[轻量化网络]ShuffleNet V2学习笔记
![[轻量化网络]ShuffleNet V2学习笔记](https://img2022.cnblogs.com/blog/741682/202210/741682-20221018143259742-137511581.png) 旷视轻量化卷积神经网络ShuffleNet V2
ECCV 2018论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
通过大量实验提出四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC的影响进行了详细分析。
提出ShuffleNet V2模型,通过Channel Split替代分组卷积,满足四条设计准则,达到了速度和精度的最优权衡。
旷视轻量化卷积神经网络ShuffleNet V2
ECCV 2018论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
通过大量实验提出四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC的影响进行了详细分析。
提出ShuffleNet V2模型,通过Channel Split替代分组卷积,满足四条设计准则,达到了速度和精度的最优权衡。
1. 四条轻量化网络设计准则
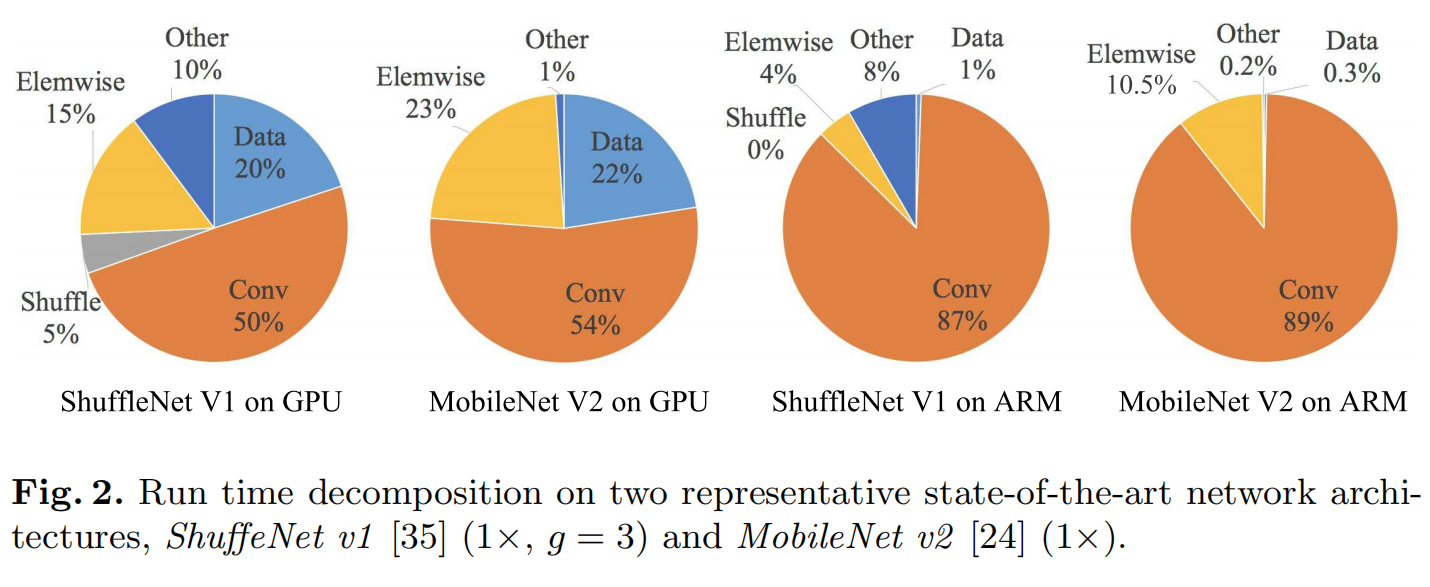
如上图所示,分别在GPU和ARM设备上,测试ShuffleNet V1和MobileNet V2在各种操作上的耗时占比,其中:
- Elementwise:逐元素操作,如RELU函数,残差网络的逐元素相加(shortcut)。
- Data:数据操作,如输入,输出。
