
一个简单的文本处理程序(有道翻译单词导出至墨墨背单词)
如下为墨墨的导入要求
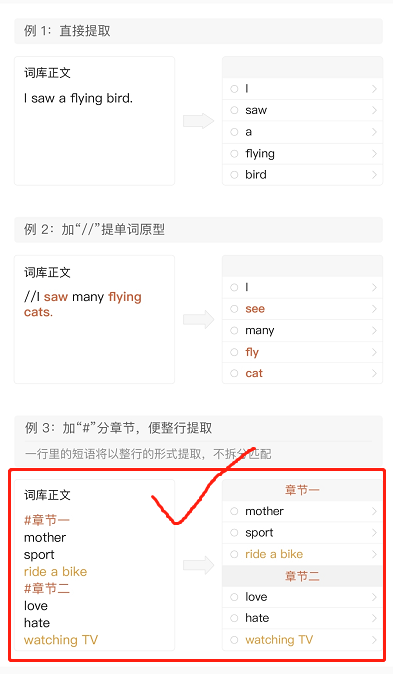
很明显,例3的导入方法是最好的;
有道单词导出
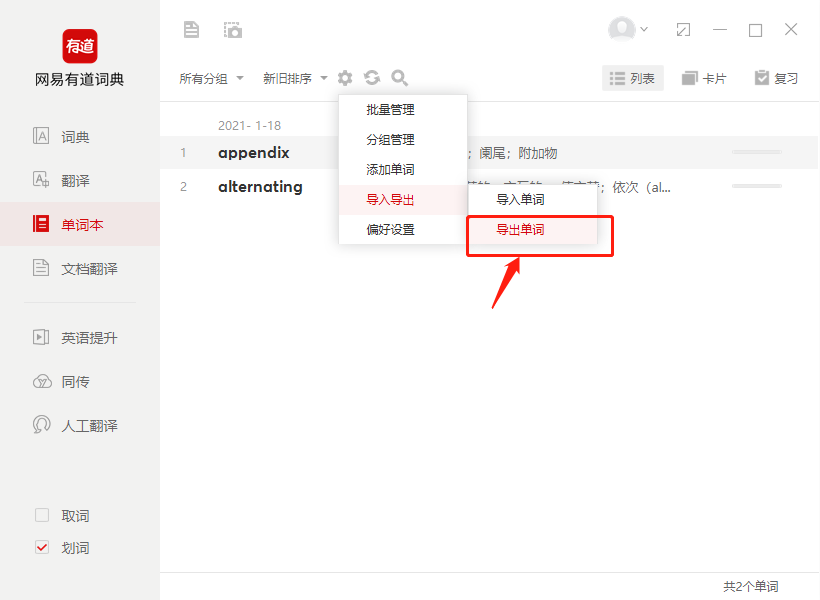
选择txt导出后发现文本编码方式为UTF-16 LE 并不能直接用于文本处理 ,shift+ctrl+s 另存为UTF-8即可
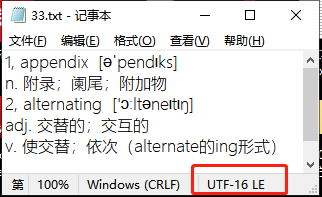
观察文本结构可以发现,每个单词前后都有一个空格,使用split(" ")分割每一行后,第2个元素就是单词,这就很好处理了;
附代码
fd = open('1.txt') #待处理文本 fd_w = open('2.txt','w+') #待生成文本 for line in fd.readlines(): #读取每一行 word_all = line.split(" ") #每一行的词以空格划分 if len(word_all)>1 and word_all[1].isalpha(): #len大于1是要去掉一些无用行 isalpha用于判断字符串是否全为英文 fd_w.write(word_all[1]+"\n")#将取出的词添加到待生成文本里 fd.close() fd_w.close()
文本1.txt

1, abbreviations [əˌbri:vɪˈeɪʃn]
n. [语] 缩写词,缩略语;[语] 缩写(abbreviation的复数)
2, albeit [ˌɔːlˈbiːɪt]
conj. 虽然,尽管
n. (Albeit) (美、英、马)艾乐贝特(人名)
3, alternating ['ɔːltəneɪtɪŋ]
adj. 交替的;交互的
v. 使交替;依次(alternate的ing形式)
4, antenna [ænˈtenə]
n. [电讯] 天线;[动] 触角,[昆] 触须
n. (Antenna)人名;(法)安泰纳
处理后的文本2.txt
abbreviations
albeit
alternating
antenna
appendix
嗯,但是还是有点问题,单词短语不能很好的处理,待有想法了再改进改进~~~~
单词里的汉语意思竟然有敏感词,2333~
---使用xml的方式导出
附简单的代码;
import xml.etree.ElementTree as ET tree = ET.parse("dsd.xml") c=tree.getroot() with open("w.txt","w",encoding="utf-8") as fc: for idx in c.findall("item"): nm = idx.find("trans").text oo=nm.replace("\n","").replace("\r","") fc.write("{} {}\n".format(idx.find("word").text,oo)) print(idx.find("word").text)
-------------====================分割线====================-------------
作者:戳人痛处
本博客link:https://www.cnblogs.com/hardfood/p/14293777.html
硬币,懂?
https://space.bilibili.com/68973181
标签:
python文本处理
, python文本读取


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!