本文主要是学习《Factor Graphs for Robot Perception》一书是记录的笔记,耗时较长,篇幅较大,后续再做细致的分节以及补充相关知识。
问题表达
Measurement predictions and noise models are the core elements of a generative model, which is well matched with the Bayesian network framework.
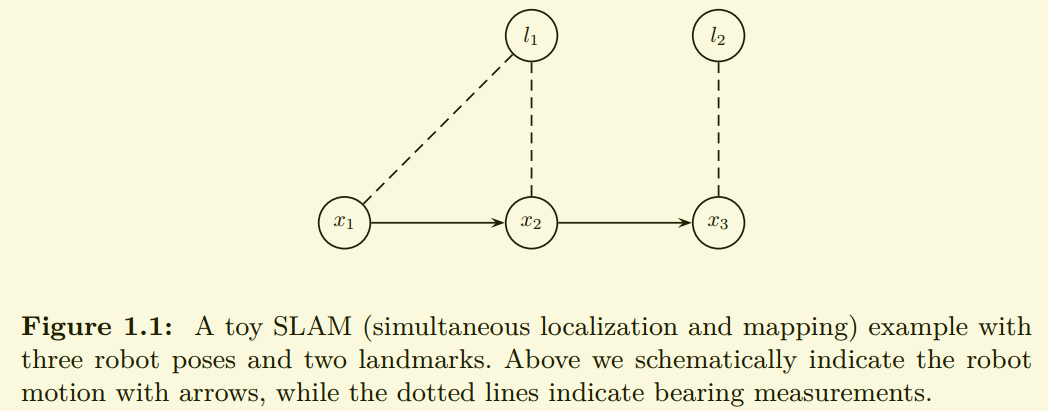
转换为贝叶斯网络:
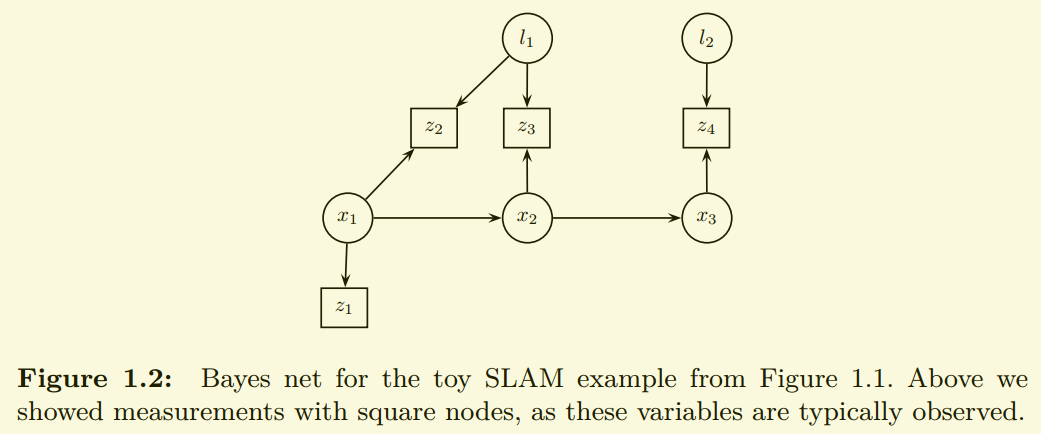
联合概率密度:
\[\begin{aligned}
p(X,Y) &= p(x_1)p(x_2|x_1)p(x_3|x_2) \\
&\times p(l_1)p(l_2) \\
&\times p(z_1|x_1) \\
&\times p(z_2|x_1,l_1)p(z_3|x_2,l_1)p(z_4|x_3,l_2)
\end{aligned}
\]
squared Mahalanobis distance:
\[\parallel \theta - \mu \parallel ^{2}_{\Sigma} \triangleq (\theta - \mu)^\top\Sigma^{-1}(\theta - \mu)
\]
多维高斯分布:
\[\begin{aligned}
\mathcal{N}(\theta;\mu,\Sigma) &= \frac {1}{\sqrt{2\pi|\Sigma|}}\operatorname{exp}(-\frac{1}{2}(\theta - \mu)^T\Sigma^{-1}(\theta - \mu)) \\
&= \frac {1}{\sqrt{2\pi|\Sigma|}}\operatorname{exp}(-\frac{1}{2}\parallel \theta - \mu \parallel ^{2}_{\Sigma})
\end{aligned}
\]
a bearing measurement from a given pose x to a given landmark l would be modeled as
\[z = h(x,l)+\eta \\
\eta \sim \mathcal{N}(\theta;0,\Sigma)
\]
\[p(z|x,l) = \mathcal{N}(z;h(x,l),R)
\]
最大后验概率密度
maximizes the posterior density p(X|Z) of the states X given the measurements Z
\[\begin{aligned}
X^{MAP} &= \underset{x}{\text{argmax}}\: p(X|Z) \\
&= \underset{x}{\text{argmax}}\: \frac{p(Z|X)p(X)}{p(Z)} \\
&= \underset{x}{\text{argmax}}\: l(X;Z)p(X)
\end{aligned}
\]
\(l(X; Z)\) is the likelihood of the states X given the measurements Z.
\[l(X;Z) \propto p(Z|X)
\]
通过条件化传感器数据,贝叶斯网络可以很容易得转换为因子图。
使用因子图的原因:
- the distinct division between states X and measurements Z
- the fact that we are more interested in the non-Gaussian likelihood functions, which are not proper probability densities.
