
一 什么是链表
链表是由一系列节点组成的元素集合。每个节点包含两部分,数据域item和指向一下个节点的指针next。通过节点之间相互连接,最终串联成一个链表

二 链表的操作
1 创建链表
头插法:
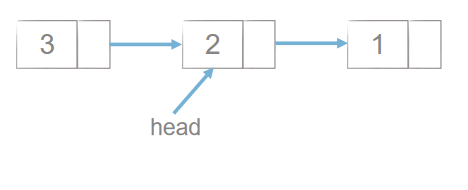
class Node: def __init__(self, item): self.item = item self.next = None def create_linklist(li): head = Node(li[0]) for element in li[1:]: node = Node(element) node.next = head head = node return head
尾插法:
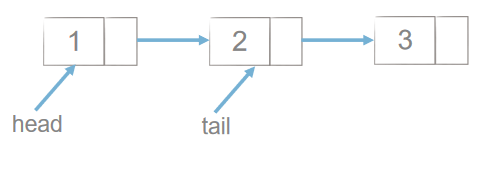
2 链表的遍历
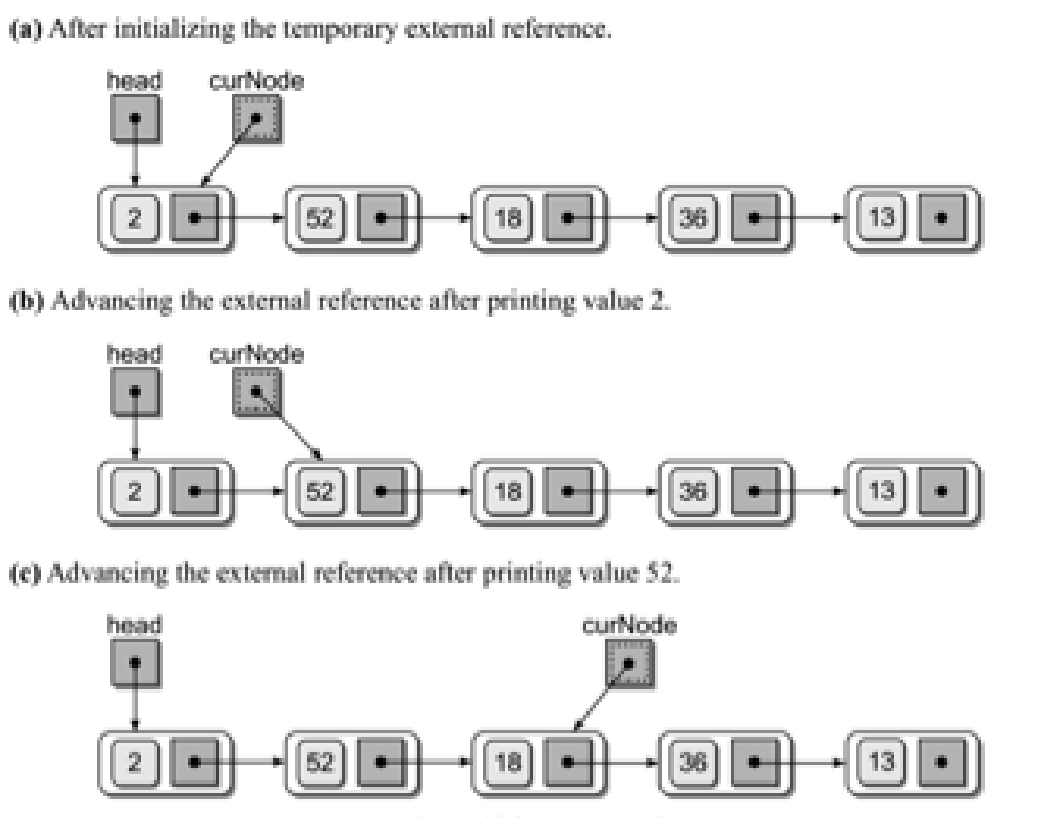
def print_linklist(lk): while lk: print(lk.item, end=',') lk = lk.next print_linklist(lk)
3 链表的插入与删除
插入:
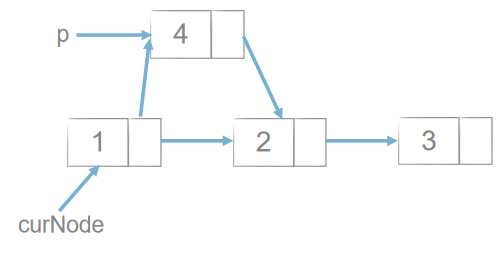
p.next = curNode.next
curNode.next = p
