关于--学习DRF反序列器--关反序列化操作
同样的由于笔者在Django的Test文件下进行测试,因此,需要配置Django的环境标量
1 import os, json, django
2 #配置添加Django环境
3 if not os.environ.get("DJANGO_SETTINGS_MODULE"):
4 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "drf_demo.settings")
5 #启动Django环境
6 django.setup()
反序列化器校验有三种形式:
- 对需要校验的“字段”进行添加validators=[<函数的引用>],用来对传入字段进行“补充校验”
- 反序列器内部构造validate_
<field_name>(self, value)方法进行“”补充校验 (注意validate_[和需要补充验证的字段名一致], 例如笔者写的“btitle”)-->局限对单个字段 - 反序列器内部构造validate(self, attrs)方法对多个字段进行“补充校验”, attrs为数据字典形式
== 前提准备好<书>和<英雄>的模型类 ==
准备图书类反序列器
1 class BookInfoSerializer(serializers.Serializer):
2 """图书序列器"""
3 id = serializers.IntegerField(label="图书序号", read_only=True)
4 btitle = serializers.CharField(label="图书标题", max_length=20)
5 # btitle = serializers.CharField(label="图书标题", max_length=20, validators=[about_django])
6 bpub_date = serializers.DateField(label="发行日期", required=False)
7 bread = serializers.IntegerField(label="阅读量", required=False)
8 bcomment = serializers.IntegerField(label="评价量", required=False)
I. 对需要校验的“字段”进行添加validators=[<函数的引用>],用来对传入字段进行“补充校验”
在图书叙序列器添加针对"btitle"的补充验证代码(需要修改原btitle等式后内容):
btitle = serializers.CharField(label="图书标题", max_length=20, validators=[about_django])
在图书叙序列器类外添加<about_django>函数, ## 在进行btitle验证时,要求btitle的内容必须含有django
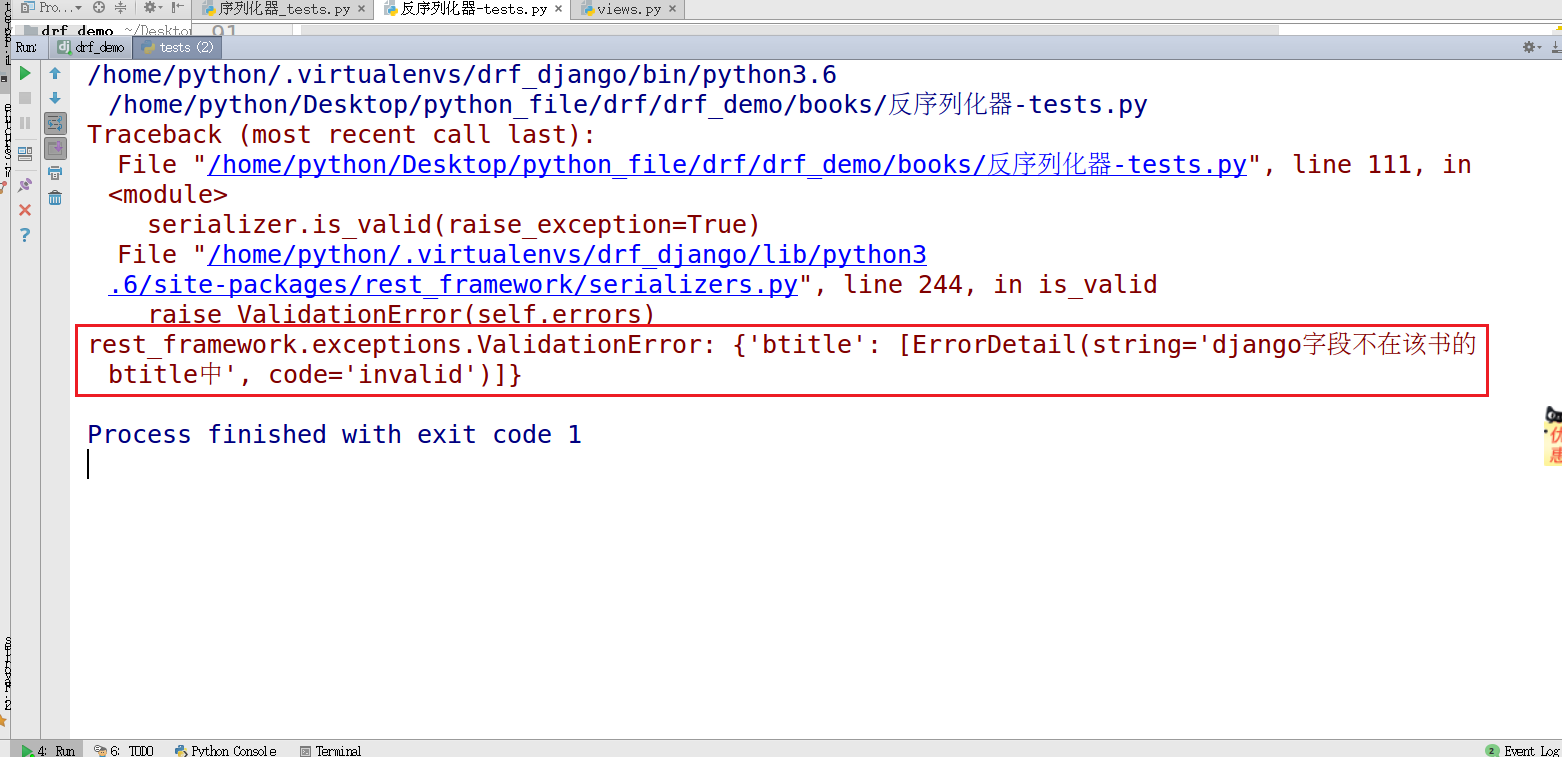
1 def about_django(value): 2 if "django" not in value.lower(): 3 raise serializers.ValidationError("django字段不在该书的btitle中")
然后运行测试代码:
1 if __name__ == '__main__': 2 # book5 = BookInfo.objects.get(id=5) 3 data = { 4 "btitle":"python", 5 "bpub_date":"2019-5-21" 6 } 7 8 serializer = BookInfoSerializer(data=data) 9 serializer.is_valid(raise_exception=True) 10 success_data = serializer.validated_data 11 print(success_data)
得到结果输出:raise出来的错误结果,正是我们进行校验函数的结果,表明我们的btitle验证时,没有含有django
II. 反序列器内部构造validate_btitle(self, value)方法进行“”补充校验
在图书叙序列器添加针对"btitle"的补充验证代码:
btitle = serializers.CharField(label="图书标题", max_length=20)
在图书叙序列器类内部添加validate_btitle(self, value)方法:
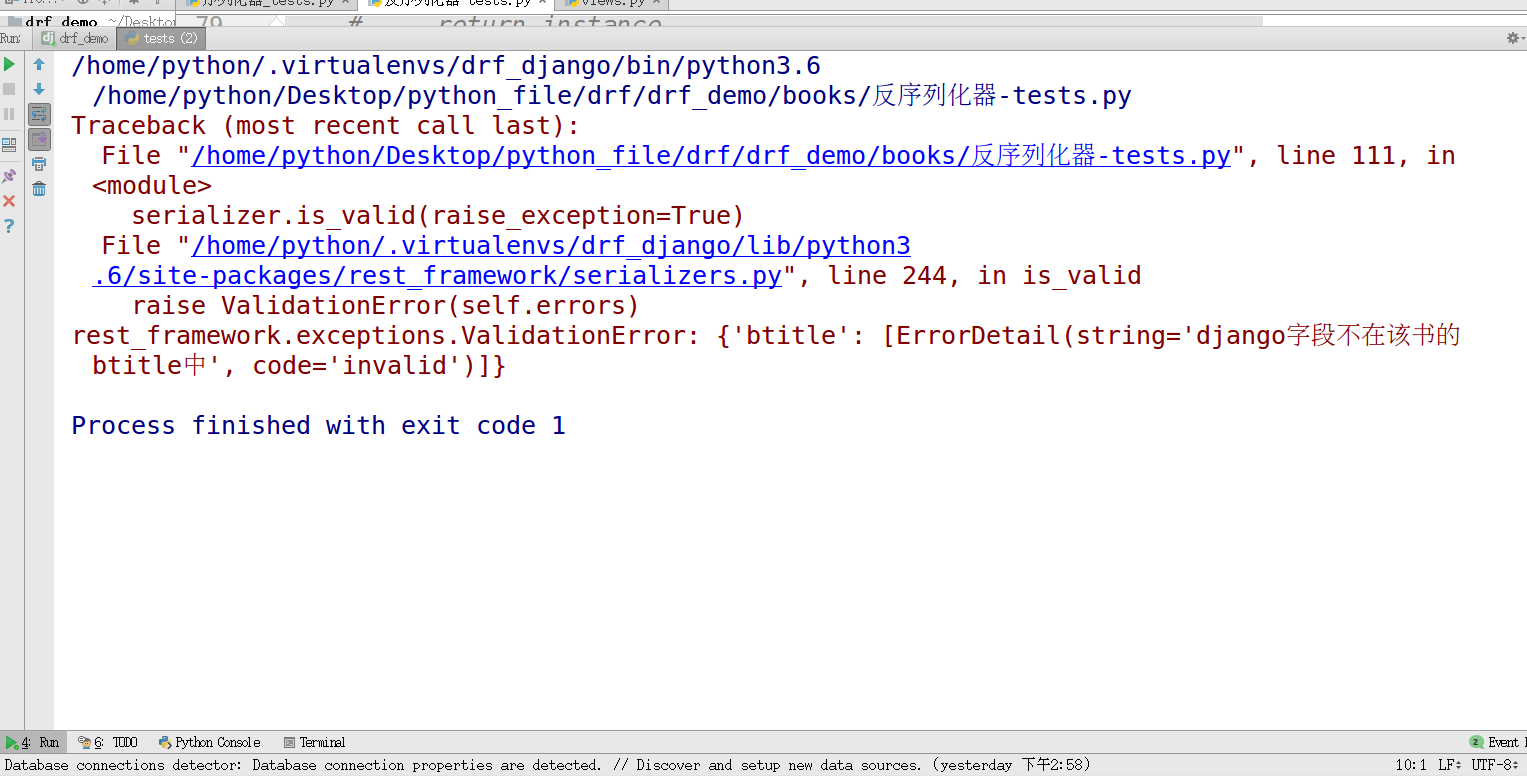
1 def validate_btitle(self, value): 2 if "django" not in value.lower(): 3 raise serializers.ValidationError("django字段不在该书的btitle中") 4 else: 5 return value
然后运行测试代码:
1 if __name__ == '__main__': 2 # book5 = BookInfo.objects.get(id=5) 3 data = { 4 "btitle":"python", 5 "bpub_date":"2019-5-21" 6 } 7 8 serializer = BookInfoSerializer(data=data) 9 serializer.is_valid(raise_exception=True) 10 success_data = serializer.validated_data 11 print(success_data)
得到结果输出:raise出来的错误结果,正是我们进行校验函数的结果,表明我们的btitle验证时,没有含有django
III. 反序列器内部构造validate(self, attrs)方法对多个字段进行“补充校验”
在图书叙序列器添加针对"bread"和"bcomment"的补充验证代码:## bread和bcomment验证时,要求bread必须大于bcomment。
bread = serializers.IntegerField(label="阅读量", required=False) bcomment = serializers.IntegerField(label="评价量", required=False)
在图书叙序列器类内部添加validate(self, attrs)方法
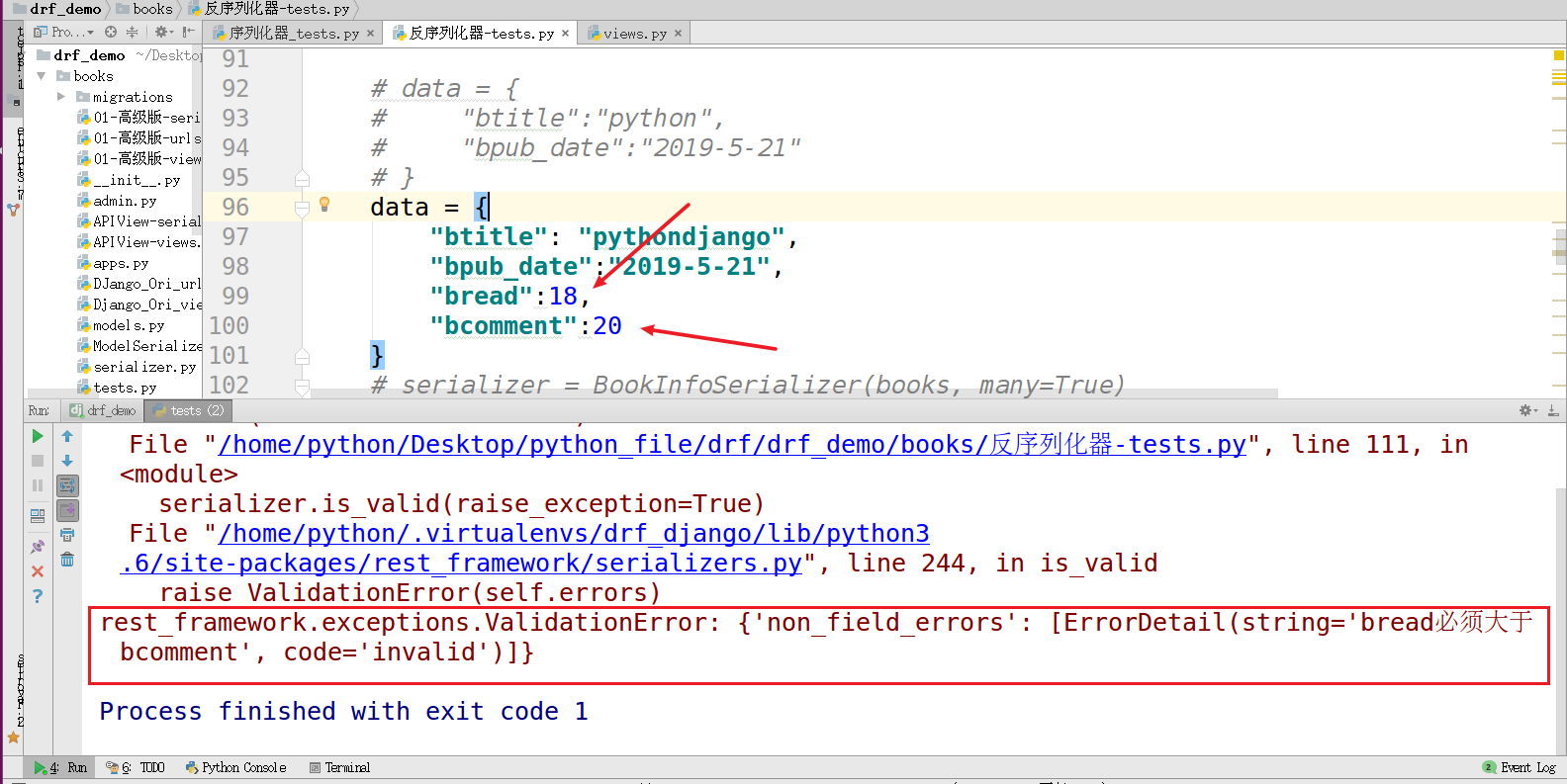
1 def validate(self, attrs): 2 # bread和bcomment验证时,要求bread必须大于bcomment。 3 bread = attrs.get("bread") 4 bcomment = attrs.get("bcomment") 5 6 if bread < bcomment: 7 raise serializers.ValidationError("bread必须大于bcomment") 8 return attrs