因此:
\[\begin{aligned}
p(X|Z) &\propto p(x_1)p(x_2|x_1)p(x_3|x_2) \\
&\times p(l_1)p(l_2) \\
&\times l(x_1;z_1) \\
&\times l(x_1,l_1;z_1)l(x_2,l_1;z_3)l(x_3,l_2:z_4)
\end{aligned}
\]
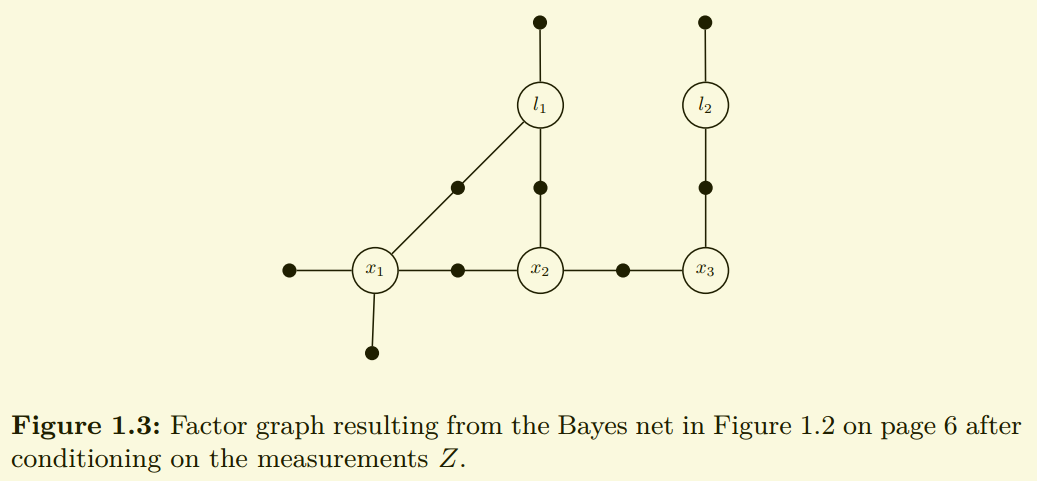
与贝叶斯网络不同测量值不在明确的显示在图中, 也不再将每个节点与相应的条件概率密度关联起来,而是使用因子(factors)来表示后验概率密度\(p(X|Z)\)。上图中,每个小黑点都是一个因子,只与其所连接的变量有关,例如似然(likelihood)因子\(l(x_3,l_2;z_4)\)只与变量节点\(x_3,l_2\)有关。
每一个因子图都是一个二分图:\(F=(\mathcal{U}, \mathcal{V}, \mathcal{\varepsilon})\),有两种类型节点 factors \(\phi_i \in \mathcal{U}\), variables \(x_j \in \mathcal{V}\).edges \(e_{ij} \in \mathcal{\varepsilon}\)
在factor与variable之间。The set of variable nodes \(X_i\) adjacent to a factor \(\phi(i)\) is written as \(\mathcal{N}(\phi(i))\).a factor graph \(\mathcal{F}\) defines the factorization of a global function \(\phi(X)\) as:
\[\phi(X) = \prod_{i}\phi_{i}(X_i)
\]
每个因子代表未归一化的后验概率\(\phi(X) \propto P(X|Z)\)。
factor graph factorization:
\[\begin{aligned}
\phi(l_1,l_2,x_1,x_2,x_3) &= \phi_1(x_1)\phi_2(x_2,x_1)\phi_3(x_3,x_2) \\
&\times \phi_4(l_1)\phi_5(l_2) \\
&\times \phi_6(x_1) \\
&\times \phi_7(x_1,l_1)\phi_8(x_2,l_1)\phi_9(x_3,l_2)
\end{aligned}
\]
应该注意到因子与原先概率密度的关系,比如\(\phi_7(x_1,l_1)=l(x_1,l_1;z_1) \propto p(z_1|x_1,l_1)\)。
对于任意的因子图,MAP问题转换成了最大化因子乘积:
\[\begin{aligned}
X^{MAP} &= \underset{X}{\text{argmax}} \: \phi(X) \\
&= \underset{X}{\text{argmax}} \: \prod_i \phi_i(X_i)
\end{aligned}
\]
假设所有的因子服从零均值高斯分布(zero-mean normal distribution),则
\[\phi_i(X_i) \propto exp(-\frac{1}{2}\parallel h_i(X_i) - z_i \parallel ^{2}_{\Sigma_i})
\]
取负对数,并去除系数\(1/2\)转为非线性最小二乘问题
\[X^{MAP} = \underset{X}{\text{argmin}} \: \Sigma_i\parallel h_i(X_i) - z_i \parallel ^{2}_{\Sigma_i}
\]
线性化求解非线性问题:
令\(h(X_i)=h_i(X^0_i + \Delta_i) \approx h_i(X^0_i) + H_i\Delta_i\)
其中\(H_i\)为测量雅可比矩阵
\[H_i = \left.\begin{matrix}\frac{\partial h(X_i)}{\partial X_i} \end{matrix}\right|_{X^0_i} \\
\Delta_i \triangleq X_i - X^0_i