删除:
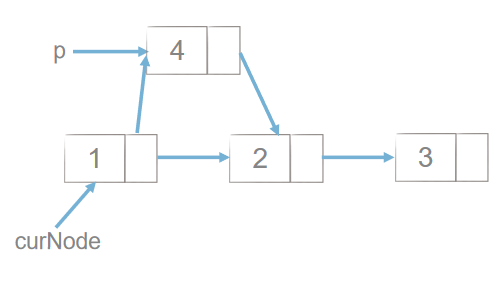
#删除: p = curNode.next curNode.next = p.next #当前节点的下一个指向就指向他下一个的下一个 del p
三 双向链表
双链表的每个节点有两个指针:一个指向后一个节点,另一个指向前一个节点。
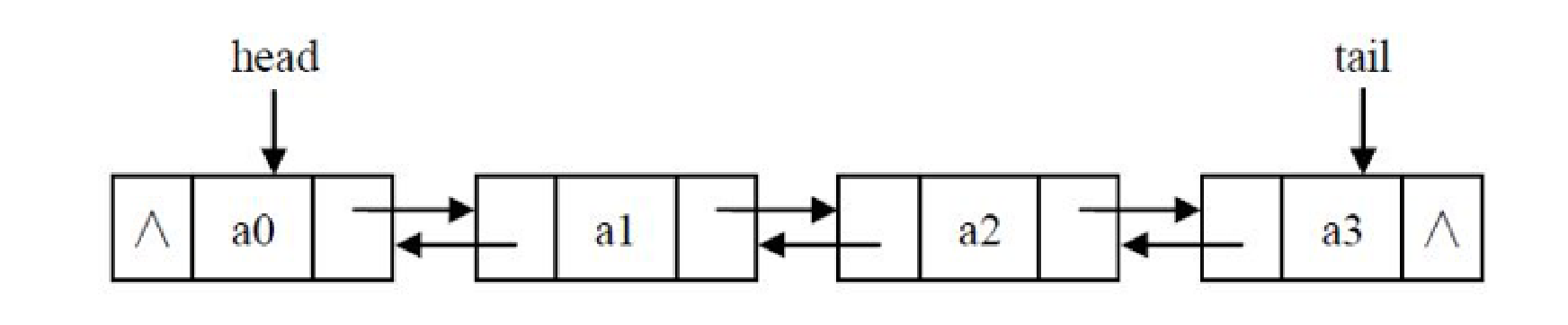
class Node(object): def __init__(self, item=None): self.item = item self.next = None self.prior = None
1 双向链表的结点插入
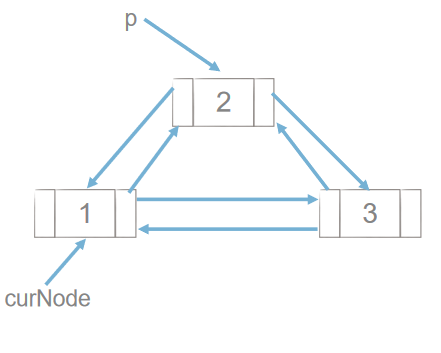
p.next = curNode.next curNode.next.prior = p p.prior = curNode curNode.next = p
2 双向链表的删除
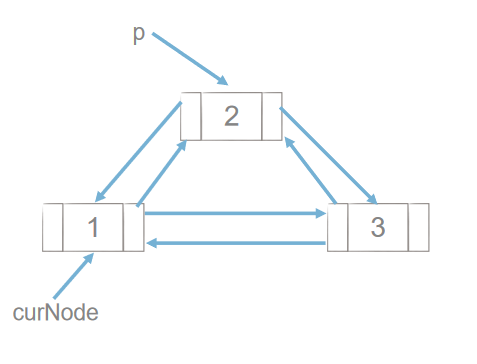
p = curNode.next curNode.next = p.next p.next.prior = curNode del p
四 哈希表
哈希表是一个通过哈希函数来计算数据存储位置的数据结构,通常支持如下操作:
- insert(key, value):插入键值对(key,value)
- get(key): 如果存在键为key的键值对则返回其value, 否则返回空值
- delete(key): 删除键为key的键值对
1 直接寻址表
当关键字的全域U比较小时,直接寻址是一种简单而有效的方法。
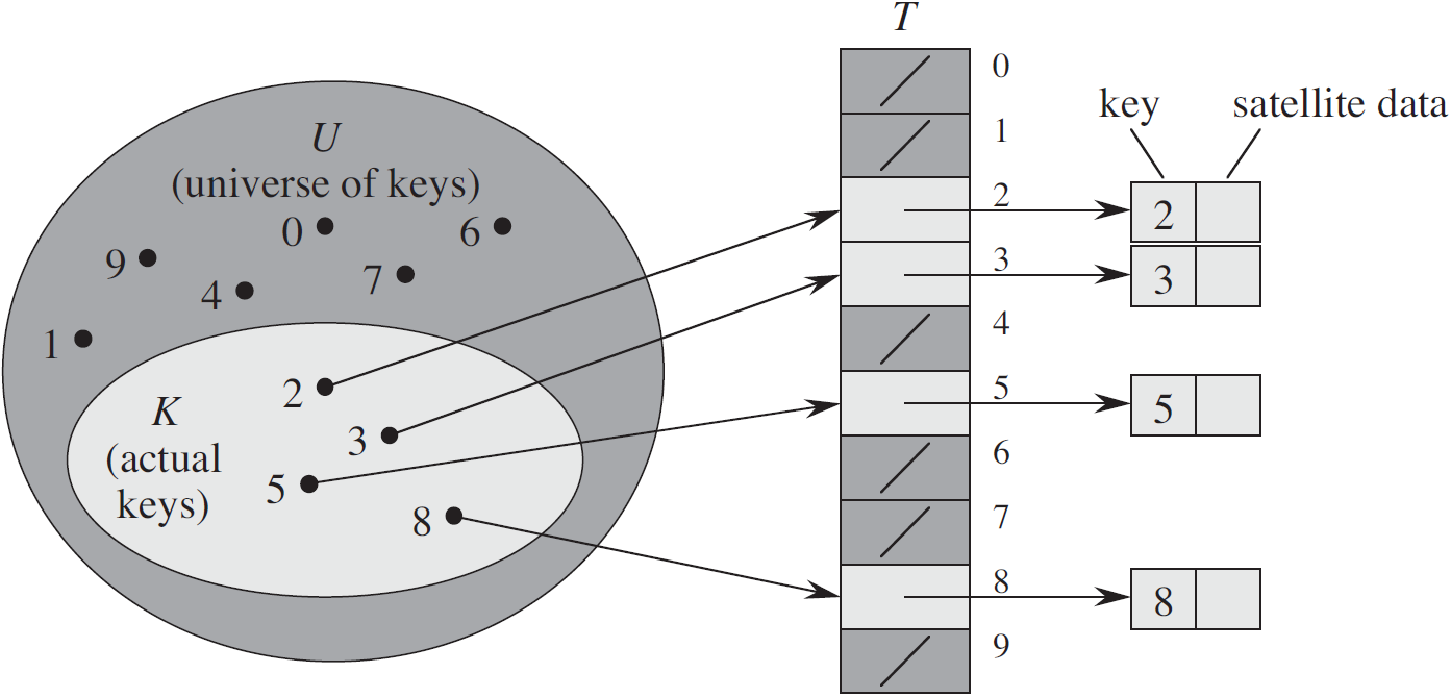
直接寻址技术缺点:
- 当域U很大时,需要消耗大量内存,很不实际
- 如果域U很大而实际出现的key很少,则大量空间被浪费
- 无法处理关键字不是数字的情况
2 哈希
改进直接寻址表:哈希(Hashing)
- 构建大小为m的寻址表T
- key为k的元素放到h(k)位置上
- h(k)是一个函数,其将域U映射到表T[0,1,...,m-1]
哈希表(Hash Table,又称为散列表),是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。
假设有一个长度为7的哈希表,哈希函数h(k)=k%7。元素集合{14,22,3,5}的存储方式如下图。
比如h(k)=k%7, h(0)=h(7)=h(14)=...

五 解决哈希冲突
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况,这种情况叫做哈希冲突。
比如h(k)=k%7, h(0)=h(7)=h(14)=...

