[Triton课程笔记] 1.1.2 Triton的设计
这节主要介绍Triton是如何设计的。
一、从推理生命周期角度

- 多模型框架支持——将每个模型的推理任务解耦交给不同的框架——Backends;
- 功能角度
- backend管理;
- 模型管理;
- 并发执行(多线程)——实例管理;
- 推理服务请求队列的分发和调度;
- 推理服务生命周期管理
- 推理请求管理,预处理
- 推理结果管理,后处理
- GRPC服务
二、从模型角度

- 单一无依赖的模型——分类,检测等网络;
- 模型组合,pipeline,下一个模型基于上一个模型的结果进行推理;
- 有状态的模型——语言模型,上下文;
三、展示
单一模型,启动多线程(实际是多进程)进行推理:

多模型,多线程推理:

单一模型多线程,对服务推理速度有很好推理效果(跟图一的意思差不多):
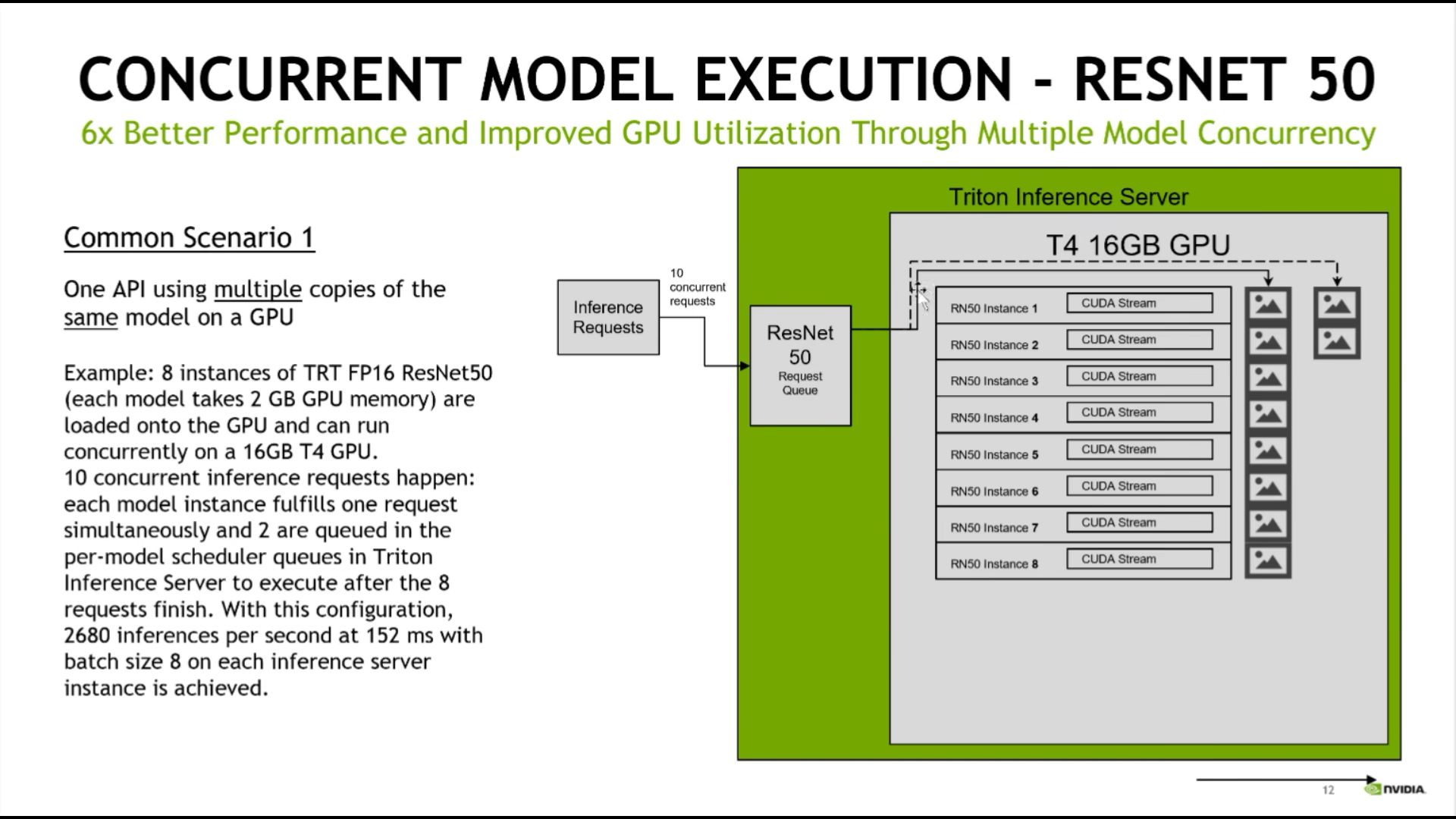
四、理解模型类型是关键