\]
\[\parallel e \parallel ^{2}_{\Sigma} \triangleq e^\top\Sigma^{-1}e = (\Sigma^{-1/2}e)^\top(\Sigma^{-1/2}e) = \parallel \Sigma^{-1/2}e \parallel^2_2
\]
上面的过程也叫作白化,误差除以测量标准差,消除了量纲,这样可以将不同类型的误差放在一起处理。
代替最小二乘问题:
\[\begin{aligned}
\Delta^* &= \underset{\Delta}{\text{argmin}} \: \sum_i\parallel H_i\Delta_i - \{ z_i - h_i(X^0_i) \} \parallel ^{2}_{\Sigma_i} \\
&= \underset{\Delta}{\text{argmin}} \: \sum_i\parallel \underbrace{A_i}_{\Sigma_i^{-1/2}H_i}\Delta_i - \underbrace{b_i}_{\Sigma_i^{-1/2}(z_i - h_i(X^0_i))} \parallel ^{2}_{2} \\
&= \underset{\Delta}{\text{argmin}} \: \parallel A\Delta - b \parallel
\end{aligned}
\]
假设矩阵\(A_{m \times n}\)列满秩,通常情况下\(m \ge n\),那么最小二乘问题有唯一解:
\[A^{\top}A \Delta = A^{\top} \mathbf{b}
\]
此时\(A^{\top}A\)正定。
cholesky法求解
其中\(A^{\top}A\)是实对称正定矩阵,Cholesky factorization后信息矩阵 \(\Lambda \triangleq A^{\top}A = R^{\top}R\),其中\(R\)是上三角矩阵。
\[A^{\top}A \Delta = A^{\top} \mathbf{b} \rightarrow \\
R^{\top}R \Delta = A^{\top} \mathbf{b} \rightarrow \\
R^{\top} \mathbf{y} = A^{\top} \mathbf{b}
\]
先求解\(\mathbf{y}\)再求解\(\Delta\)
QR法求解
\[H_{n} \ldots H_{2} H_{1} A = Q_{m \times m}^{\top} A_{m \times n} = \left[\begin{array}{l} R_{n \times n} \\ 0_{(m -n) \times n} \end{array}\right]
\]
QR Decomposition with Householder Reflections
与Gram-Schmidt正交化操作相比,Householder reflections在QR分解中更常用。Householder reflections是另外一种正交变换(orthogonal transformation),它可以将一个向量\(\mathbf{x}\)变换到一个与之平行的向量\(\mathbf{y}\)。
\[H = I - 2vv^T
\]
\[\|A \Delta - b \|_{2}^{2} = \left \| Q^{\top} A \Delta - Q^{\top} b \right \|_{2}^{2} = \|R \Delta - d \|_{2}^{2} + \| e \|_{2}^{2}
\]
其中
\[Q^{\top} b = \left[\begin{array}{l}
d \\ e
\end{array}\right]
\]
\(\|e\|^{2}\)是QR分解的残差,与\(\Delta\)无关。

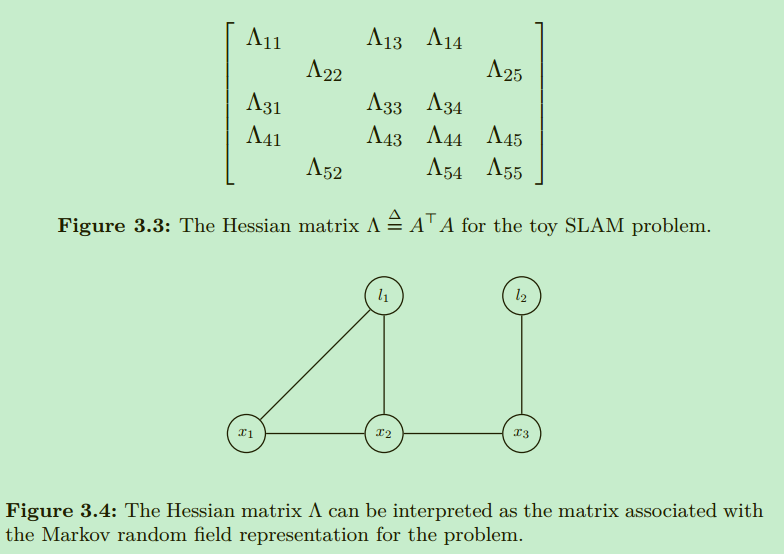
\(\Lambda\)被称作信息矩阵可以和另一种无向图模型(undirected graphical model)马科夫随机场联系起来。\(\Lambda\)是\(G\)的伴随矩阵。后续不采用MRF而是使用因子图,是因为因子图可以表达更细粒度的因子化,更贴近于原始问题方程。
