别再用CSV了,更高效的Python文件存储方案
CSV无可厚非的是一种良好的通用文件存储方式,几乎任何一款工具或者编程语言都能对其进行读写,但是当文件特别大的时候,CSV这种存储方式就会变得十分缓慢且低效。本文将介绍几种在Python中能够代替CSV这种格式的其他文件格式,并对比每种文件存储的时间与大小。
先说结论,parquet是最好的文件存储格式,具体对比见下文。
生成随机数据
导入依赖
import random
import string
import pickle
# 以下需要自行安装
import numpy as np
import pandas as pd
import tables
import pyarrow as pa
import pyarrow.feather as feather
import pyarrow.parquet as pq
import fastparquet as fp
生成随机数据
这里使用pandas的dataframe来存储数据
# 变量定义
row_num = int(1e7)
col_num = 5
str_len = 4
str_nunique = 10 # 字符串组合数量
# 生成随机数
int_matrix = np.random.randint(0, 100, size=(row_num, col_num))
df = pd.DataFrame(int_matrix, columns=['int_%d' % i for i in range(col_num)])
float_matrix = np.random.rand(row_num, col_num)
df = pd.concat(
(df, pd.DataFrame(float_matrix, columns=['float_%d' % i for i in range(col_num)])), axis=1)
str_list = [''.join(random.sample(string.ascii_letters, str_len))
for _ in range(str_nunique)]
for i in range(col_num):
sr = pd.Series(str_list*(row_num//str_nunique)
).sample(frac=1, random_state=i)
df['str_%d' % i] = sr
print(df.info())
生成100w行数据,其中整型,浮点型和字符串各5列,数据大小在内存里大概为1GB+
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000000 entries, 0 to 9999999
Data columns (total 15 columns):
# Column Dtype
--- ------ -----
0 int_0 int64
1 int_1 int64
2 int_2 int64
3 int_3 int64
4 int_4 int64
5 float_0 float64
6 float_1 float64
7 float_2 float64
8 float_3 float64
9 float_4 float64
