2021-2022-1 20191315《信息安全系统设计与实现(上)》学习笔记7
第四章 并发编程
本章论述了并发编程,介绍了并行计算的概念,指出了并行计算的重要性;比较了顺序算法与并行算法,以及并行性与并发性;解释了线程的原理及其相对于进程的优势;通过示例介绍了 Pthread 中的线程操作,包括线程管理函数,互斥量、连接、条件变量和屏障等线程同步工具;通过具体示例演示了如何使用线程进行并发编程,包括矩阵计算、快速排序和用并发线程求解线性方程组等方法;解释了死锁问题,并说明了如何防止并发程序中的死锁问题;讨论了信号量,并论证了它们相对于条件变量的优点;还解释了支持 Linux 中线程的独特方式。编程项目是为了实现用户级线程。它提供了一个基础系统来帮助读者开始工作。这个基础系统支持并发任务的动态创建、执行和终止,相当于在某个进程的同一地址空间中执行线程。读者可通过该项目实现线程同步的线程连接、互斥量和信号量,并演示它们在并发程序中的用法。该编程项目会让读者更加深入地了解多任务处理、线程同步和并发编程的原理及方法。
并行计算导论
- 在早期,大多数计算机只有一个处理组件,称为处理器或中央处理器(CPU)。受这种硬件条件的限制,计算机程序通常是为串行计算编写的。要求解某个问题,先要设计一种算法,描述如何一步步地解决问题,然后用计算机程序以串行指令流的形式实现该算法。在只有一个 CPU 的情况下,每次只能按顺序执行某算法的一个指令和步骤。但是,基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。并行计算是一种计算方案,它尝试使用多个执行并行算法的处理器更快速地解决问题。
顺序算法与并行算法
- 顺序算法:begin-end代码块列出算法。可包含多个步骤,所有步骤通过单个任务依次执行,每次执行一个步骤,全执行完,算法结束。
- 并行算法:cobegin-coend代码块来指定独立任务,所有任务都是并行执行的,紧接着代码块的下一个步骤将只在所有这些任务完成之后执行。

并行性和并发性
并行算法只识别可并行执行的任务,但是它没有规定如何将任务映射到处理组件。在理想情况下,并行算法中的所有任务都应该同时实时执行。然而,真正的并行执行只能在有多个处理组件的系统中实现,比如多久理器或多核系统。在单CPU系统中,一次只能执行一个任务。在这种情况下,不同的任多务只能并发执行,即在逻辑上并行执行。在单CPU系统中,并发性是通过多任务处理来实现的。
线程
原理
- 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如Win32线程;由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;或者由内核与用户进程,如Windows 7的线程,进行混合调度。 - 同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