Elimination Algorithm
边缘化marginalization
one solution is to remove older variables without removing information
消除算法可以将因子图转换回贝叶斯网络(有向无环图),但是只关注未知变量\(X\)。对于任意形式为\(\phi(X) = \phi(x_1,x_2, \dots, x_n)\)的因子图,变量消除算法可以将这样的因子图转换为因子化的贝叶斯网络,概率密度函数的形式为:
\[p(X) = p(x_1|S_1)p(x_2|S_2) \dots p(x_n)
\]

稀疏高斯因子

\[\begin{aligned}
\phi(l_1,l_2,x_1,x_2,x_3) &= \phi_1(x_1)\phi_2(x_2,x_1)\phi_3(x_3,x_2) \\
&\times \phi_4(l_1)\phi_5(l_2) \\
&\times \phi_6(x_1) \\
&\times \phi_7(x_1,l_1)\phi_8(x_2,l_1)\phi_9(x_3,l_2)
\end{aligned}
\]
\[\phi_i(X_i) \propto \operatorname{exp} \left\{ -\frac{1}{2} \left\| A_iX_i - b_i \right\|^2_2 \right\}
\]
\(X_i\)是与因子\(\phi_i\)相关的变量,例如\(\phi_7\),\(X_7 = \{ x_1;l_1\}\),分号在这里表示列方向级联。
\[\phi_7(X_7) = \operatorname{exp} \left\{ -\frac{1}{2} \left\| A_{71}l_1 + A_{73}x_1 - b_7 \right\|^2_2 \right\}
\]
令\(A_7 = [A_{71}|A_{73}]\),则
\[\phi_7(X_7) = \operatorname{exp} \left\{ -\frac{1}{2} \left\| A_7X_7 - b_7 \right\|^2_2 \right\}
\]
\[\begin{aligned}
\psi(x_j,S_j) &= \prod_i \phi_i(X_i) \\
&= \operatorname{exp} \left\{ -\frac{1}{2} \sum_i \left\| A_{i}X_i - b_i \right\|^2_2 \right\} \\
&= \operatorname{exp} \left\{ -\frac{1}{2} \left\| \bar{A}_{j}[x_j;S_j] - \bar{b}_j \right\|^2_2 \right\}
\end{aligned}
\]
这里以消除\(l_1\)\(为例,与其相邻的因子有\)\phi_4,\phi_7,\phi_8$,因此
\[\begin{aligned}
\psi(l_1,\{x_1;x_2\}) &= \operatorname{exp} \left\{ -\frac{1}{2} \left\| \bar{A}_{1}[l_1;x_1;x_2] - \bar{b}_1 \right\|^2_2 \right\}
\end{aligned}
\]
其中:
\[\bar{A}_{1} = \begin{bmatrix}
A_{41} & & \\
A_{71} & A_{73} & \\
A_{81} & & A_{84}
\end{bmatrix},
\bar{b}_1 = \begin{bmatrix}
b_4 \\
b_7 \\
b_8
\end{bmatrix}
\]
这一步只是将多个求和的因子整合到一个大矩阵中。
使用Partial QR消除变量
使用partial QR-factorization将\(\psi(x_j,S_j)\)中提取的增广矩阵\([\bar{A}_{j}|\bar{b}_{j}]\)变换为:
\[[\bar{A}_{j}|\bar{b}_{j}] = Q\begin{bmatrix}
R_j & T_j & d_j \\
&\tilde{A}_\tau & \tilde{b}_\tau
\end{bmatrix}
\]
其中\(Q\)为单位正交阵,\(R_j\)为上三角矩阵。
