
[Triton课程笔记] 1.2.2 编程实战-如何编写模型配置
一、最小模型配置

必要参数:
platform/backend: 用于指定后端,大部分情况二选一,特殊情况需要特殊对待,见后面。
max_batch_size: 指定最大batch。
input、output: 输入输出Tensor的名字和信息。
注意,对于Tensorrt,TensorFlow save-model,onnx模型,config.pbtxt不是必须的,只要启动指定 --strict-model-config=false
二、platform和backend的异同

对于Tensorrt、onnxrt、pytorch,这两种参数二选一即可。
对于TensorFlow必须指定platform,backend可选。
对于openvino,python,dali,只能使用backend。
对于Custom,21.05版本之前,可以通过platform参数设置为custom表示;之后必须通过backend字段进行指定,值为你的custom backend library的名字。
三、max_batch_size&input&output
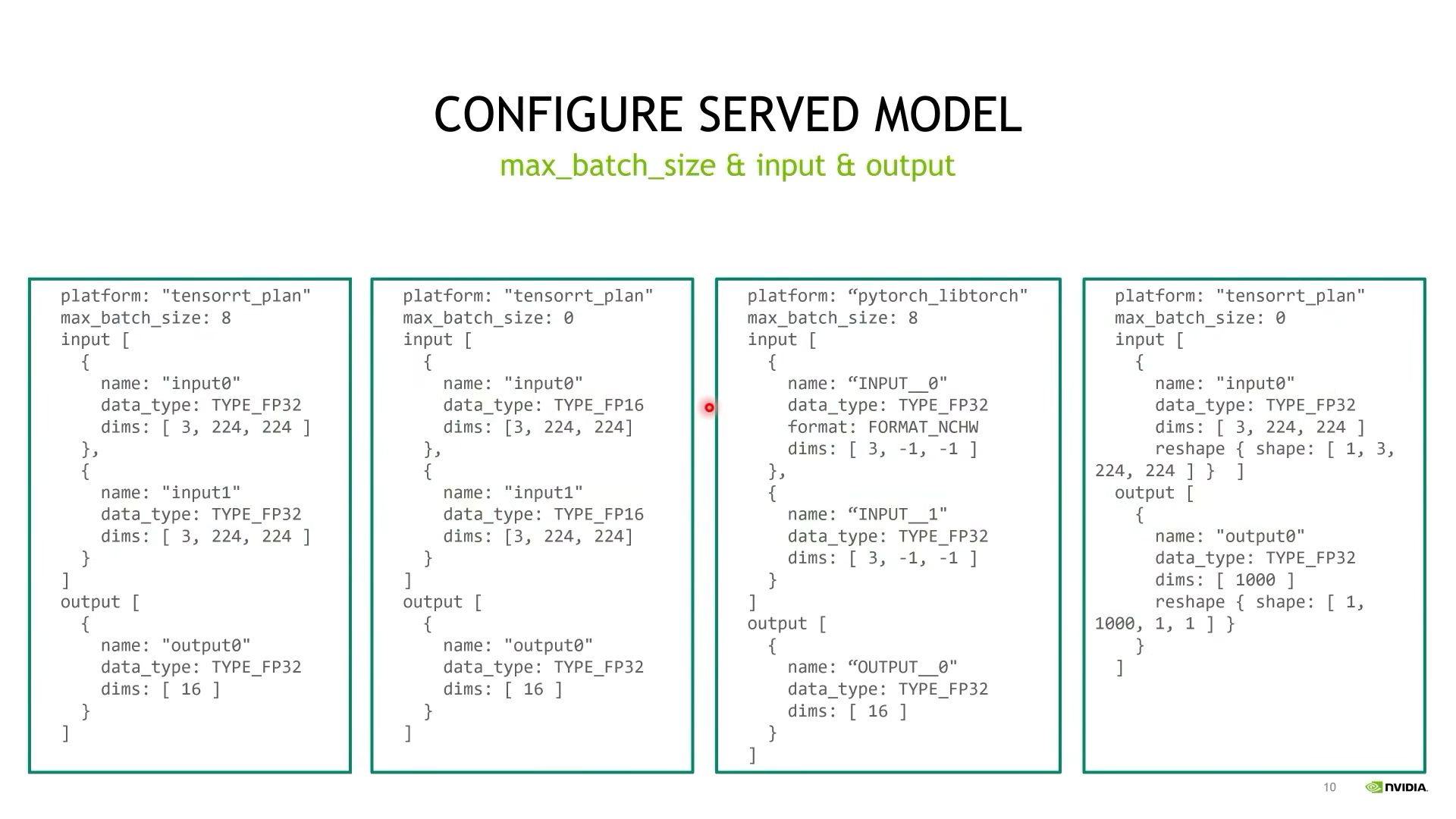
情况1:
max_batch_size为一个大于0的常数,Input和output指定名字,数据类型,数据形状。
注意:dims在指定的时候忽略batch_size的维度。
情况2:
max_batch_size等于0。表示模型的输入和输出是不包括batch_size那个维度的。
这个时候维度信息就是真实的维度信息。
情况3:
pytorch特殊情况,torchscript模型不保存输入输出的名字,因此对输入输出名称有特殊规定,"字符串__数字"。
支持可变shape,设置为-1。
情况4:
reshape参数:对输入输出进行reshape。
四、模型版本管理——version_policy