- Conv:卷积操作。
- Shuffe:通道重排。
由这个实验可以得出以下结论:
- 乘-加浮点运算次数FLOPs仅反映卷积层,仅为间接指标。
- 不同硬件上的测试结果不同。
- 数据读写的内存MAC占用影响很大。
- Element-wise逐元素操作带来的开销不可忽略。
由此引出轻量化网络的四条设计准则:
- 准则一:输入输出通道数相同时,内存访问量MAC最小。
- 准则二:分组数过大的分组卷积会增加MAC。
- 准则三:碎片化操作对并行加速不友好。
- 准则四:逐元素(Element-wise)操作带来的内存和耗时不可忽略。
注:准则一可以理解为卷积核数量最好与输入的通道数一致;碎片操作指多通路,多分支等,如inception里的分支结构;逐元素操作,如RELU,残差网络的shortcut。
2. 原则详解
2.1. 准则一:输入输出通道数相同时,内存访问量MAC最小
2.1.1. 如何计算FLOPs和MAC
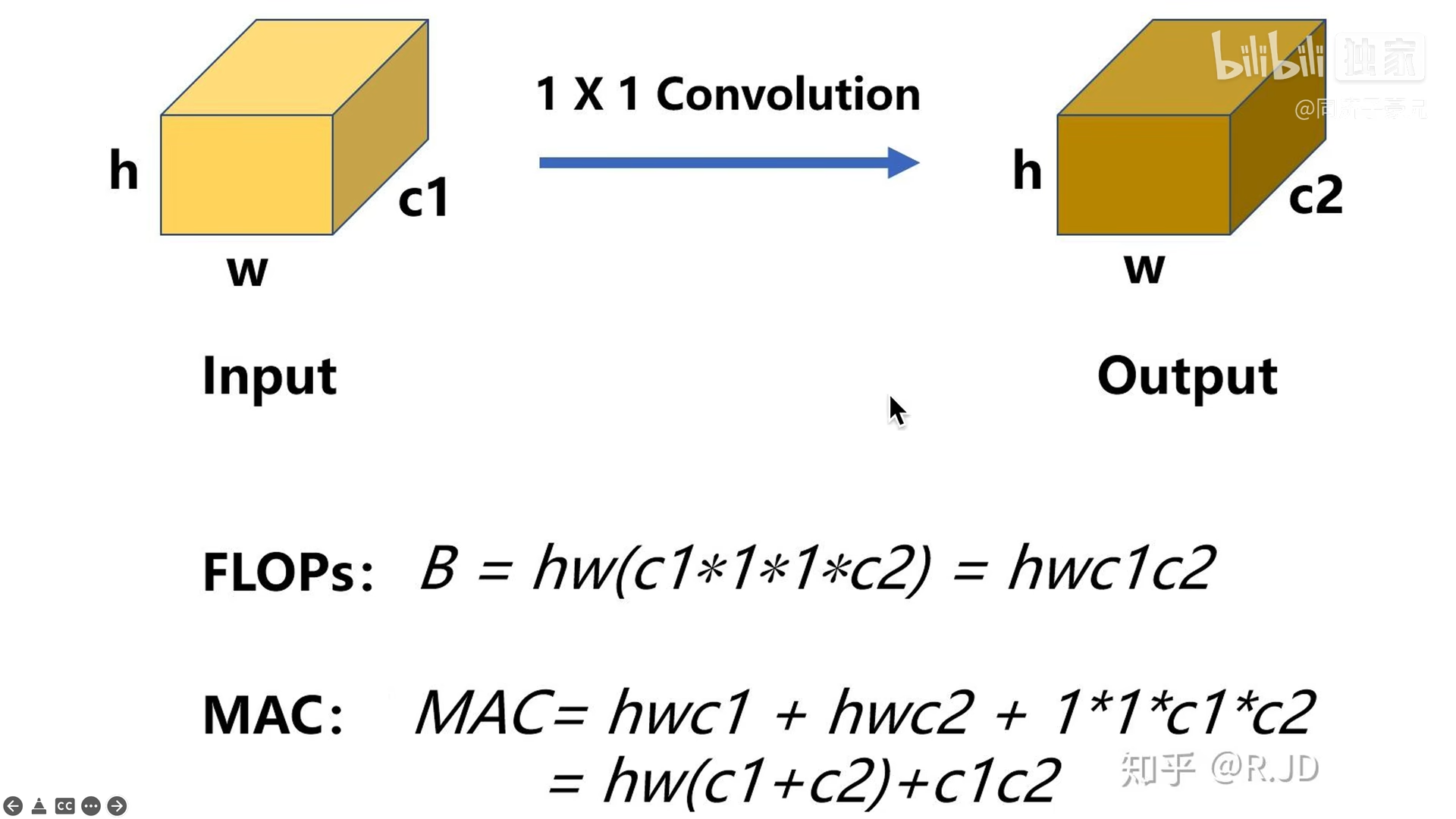
FLOPs:计算量,只算乘法。在上图中,计算次数为输出的特征大小h*w*c2,每次的计算量为卷积核的大小1*1*c1,总共的计算量为h*w*c2*1*1*c1。
MAC:内存访问量,为输入,卷积核与输出的和。
2.1.2. 证明,均值不等式
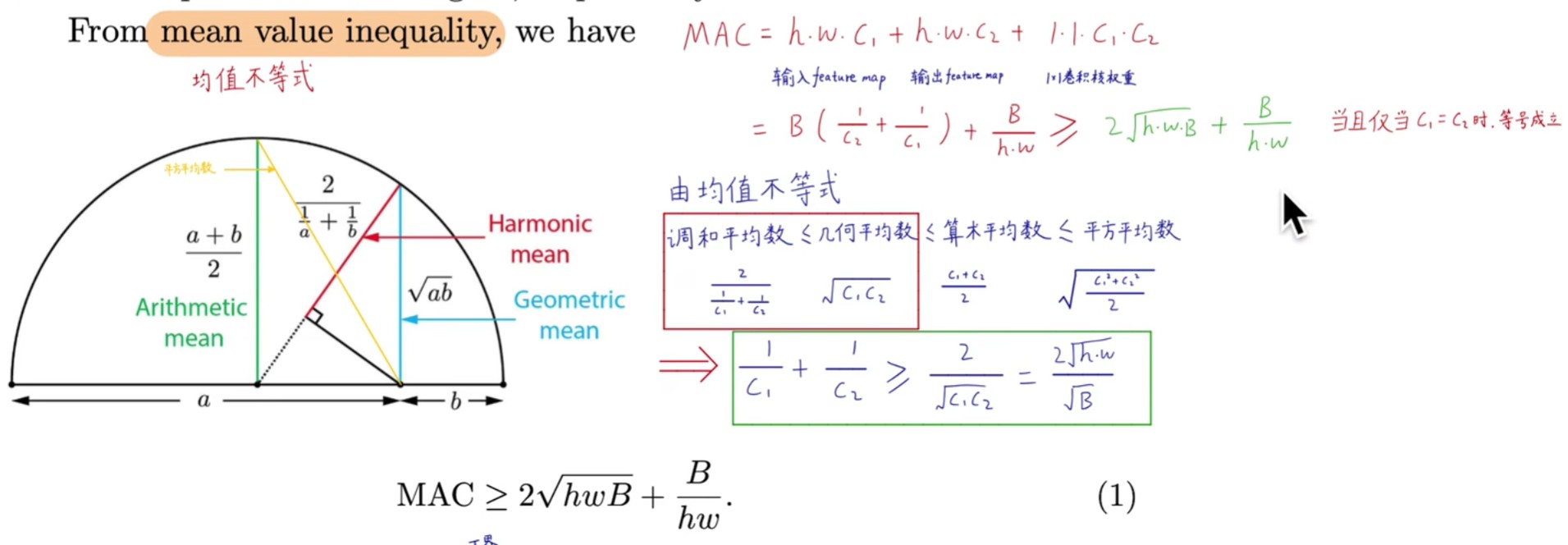
通过直角三角边之间的关系,构建均值不等式,只有当C1=C2的时候,不等式才取等号,这个时候MAC最小。
2.1.3. 实验
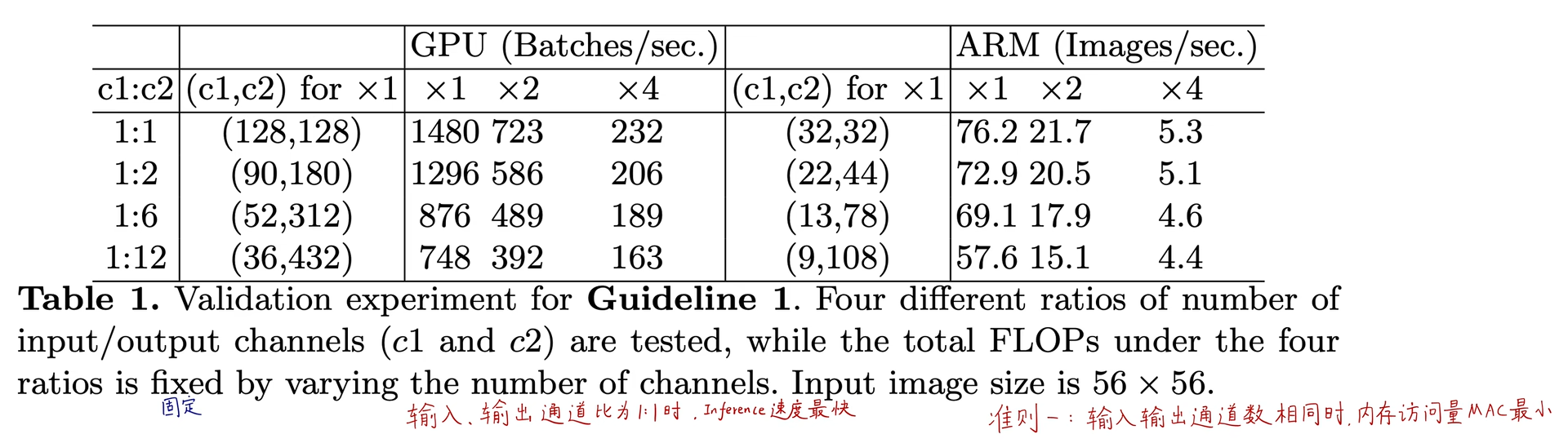
固定FLOPs,通过改变输入输出的通道数比例进行对比测试。1:1的通道数比例的时候,推断速度最快,用来类推此时的MAC最小。