一个进程可以有很多线程,每条线程并行执行不同的任务。 - 在多核或多CPU,或支持Hyper-threading的CPU上使用多线程程序设计的好处是显而易见,即提高了程序的执行吞吐率。在单CPU单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,从而提高了程序的执行效率。
优点
- 线程创建和切换速度更快
- 响应速度更快
- 更适合并行计算
缺点
- 由于地址空间共享,线程需要来自用户的明确同步。
- 许多库函数可能对线程不安全,例如传统 strtok()函数将一个字符串分成一连串令牌。通常,任何使用全局变量或依赖于静态内有内容的函数,线程都不安全。为了使库函数适应线程环境,还需要做大量的工作。
- 在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
线程操作
线程可在内核模式或用户模式下执行
线程管理函数
Pthread库提供了用于线程管理的以下API


创建一个新的线程
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
线程终止
void pthread_exit(void *retval);
等待线程结束
int pthread_join(pthread_t thread, void **retval);
返回线程ID
pthread_t pthread_self(void);
取消一个线程
int pthread_cancel(pthread_t thread);
将一个线程从进程中分离
int pthread_detach(pthread_t thread);
线程同步
由于线程在进程的同一地址空间中执行 它们共享同一地址空间中的所有全局变量和数据结构。当多个线程试图修改同一共享变量或数据结构时,如果修改结果取决于线程的执行顺序,则称之为竞态条件。在并发程序中,绝不能有竞态条件。否则,结果可能不一致。除了连接操作之外,并发执行的线程通常需要相互协作。为了防止出现竞态条件并且支持线程协作,线程需要同步。通常,同步是一种机制和规则,用于确保共享数据对象的完整性和并发执行实体的协调性。它可以应用于内核模式下的进程,也可以应用于用户模式下的线程。
互斥量
同步工具是锁,它允许执行实体仅在有锁的情况下才能执行。锁被称为互斥量
互斥变量是用pthread_mutex_t类型声明的,在使用之前必须进行初始化。
- 静态方法:
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
定义互斥量m,并使用默认属性对其进行初始化。 - 动态方法:
pthread_mutex_init(pthread_mutex_t *m,pthread_mutexattr_t,*attr);
通常attr参数可以设置位NULL,作为默认属性。
初始化完成后,线程可以通过以下函数使用互斥量。

