
EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考
在这篇文章中, 将讨论EDW on Hadoop 有哪些备选方案, 以及我个人的倾向性, 最后是建构方法. 欢迎转载, 但必须注明原贴(刘忠武, http://www.cnblogs.com/harrychinese/p/edw_on_hadoop.html).
数据仓库发展已经有二十多年了, 我们先看看数据仓库发展的趋势:
在数据规模小的时候, 采用单节点RDBMS作为存储和执行引擎, 比如Oracle/PostgreSQL/MySQL都行;
当数据规模大了后, 或者时间窗口很紧时, 多采用MPP的解决方案, 比如Teradata/Exedata, 这些MPP多是一体机, 实施成本比较高, 满配后如要做扩容, 哪怕是很小的扩容, 都需投入大量资金, 显得非常不划算. 现在有的互联网企业的数据量非常之大, 即使是采用顶配的一体机, 往往也撑不住.
最近几年, SQL on Hadoop技术发展很快, 尤其是Hive被大量采用之后, 开源社区和商业数据仓库厂商都意识到EDW on Hadoop是未来的方向. 下图是一些现在比较活跃的方案,
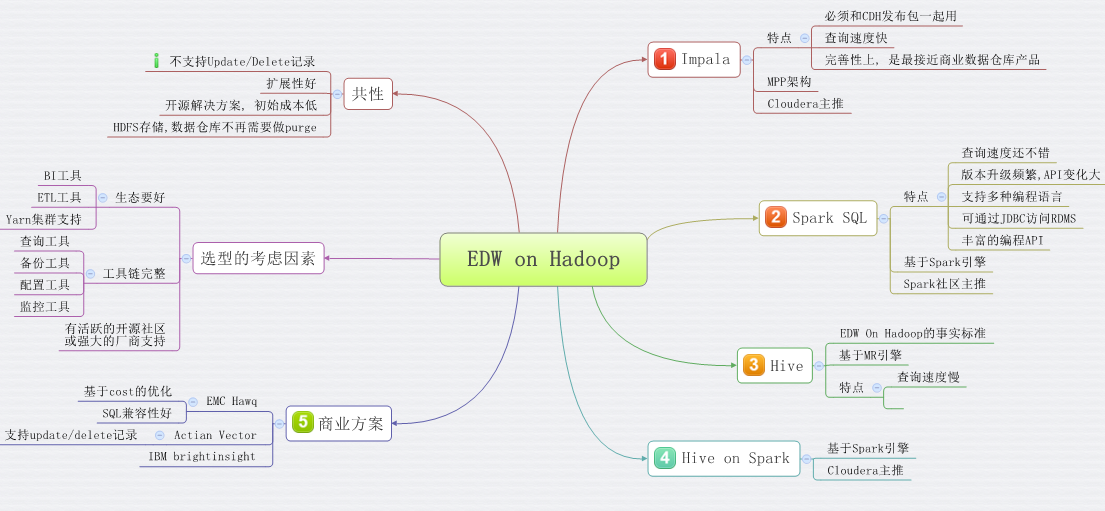
在开源方案中, 我比较看好Impala和Spark SQL, 尤其是Spark SQL. 原因有:
1.使用Spark SQL建构EDW相对容易些: 数据仓库项目中, ETL是非常重要的一环, Spark作为一个高效的计算框架, 借助RDD算子或者SQL写法很胜任ETL的Transform, Extract可以借助Sqoop.
2. Spark SQL性能不错: 在最近1.3版Spark SQL性能已经很不错.
3. Spark, one stack to rule them all: 对于企业而言, spark会给你更多, 将来MLlib应该能替代SAS. 对于开发者而言, 只需要学一门, 就能做好多方面的事情.这有点像Java语言当初的口号,一次编译,到处运行。
4. 社区活跃, 版本迭代快(版本这事, 是优点也是缺点)
Spark SQL数据仓库架构设计
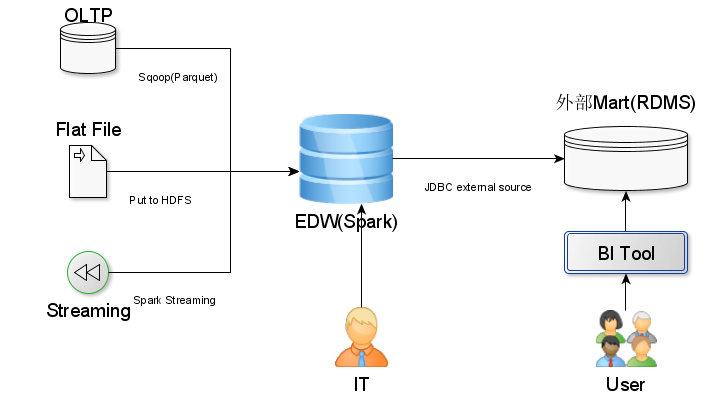
两张架构图, 第一张是展现EDW的位置, Input有哪些, Output有哪些. Input展现的已经很明显了, 对于EDW输出, 目前传统的BI工具还不支持Spark SQL, 所以我们设计一个外部RDBMS数据集市, Spark数据仓库负责推数据到该数据集市, BI工具直接访问这个数据集市.