2.2. 准则二:分组数过大的分组卷积会增加MAC
2.2.1. 理论证明
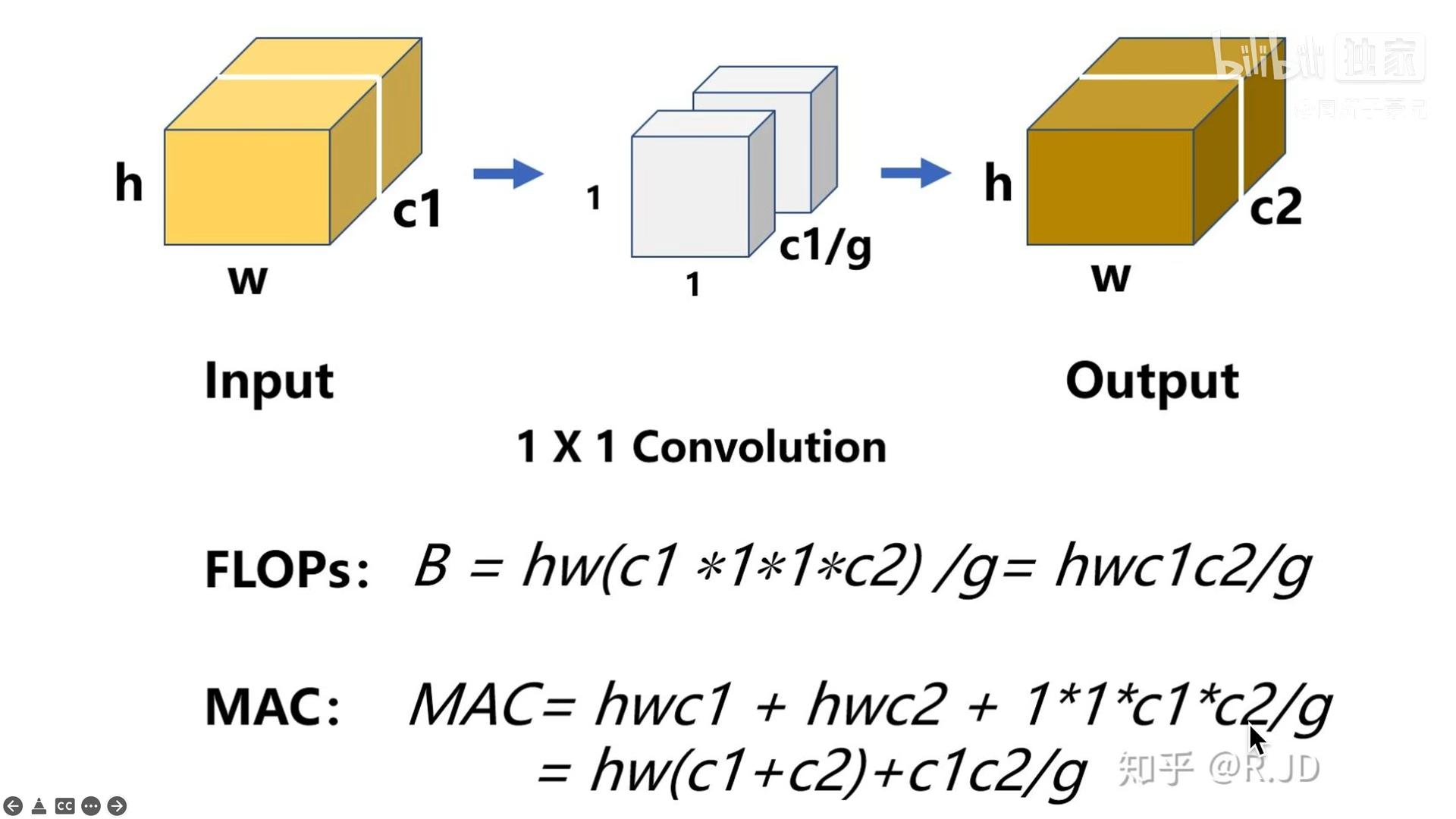
计算分组卷积的FLOPs和MAC,将B,h,w,c1设为常数,将B代入MAC公式中:

当固定输入尺寸c1,计算量B,当g越大,MAC越大。
2.2.2. 实验
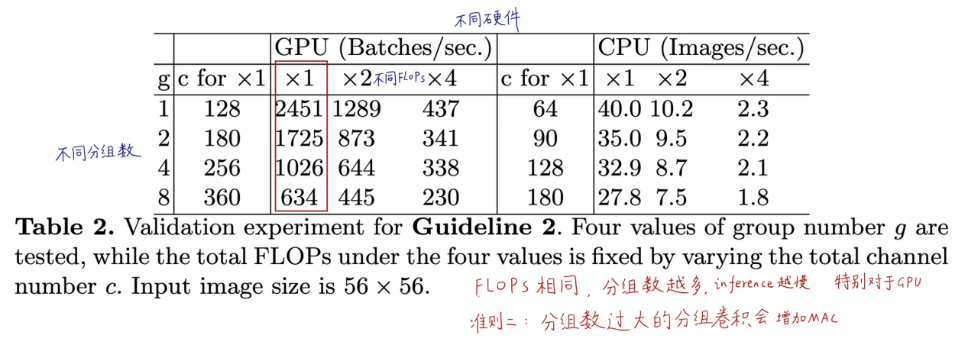
在同样的FLOPs下,分组数越多,推断速度越慢。
2.3. 准则三:碎片化操作对并行加速不友好
在很多网络,如GoogLeNet或者AI直接搜出来的网络那样,多路的结构是很常见的。往往这些碎片化操作,虽然有助于提高模型准确率,但对并行加速非常不友好,特别是GPU这种设备,而且也造成了额外的开销,如kernel launch和同步。
实验:
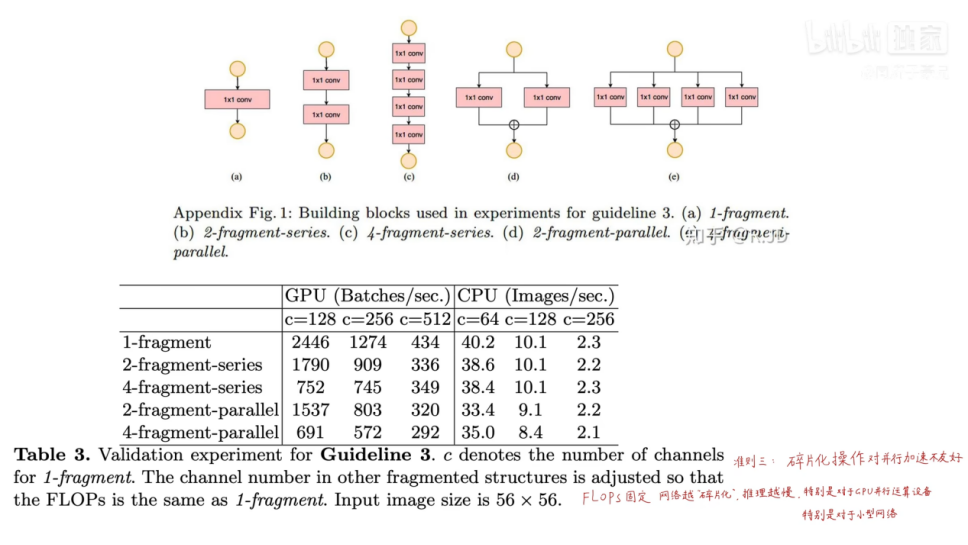
