人口分析案例
需求:
- 导入文件,查看原始数据
- 将人口数据和各州简称数据进行合并
- 将合并的数据中重复的abbreviation列进行删除
- 查看存在缺失数据的列
- 找到有哪些state/region使得state的值为NaN,进行去重操作
- 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
- 合并各州面积数据areas
- 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
- 去除含有缺失数据的行
- 找出2010年的全民人口数据
- 计算各州的人口密度
- 排序,并找出人口密度最高的五个州 df.sort_values()
abb = pd.read_csv('./data/state-abbrevs.csv') pop = pd.read_csv('./data/state-population.csv') area = pd.read_csv('./data/state-areas.csv')
#将人口数据和各州简称数据进行合并 display(abb.head(1),pop.head(1)) abb_pop = pd.merge(abb,pop,left_on='abbreviation',right_on='state/region',how='outer') abb_pop.head()
#将合并的数据中重复的abbreviation列进行删除 abb_pop.drop(labels='abbreviation',axis=1,inplace=True) abb_pop.head() state state/region ages year population 0 Alabama AL under18 2012 1117489.0 1 Alabama AL total 2012 4817528.0 2 Alabama AL under18 2010 1130966.0 3 Alabama AL total 2010 4785570.0 4 Alabama AL under18 2011 1125763.0
#查看存在缺失数据的列 abb_pop.isnull().any(axis=0) state True state/region False ages False year False population True dtype: bool
#找到有哪些state/region使得state的值为NaN,进行去重操作 #1.检测state列中的空值 abb_pop['state'].isnull() #2.将1的返回值作用的state_region这一列中 abb_pop['state/region'][abb_pop['state'].isnull()] #3.去重 abb_pop['state/region'][abb_pop['state'].isnull()].unique()
#为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN abb_pop['state/region'] == 'USA' # 将控制覆盖成United State abb_pop.loc[indexs,'state'] = 'United State' pr_index = abb_pop['state'][abb_pop['state/region'] == 'PR'].index abb_pop.loc[pr_index,'state'] = 'PPPRRR'
#合并各州面积数据areas 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行 去除含有缺失数据的行 找出2010年的全民人口数据 计算各州的人口密度 排序,并找出人口密度最高的五个州 df.sort_values() #合并各州面积数据areas abb_pop_area = pd.merge(abb_pop,area,how='outer') abb_pop_area.head() state state/region ages year population area (sq. mi) 0 Alabama AL under18 2012.0 1117489.0 52423.0 1 Alabama AL total 2012.0 4817528.0 52423.0 2 Alabama AL under18 2010.0 1130966.0 52423.0 3 Alabama AL total 2010.0 4785570.0 52423.0 4 Alabama AL under18 2011.0 1125763.0 52423.0 #我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行 abb_pop_area['area (sq. mi)'].isnull() a_index = abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index #去除含有缺失数据的行 abb_pop_area.drop(labels=a_index,axis=0,inplace=True) #找出2010年的全民人口数据 abb_pop_area.query('year == 2010 & ages == "total"')
state state/region ages year population area (sq. mi) 3 Alabama AL total 2010.0 4785570.0 52423.0 91 Alaska AK total 2010.0 713868.0 656425.0 101 Arizona AZ total 2010.0 6408790.0 114006.0 189 Arkansas AR total 2010.0 2922280.0 53182.0 197 California CA total 2010.0 37333601.0 163707.0 283 Colorado CO total 2010.0 5048196.0 104100.0 293 Connecticut CT total 2010.0 3579210.0 5544.0 379 Delaware DE total 2010.0 899711.0 1954.0 389 District of Columbia DC total 2010.0 605125.0 68.0 475 Florida