version_policy参数,策略:
- all:加载所有版本的模型。
- latest:加载最新的模型(可多个,版本号越大越新)
- specific:指定特定的版本。
五、Instance Groups
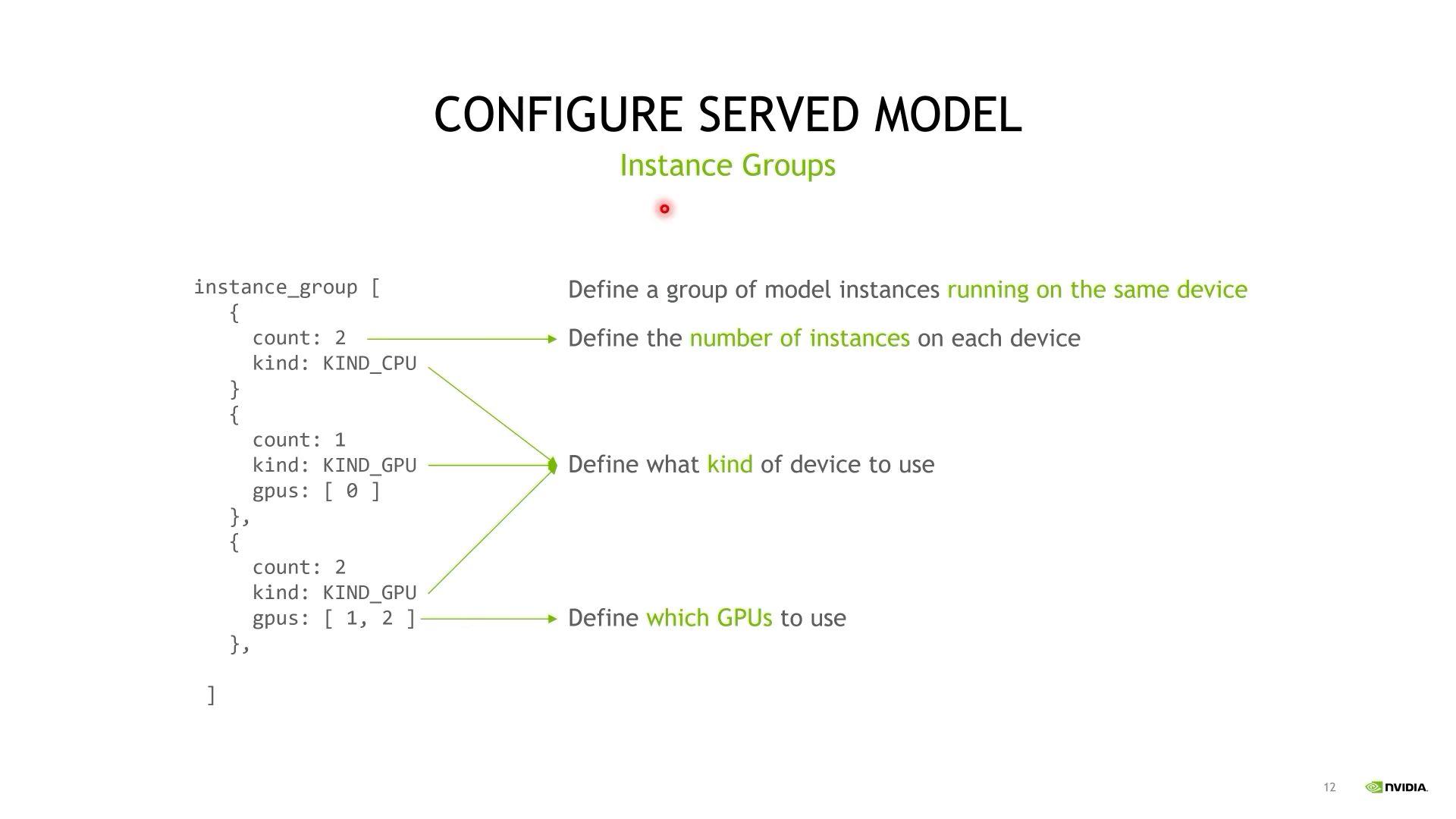
对应triton的并行计算能力特性,这个参数主要用来配置在指定设备上运行多个实例,提高模型服务能力,增加吞吐。
Instance Groups配置跑在同样设备上的一组模型实例。
- count:同时开启的模型数量。
- kind:指定设备类型。
- gpus:指定GPU编号,如果不指定这个参数,triton会在每个GPU上跑相应数量的instance。
可配置多组。
六、Scheduling And Batching
Scheduling:指定调度策略来应对请求。
6.1 Default Scheduler

- 不做batching;
- 输入进来是多少就按照多少去推理;
6.2 Dynamic Batcher

- 在服务端将多少个batch_size比较小的input_tensor合并为一个batch_size比较大的input_tensor;
- 提高吞吐率的关键手段;
- 只适合无状态模型;
子参数:
- preferr_batch_size: 期望达到的batch_size是多少,多个值;
- max_queue_delay_microseconds: 打成batch的时间限制,微秒;
高级子参数:
- preserver_ordering: 请求进来的顺序和响应出去的顺序保持一致;
- priority_levels: 定义不同优先级请求处理顺序;
- Queue_Policy: 设置请求等待队列行为;
6.3 Sequence Batcher

- 专门用于stateful model的一种调度器;
- 确保同一序列的推理请求能够路由到同样的模型实例上推理;
6.4 Ensemble Scheduler
- 组合不同的模块,形成pipeline;
- 后面详细介绍。
七、Optimization Policy

- Onnx模型优化——TRT backend for ONNX;
- TensorFlow模型优化——TF-TRT;
八、Model Warmup

指定模型热身的参数:
- 初始化可能延迟,直到收到前面几个推理请求;
- 热身完成后,Triton的服务才是Ready状态;
- 模型加载会变长;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号