保持FLOPs不变的情况下,设计了单个卷积模块,多个卷积模块串行,多个卷积模块并行的结构。最后结果证明,碎片化操作在GPU上,碎片化操作对推断速度的影响最大,ARM设备的影响反而相对小。
2.4. 准则四:逐元素(Element-wise)操作带来的内存和耗时不可忽略
碎片化操作:RELU,AddTensor,AddBias等。
特点:FLOPs很小,MAC很高。
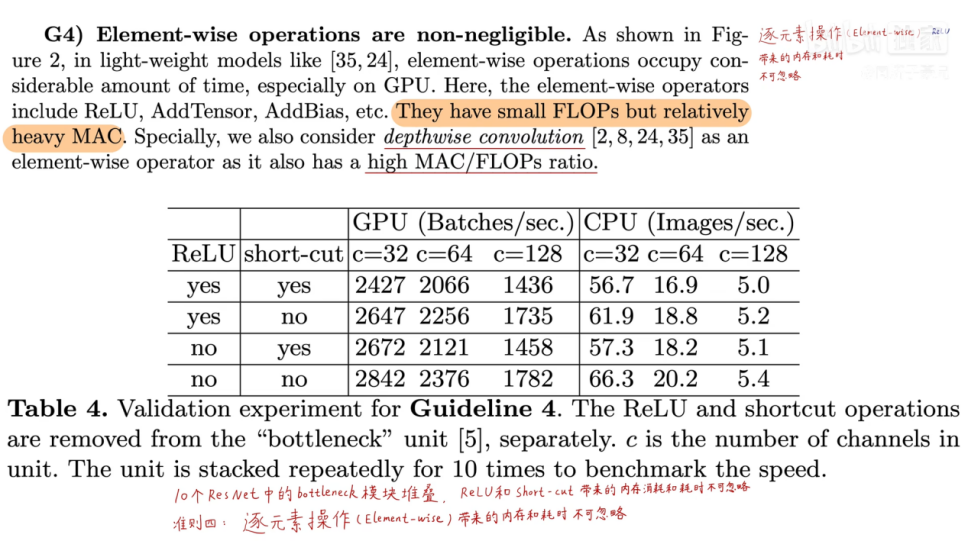
以是否保留RELU和shortcut,进行实验。
在RELU和shortcut都去掉的情况下,在GPU和ARM上,都获得20%左右的提速。
3. 基本模块设计
根据四个基本准则,目标是设计出这样一个网络:在既不使用标准1*1卷积,也不使用过多分组卷积的前提下,使用尽可能多的channel。
为了实现上面的目标,使用了Channel Split操作。
