[Triton课程笔记] 2.1.1 Backend-大纲
一、大纲

二、什么时候需要实现backend

- 需要运行Triton不支持的自研框架;
- 需要运行预处理、后处理,还有一些深度学习框架不支持的操作;
三、怎么实现backend
3.1. 框架预览
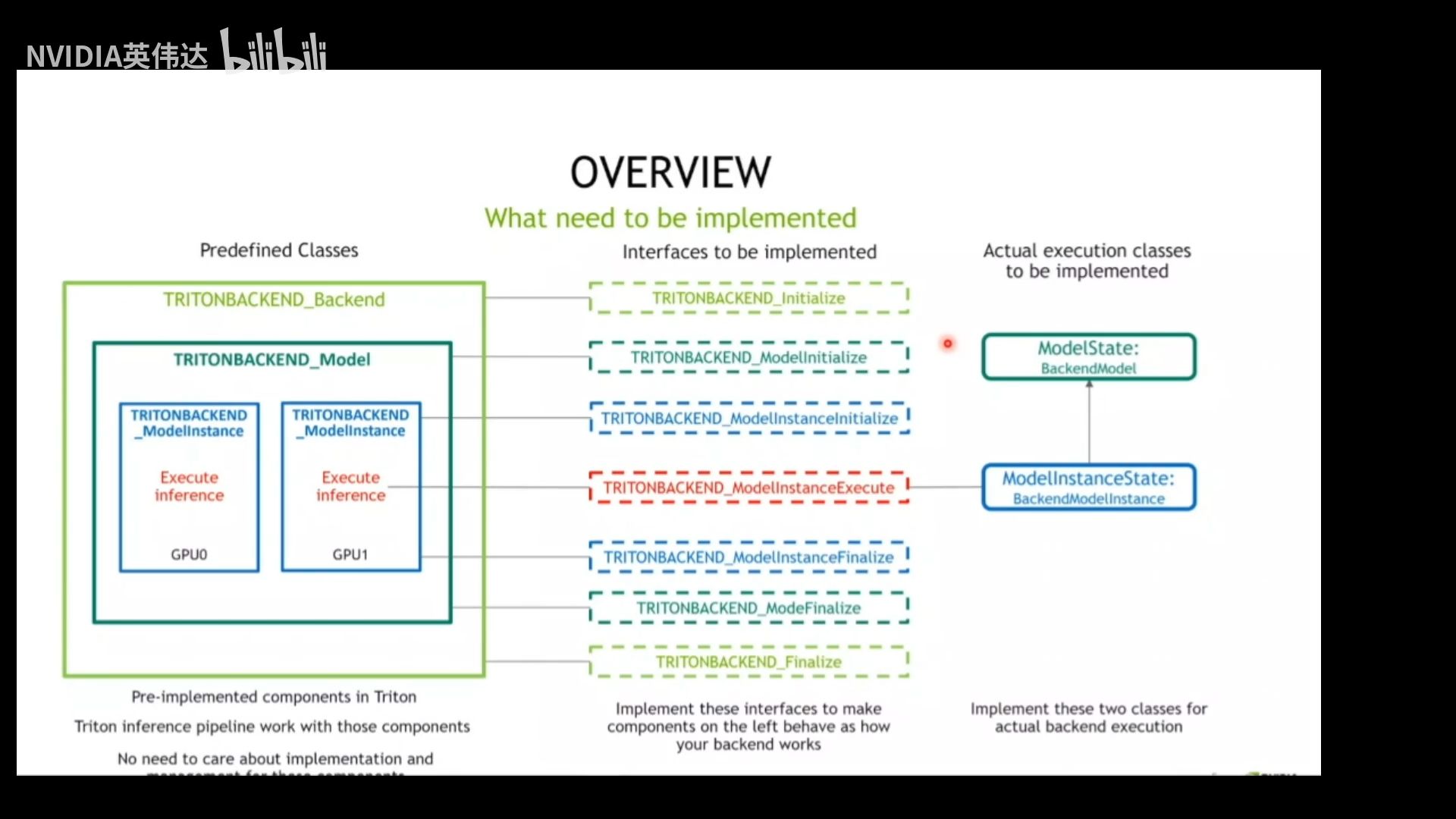
- 三个虚拟类:(已经定义的类,不需要继承)
- TRITONBACKEND_Backend:对应pytorch、tensorflow这些框架;
- TRITONBACKEND_Model:对应具体的模型,如resnet50;
- TRITONBACKEND_ModelInstance:模型的运行实例;
- 七个接口函数:(真正需要实现的接口,C风格函数)
- TRITONBACKEND_Initialize:Triton会将TRITONBACKEND_Backend类的实例传入这个函数,然后这个函数对这个对象实例进行初始化;