线程使用互斥量来保护共享数据对象。
死锁预防
- 互斥量使用封锁协议。有多种方法可以解决可能的死锁问题,其中包括死锁防御、死锁规避、死锁检测和回复等。在实际情况中,唯一可行的方法时死锁预防,试图在设计并行算法是防止死锁发生。
- 一种简单的死锁预防时对互斥量进行排序,并确保每个线程只在一个方向请求互斥量,这样请求序列中就不会有循环。
- 条件加锁和退避预防死锁

条件变量
作为锁,互斥量仅用于确保线程只能互斥地访问临界区中的共享数据对象。条件变量提供了一种线程协作的方法。在Pthread中,使用othread_cond_t来声明条件变量,而且必须在使用前进行初始化。
- 静态方法
pthread_cond_t con = PTHREAD_COND_INITALLIZER; - 动态方法
使用pthread_cond_init()函数,通过attr参数设置条件变量。
信号量
信号量是进程同步的一般机制。(计数)信号量是一种数据结构.
struct sem{
int value;
struct process *queue
}s;
最有名的信号量操作时P和V

屏障
线程连接操作允许某线程(通常是主线程)等待其他线程终止。在某些情况下,保持线程活动会更好,但应要求他们在所有线程都达到指定同步点之前不能继续活动。在Pthreads中,可以采用屏障以及一系列屏障函数。
首先,主线程创建一个屏障对象
pthread_barrier_init(&barrier NULL,nthreads);
用屏蔽中同步线程数字对他进行初始化。然后,主线程创建工作线程来执行任务。
实践
用并发线程快速排序
源代码
点击查看代码
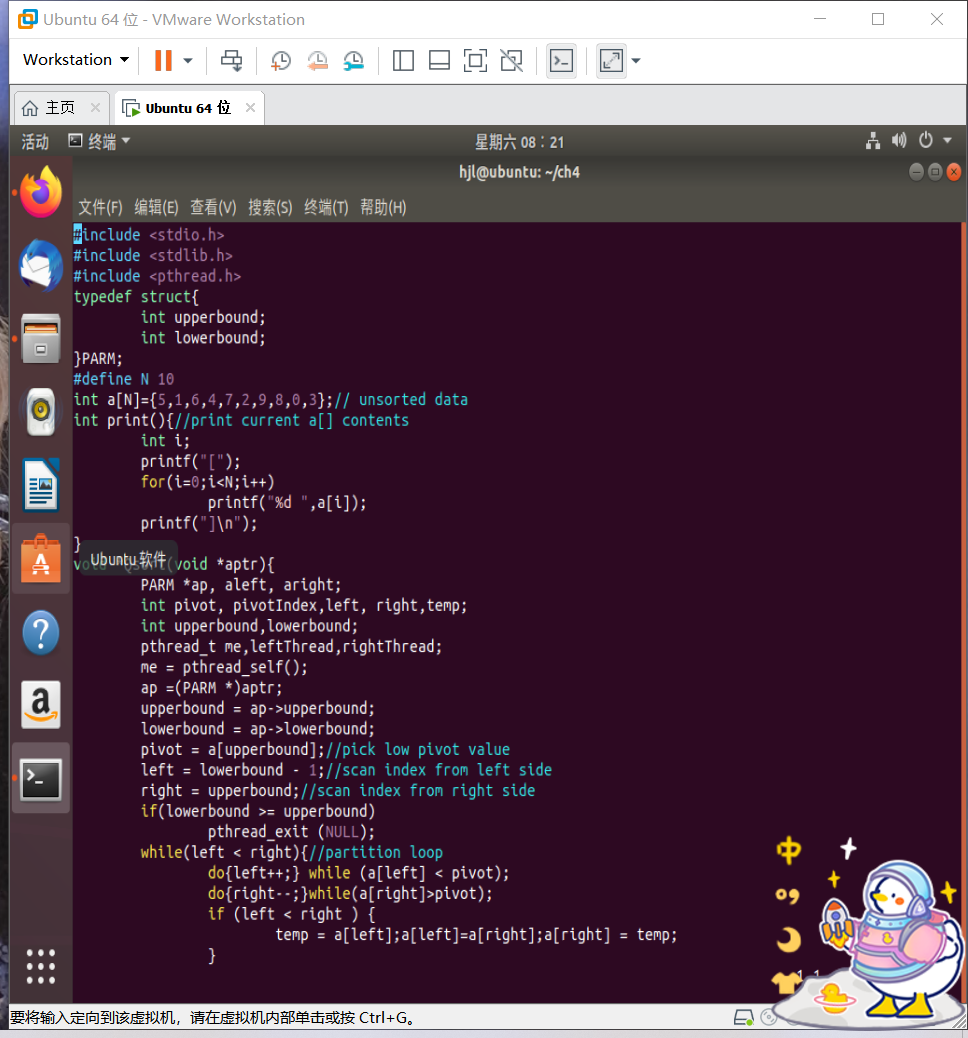
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
typedef struct{
int upperbound;
int lowerbound;
}PARM;
#define N 10
int a[N]={5,1,6,4,7,2,9,8,0,3};// unsorted data
int print(){//print current a[] contents
int i;
printf("[");
for(i=0;i<N;i++)
printf("%d ",a[i]);
printf("]\n");
}
void *Qsort(void *aptr){
PARM *ap, aleft, aright;
int pivot, pivotIndex,left, right,temp;
int upperbound,lowerbound;
pthread_t me,leftThread,rightThread;
me = pthread_self();
ap =(PARM *)aptr;
upperbound = ap->upperbound;
lowerbound = ap->lowerbound;