- 无状态模型
- CV模型;
- 均匀分配调度,动态batch;
- 有状态(推理结果基于前面的队列)
- NLP模型;
- 基于序列的调度:将同一推理队列绑定到一个推理服务实例上。
- Direct:推理队列按原有的顺序去进出;
- Oldest:推理队列内部顺序可以被打乱;
- 组合的
- pipeline:如前处理-推理-后处理,三个模型;
- 每个模型可以有自己的调度器;
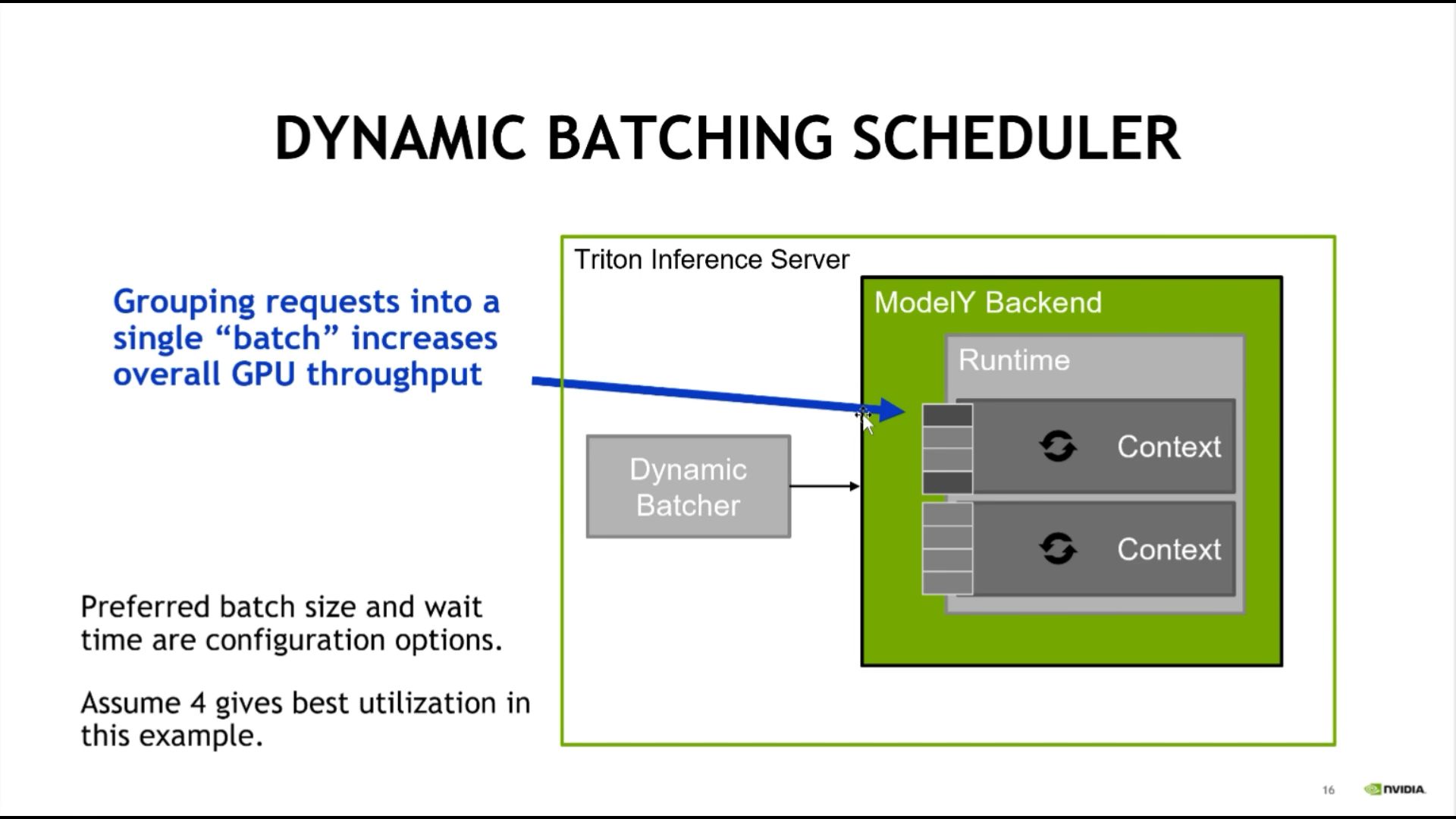
五、动态batch调度器
对请求队列进行动态batch处理:

六、流式推理请求

举例语音的场景,流式处理:进来一个语音就需要处理一个,而不能等全部拿到之后再处理。
七、模型组合的情况
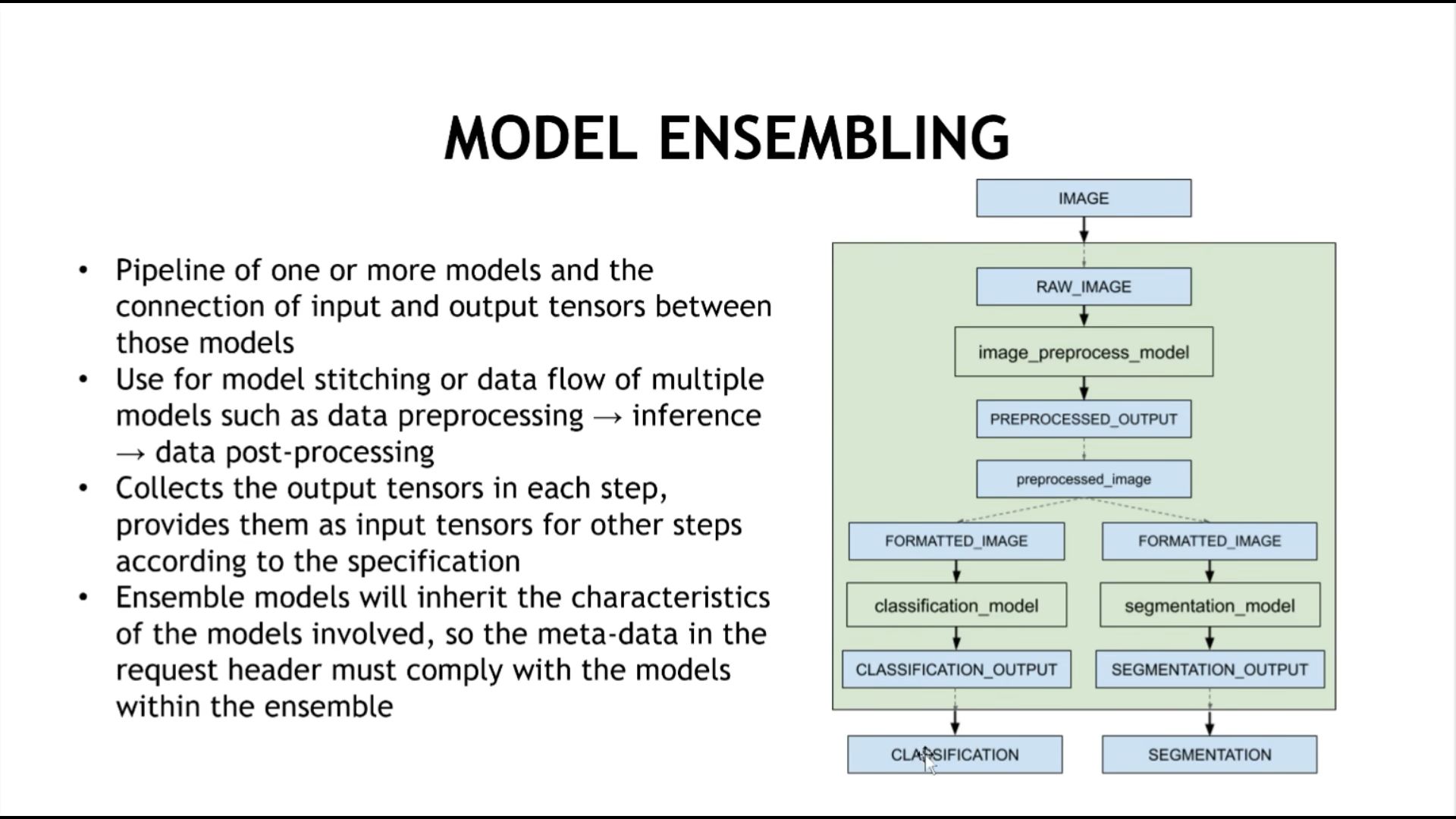
图片进入,预处理模型处理,处理后的图片,同时分类模型和分割模型。
八、framework backend和customer backend

- framework backend由其他深度学习框架定义,调用其他框架的api去实现;
- customer backend,由用户去实现。
本文版权归作者(https://www.cnblogs.com/harrymore/)和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,如有问题, 可邮件(harrymore@126.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号