10 str_0 object
11 str_1 object
12 str_2 object
13 str_3 object
14 str_4 object
dtypes: float64(5), int64(5), object(5)
memory usage: 1.1+ GB
保存文件
csv
CSV的保存方式很简单,直接使用pandas自带的to_csv() 方法即可
# 写入
df.to_csv('./df_csv.csv', index=False)
# 读取
df = pd.read_csv('./df_csv.csv')
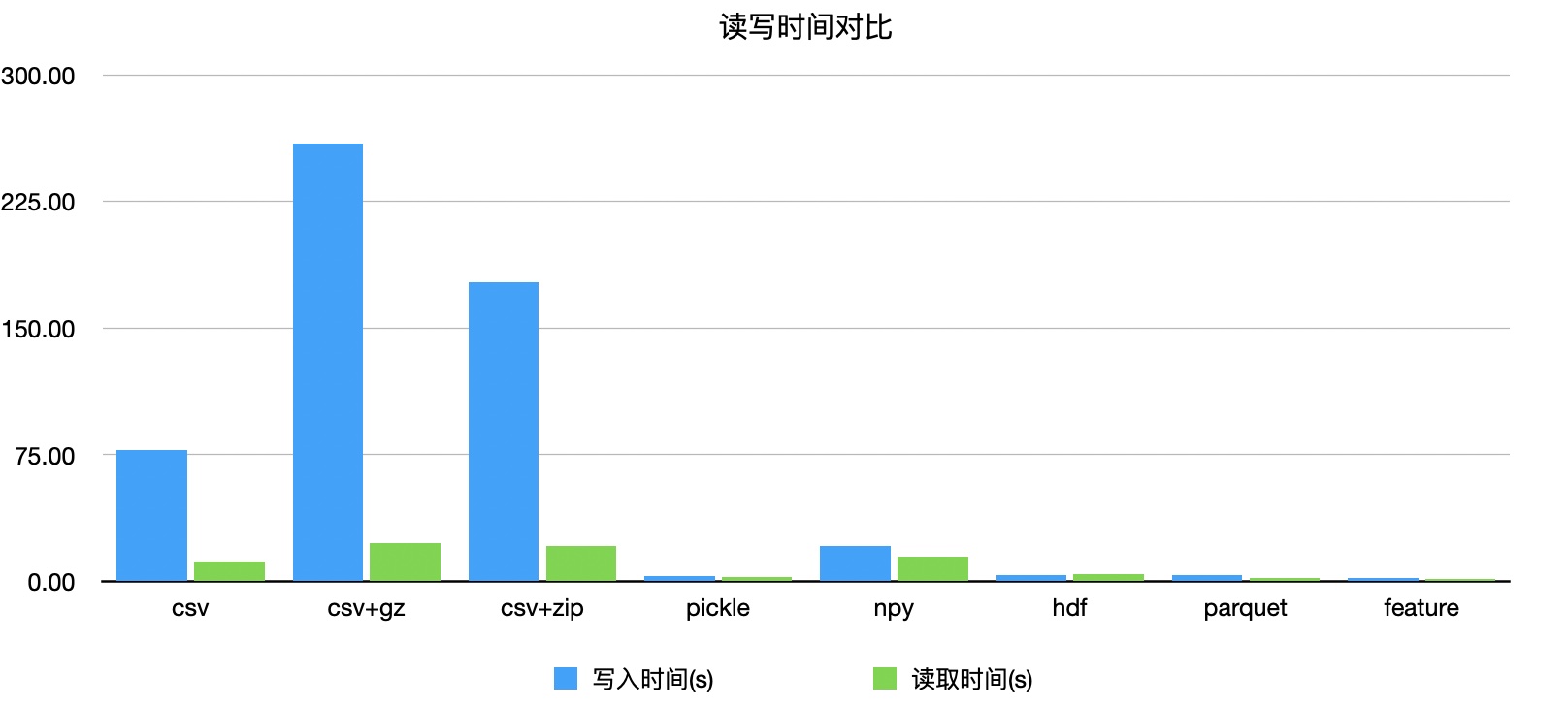
写入时间花费:78 s
读取时间花费:11.8 s
所需存储空间:1.3GB
csv + gz
基于自带的压缩方法,对保存的csv文件使用gzip算法进行压缩
# 写入
df.to_csv('./df_csv.csv.gz', index=False, compression='gzip')
# 读取
df = pd.read_csv('./df_csv.csv.gz', compression='gzip')
写入时间花费:259 s
读取时间花费:22.8 s
所需存储空间:508M
csv + zip
基于自带的压缩方法,对保存的csv文件使用zip算法进行压缩
# 写入
df.to_csv('./df_csv.csv.zip', index=False, compression='zip')
# 读取
df = pd.read_csv('./df_csv.csv.zip', compression='zip')
写入时间花费:177 s
读取时间花费:20.7 s
所需存储空间:511M
pkl
pkl文件需要用到built-in的pickle包
# 写入
with open('./df_pkl.pkl', 'wb') as f:
pickle.dump(df, f)
# 读取
with open('./df_pkl.pkl', 'rb') as f:
df = pickle.load(f)
写入时间花费:2.89 s
读取时间花费:2.61 s
所需存储空间:858M
npy
npy是numpy自带的一种保存格式,唯一的缺点是只能保存numpy的格式,所以需要将pandas先转成numpy才行,为了公平,这里我们会算上转换的时间
# 写入
with open('./df_npy.npy', "wb") as f:
np.save(f, arr=df.values)
# 读取
with open('./df_npy.npy', "rb") as f:
df_array = np.load(f, allow_pickle=True)
df = pd.DataFrame(df_array)
写入时间花费:21 s
读取时间花费:14.8 s
所需存储空间:620M
hdf
层次数据格式(HDF)是自描述的,允许应用程序在没有外部信息的情况下解释文件的结构和内容。一个HDF文件可以包含一系列相关对象,这些对象可以作为一个组或单个对象进行访问。
这里将使用pandas自带的to_hdf()方法,该方法默认是用的HDF5格式
# 写入
df.to_hdf('df_hdf.h5', key='df')
