[轻量化网络]Mnasnet学习笔记
![[轻量化网络]Mnasnet学习笔记](https://img2022.cnblogs.com/blog/741682/202210/741682-20221007161158541-1101718959.png) 谷歌轻量化卷积神经网络Mnasnet,介于MobileNet V2和V3之间。
CVPR2019论文:Mnasnet: Platform-aware neural architecture search for mobile
使用多目标优化的目标函数,兼顾速度和精度,其中速度用真实手机推断时间衡量。
提出分层的神经网络架构搜索空间,将卷积神经网络分解为若干block,分别搜索各自的基本模块,保证层结构多样性。
谷歌轻量化卷积神经网络Mnasnet,介于MobileNet V2和V3之间。
CVPR2019论文:Mnasnet: Platform-aware neural architecture search for mobile
使用多目标优化的目标函数,兼顾速度和精度,其中速度用真实手机推断时间衡量。
提出分层的神经网络架构搜索空间,将卷积神经网络分解为若干block,分别搜索各自的基本模块,保证层结构多样性。
1. 重点与亮点
由google团队论文《MnasNet: Platform-Aware Neural Architecture Search for Mobile》中提出,使用神经架构搜索技术,自动发现在给定任务上表现良好且计算和内存效率高的网络架构。它在图像分类和目标检测等计算机视觉任务上表现出色,适用于移动和嵌入式设备。
1.1. 多目标优化函数
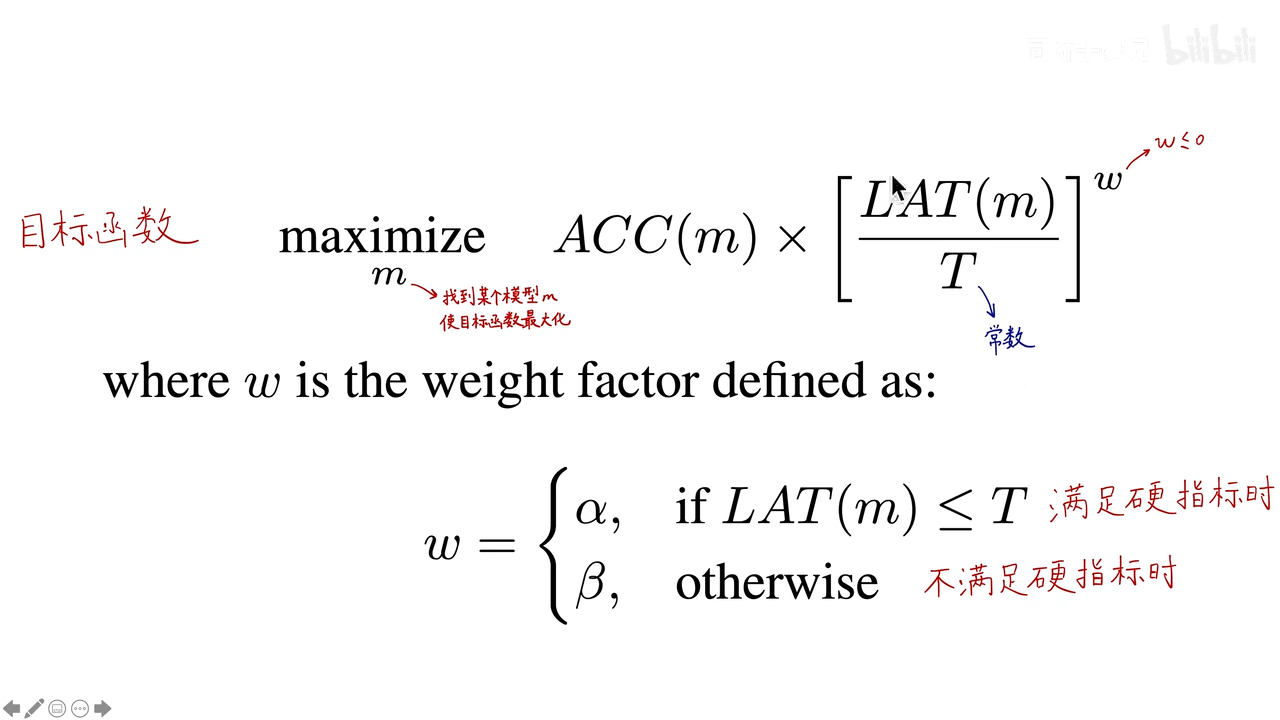
将准确定性能和真实手机推理时间结合在一起,兼顾精度和速度构建出多目标的优化函数。(精度,速度)
其中ACC是准确度;LAT是预测时间;T是一个常数,硬指标,表示让模型在T时间内完成预测,如75ms;w是一个小于等于零的数;整体来讲,要让目标函数(找到某个模型m)最大化,则ACC要足够大,LAT要足够小。
w是一个超参数,当LAT满足硬指标的时候,设置为α,否则设置为β,至于不同的α和β有什么区别,可以参考下图:
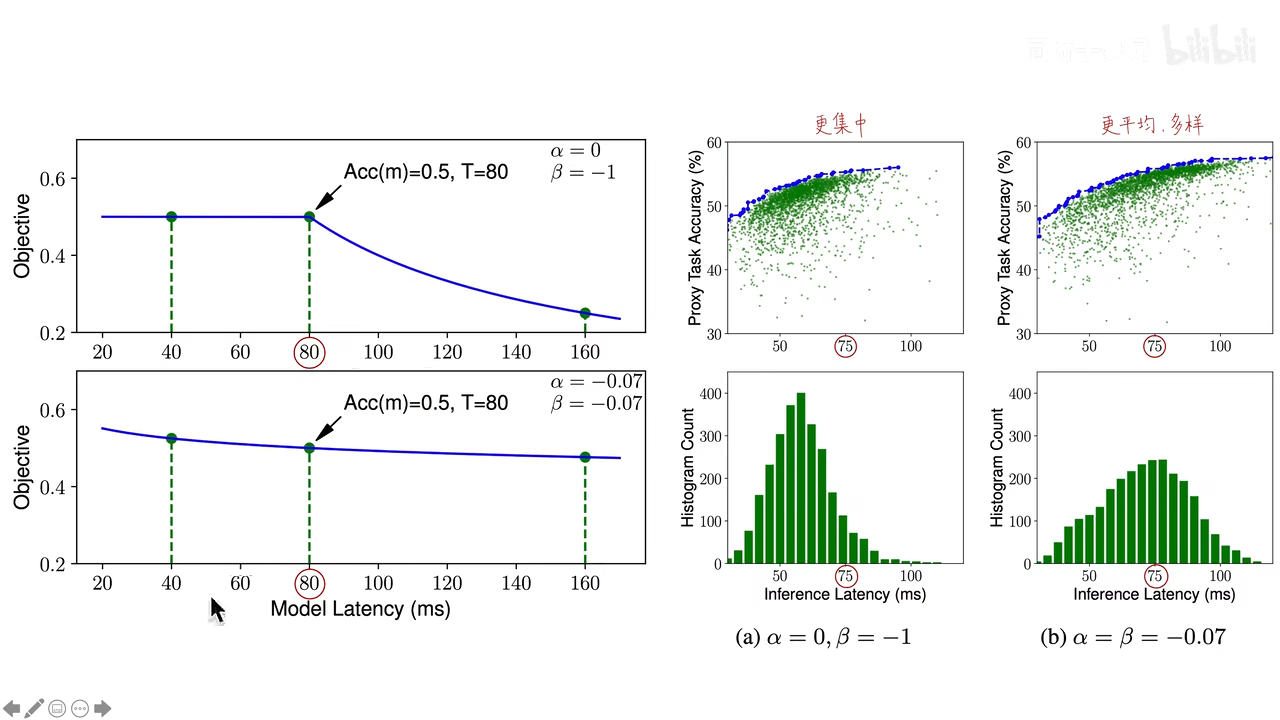
左图是一个横轴为LAT,纵轴为目标函数的折线图。
方案1(左上角的图),当α为0,β为-1的时候,T之前(w=0),目标函数等于ACC,LAT无影响;T之后(w=-1),对LAT继续增加,导致对目标函数有明显的惩罚。
方案2(左下角的图),当α、β均为-0.07的时候,目标函数是一条平滑的曲线。至于为什么选-0.07,这个也是有依据的:

也就是说,当模型精度提高5%的时候,允许推断时间增加为原来的2倍,利用这个关系算出来的α、β更有利于寻找模型的帕累托最优解。
右图是不同的方案下,生成模型的分布情况。
方案一导致生成的模型更集中,由于超过T就会受到明显惩罚,最终搜索结果更偏向于待在舒适区(不求有功但求无过,哈哈),即T之前。
方案二,生成的模型更加多样与平均,搜索的空间更大,可以搜到更多样的模型,更多的精度与速度组合的模型。
他们搜了3000个模型,总的来说就是财大气粗。
1.2. 分层分解的的NAS搜索空间
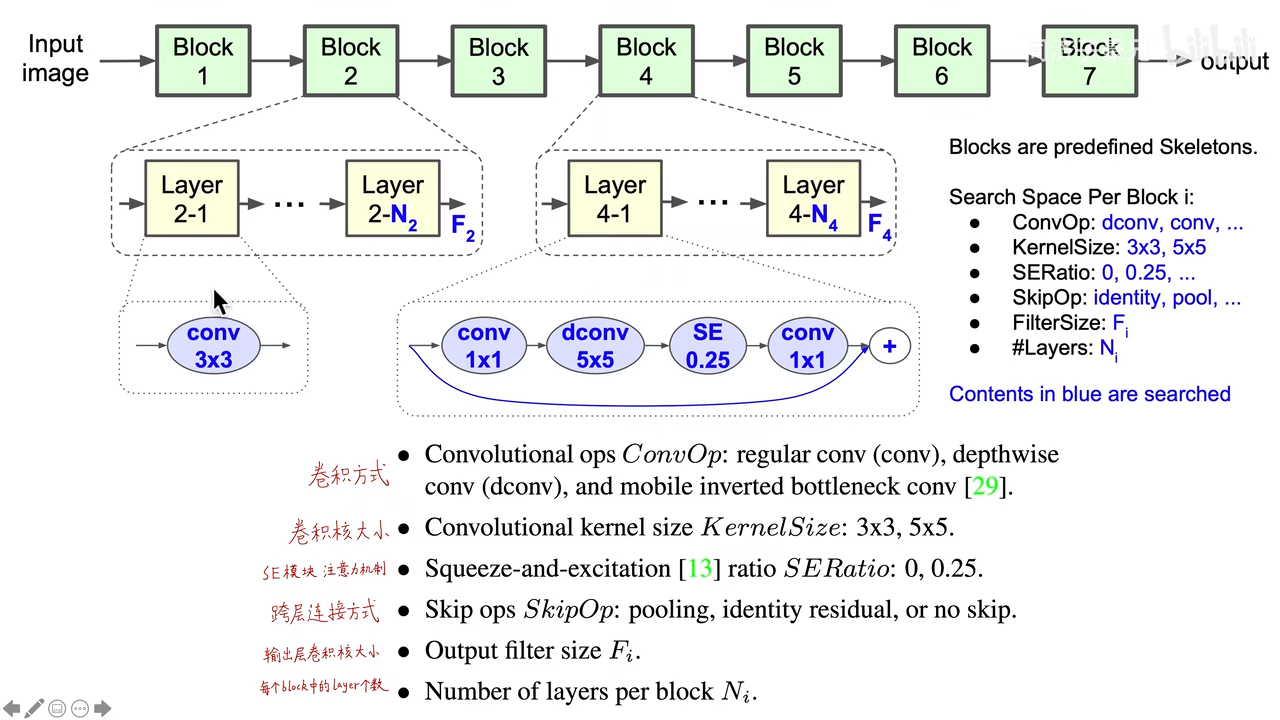