- TRITONBACKEND_Finalize:对TRITONBACKEND_Backend实例对象做一些收尾的工作;
- TRITONBACKEND_ModelInitialize:初始化TRITONBACKEND_Model对象实例,如初始化模型名称、输入输出名字,config.pbtxt中定义的内容都是由他来初始化;
- TRITONBACKEND_ModelFinalize: 对TRITONBACKEND_Model对象实例进行一些收尾和善后工作;
- TRITONBACKEND_ModelInstanceInitialize:对TRITONBACKEND_ModelInstance对象实例进行初始化,如指定模型实例的运行设备等,包含一切跟某个model instance相关的信息;
- TRITONBACKEND_ModelInstanceFinalize:负责TRITONBACKEND_ModelInstance对象实例善后工作;
- TRITONBACKEND_ModelInstanceExecute:这七个接口函数中最核心的函数,真正执行模型推理的函数,在运行某个模型的时候会调用它进行实际的推理;
- 两个状态类:ModeState和ModelInstanceState,模型推理的实际承担者;
3.2. 状态类的具体作用
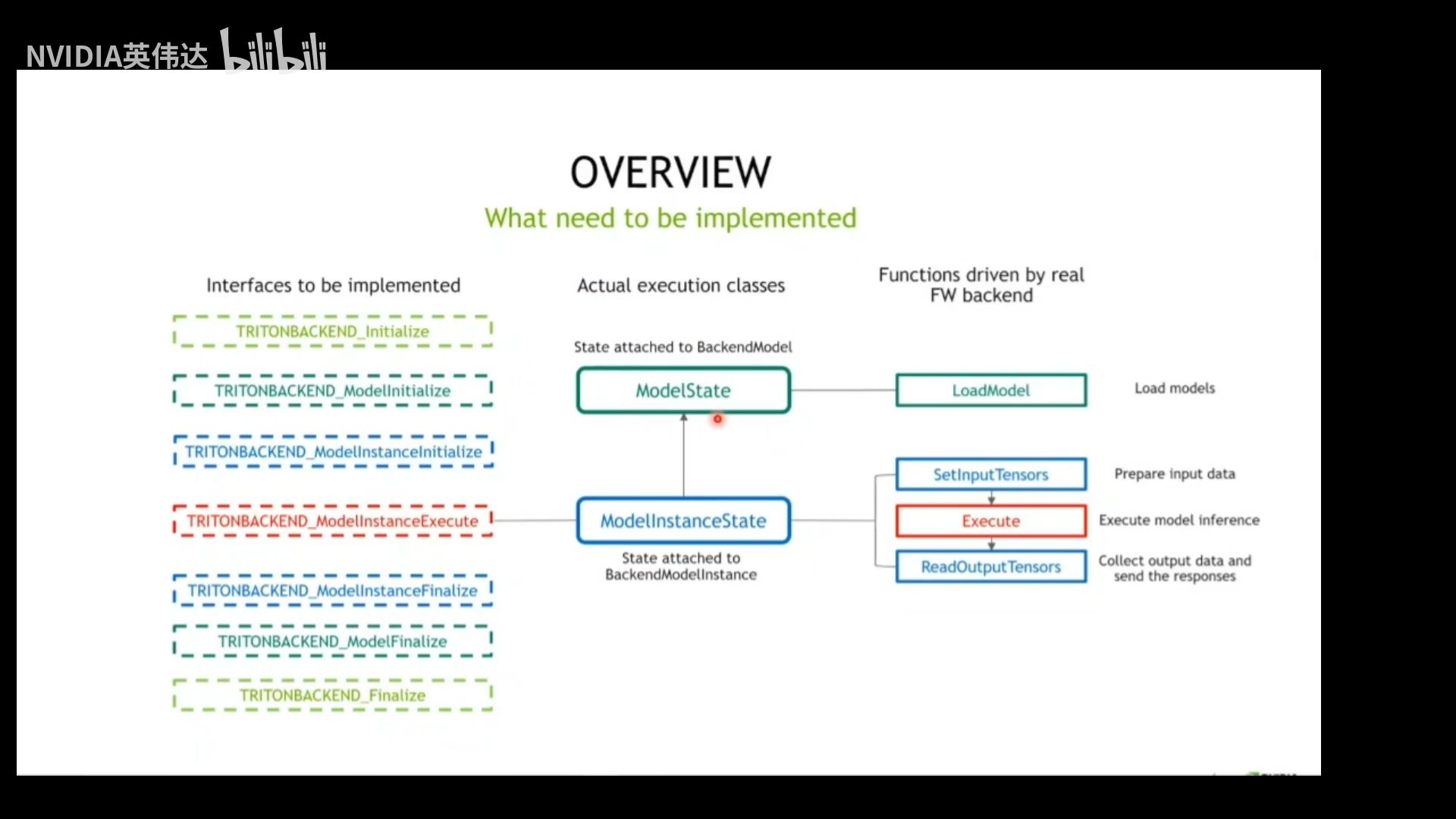 ModelState:依附于TRITONBACKEND_Model对象实例的状态信息,维护Model和ModelInstance相关的属性,如模型名称,输入输出信息等;成员方法LoadModel,负责将模型文件加载到TritonBackend中。
ModelState:依附于TRITONBACKEND_Model对象实例的状态信息,维护Model和ModelInstance相关的属性,如模型名称,输入输出信息等;成员方法LoadModel,负责将模型文件加载到TritonBackend中。ModelInstatnceState:维护TRITONBACKEND_ModelInstance对象实例的状态信息。(pytorch backend)实现了三个成员方法:
- SetInputTensors:准备模型推理输入数据;
- Excute:执行模型推理;
- ReadOutputTensors:搜集推理结果,返回给Triton;
3.3. 状态类的创建和调用流程
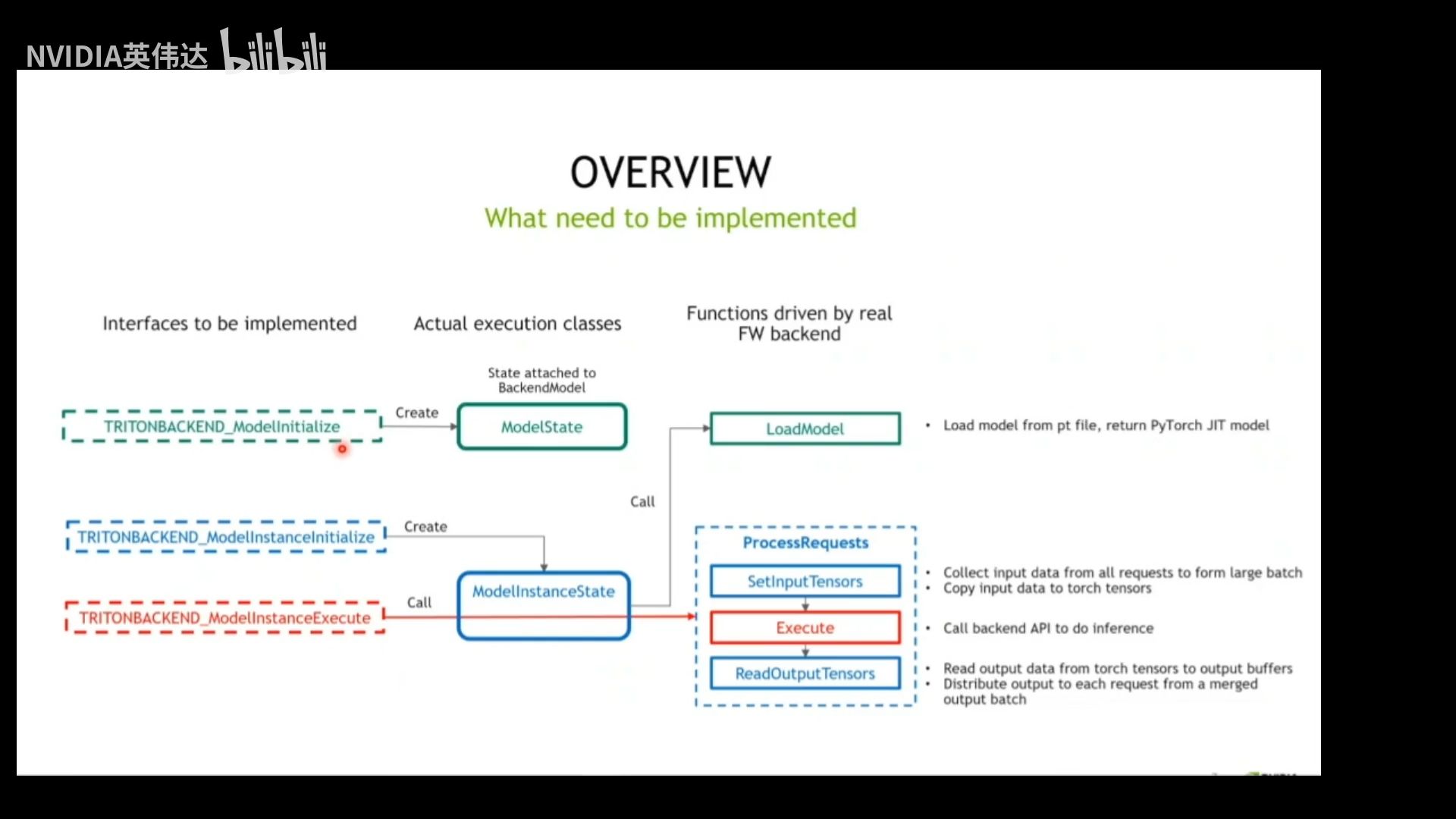
- TRITONBACKEND_ModelInitialize函数创建ModelState对象实例,并依附到BackenModel对象上;
- TRITONBACKEND_ModelInstanceInitialize创建ModelInstatnceState实例,在执行模型推理的时候,TRITONBACKEND_ModelInstanceExecute函数负责输入处理,推理、输出推理;在pytorch backend中,这个过程被封装在ModelInstatnceState的ProcessRequests成员方法中,然后这个方法顺序执行SetInputTensors、Excute、ReadOutputTensors这三个成员方法去达成目标。