pivot = a[upperbound];//pick low pivot value
left = lowerbound - 1;//scan index from left side
right = upperbound;//scan index from right side
if(lowerbound >= upperbound)
pthread_exit (NULL);
while(left < right){//partition loop
do{left++;} while (a[left] < pivot);
do{right--;}while(a[right]>pivot);
if (left < right ) {
temp = a[left];a[left]=a[right];a[right] = temp;
}
}
print();
pivotIndex = left;//put pivot back
temp = a[pivotIndex] ;
a[pivotIndex] = pivot;
a[upperbound] = temp;
//start the "recursive threads"
aleft.upperbound = pivotIndex - 1;
aleft.lowerbound = lowerbound;
aright.upperbound = upperbound;
aright.lowerbound = pivotIndex + 1;
printf("%lu: create left and right threadsln", me) ;
pthread_create(&leftThread,NULL,Qsort,(void * )&aleft);
pthread_create(&rightThread,NULL,Qsort,(void *)&aright);
//wait for left and right threads to finish
pthread_join(leftThread,NULL);
pthread_join(rightThread, NULL);
printf("%lu: joined with left & right threads\n",me);
}
int main(int argc, char *argv[]){
PARM arg;
int i, *array;
pthread_t me,thread;
me = pthread_self( );
printf("main %lu: unsorted array = ", me);
print( ) ;
arg.upperbound = N-1;
arg. lowerbound = 0 ;
printf("main %lu create a thread to do QS\n" , me);