\[\psi(x_j,S_j) = \operatorname{exp} \left\{ -\frac{1}{2} \left\| \bar{A}_{j}[x_j;S_j] - \bar{b}_j \right\|^2_2 \right\}
\]
\[\begin{aligned}
\left\| \bar{A}_{j}[x_j;S_j] - \bar{b}_j \right\|^2_2 &= \left\| Q(\begin{bmatrix}
R_j & T_j \\
&\tilde{A}_\tau
\end{bmatrix}\begin{bmatrix}x_j \\ S_j \end{bmatrix} - \begin{bmatrix}d_j \\ \tilde{b}_\tau \end{bmatrix}) \right\|^2_2 \\
&= \left\| R_jx_j + T_jS_j - d_j \right\|^2_2 + \left\| \tilde{A}_\tau S_j - \tilde{b}_\tau \right\|^2_2
\end{aligned}
\]
因此
\[\begin{aligned}
\psi(x_j,S_j) &= \operatorname{exp} \left\{ -\frac{1}{2} \left\| R_jx_j + T_jS_j - d_j \right\|^2_2 \right\}\operatorname{exp} \left\{ -\frac{1}{2} \left\| \tilde{A}_\tau S_j - \tilde{b}_\tau \right\|^2_2 \right\} \\
&= p(x_j|S_j)p(S_j)
\end{aligned}
\]
比如消除变量\(l_1\),此时
\[\psi(l_1,\{x_1, x_2\}) = \operatorname{exp} \left\{ -\frac{1}{2} \left\| R_1 l_1 + [T_{13}|T_{14}][x_1;x_2] - d_1 \right\|^2_2 \right\}\operatorname{exp} \left\{ -\frac{1}{2} \left\| [\tilde{A}_{13}|\tilde{A}_{14}] [x_1;x_2] - \tilde{b}_1 \right\|^2_2 \right\}
\]
\[\left[{\begin{array}{c|c}
\begin{matrix}
& &A_{13} & & \\
& &A_{23} &A_{24} & \\
& & &A_{34} &A_{35} \\
A_{41} \\
&A_{52} \\
& &A_{63} \\
A_{71} & &A_{73} \\
A_{81} & & &A_{84} \\
&A_{92} & & &A_{95}
\end{matrix}
& \begin{matrix}
b_1 \\ b_2 \\ b_3 \\ b_4 \\ b_5 \\ b_5 \\ b_6 \\b_7 \\ b_8 \\ b_9
\end{matrix}
\end{array}} \right] \rightarrow
\left[
{\begin{array}{c|cccc|c}
R_1 & &T_{13} &T_{14} & &d_1\\
\hline & &A_{13} & & &b_1\\
& &A_{23} &A_{24} & &b_2\\
& & &A_{34} &A_{35} &b_3\\
&A_{52} & & & &b_5 \\
& &A_{63} & & &b_6 \\
&A_{92} & & &A_{95} &b_9 \\
\hline & &\tilde{A}_{13} &\tilde{A}_{14} & &\tilde{b}_1
\end{array}}
\right]
\]
后续消除后的结果:
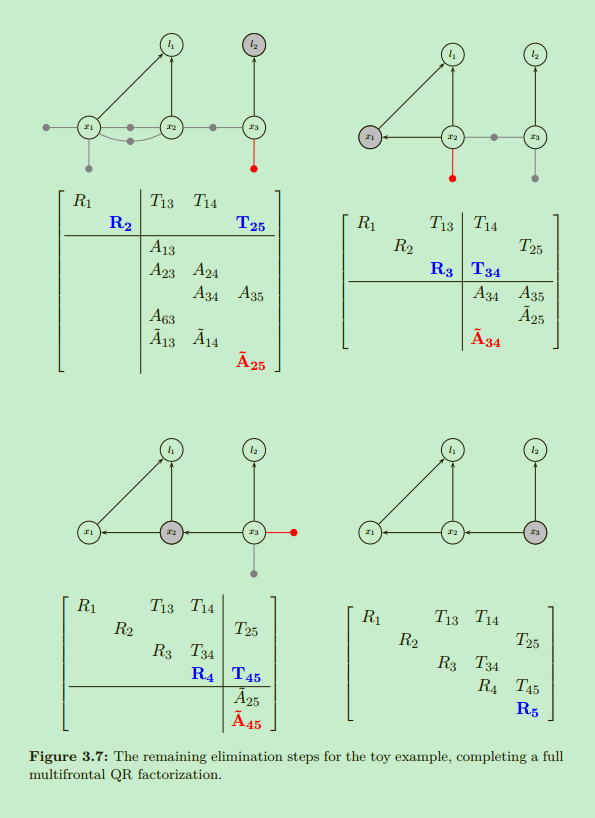
a Bayes net is a directed acyclic graph (DAG), and that is exactly the “uppertriangular” property for matrices.