# 读取
df = pd.read_hdf('df_hdf.h5', key='df')
写入时间花费:3.96 s
读取时间花费:4.13 s
所需存储空间:1.5G
已废弃 msgpack
pandas支持msgpack格式的对象序列化。他是一种轻量级可移植的二进制格式,同二进制的JSON类似,具有高效的空间利用率以及不错的写入(序列化)和读取(反序列化)性能。
从0.25版本开始,不推荐使用msgpack格式,并且之后的版本也将删除它。推荐使用pyarrow对pandas对象进行在线的转换。
read_msgpack() (opens new window)仅在pandas的0.20.3版本及以下版本兼容。
parquet
Apache Parquet为数据帧提供了分区的二进制柱状序列化。它的设计目的是使数据帧的读写效率,并使数据共享跨数据分析语言容易。Parquet可以使用多种压缩技术来尽可能地缩小文件大小,同时仍然保持良好的读取性能。
这里需要使用到pyarrow里面的方法来进行操作
# 写入
pq.write_table(pa.Table.from_pandas(df), 'df_parquet.parquet')
# 读取
df = pq.read_table('df_parquet.parquet').to_pandas()
写入时间花费:3.47 s
读取时间花费:1.85 s
所需存储空间:426M
feature
Feather是一种可移植的文件格式,用于存储内部使用Arrow IPC格式的Arrow表或数据帧(来自Python或R等语言)。Feather是在Arrow项目早期创建的,作为Python和R的快速、语言无关的数据帧存储概念的证明。
这里需要使用到pyarrow里面的方法来进行操作
# 写入
feather.write_feather(df, 'df_feather.feather')
# 读取
df = feather.read_feather('df_feather.feather')
写入时间花费:1.9 s
读取时间花费:1.52 s
所需存储空间:715M
总结
对比表格
| 文件类型 | 写入时间(s) | 读取时间(s) | 存储空间(MB) |
|---|---|---|---|
| csv | 78.00 | 11.80 | 1,300 |
| csv+gz | 259.00 | 22.80 | 508 |
| csv+zip | 177.00 | 20.70 | 511 |
| pickle | 2.89 | 2.61 | 858 |
| npy | 21.00 | 14.80 | 620 |
| hdf | 3.96 | 4.13 | 1,500 |
| parquet | 3.47 | 1.85 | 426 |
| feature | 1.90 | 1.52 | 715 |
时间对比
空间对比
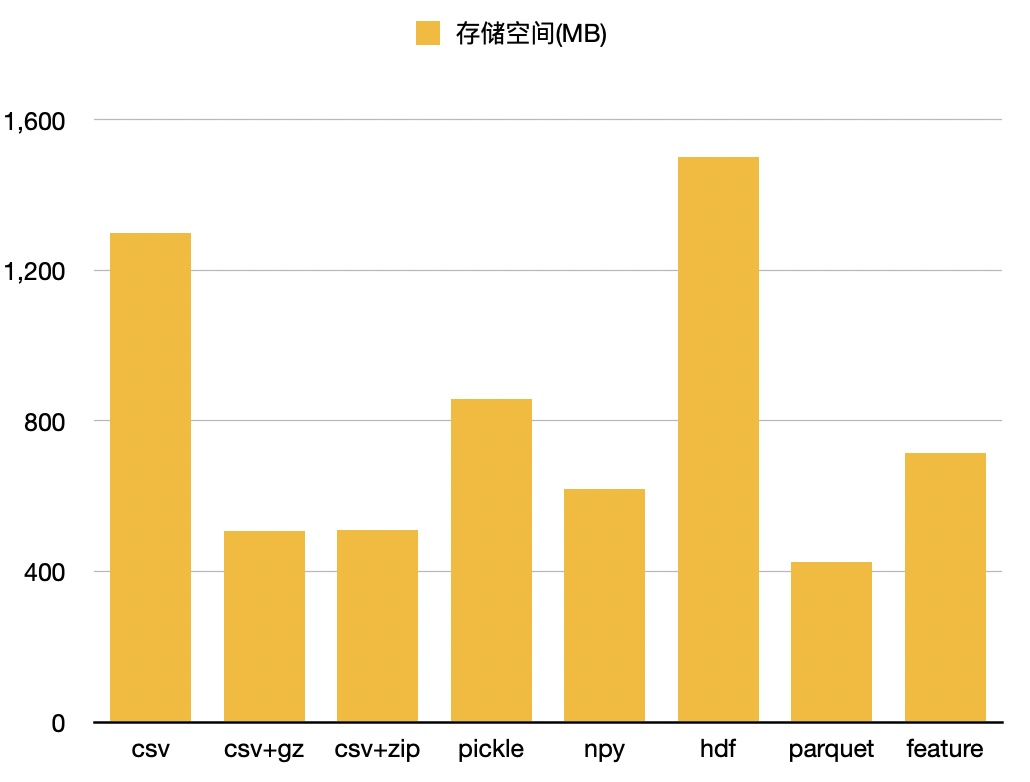
可以看出parquet会是一个保存文件的最好选择,虽然时间上比feature略慢一点,但空间上有着更大的优势。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号