然后运行测试代码:
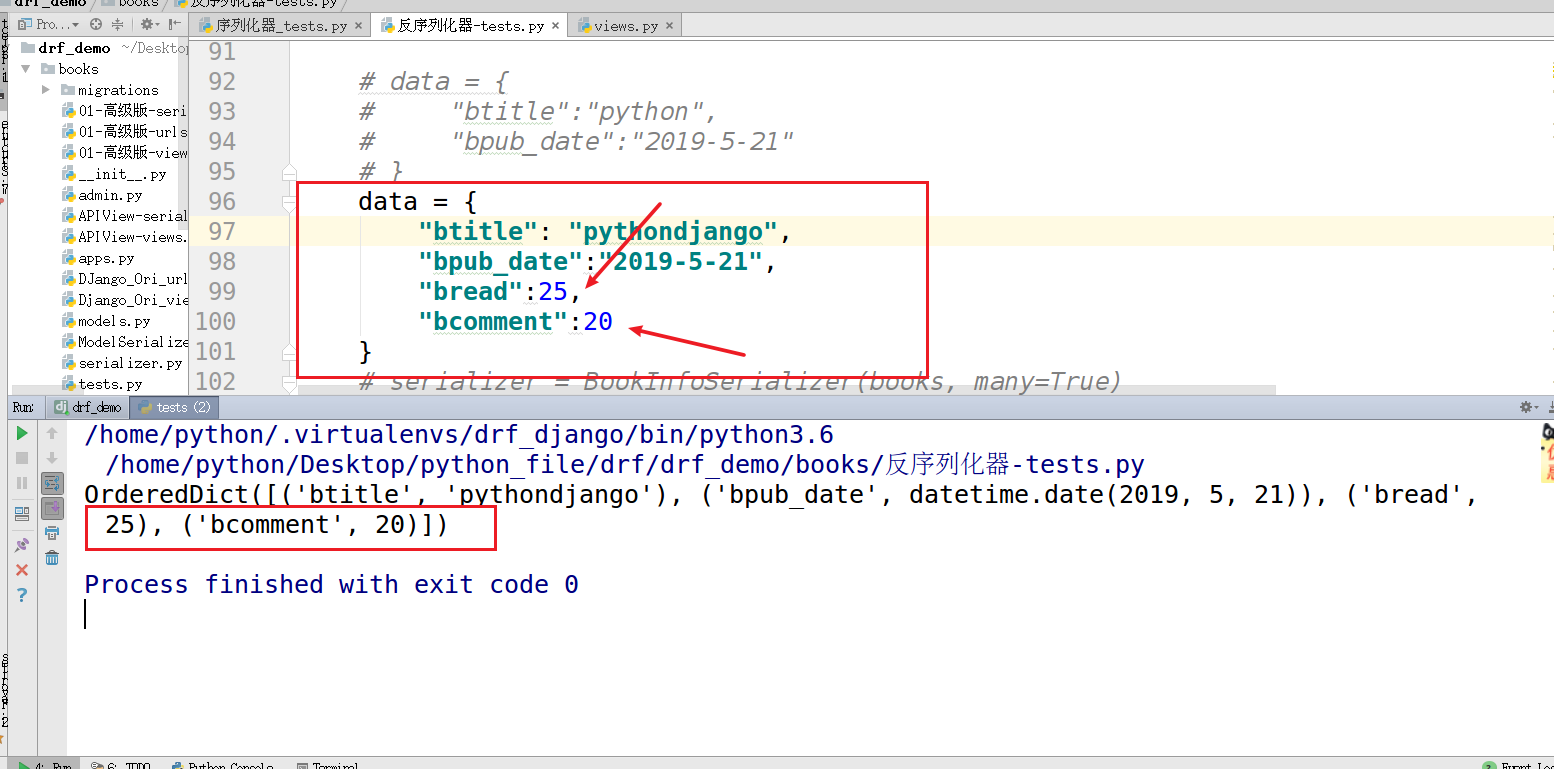
1 if __name__ == '__main__': 2 data = { 3 "btitle": "pythondjango", 4 "bpub_date":"2019-5-21", 5 "bread":25, 6 "bcomment":20 7 } 8 9 serializer = BookInfoSerializer(data=data) 10 serializer.is_valid(raise_exception=True) 11 success_data = serializer.validated_data 12 print(success_data)
得到结果输出:由于输入的bread > bcomment ,结果输出有效
得到结果输出:由于输入的bread < bcomment ,raise出来的错误结果,正是我们进行校验函数的结果,表明我们的breaa和bcomment验证时,bread < bcomment
分享到此结束,此外需要注意几点:
1. 构造validate_<field_name>的时候,注意validate_[和需要补充验证的字段名一致](例如笔者写的“btitle”)-->局限对单个字段
2. 需要对多个字段进行补充验证的时候,采用反序列器内部构造validate(self, attrs)方法对多个字段进行“补充校验”, attrs为数据字典形式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号