
LSM Tree
总览
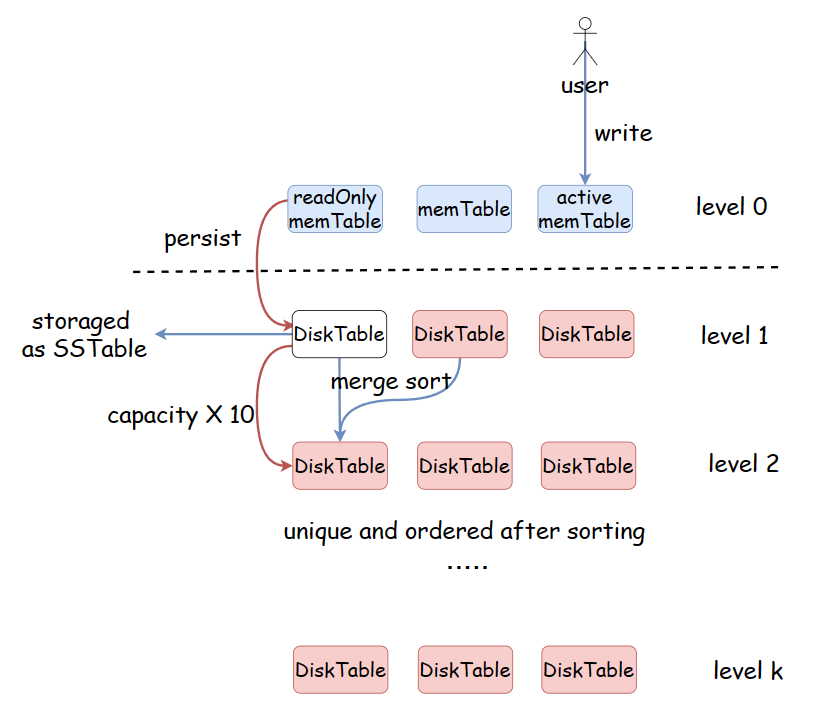
写流程:
- 就地写,写入memTable
- 当active memTable 满后,转变为readOnly memTable, 在合适时机flush入磁盘。
- 当前level数据满后,进行归并操作,把数据排序,去重后转入下一level。
背景介绍
两种场景,读多写少,写多读少。
原地写
写操作:找到老数据所在位置,更新, IO操作,慢。
读操作:空间利用率高。
追加写
写操作:直接追加。
读操作:日志末尾逆序检索,性能不稳定。
LSM Tree适用于写多读少,以写效率为首要目标,保持读效率在容忍范围内。
追加写存在的问题:
-
空间浪费
存在多份数据。
-
读性能低
如何解决空间浪费:
异步运行一个日志压缩线程。对于同一个数据的内容进行合并,保留最新数据。
新的问题:并发的资源竞争问题。
拆分文件解决资源竞争
把本来一个追加写的大文件拆分成一个个小的Table,这样的话,读取操作只需要在较新的Table中进行,旧的Table可以另外异步compact。
如何提高查找性能:
在每个表中使得数据有序,引入二分,使得单个表中的查询变成logN级别。
但是这样需要随机存储。与我们追加写的初衷相违背。
在DiskTable的基础上引入memTable(内存表),额外在内存中维护 memTable结构。
- memTable在内存中缓存
- memTable本身有序
- 在memTable的写操作统一采用就地写
- memTable是用户写操作的唯一入口
- memTable达到一定数据量后写入磁盘,成为追加DiskTable
为什么引入memTable不会违背我们追加写的初衷,不会违背我们以写效率为目标的初衷呢?
内存随机存储的速度是磁盘随机存储的几百到几千倍。
而我们的DiskTable依旧是追加写的形式。
三个新的问题
memTable的数据易失
WAL(write-ahead-log) 预写日志: 在将数据写入memTable前,先将操作写入位于磁盘的log中,保证了可以通过重放WAL来恢复memTable。
为什么日志同样是往磁盘中写入,却不会影响性能?
WAL日志是追加写,磁盘顺序IO,并不会对性能造成过大影响。
memTable写磁盘堵塞
将memTable分为两部分,Active memTable 和 ReadOnly memTable,当一个Active memTable 数据满时,转变为ReadOnly memTable,新的写入会使用新的Active memTable,ReadOnly memTable会进行磁盘持久化。
memTable内部采用什么数据结构
跳表?红黑树?其实都行。
跳表(Skip List):
- 优势:
- 有更细的锁粒度,插入时涉及的节点较少。
- 跳表是一种有序的数据结构,对范围查询有较好的支持。
- 插入和删除的平均时间复杂度为O(log n)。
- 实现相对简单,易于理解和调试。
- 劣势:
- 跳表的实现相对于红黑树来说,可能会占用更多的空间。
- 需要维护多个层级,可能增加一些额外的开销。
红黑树(Red-Black Tree):
- 优势:
- 在插入和删除等操作方面,红黑树的常数因子较小,可能在某些情况下更快。
- 红黑树的空间利用率较高,不需要额外的指针。
- 劣势:
- 实现相对复杂,难以理解和维护。
- 对于范围查询,可能性能不如跳表。
有关DiskTable
-
DiskTable内部不存在重复kv数据对,内存就地写。
-
DiskTable内部kv数据对有序,调表/红黑树插入。
-
每个memTable的视野有限,Table是一个相对较小的单位,解决单个Table的数据冗余并不能解决全局的数据冗余。
如何解决diskTable视野有限的情况?
Table 分层
- 将磁盘中的文件分为level 0 ~ level k, 一共k + 1 层。
- 每层的diskTable数量保持一致。
- level i + 1 的容量是level i 的 T 倍,T 一般取10。
- 每一层的数据容量满时,会向下层进行归并操作,排序并且去重。
在LSM Tree 中, 在磁盘的存储中,diskTable用特定的数据结构 SSTable(Sorted String Tables) 存储。
- 因为每一层的diskTable容量是上一层的数倍,在靠下的层次中,diskTable会很大,当我们对其进行读取的时候会显得很笨重。
SSTable做的优化:
- 数据通常按照某种方式进行分块,使得查询时可以只加载所需范围的块,而不是整个 SSTable。这降低了查询时所需的 I/O 操作,提高了查询效率。
- 每个SST会维护一组索引信息,记录了每个块的k_min 和 k_max