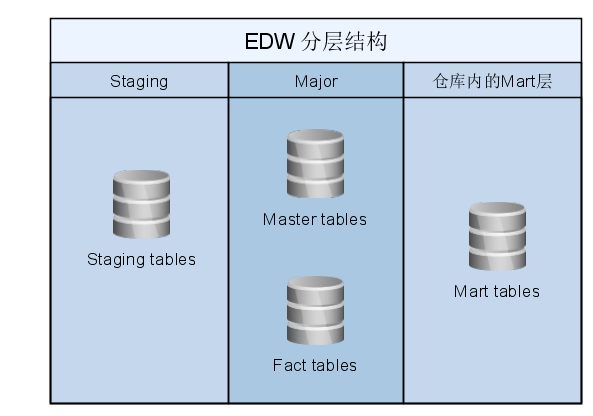
和传统的数据仓库一样, 为了治理需要, 也需要对于Spark EDW分层, 一般三层就足够了.
另外, 我们可考虑设计一个active archive区, 专门归档OLTP数据.
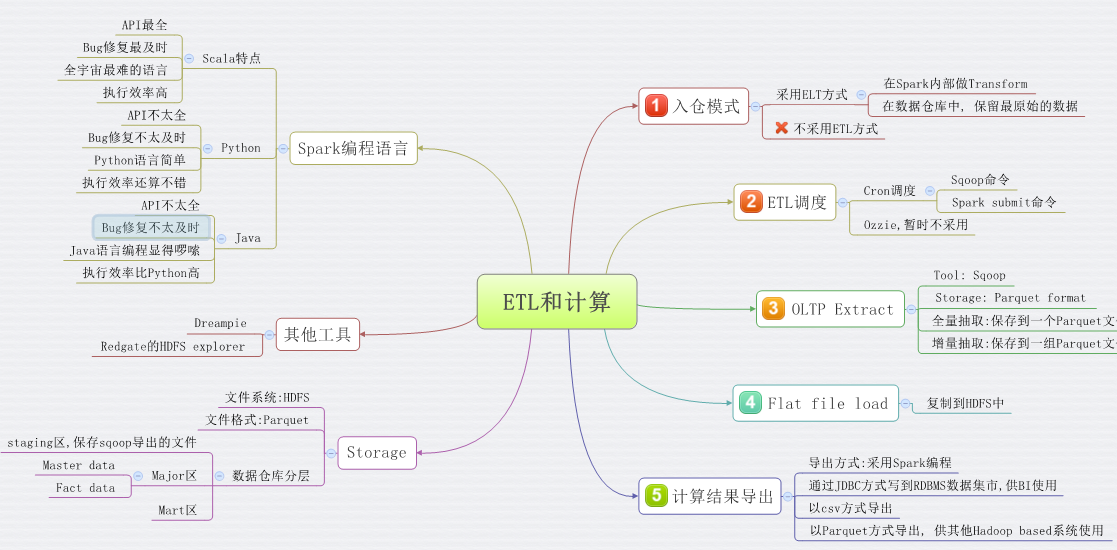
ETL设计思想
每个EDW, ETL工作量都很大, 而且直接影响EDW使用效果.
从大的设计架构看, 推荐采用ELT, 而不是ETL模式. 为什么? 传统ETL最大的好处是, 可以减轻EDW的压力. 对于Hadoop基础上的数据仓库, 但采用ETL的这个好处, 就不明显了, EDW压力可以通过横向扩展, 很容易解决.
对于Extract, 可用Sqoop完成卸载, 推荐采用Parquet格式, 这样Spark SQL可以直接mount这些数据, 也就完整了Load.
Transform在Spark上完成, Spark编程接口非常丰富, 支持Scala/Python/Java编程语言.
至于到底采用哪种开发语言, 我的看法是, 优先采用Python, 无它, Python代码最易读了. 但我们需要清楚的是, Scala API总是最全的, Java 版API次之, Python版的API最少, 另外, API若有bug的话, Python版修复的进度也是最晚的. 但好在Python API现在已经很完善了. 在Spark 1.3版中, Python 的dataFrame缺少createJDBCTable() 编程接口.
简单总结一下
Spark数据仓库的能承担的作用有:
1. 产生BI报表数据
2. 做数据挖掘
3. 作为Active archive
另外, 还能节省不少开销: 省掉了一体机, 省掉了ETL工具, 省掉了SAS分析软件, 省掉高端的存储.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律