贝叶斯网络是一个有向无环图,相关的矩阵具有可转为上三角矩阵的特性。
转换后的贝叶斯网络很明显是个上三角矩阵,使用倒推法即可倒序求解问题。
Elimination Ordering
消除的顺序对于性能有很大的影响。假设消除所有变量的开销为:
\[f\left(\Phi_{1: n}\right) = \sum_{j=1}^{n} g\left(\Phi_{j: n}, x_{j}\right)
\]
其中\(g\left(\Phi_{j: n}, x_{j}\right)\)为从剩下的图结构\(\Phi_{j: n}\)中消除变量\(x_j\)的计算开销。而每一步变量消除的开销主要在partial QR factorization上面。对于一个\(m_k \times n_k\)的矩阵来说,QR分解需要\(4m_kn_k\)次浮点运算,那么总开销可以近似为:
\[g\left(\Phi_{j: n}, x_{j}\right) \approx \sum_{k=1}^{n_{j}} 4 m_{k} n_{k}=\sum_{k=1}^{n_{j}} 4\left(m_{j}-k\right)\left(n_{j}+s_{j}+1-k\right)
\]
其中\(n_j\)为待消除变量\(x_j\)的维数,\(s_j\)为\(S_j\)中变量的个数,\(m_j\)为增广矩阵\([\bar{A}_{j}|\bar{b}_{j}]\)的行数。对于一个\(m \times n\)稠密矩阵矩阵做QR分解所需算力为:
\(f\left(\Phi_{1: n}\right)=\sum_{k=1}^{n-1} 4(m-k)(n+1-k)=2(m-n / 3) n^{2}+O(m n)\)
这里假设路标\(l\)为3维,位姿为\(x,y,\theta\)三自由度。则第一步消除(假设稠密矩阵):4(39)(35+1) = 1728, 第二步消除:4(38)(34+1) = 1248。这里的计算和书中的有出入。\(f\left(\Phi_{1: 5}\right)=1752+1304+1256+608+152=5072 \text { flops}\)
但实际上对于稀疏矩阵来说:\(f\left(\Phi_{1: 5}\right)=32+20+488+488+128=1156 \text { flops }\)。可以看到稀疏矩阵比稠密矩阵的所需的计算少了很多。
变量消除顺序
变量消除顺序对于计算量的影响很大,不同的消除顺序会将因子图转为不同结构的贝叶斯网络,但是描述的是等价的MAP估计。
COLAMD and METIS are best overall performers.The Schur complement trick is an often-used technique in computer vision.
Updating a Matrix Factorization
\[\begin{aligned}
\Delta^* &= \underset{\Delta}{\text{argmin}} \: \sum_i\parallel H_i\Delta_i - \{ z_i - h_i(X^0_i) \} \parallel ^{2}_{\Sigma_i} \\
&= \underset{\Delta}{\text{argmin}} \: \sum_i\parallel \underbrace{A_i}_{\Sigma_i^{-1/2}H_i}\Delta_i - \underbrace{b_i}_{\Sigma_i^{-1/2}(z_i - h_i(X^0_i))} \parallel ^{2}_{2} \\
&= \underset{\Delta}{\text{argmin}} \: \parallel A\Delta - b \parallel
\end{aligned}
\]
而
\[\|A \Delta-b\|_{2}^{2}=\left\|Q^{\top} A \Delta-Q^{\top} b\right\|_{2}^{2}=\|R \Delta-d\|_{2}^{2} + \|e\|_{2}^{2} \\
Q^{\top} b = \left[\begin{array}{l}
d \\ e
\end{array}\right]
\]
当有新的测量值时,假设所带来的影响为\(A' =\left[\begin{array}{l} A \\ a^\top \end{array}\right],b' = \left[\begin{array}{l} b \\ \beta \end{array}\right]\)。构造新的正交矩阵\(Q'\)为
\[Q' = \left[\begin{array}{l}
Q_{m \times m} & 0_{m \times 1} \\ 0_{1 \times m} & 1_{1 \times 1}
\end{array}\right]
\]
此时
\[\left\| A' \Delta - b' \right\|_{2}^{2} = \left\| Q'^{\top} A' \Delta - Q'^{\top} b' \right\|_{2}^{2} \\
\left[\begin{array}{l}
Q^{\top}_{m \times m} & 0_{m \times 1} \\ 0_{1 \times m} & 1_{1 \times 1}
\end{array}\right]
\left[\begin{array}{l}
A_{m \times n} \\ a^\top_{1 \times n}
\end{array}\right] = \left[\begin{array}{l} R_{n \times n} \\ 0_{(m -n) \times n} \\ a^\top_{1 \times n} \end{array}\right] = R_a, \quad
\left[\begin{array}{l}
Q^{\top}_{m \times m} & 0_{m \times 1} \\ 0_{1 \times m} & 1_{1 \times 1}
\end{array}\right] \left[\begin{array}{l} b_{m \times 1} \\ \beta_{1 \times 1} \end{array}\right] = \left[\begin{array}{l} d_{n \times 1} \\ e_{(m-n) \times 1} \\\beta_{1 \times 1} \end{array}\right]