pthread_create(&thread,NULL,Qsort,(void * ) &arg);//wait for Qs thread to finish
pthread_join(thread,NULL);
printf ("main %lu sorted array = ", me);
print () ;
}
运行结果

用线程计算矩阵的和
源代码
点击查看代码
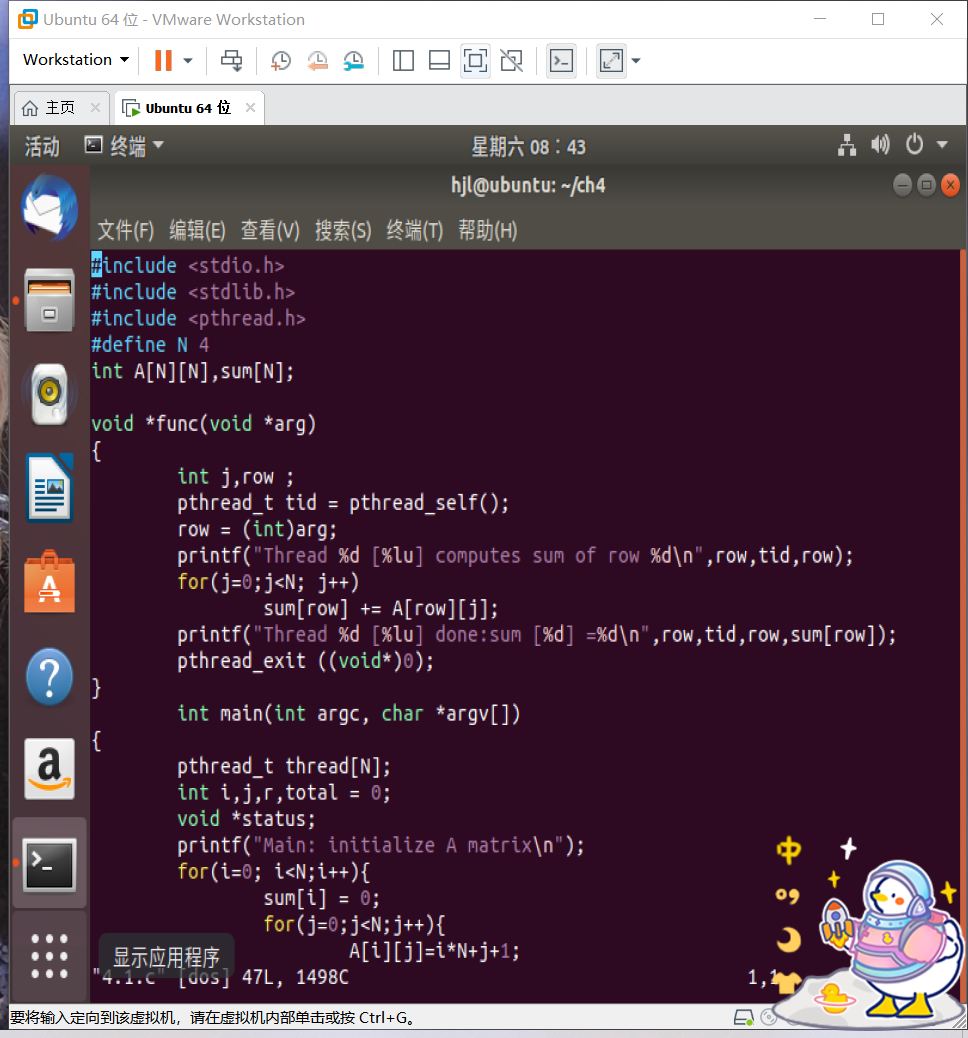
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define N 4
int A[N][N],sum[N];
void *func(void *arg)
{
int j,row ;
pthread_t tid = pthread_self();
row = (int)arg;
printf("Thread %d [%lu] computes sum of row %d\n",row,tid,row);
for(j=0;j<N; j++)
sum[row] += A[row][j];
printf("Thread %d [%lu] done:sum [%d] =%d\n",row,tid,row,sum[row]);
pthread_exit ((void*)0);
}
int main(int argc, char *argv[])
{
pthread_t thread[N];
int i,j,r,total = 0;
void *status;
printf("Main: initialize A matrix\n");
for(i=0; i<N;i++){
sum[i] = 0;
for(j=0;j<N;j++){
A[i][j]=i*N+j+1;
printf("%4d ",A[i][j]);
}
printf( "\n" );
}
printf ("Main: create %d threads\n",N);
for(i=0;i<N;i++) {
pthread_create(&thread[i],NULL,func,(void *)i);
}
printf("Main: try to join with thread\n");
for(i=0; i<N; i++) {
pthread_join(thread[i],&status);
printf("Main: joined with %d [%lu]: status=%d\n",i,thread[i],
(int)status);
}
printf("Main: compute and print total sum:");
for(i=0;i<N;i++)
total += sum[i];
printf ("tatal = %d\n",total );
pthread_exit(NULL);
}
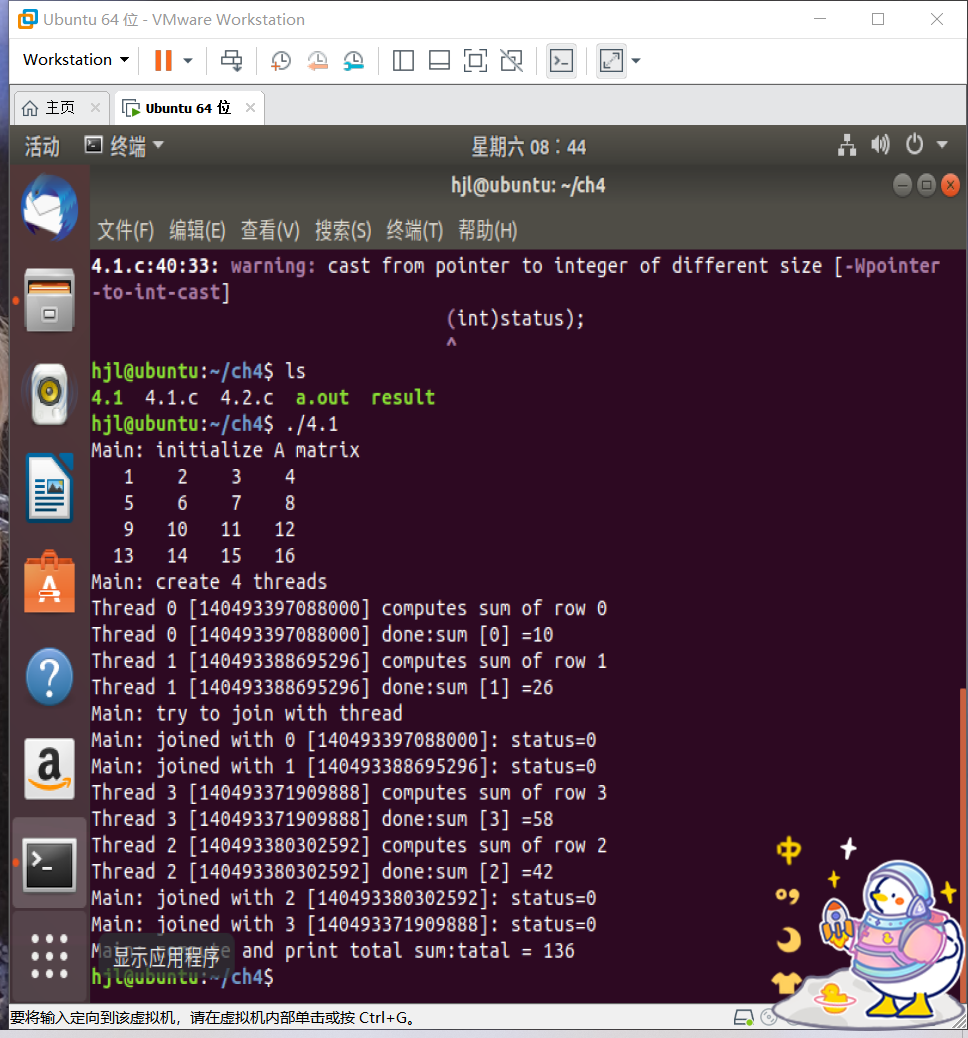
运行结果