四、为什么用这种设计
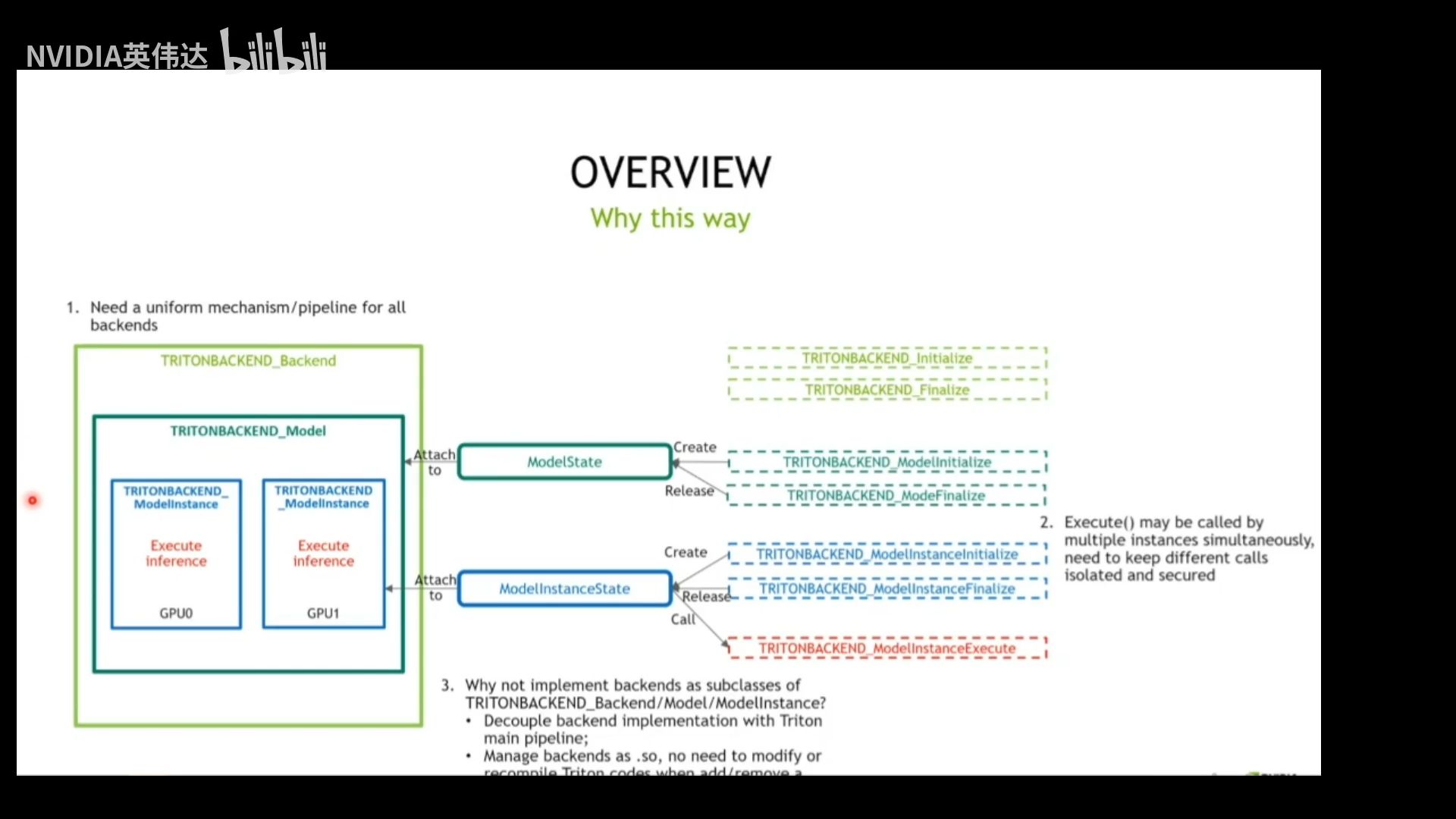
- 需要一种统一框架来应对所有backend;
- excute()可能给不同的实例同时调用,需要确保所有不同的调用是独立的,安全的,而这里的ModelInstanceState是依附到不同的ModelInstance实例的,因此符合条件;
- 解耦backend实现和Triton主流程代码,这样实现backend的时候只需要编译自己的backend代码即可;
本文版权归作者(https://www.cnblogs.com/harrymore/)和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,如有问题, 可邮件(harrymore@126.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号