1 开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。
线性探查:如果位置i被占用,则探查i+1, i+2,……
二次探查:如果位置i被占用,则探查i+12,i-12,i+22,i-22,……
二度哈希:有n个哈希函数,当使用第1个哈希函数h1发生冲突时,则尝试使用h2,h3,……
2 拉链法
拉链法:哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
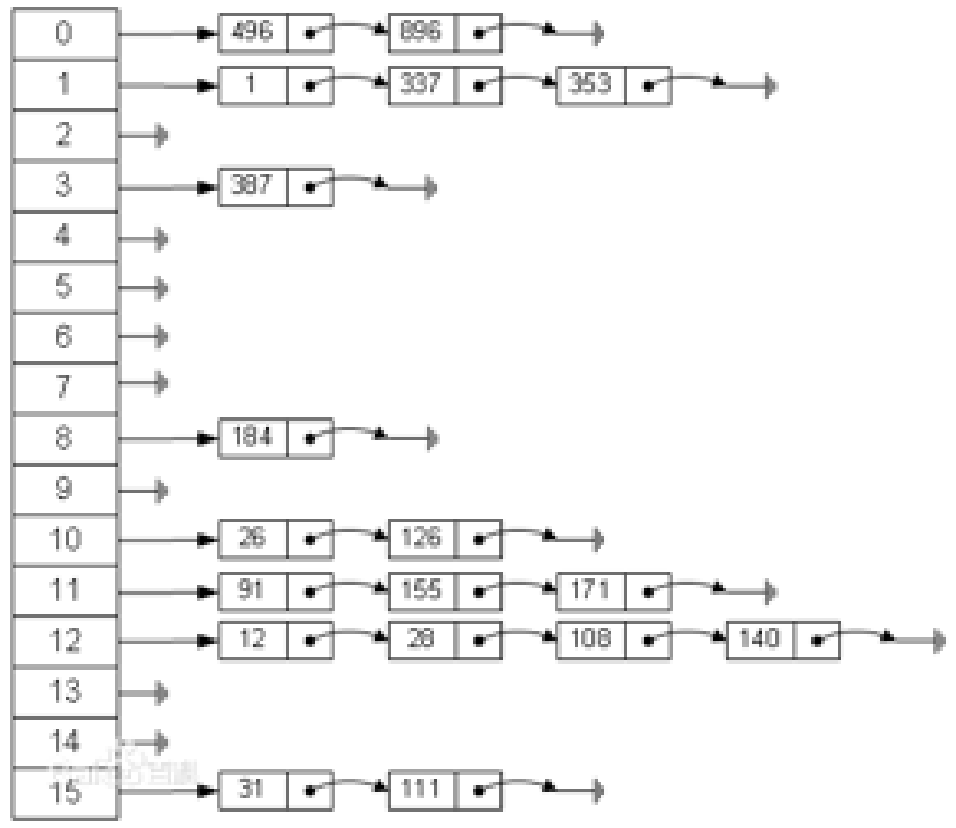
3 常见的哈希函数
除法哈希法: h(k) = k % m
乘法哈希法: h(k) = floor(m*(A*key%1))
全域哈希法: ha,b(k) = ((a*key + b) mod p) mod m a,b=1,2,...,p-1
六 哈希表的应用---集合和字典
字典与集合都是通过哈希表来实现的
a = {'name':'Alex', 'age':18, 'gender':'Man'}
使用哈希表存储字典, 通过哈希函数将字典映射为下标。假设h('name') =3, h('age')=1, h('gender')=4, 则哈希表存储为[None, 18,None, 'Alex', 'Man']
如果发生哈希冲突,则通过拉链法或开发寻址方法解决
class LinkList: class Node: def __init__(self, item=None): self.item = item self.next = None class LinkListIterator: def __init__(self, node): self.node = node def __next__(self): if self.node: cur_node = self.node self.node = cur_node.next return cur_node.item else: raise StopIteration def __iter__(self): return self def __init__(self, iterable=None): self.head = None self.tail = None if iterable: self.extend(iterable) def append(self, obj): s = LinkList.Node(obj) if not self.head: self.head = s self.tail = s else: self.tail.next = s self.tail = s def extend(self, iterable): for obj in iterable: self.append(obj) def find(self, obj): for n in self: if n == obj: return True else: return False def __iter__(self): return self.LinkListIterator(self.head) def __repr__(self): return "<<" + ", ".join(map(str, self)) + ">>" # 类似于集合的结构 class HashTable: def __init__(self, size=10): self.size = size self.T = [LinkList() for i in range(self.size)] def h(self, k): return k % self.size def insert(self, k): i = self.h(k) if self.find(k): print("Duplicated Insert.") else: self.T[i].append(k) def find(self, k): i = self.h(k) return self.T[i].find(k) se = HashTable() se.insert(10) se.insert(11) se.insert(12) se.insert(100) se.insert(200) se.insert(300) print(se.find(14)) print(se.T[0])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号