\]
实际上还有:
\[\left\| A' \Delta - b' \right\|_{2}^{2} = \left\| \left[\begin{array}{l} A \\ a^\top \end{array}\right]\Delta - \left[\begin{array}{l} b \\ \beta \end{array}\right] \right\|_{2}^{2} = \left\| A\Delta - b \right\|_{2}^{2} + \left\| a^{\top}\Delta - \beta \right\|_{2}^{2}
\]
我们希望\(R_a\)满足这样的形式:
\[R_a = \left[\begin{array}{l}
R' \\
0
\end{array}\right]
\]
使用旋转的方式来更新矩阵分解在数值上更稳定也更精确,给定的旋转为:
\[G = \left[\begin{array}{l}
\text{cos}\phi & \text{sin}\phi \\ -\text{sin}\phi & \text{cos}\phi
\end{array}\right]
\]
挑选参数\(\phi\)可以使\(A\)中的第\((i,j)^{th}\)个元素为0。

上图中最左边的矩阵为\(G\)实际的形式,可以将R中的x位置元素变为0。通过一系列的旋转操作将新添加的行变0,这样以来:
\[G_{j_k} \dots G_{j_2}G_{j_1}R_a = \left[\begin{array}{l} R_{n \times n}' \\ 0_{(m - n + 1) \times n} \end{array}\right]
\]
显然这些\(G\)都是正交矩阵,因此
\[\begin{aligned}
\|A' \Delta - b' \|_{2}^{2} &= \left\| Q'^{\top} A' \Delta - Q'^{\top} b' \right\|_{2}^{2} \\
&= \left\| G_{j_k} \dots G_{j_2}G_{j_1}[Q'^{\top} A' \Delta - Q'^{\top} b'] \right\|_{2}^{2} \\
&= \left\| \left[\begin{array}{l} R_{n \times n}' \\ 0_{(m - n + 1) \times n} \end{array}\right] \Delta -\left[\begin{array}{l} d_{n \times 1}' \\ e_{(m - n + 1) \times 1} \end{array}\right] \right\|_{2}^{2} \\
&= \|R_{n \times n}' \Delta - d' \|_{2}^{2} + \| e_{(m - n + 1) \times 1} \|_{2}^{2}
\end{aligned}
\]
The Bayes tree
clique: 一个无向图中,满足两两之间有边连接的顶点的集合,被称为该无向图的团。
chord(弦): 环中的一条连接两个非邻顶点的边;
chordal(弦图): 任何长度超过3的环有一个chord;
在求解非线性问题的时候,矩阵分解的方法没法很好的处理,因此我们引入新的图模型Bayes tree。在推理方面,树结构的图效率很高。构建树结构图模型的步骤:
- 使用变量消除将因子图转换为贝叶斯网络;
- 在贝叶斯网络的cliques中找出一个树结构;
为了检测贝叶斯网络中的团结构(clique),可能需要把贝叶斯网络重写为贝叶斯树。虽然不能明显的看出贝叶斯网络中的团可以形成一个树结构,但是由于弦的属性,事实确实是这样。罗列出无向树中所有的团就是一个团树(clique tree)。

贝叶斯树是一棵有向树,节点代表潜在的弦图贝叶斯网络中的团\(C_k\)。定义每个节点的条件概率密度为\(p(F_k|S_k)\),分隔因子\(S_k\)是团\(C_k\)与父团\(\prod_k\)的交集。
贝叶斯树更新
增量推导只需要对贝叶斯树做简单的更新。相比于抽象的增量矩阵分解过程,增量更新贝叶斯树可以提供一种更好的解释和理解方式。当一个新的测量值带来一个因子,比如该测量值与有两个变量有关,将会引入一个新的二元因子\(f(x_j,x_{j'})\),只有包含\(x_j,x_{j'}\)的团之间的边和root节点受影响,这些团下面的子树和其他不包含\(x_j,x_{j'}\)的子树并不会受影响。因此,贝叶斯树更新的过程就是,将树中受影响的部分转换回因子图,然后将新测量相关的新因子添加进去。使用任何便捷的消除方法对这个临时的因子图做消除操作,形成新的贝叶斯树,未受影响的子树再添加上去。
贝叶斯树的两个重要属性保证了只有树的顶部部分会被影响。贝叶树形成于弦图贝叶斯网络的逆向消除顺序,因此团中的变量是从他们的子团消除过程中收集到信息,这就导致任何团中信息只向其根节点方向传播。其次,只有当与因子相关的第一个变量被消除时,该因子的信息才进入消除状态。

流型上的优化
增量旋转
使用轴角\((\bar{\omega},\theta)\)来表示三维旋转更加符合向量值增量的表示形式,\(\bar{\omega} \in S^2\)是球面上的单位向量,表示旋转操作的旋转轴,\(\theta\)是绕该向量旋转的角度。\(\xi = \bar{\omega}\theta \in \mathbb{R}^3\),对于一个很小的\(\theta\)有
\[R(\xi) \approx \left[ \begin{array}{}
1 & -\xi_{z} & \xi_{y} \\
\xi_{z} & 1 & -\xi_{x} \\
-\xi_{y} & \xi_{x} & 1
\end{array} \right] = I + \hat{\xi} \\
\hat{\xi} \triangleq \left[\begin{array}{ccc}
0 & -\xi_{z} & \xi_{y} \\
\xi_{z} & 0 & -\xi_{x} \\
-\xi_{y} & \xi_{x} & 0
\end{array}\right]
\]
其中\(\hat{\xi}\)是\(\xi\)的斜对称矩阵。
指数映射
相比于上面的近似,指数映射可以将三维增量\(\xi\)映射为精确的旋转。
\[\exp \hat{\xi} \triangleq \sum_{k=0}^{\infty} \frac{1}{k !} \hat{\xi}^{k}=I+\hat{\xi}+\frac{\hat{\xi}^{2}}{2 !}+\frac{\hat{\xi}^{3}}{3 !}+\ldots