FL total 2010.0 18846054.0 65758.0 485 Georgia GA total 2010.0 9713248.0 59441.0 570 Hawaii HI total 2010.0 1363731.0 10932.0 #计算各州的人口密度 abb_pop_area['midu'] = abb_pop_area['population'] / abb_pop_area['area (sq. mi)'] abb_pop_area.head() state state/region ages year population area (sq. mi) midu 0 Alabama AL under18 2012.0 1117489.0 52423.0 21.316769 1 Alabama AL total 2012.0 4817528.0 52423.0 91.897221 2 Alabama AL under18 2010.0 1130966.0 52423.0 21.573851 3 Alabama AL total 2010.0 4785570.0 52423.0 91.287603 4 Alabama AL under18 2011.0 1125763.0 52423.0 21.474601 #排序,并找出人口密度最高的五个州 df.sort_values() abb_pop_area.sort_values(by='midu',axis=0,ascending=False).head() state state/region ages year population area (sq. mi) midu 391 District of Columbia DC total 2013.0 646449.0 68.0 9506.602941 385 District of Columbia DC total 2012.0 633427.0 68.0 9315.102941 387 District of Columbia DC total 2011.0 619624.0 68.0 9112.117647 431 District of Columbia DC total 1990.0 605321.0 68.0 8901.779412 389 District of Columbia DC total 2010.0 605125.0 68.0 8898.897059
美国2012年总统候选人政治献金数据分析
需求:
- 读取文件usa_election.txt
- 查看文件样式及基本信息
- 【知识点】使用map函数+字典,新建一列各个候选人所在党派party
- 使用np.unique()函数查看colums:party这一列中有哪些元素
- 使用value_counts()函数,统计party列中各个元素出现次数,value_counts()是Series中的,无参,返回一个带有每个元素出现次数的Series
- 【知识点】使用groupby()函数,查看各个党派收到的政治献金总数contb_receipt_amt
- 查看具体每天各个党派收到的政治献金总数contb_receipt_amt 。使用groupby([多个分组参数])
- 将表中日期格式转换为'yyyy-mm-dd'。日期格式,通过函数加map方式进行转换
- 查看老兵(捐献者职业)DISABLED VETERAN主要支持谁 :查看老兵们捐赠给谁的钱最多
- 找出候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额 .通过query("查询条件来查找捐献人职业")
# 方便操作,将月份和参选人以及所在政党进行定义 months = {'JAN' : 1, 'FEB' : 2, 'MAR' : 3, 'APR' : 4, 'MAY' : 5, 'JUN' : 6, 'JUL' : 7, 'AUG' : 8, 'SEP' : 9, 'OCT': 10, 'NOV': 11, 'DEC' : 12} of_interest = ['Obama, Barack', 'Romney, Mitt', 'Santorum, Rick', 'Paul, Ron', 'Gingrich, Newt'] parties = { 'Bachmann, Michelle': 'Republican', 'Romney, Mitt': 'Republican', 'Obama, Barack': 'Democrat', "Roemer, Charles E. 'Buddy' III": 'Reform', 'Pawlenty, Timothy': 'Republican', 'Johnson, Gary Earl': 'Libertarian', 'Paul, Ron': 'Republican', 'Santorum, Rick': 'Republican', 'Cain, Herman': 'Republican', 'Gingrich, Newt': 'Republican', 'McCotter, Thaddeus G': 'Republican', 'Huntsman, Jon': 'Republican', 'Perry, Rick': 'Republican' }
#使用map函数+字典,新建一列各个候选人所在党派party table['party'] = table['cand_nm'].map(parties) table.head() cmte_id cand_id cand_nm contbr_nm contbr_city contbr_st contbr_zip contbr_employer contbr_occupation contb_receipt_amt contb_receipt_dt receipt_desc memo_cd memo_text form_tp file_num party 0 C00410118 P20002978 Bachmann, Michelle HARVEY, WILLIAM MOBILE AL 3.6601e+08 RETIRED RETIRED 250.0 20-JUN-11 NaN NaN NaN SA17A 736166 Republican 1 C00410118 P20002978 Bachmann, Michelle HARVEY, WILLIAM MOBILE AL 3.6601e+08 RETIRED RETIRED 50.0 23-JUN-11 NaN NaN NaN SA17A 736166 