[经典论文重读]Inception V2/V3
1. 前言
Inception V2/V3由googLeNet的一作在《Rethinking the Inception Architecture for Computer Vision》中提出。本论文在GoogLeNet和BN-Inception的基础上,对Inception模块的结构、性能、参数量和计算效率进行了重新思考和重新设计。提出了Inception V2和Inception V3模型,取得了3.5%左右的Top-5错误率。
Inception V3具有强大的图像特征抽取和分类性能,是常用的迁移学习主干网络基模型。
论文首先提出了设计CNN模块的四大基本原则:
- 避免过度降维和特征Bottleneck瓶颈收缩(避免过度的1 x 1卷积,特别是在网络浅层)。
- 独立的特征越多收敛越快(尽可能在分类层之前增加通道数)。
- 大卷积核卷积之前可用1x1卷积降维(3x3或5x5卷积之前可先用1x1卷积降维,可保留相邻单元的强相关性)。
- 要均衡网络的宽度和深度。
在四大基本原则的基础上,对Inception模块进行了改进。
首先将5x5卷积分解为2个3x3卷积,可以在保证感受野大小不变的情况下减少参数量和计算量,同时引入额外的非线性。
然后将3x3卷积分解为1x3和3x1两个不对称卷积(空间可分离卷积)。
对GoogLeNet的辅助分类器的作用进行了重新思考。提出辅助分类器并不能帮助模型更快收敛和更快的特征演化,但是增加了BN层和Dropout层的辅助分类器可以起到正则化作用。
提出了更高效的下采样模块,使用Inception模块本身进行下采样,在节约计算量的同时防止特征瓶颈和信息丢失。
使用以上改进,构建了Inception V2模型,在此基础上,进一步引入优化器改进、Label Smoothing标签平滑正则化等技巧,提出Inception V3模型。
论文还包括对小分辨率图像分类的性能研究。
重点可以概括为四、三、二,提出四个基本原则,实践三个改进模块,提出两个模型。
2. 四大基本原则
作者们在几种卷积神经网络架构上进行了大量的实验,提出了几个基本原则,当然这些还需要更多的实验和证据进行证明。(google团队的论文风格,通过实验,提出理论基础)
- 原则一:避免过度降维或者收缩特征bottleneck,特别是在网络浅层,feature map的长宽大小应该随网络加深缓缓减小。
- 原则二:特征越多,收敛越快。相互独立的特征越多,输入的信息分解得越彻底,也印证了赫布原理的fire together, wire together。
- 原则三:在空间聚合之前,也就是使用类似3*3,5*5这种大卷积核之前,可以使用1*1卷积降维,这个时候信息不会损失(或者损失很少)基于一个假设,如果输出用于空间聚合上下文,则相邻单元之间的强相关性导致在降维过程中的信息损失要少得多。
- 原则四:均衡网络的宽度和深度,两者同时提升,既可提高性能,又能提高效率。
上述的一般性准则从理论上是可行的,但是也不是开箱即用,实际上也需要更多的实验去验证。
3. 分解大卷积核的卷积

如上图所示,一个5*5的卷积核,可以拆分为两个3*3的卷积,而实际他们的感受野都是5*5。
另外,本文还分析了两个3*3卷积中间是否需要保留非线性激活,如下图所示:

证明了分解卷积时保留非线性激活可以提升模型表示能力。
3.1. 分解为更小的卷积

这是第一个改变的模块,由原来的5*5卷积,在计算量上,是两个3*3卷积的2.78倍,因此在减少参数量的同时,也减少了计算量,同时又不损失感受野。
3.2. 分解为不对称卷积

这是第二个模块,将一个3*3卷积,分解成一个1*3和一个3*1卷积,参数和计算量少了33%。不过不对称卷积也是有限制的,在靠前的层效果不好,一般需要feature map的尺寸在12~20之间。
4. 扩展滤波器组

用于卷积网络最后的升维,增加feature map的个数,挖掘高维独立稀疏特征。
以上三个就是本论文提出的三个新的模块,可以看到这三个模块右边都有池化层,隐含了一个高效下采样的技巧。
一般来说卷积神经网络就是不断地对特征进行下采样,在下采样的过程中,一般需要先升维以保留更多的信息,传统的做法有两种,一是先池化压缩,再升维,这种办法丢失的信息太多,违反了原则一;二是先升维再池化,但是这个计算量要比前面那个多三倍,如下图所示。

本论文的三个inception模块,把卷积和池化并行进行,在扩充通道的同时下采样,保证了计算效率,如下图所示:

5. 辅助分类器
这里作者也承认,在GoogLeNet中的两个浅层的辅助分类器对模型的收敛没起到什么作用,去掉也没什么影响,相对的,本论文在靠近输出层增加了辅助分类器,并增加了BN层,发现提高了top1准确率,而且猜测能起到正则化的作用(后面大家都知道BN层的确是有这个作用)

6. Inception-v2网络
V2实际上就是运用了以上提到的模块与改进,组合成了一个新的网络:

本网络计算量是GoogLeNet的2.5倍,但仍旧比Vgg高效。
7. 标签平滑
作者提出了一种通过向真实数据标签分布加入噪声的方式来进行正则化,抑制过拟合问题。一般地,数据标签都是以One-hot形式编码,正确类别标记为1,错误标签标记为0,使用交叉熵损失函数时,其损失函数为:
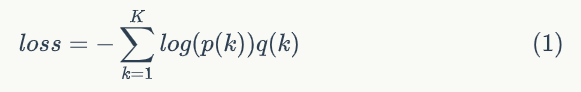
其中,$k \in \{1…K\}$ (K表示总的分类数), p(k)为模型预测概率,为最后一层输出的Logit分数经过softmax层的输出:

q(k)为正确类别的标签值,正确类别对应的位置为1,其他的为0。
从最小化交叉熵函数的角度来看,要使之最小化,log(p(k))最需要最大化,也就是p(k)越接近1越好,倒推到2式,则正确类别所在的Logit越大,其对应的softmax概率才越接近于1,这样在训练的时候,鼓励模型不计代价增大这类的概率,容易造成过拟合。
所以作者提出不使用原始的标签概率分布q(k) ,进而考虑标签的真实分布u(k) 与平滑指数 $\epsilon $ 来修正q(k), 得到新的标签概率分布:

, 一般来说u(k)为均匀分布, 即

实际就是对原来的one hot标签中,把一个概率,平分给其他不是正确类别的类。

如 $\epsilon$取0.1,有4个类,就把原来正确的类的概率设置为0.9,然后0.1平均分给其他类别。
使用这个方法,在ILSVRC2012的数据集上能够把top1和top5的准确率都降低0.2个点。
8. Inception-V3
训练是使用了SGD,早期使用momentum优化算法进行训练,最好的模型是使用RMSProp优化算法,另外还用了gradient clipping,验证阶段用了移动平均平滑的技巧。
另外还在小图的性能上进行了实验,实验证明了在保持相同计算量的同事,不同分辨率的输入性能差别不大:

其实可以看到还是有帮助的,299的相对79已经提高了0.6个点了。
在Inception-v2的基础上,作者逐步加上了RMSprop优化、label smoothing 与 BN-auxilary, 形成了Inception-v3,在单尺度crop的输入下,最终模型的结果如下,最后一行就是Inception V3:

9. 参考
[1] 论文阅读:Rethinking the Inception Architecture for Computer Vision
[2] 【精读AI论文】Inception V3深度学习图像分类算法
[4] 知乎:神经网络中的label smooth为什么没有火?
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号