[轻量化网络]MobileNet V2学习笔记
![[轻量化网络]MobileNet V2学习笔记](https://img2022.cnblogs.com/blog/741682/202209/741682-20220922183001225-1309822696.png) 谷歌轻量化卷积神经网络MobileNet V2,用于移动端实时边缘计算部署。
构建先升维后降维,在降维时使用线性激活函数,带残差的Inverted bottleck模块,防止ReLU信息丢失。
在图像分类、目标检测、语义分割等任务上实现了网络轻量化、速度和准确度的权衡。
谷歌轻量化卷积神经网络MobileNet V2,用于移动端实时边缘计算部署。
构建先升维后降维,在降维时使用线性激活函数,带残差的Inverted bottleck模块,防止ReLU信息丢失。
在图像分类、目标检测、语义分割等任务上实现了网络轻量化、速度和准确度的权衡。
1. V1的问题
V1的核心是使用深度可分离卷积去替代普通的卷积核,对输入进行特征提取,在性能不下滑太多的前提下,大大减少参数量和计算量。但是在实际训练中,很容易把深度卷积部分训练废掉,造成深度卷积的卷积核中有不少的0值。
因为V1的结构中并没有引入残差连接,容易在模型训练反向传播的时候,梯度消失或者爆炸。
另外一个是RELU函数的锅,流形分布在映射到另外一个维度空间之后,再进行RELU激活,如果新的空间维度太小,会造成信息的损失。这个在设计直觉中会详细说。
2. V2的设计直觉
关于流形,流形学习的观点是认为,我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示[1]。V2认为,在图片的高维feature map中包含了流形,它可以通过降维嵌入到一个低维的子空间中。
在一般的卷积操作中,激活一般使用RELU函数,为了验证RELU函数对不同维度的数据的损失程度,论文用一个例子进行说明:

如上图所示,Input是二维空间中的n个点组成的螺旋线X2 * n,经过随机矩阵Tm * 2映射到m维并RELU激活:
ym*n = RELU(Tm * 2 * X2 * n)
再通过T矩阵的广义逆矩阵 T2*m-1 将ymxn映射回二维空间
X'2*n = T2*m-1 * ym*n
上图的就是各个维度m(取2,3,5,15和30)下的Output。这个例子为了说明,在低维度下使用RELU进行激活,会造成信息的丢失,在扩充出足够多的冗余维度时,RELU能够保存流形的原始信息。
进一步的思考:
- 如果不想让RELU因“抹零”丢失信息,则应该让输入(也就是论文中的mainfold of interest)都为正值。
- 但是如果让输入都为正值,则RELU就变成了恒等映射(线性变换)。
- 根据万能近似定理,神经网络需要线性和非线性激活函数才能够模拟和逼近其他函数。
因此需要扩充出冗余的维度再RELU,这样既防止信息丢失,也发挥RELU的非线性,至于低维度的feature map则通过线性变换进行激活,这些直觉和理论就是V2的设计基础,也就是
带线性瓶颈层的逆残差结构——Inverted Residuals with Linear Bottlenecks。
3. V2的核心结构
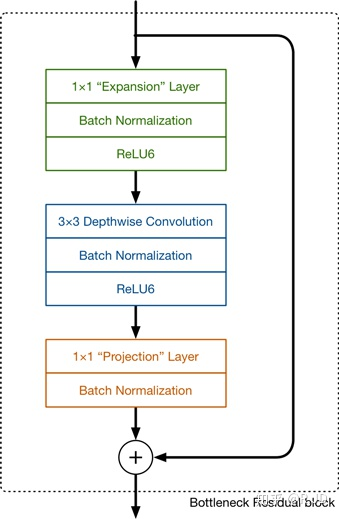
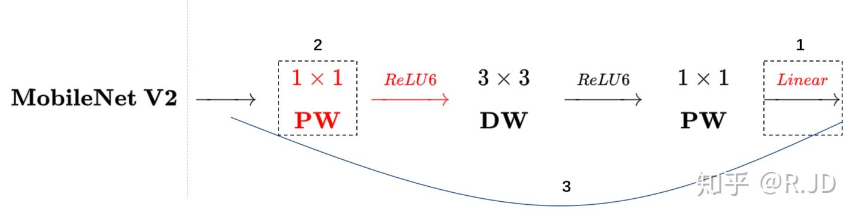
逆残差模块是V2的主要组成结构,先使用1x1卷积,对输入的feature map进行升维,一般为倍数t=6,然后经过一个BN+RELU6进行激活,然后使用深度卷积,再接一个BN+RELU6,最后通过1x1卷积降维,后面接一个线性变换激活函数。
与标准残差模块相对比,标准的残差模块是先降维再升维,通道多的tensor进行短接;逆残差模块是先升维再降维,通道数少的tensor进行短接,如下图所示:
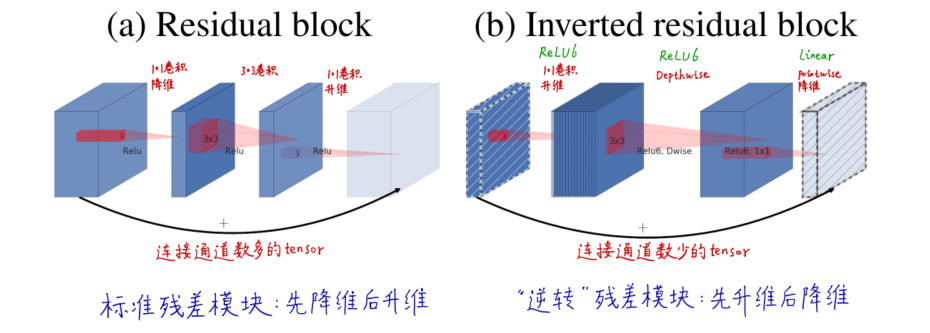
而最后的激活层也叫linear bottleneck。
和V1的结构对比:
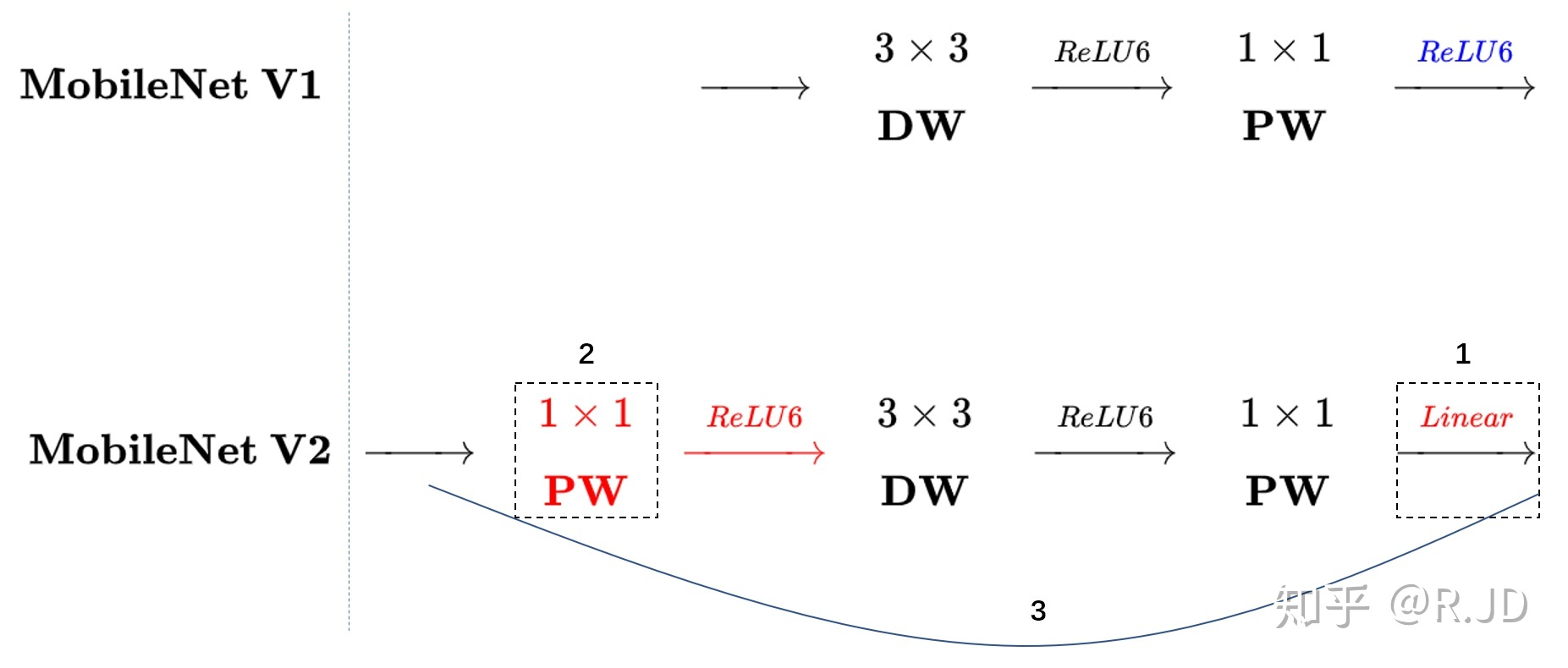
4. V2与V1对比

可以看到,虽然V2的层数比V1的要多很多,但是FLOPs,参数以及CPU耗时都是比V1要好的。
但是,很多人在实际使用中,却发现V1要比V2的效果要好,迷。
5. 其他
5.1. 为什么使用RELU6而不是RELU
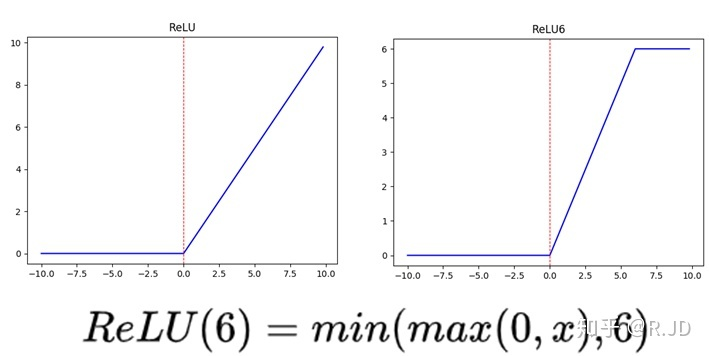
可以看到RELU和RELU6的区别在于是否将大于6的数截断为6,RELU6可以在训练阶段将权重都限制在一个比较小的范围内,这样在低精度的边缘设备上也能够稳定的运行(鲁棒性)。
6. 参考
[1] 深度学习之:什么是流形(manifold)?流形空间,流形学习
[2] 轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3
[3] 精读AI论文】谷歌轻量化网络MobileNet V2(附MobileNetV2代码讲解)
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号