\]
实际上指数映射对于任意大的向量\(\xi\)都有效,这就罗格里德斯公式:
\[\exp \hat{\xi} = I + \frac{\sin \theta}{\theta}\hat{\xi} + \frac{1 - \cos \theta}{\theta ^2}\hat{\xi}^2
\]
局部坐标
指数映射可以将一个局部坐标(Local Coordinates)向量\(\xi \in \mathbb{R}^3\)映射到待评估旋转值\(R_0 \in SO(3)\)的附近。
\[R_{0} \oplus \xi \triangleq R_{0} \cdot \exp \hat{\xi}
\]
指数化局部坐标\(\xi\)将会带来以\(R_0\)为基础的增量旋转。
平面旋转
对于平面旋转来说,\(\xi \in \mathbb{R}\),
\[\hat{\xi} \triangleq\left[\begin{array}{cc}
0 & -\xi \\
\xi & 0
\end{array}\right]
\]
\[\exp \hat{\xi} \triangleq \sum_{k=0}^{\infty} \frac{1}{k !} \hat{\xi}^{k} = \left[\begin{array}{cc}
1-\xi^{2} / 2 \ldots & -\xi+\xi^{3} / 6 \ldots \\
\xi-\xi^{3} / 6 \ldots & 1-\xi^{2} / 2 \ldots
\end{array}\right]=\left[\begin{array}{cc}
\cos \xi & -\sin \xi \\
\sin \xi & \cos \xi
\end{array}\right]
\]
\[\begin{aligned}
R_{0} \oplus \xi & \triangleq R_{0} \cdot \exp \hat{\xi} \\
&=\left[\begin{array}{cc}
\cos \theta_{0} & -\sin \theta_{0} \\
\sin \theta_{0} & \cos \theta_{0}
\end{array}\right]\left[\begin{array}{cc}
\cos \xi & -\sin \xi \\
\sin \xi & \cos \xi
\end{array}\right] \\
&=\left[\begin{array}{cc}
\cos \left(\theta_{0}+\xi\right) & -\sin \left(\theta_{0}+\xi\right) \\
\sin \left(\theta_{0}+\xi\right) & \cos \left(\theta_{0}+\xi\right)
\end{array}\right]
\end{aligned}
\]
局部位置坐标
假设在有限的时间\(\Delta \tau\)内角速度为\(\omega\),平移速度为\(v\),局部位置坐标\(\xi\)为:
\[\xi = \left[ \begin{array}{c} \omega \\ v \end{array} \right] \Delta \tau
\]
hat操作符定义为:
\[\hat{ }:\left[\begin{array}{l}
\omega \\
v
\end{array}\right] \longmapsto \left[\begin{array}{ll}
\hat{\omega} & v \\
0 & 0
\end{array}\right]
\]
\(SE(2)\)的hat操作:
\[\hat{} : \mathbb{R}^{3} \rightarrow \mathfrak{s e}(2): \xi \mapsto \left[\begin{array}{cc|c}
0 & -\omega_{z} & v_{x} \\
\omega_{z} & 0 & v_{y} \\
\hline 0 & 0 & 0
\end{array}\right] \Delta \tau
\]
\(SE(3)\)的hat操作:
\[\hat{}: \mathbb{R}^{6} \rightarrow \mathfrak{s e}(3): \xi \mapsto\left[\begin{array}{ccc|c}
0 & -\omega_{z} & \omega_{y} & v_{x} \\
\omega_{z} & 0 & -\omega_{x} & v_{y} \\
-\omega_{y} & \omega_{x} & 0 & v_{z} \\
\hline 0 & 0 & 0 & 0
\end{array}\right] \Delta \tau
\]
我们可以使用指数映射将一个局部位置坐标映射到初始评估位姿\(x_0\)附近:
\[x_0 \oplus \xi = x_0 \cdot \exp \hat{\xi}
\]
矩阵李群
hat操作符将一个向量\(\xi\)映射到李代数\(\mathfrak{g}\):
\[\hat{}:\mathbb{R}^n \rightarrow \mathfrak{g},\xi \mapsto \hat{\xi}
\]
逆操作vee操作符:
\[{}^\vee: \mathfrak{g} \rightarrow \mathbb{R}^n, \hat{\xi} \mapsto \xi
\]
指数映射可以将局部坐标\(\xi\)映射到任何初始评估点\(a \in G\)的附近:
\[a \oplus \xi \triangleq a \cdot \exp \hat{\xi}
\]
General Manifolds and Retractions
不满足群结构的流型\(\mathcal{M}\)上也可以做上述的映射操作:
retraction \(\mathcal{R}_a: \mathcal{M} \times \mathbb{R}^n \rightarrow \mathcal{M}\)
\[a \oplus \xi \triangleq \mathcal{R}_a(\xi), a \in \mathcal{M}
\]
retraction定义在一般流型上,hat操作是定义在群上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号