Republican 2 C00410118 P20002978 Bachmann, Michelle SMITH, LANIER LANETT AL 3.68633e+08 INFORMATION REQUESTED INFORMATION REQUESTED 250.0 05-JUL-11 NaN NaN NaN SA17A 749073 Republican 3 C00410118 P20002978 Bachmann, Michelle BLEVINS, DARONDA PIGGOTT AR 7.24548e+08 NONE RETIRED 250.0 01-AUG-11 NaN NaN NaN SA17A 749073 Republican 4 C00410118 P20002978 Bachmann, Michelle WARDENBURG, HAROLD HOT SPRINGS NATION AR 7.19016e+08 NONE RETIRED 300.0 20-JUN-11 NaN NaN NaN SA17A 736166 Republican
#party这一列中有哪些元素 table['party'].unique() array(['Republican', 'Democrat', 'Reform', 'Libertarian'], dtype=object)
#使用value_counts()函数,统计party列中各个元素出现次数,value_counts()是Series中的,无参,返回一个带有每个元素出现次数的Series table['party'].value_counts() Democrat 292400 Republican 237575 Reform 5364 Libertarian 702 Name: party, dtype: int64
#使用groupby()函数,查看各个党派收到的政治献金总数contb_receipt_amt table.groupby(by='party')['contb_receipt_amt'].sum() party Democrat 8.105758e+07 Libertarian 4.132769e+05 Reform 3.390338e+05 Republican 1.192255e+08 Name: contb_receipt_amt, dtype: float64
#查看具体每天各个党派收到的政治献金总数contb_receipt_amt 。使用groupby([多个分组参数]) table.groupby(by=['party','contb_receipt_dt'])['contb_receipt_amt'].sum() party contb_receipt_dt Democrat 01-AUG-11 175281.00 01-DEC-11 651532.82 01-JAN-12 58098.80 01-JUL-11 165961.00 01-JUN-11 145459.00 ..........................................................
def trasform_date(d): day,month,year = d.split('-') month = months[month] return "20"+year+'-'+str(month)+'-'+day #将表中日期格式转换为'yyyy-mm-dd'。日期格式,通过函数加map方式进行转换 table['contb_receipt_dt'] = table['contb_receipt_dt'].apply(trasform_date)
#查看老兵(捐献者职业)DISABLED VETERAN主要支持谁 :查看老兵们捐赠给谁的钱最多 table['contbr_occupation'] == 'DISABLED VETERAN' old_bing_df = table.loc[table['contbr_occupation'] == 'DISABLED VETERAN'] old_bing_df.groupby(by='cand_nm')['contb_receipt_amt'].sum() cand_nm Cain, Herman 300.00 Obama, Barack 4205.00 Paul, Ron 2425.49 Santorum, Rick 250.00 Name: contb_receipt_amt, dtype: float64
#找出候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额 .通过query("查询条件来查找捐献人职业") table.query('contb_receipt_amt == 1944042.43')
城市气候与海洋的关系研究
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from pylab import mpl mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
导入各个海滨城市的数据
ferrara1 = pd.read_csv('./ferrara_150715.csv') ferrara2 = pd.read_csv('./ferrara_250715.csv') ferrara3 = pd.read_csv('./ferrara_270615.csv') ferrara=pd.concat([ferrara1,ferrara1,ferrara1],ignore_index=True) torino1 = pd.read_csv('./torino_150715.csv') torino2 = pd.read_csv('./torino_250715.csv') torino3 = pd.read_csv('./torino_270615.csv') torino = pd.concat([torino1,torino2,torino3],ignore_index=True) mantova1 = pd.read_csv('./mantova_150715.csv') mantova2 = pd.read_csv('./mantova_250715.csv') mantova3 = pd.read_csv('./mantova_270615.csv') mantova = pd.concat([mantova1,mantova2,mantova3],ignore_index=True) milano1 = pd.read_csv('./milano_150715.csv') milano2 = pd.read_csv('./milano_250715.csv') milano3 = pd.read_csv('./milano_270615.csv') milano = pd.concat([milano1,milano2,milano3],ignore_index=True) ravenna1 = pd.read_csv('./ravenna_150715.csv') ravenna2 = pd.read_csv('./ravenna_250715.csv') ravenna3 = pd.read_csv('./ravenna_270615.csv') ravenna = pd.concat([ravenna1,ravenna2,ravenna3],ignore_index=True) asti1 = pd.read_csv('./asti_150715.csv') asti2 = pd.read_csv('./asti_250715.csv') asti3 = pd.read_csv('./asti_270615.csv') asti = pd.concat([asti1,asti2,asti3],ignore_index=True) bologna1 = pd.read_csv('./bologna_150715.csv') bologna2 = pd.read_csv('./bologna_250715.csv') bologna3 = pd.read_csv('./bologna_270615.csv') bologna = pd.concat([bologna1,bologna2,bologna3],ignore_index=True) piacenza1 = pd.read_csv('./piacenza_150715.csv') piacenza2 = pd.read_csv('./piacenza_250715.csv') piacenza3 = pd.read_csv('./piacenza_270615.csv') piacenza = pd.concat([piacenza1,piacenza2,piacenza3],ignore_index=True) cesena1 = pd.read_csv('./cesena_150715.csv') cesena2 = pd.read_csv('./cesena_250715.csv') cesena3 = pd.read_csv('./cesena_270615.csv') cesena = pd.concat([cesena1,cesena2,cesena3],ignore_index=True) faenza1 = pd.read_csv('./faenza_150715.csv') faenza2 = pd.read_csv('./faenza_250715.csv') faenza3 = pd.read_csv('./faenza_270615.csv') faenza = pd.concat([faenza1,faenza2,faenza3],ignore_index=True)
去除没用的列
city_list = [ferrara,torino,mantova,milano,ravenna,asti,bologna,piacenza,cesena,faenza] for city in city_list: city.drop('Unnamed: 0',axis=1,inplace=True)
显示最高温度于离海远近的关系(观察多个城市)
city_max_temp = [] city_dist = [] for city in city_list: temp = city['temp'].max() dist = city['dist'].max() city_max_temp.append(temp) city_dist.append(dist)
画图
plt.scatter(city_dist,city_max_temp) plt.xlabel("距离") plt.ylabel("最高温度") plt.title("距离和温度之间的关系图")
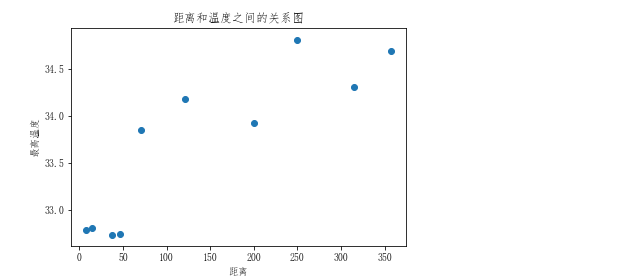
观察发现,离海近的可以形成一条直线,离海远的也能形成一条直线。
- 分别以100公里和50公里为分界点,划分为离海近和离海远的两组数据(近海:小于100 远海:大于50)
city_dist = np.array(city_dist)
city_max_temp = np.array(city_max_temp)
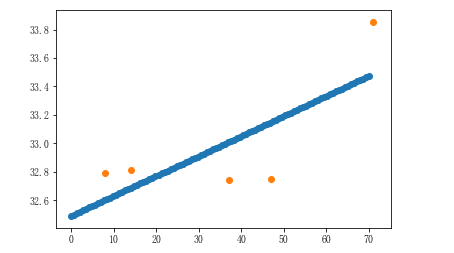
# 找到近海城市 condition = city_dist < 100 near_city_dist = city_dist[condition] near_city_temp = city_max_temp[condition]
### 机器学习 - 算法模型对象:特殊的对象. 在该对象中已经集成好一个方程(还没有求出解的方程) - 模型对象的作用:通过方程实现预测或者分类 - 样本数据(df,np) - 特征数据:自变量 - 目标(标签)数据:因变量 - 模型对象的分类: - 有监督学习: 模型需要的样本数据中存在特征和目标 - 无监督学习:模型需要的样本数据中存在特征 - 半监督学习:模型需要的样本数据部分需要有特征和目标,部分值需要特征数据 - sklearn模块:封装了多种模型对象 from sklearn.linear_model import LinearRegression # 实例化对象 l = LinearRegression() # 训练模型 l.fit(near_city_dist.reshape(-1,1),near_city_temp) # 实现预测温度, 38表示一个特征 l.predict([[38]]) # 模型的精准度 l.score(near_city_dist.reshape(-1,1),near_city_temp)
# 绘制回归曲线 x = np.linspace(0,70, num=100) # x 特征范围,这里表示距离范围 y = l.predict(x.reshape(-1,1)) # y 根据x值预测温度 plt.scatter(x,y) plt.scatter(near_city_dist,near_city_temp)