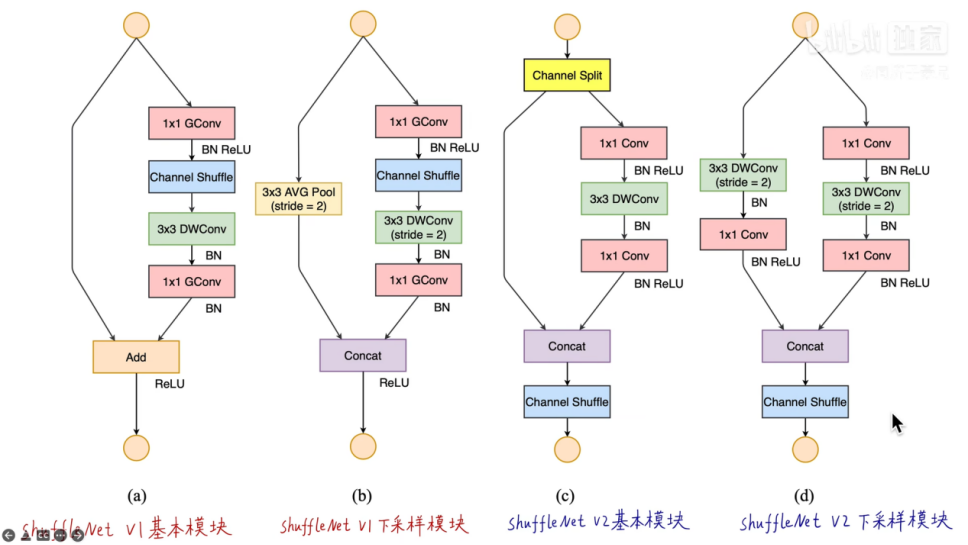
c是基本模块,将输入通道分为两部分(论文是均分),一部分进行卷积操作,一部分恒等映射,最后串起来再channel shuffle。V2摒弃了V1的创新点分组操作,用Channel split操作实现了分组的效果。
d是下采样模块,分别用步长为2的卷积操作进行下采样。最后输出的通道数加倍,长宽减半。
“Concat”“Channel Shuffle”“Channel Split”这几个连续的elementwise 操作,可以合并为一个操作,使得更符合准则四。
4. 参考
[1] 【精读AI论文】谷歌轻量化网络MobileNet V2(附MobileNetV2代码讲解)
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号