设计了一个分层搜索的架构,总共有7个Block,每个Block里面有N个Layer,每个Block里的Layer的结构都是一样的,这就让不同Block中的结构是不一样的,缩小了搜索空间的同时,保证了结构的多样性。
其中图中蓝色的表示都是人工智能强化学习模型搜索出来的,如每个Layer的结构(卷积的方式如传统卷积还是深度可分离卷积,卷积核的大小),是否加SE模块注意力机制seratio的大小,跨层连接方式,输出层卷积核大小,每个Block中的Layer个数。
2. 其他
2.1. 强化学习
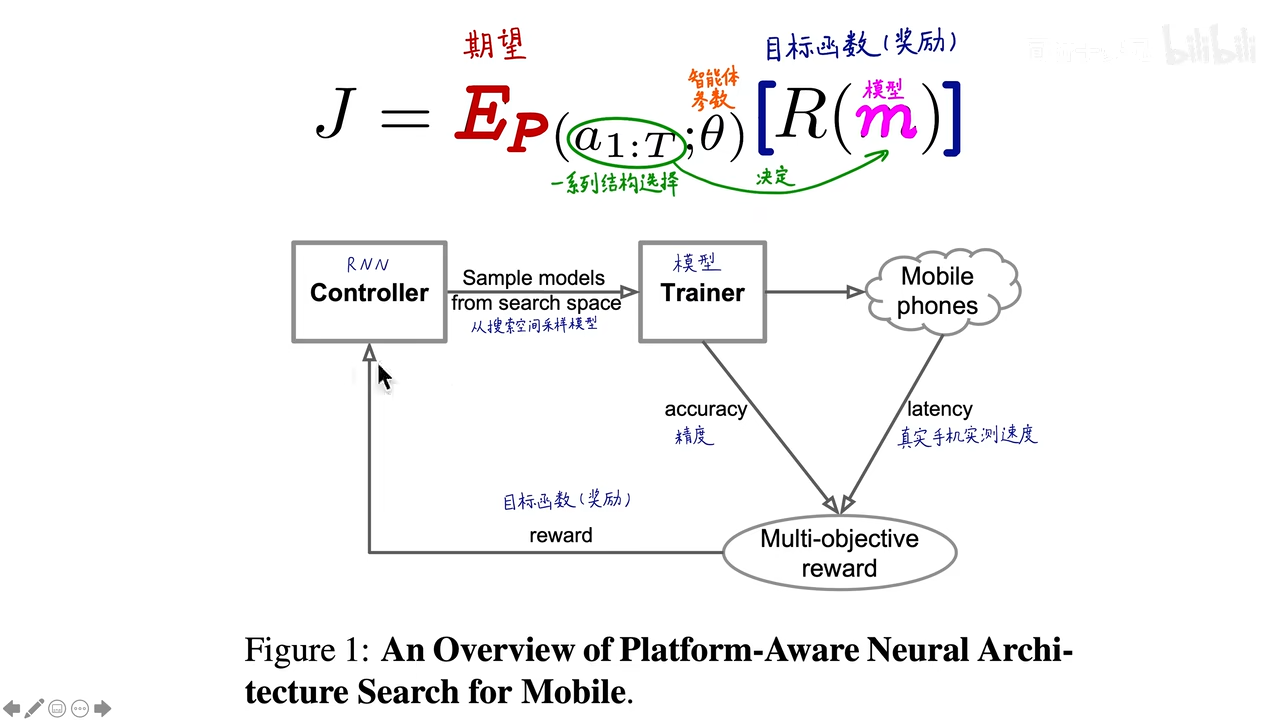
使用一个RNN作为智能代理,在搜索空间中采样模型,并进行模型训练,然后计算精度和在真实手机上的推断速度,算出目标优化函数,作为奖励反馈给RNN模型,RNN收到奖励后作出新一轮的反应,并采取新的行动策略……最终目标是目标函数最大化及期望值最大化。
2.2. 最终模型
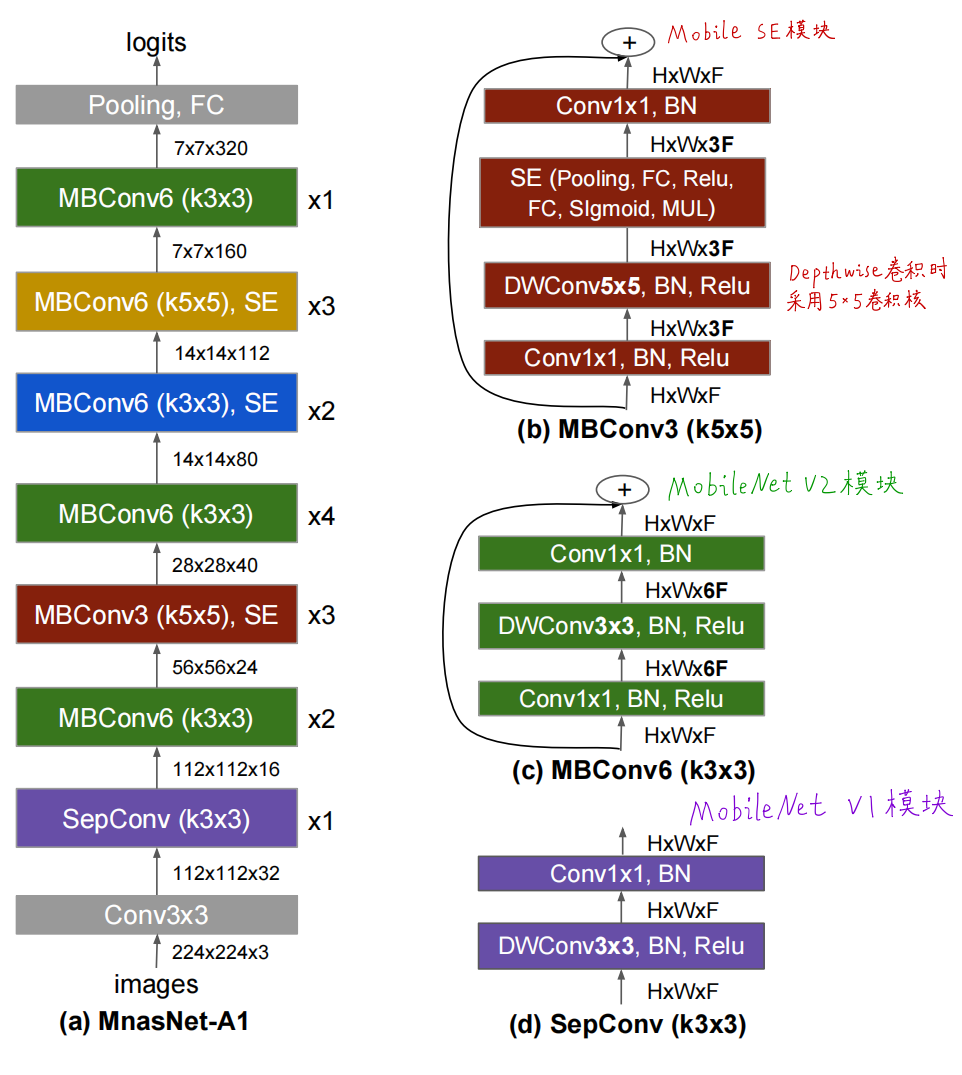
这是搜索出来的架构,紫色部分是MobileNetv1的深度可分离卷积模块,绿色的是MobileNetV2的逆残差模块,红色的是带注意力机制的mobile SE模块。比较有趣的是,AI自己搜出来的卷积核里有5x5的卷积,跟主流的人工设计的架构里基本是3x3的卷积核有点不一样,说到底深度学习还是一门试验科学,最终好的模型也是试出来的。
3.题外话
目标优化函数导致最终搜索出来的模型那块是比较有意思的,类比现实的组织,评绩点的时候,如果上头给你定了一个硬指标,保证硬指标就能够拿到平均分,没达到这个指标,则按照程度给予严厉的惩罚,则最终导致大多数人都会选择相对保守的执行策略,大家都更愿意停留在舒适区,宁愿少做也不愿犯错;如果虽然有一个硬指标,但是允许你在一定程度上犯错,则会有更多人选择更多样的执行策略,而且更愿意试错。
4. 参考
[1] 【精读AI论文】谷歌轻量化网络Mnasnet(神经架构搜索)
[3] 如何评价 Google 最新的模型 MnasNet?
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号