bgr_channels[i].reshape(1, 1); // reshape为1通道,1行,n列 } cv::Mat dst_mat; cv::hconcat(bgr_channels, dst_mat); return dst_mat; }
其中,reshape(文档)将每个通道进行flatten操作,即从2*2展平为1*4,然后再沿1轴进行拼接,如下图所示:
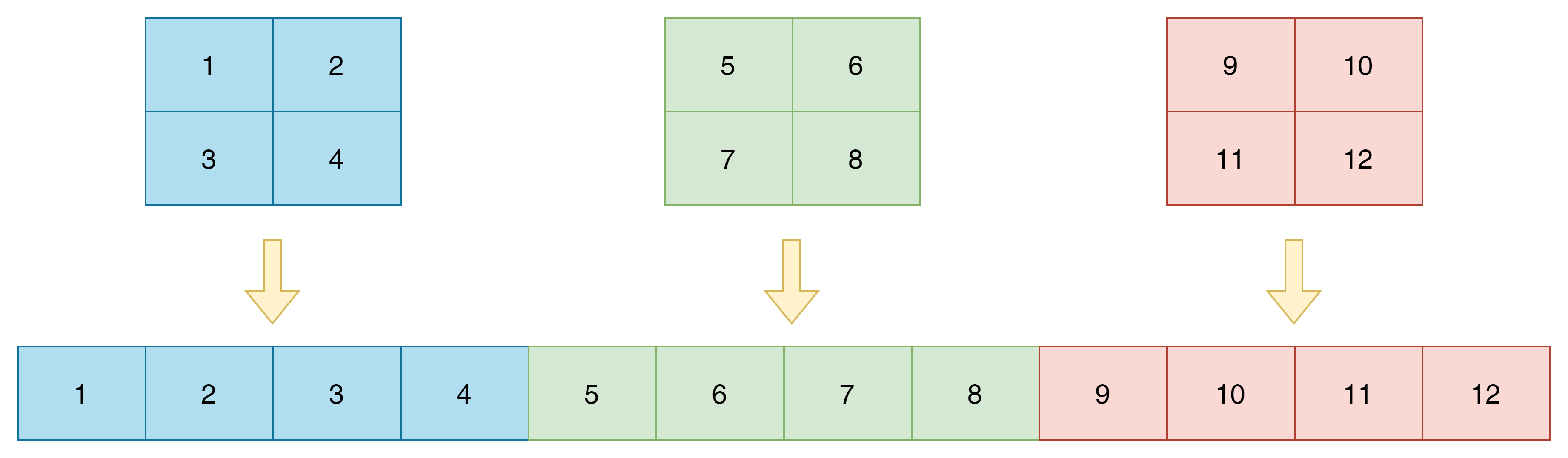
图10
这个dst_mat的内存数据就是我们想要的结果:
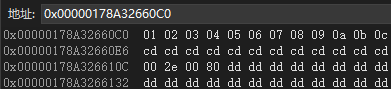
图11
假如这个时候不需要进行其他操作,直接返回dst_mat就可以了,如果还需要进行基于shape的相关操作,还需要再reshape一次: dst_mat = dst_mat.reshape(3, { 2,2 }); 。
如果是对接其他模型,如Triton backend,就不需要另外转了,因为reshape只是改变了读取数据的方式,并没有对数据进行任何操作,而最后传给Triton的也只是data指针。
当然还有很多方法可以进行转换,如使用vector数组将reshape后的channel按照顺序复制到数组中,其本质也是一样的。
4. 参考
https://cloud.tencent.com/developer/ask/sof/107600649
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号