[重读经典论文]YOLOV6
1. 前言
YOLOv6是美团视觉智能部研发的一款目标检测框架,致力于工业应用。它支持模型训练、推理及多平台部署等全链条的工业应用需求,并在网络结构、训练策略等算法层面进行了多项改进,能够同时专注于检测的精度和推理效率。
与其他yolo模型的性能对比:

YOLOv6-N在COCO数据集上精度为35.9 mAP,在T4卡推理速度可达1234 FPS。
YOLOv6-S 精度为 43.5 mAP,推理速度 495 FPS;YOLOv6-S 量化模型的性能更是达到SOTA在T4卡上的 FPS可加速至869,同时精度保持为 43.3%mAP。
YOLOv6-T/M/L 也具有出色的性能,与其他检测器相比,模型在基本相同的推理速度时,可以达到更高的精度。
2. 主要工作
2.1. 硬件感知网络设计
- 单路径vs多分支网络结构
- 结构重参化和激活函数
- 混合通道解耦检测头
2.2. 先进检测算法探究
- 标签分配策略
- 分类和回归损失函数
2.3. 工业便利技巧
- 自蒸馏训练
- 更多训练轮数
2.4. 定制化的量化部署方案
3. 网络结构设计

如上图所示,整体网络框架依旧沿袭了backbone+neck+head的结构,backbone和neck借鉴了RepVgg ,head在YOLOX的基础上稍微修改了一下。
3.1. Backbone

如上图所示为backbone的基本block。借鉴了RepVgg的结构重参数化,图中(a)部分为训练时的RepVgg Block,(b)为推理时通过架构重参数化技术转为单路模型,YOLOV6的小网络就用了RepVgg Block。另外,结合CSP Block和RepVgg的结构重参数化技术,组合成了CSPStackRep Block,大网络(medium and large)采用这个Block去组成backbone。关于RepVgg可以参考 RepVgg网络简介。
3.2. Neck
Neck基本沿袭YOLOV4/V5的PAN结构,不同的是将原来的CSP-Block替换为RepBlock或者CSPStackRep block(根据大小网络区分),在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。

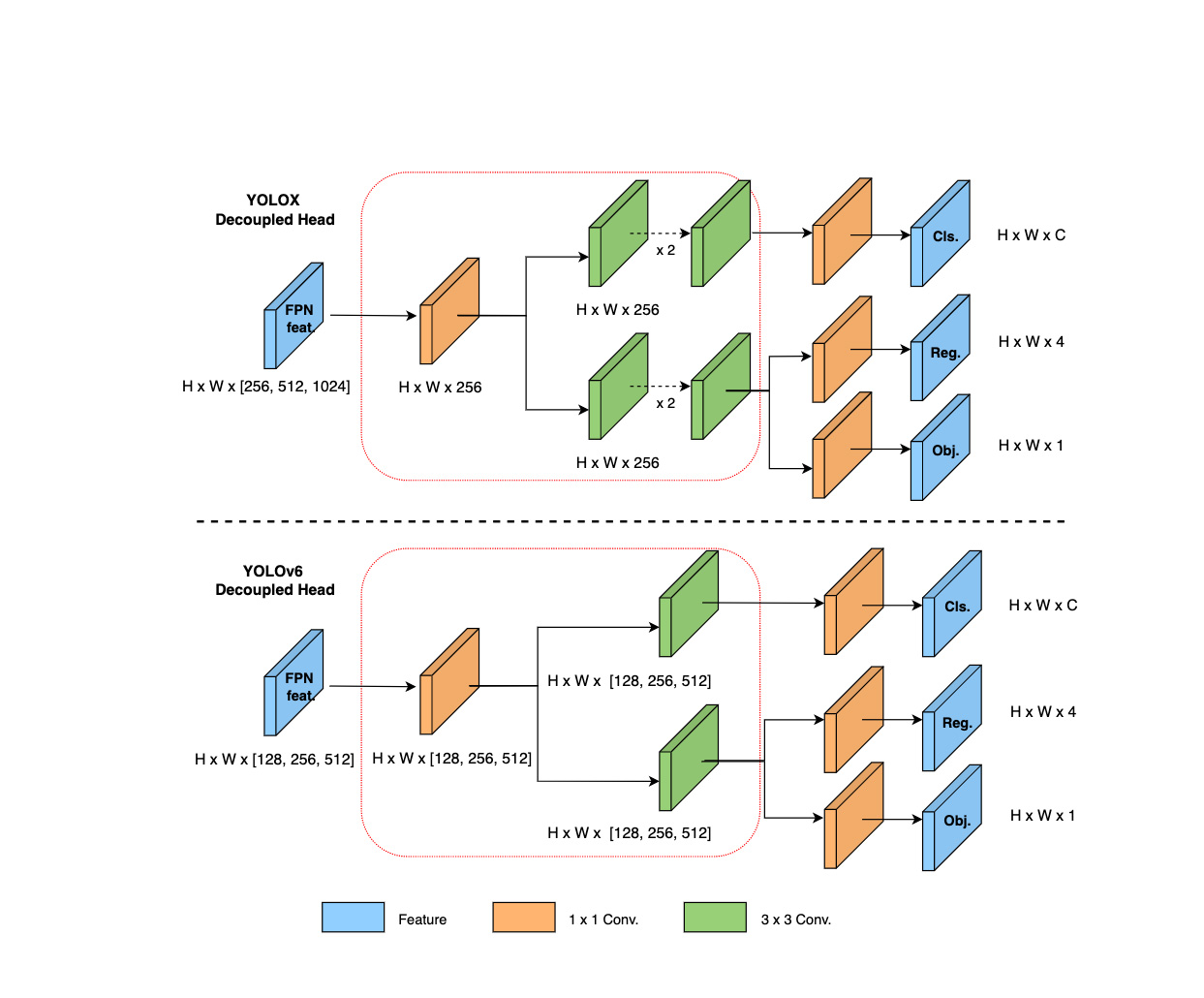
3.3. Head
Head主要简化了原来的解耦检测头, 使得效率更高,还为此取了一个名字叫Efficient Decoupled Head,实际就是在YOLOVX的基础上改了两点:
- 将解耦头中最后的两个3*3卷积层改成一层;
- 将这个3*3卷积层的输出通道改为与输入通道一致。
这么一改动,就说是基于Hybrid Channels策略的Efficient Decoupled Head,实属科研界的老坏习惯。
最后本论文继续沿用YOLOX anchor point_based范式anchor-free的检测方式,原因是泛化性能更好,预测结果解码更简单,速度更快。
4. 标签分配策略
前期也使用了YOLOX的SimOTA分配策略,但是在实践中发现拖慢训练过程,容易导致训练不稳定,于是转用了TAL算法,更高效而且容易训练。
5. 损失函数
沿袭基本通用公式:

5.1. 分类loss
采用了VariFocal Loss(VFL),它对正负样本的处理是不对称的,通过考虑正负样本的不同重要程度,它平衡了来自两个样本的学习信号。
5.2. 回归loss
YOLOV6-N采用了SIoU,YOLOV6-T采用了GIoU。
SIoU is applied to YOLOv6-N and YOLOv6-T, while others use GIoU。
另外在YOLOv6-M/L中加入了Probability Loss,采用DFL和DFLv2,将连续的坐标回归问题转换为离散的分类问题,但是由于计算成本太高,小模型没有采纳。
5.3. object损失
沿袭了YOLOX的损失函数,即二只交叉熵损失,并且正负样本的损失都计算,但是后面论文实验发现加入obj 损失之后,性能反而下降,于是后面将obj损失去掉了。

猜测可能是obj分支和TAL中其他两个分支之间的冲突。具体来说,在训练阶段,预测的box和groundtruth box之间的IoU以及分类分数被用来共同建立一个指标作为分配标签的标准。然而,引入obj分支将需要对齐的任务数量从两个扩展到三个,这显然增加了难度。
6. 工业实用改进
6.1. 更多epoch
这个没啥好说。
6.2. 自蒸馏
采用自蒸馏和更多训练epoch,其中自蒸馏使用KL散度去最小化教师网络和学生网络的差距,box回归标签使用DFL算法(将连续的坐标回归问题转换为离散的分类问题),蒸馏loss:

其中 和
和 是教师网络和学生网络的分类预测概率,
是教师网络和学生网络的分类预测概率, 和
和 是box回归预测值。
是box回归预测值。
硬标签预测loss为5中的(3)式,最后的loss为:

其中alpha用了cosine weight decay策略,让学生模型前期多学习软标签,后期多学习硬标签。
6.3. 推理阶段加灰边
推理的时候,将图片加上灰边,让图片边缘部分的检测更加精准,提高模型性能,这个问题猜测是在训练时用的Mosaic augmentation会给图片加上灰边,因此预测的时候加上会适合模型推断。
但是因为加上大量灰边会影响推理速度(变相提高分辨率),因此v6的做法是在训练阶段最后的一些epoch关掉Mosaic augmentation,然后在预测时加上少量灰边,达到精度和速度的权衡。
7. 量化与部署
7.1. YOLOV6量化存在的问题
YOLOV6在量化方面存在一些问题:
- YOLOv6结构中大量使用了重参数化结构,导致数据分布过差,PTQ精度急剧下降。
- 重参数化结构网络,无法直接使用OAT进行微调提升量化性能。
- Deploy模型无BN,不利于训练
- Train模式进行QAT之后无法进行分支融合
这些问题导致量化后的模型性能很差,如下表所示:

7.2. 解决方式
因为常规量化结构重参数化的模型方法会导致模型退化,因此用了RepOptimizer优化器去直接训练一个直筒型的模型出来,在这个基础上去做量化,如下图所示:

RepOptimizer算是RepVgg2.0,思路是引入先验知识先验信息用于修改梯度数值,称为梯度重参数化,对应的优化器称为RepOptimizer,去训练VGG式的直筒模型,训练得到RepOptVGG模型。
总的来说,虽然YOLOv6给学术界吐槽创新不足,但是它的确是在工业上有很大的实用性,特别是在自蒸馏和量化部署方面做了很多工作,对部署比较友好,而且也做了大量的消融实验,有一定的借鉴意义。
8. 参考
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号