spark作业在YARN上排队优化过程
一、集群现状:
集群2管理节点+14数据节点,一台数据节点硬件异常,相应进程未启动,每台主机物理cpu16c,yarn配置了15c,目前集群共有15*13=195c
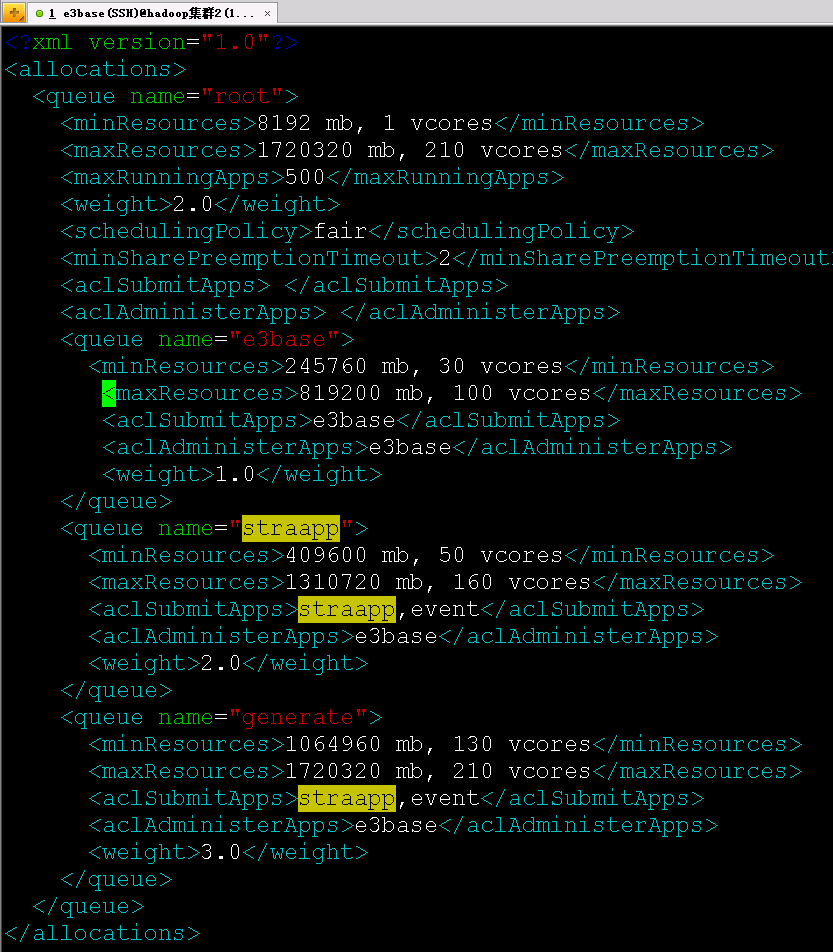
二、队列配置
集群分为straapp、e3base、generate三个队列
1、straapp跑的是mr作业
2、e3base跑的是sparksubmit,固定占用33c
3、generate跑的是业务提交的spark作业,在业务代码中写好了,每个作业占用17c
三、目前出现的问题:
(1)一台数据节点主机regionserver异常,日志请查看附件
(2)generate队列的spark作业排队,集群空闲状态下也排队。 经过观察,单个作业的执行时间并没有变慢,只是generate队列的spark作业不能并发两个以上
影响范围:
(2)generate队列的spark作业排队,集群空闲状态下也排队。 经过观察,单个作业的执行时间并没有变慢,只是generate队列的spark作业不能并发两个以上
影响范围:
目前导致规定时间内应该执行完的作业不能执行完,影响业务文件生成
具体情况如下:
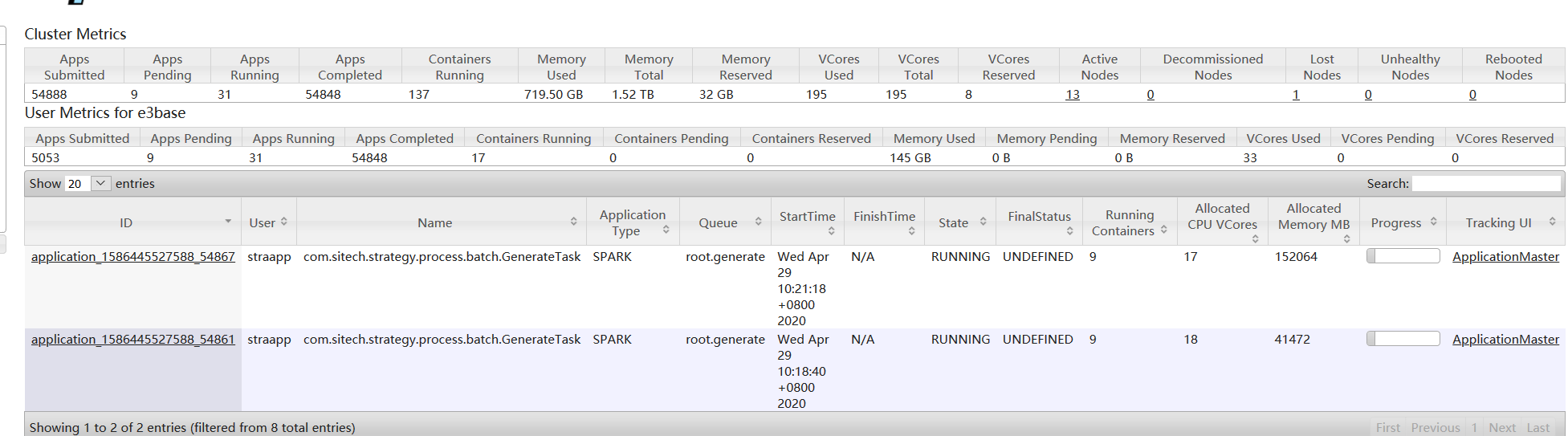
1、集群资源被用满的情况
从监控页面上可以看到,此时集群资源被用尽,按照配置,权重最大的generate应该占用最多的资源,但是generate只有35c,大部分资源被straapp的mr作业使用
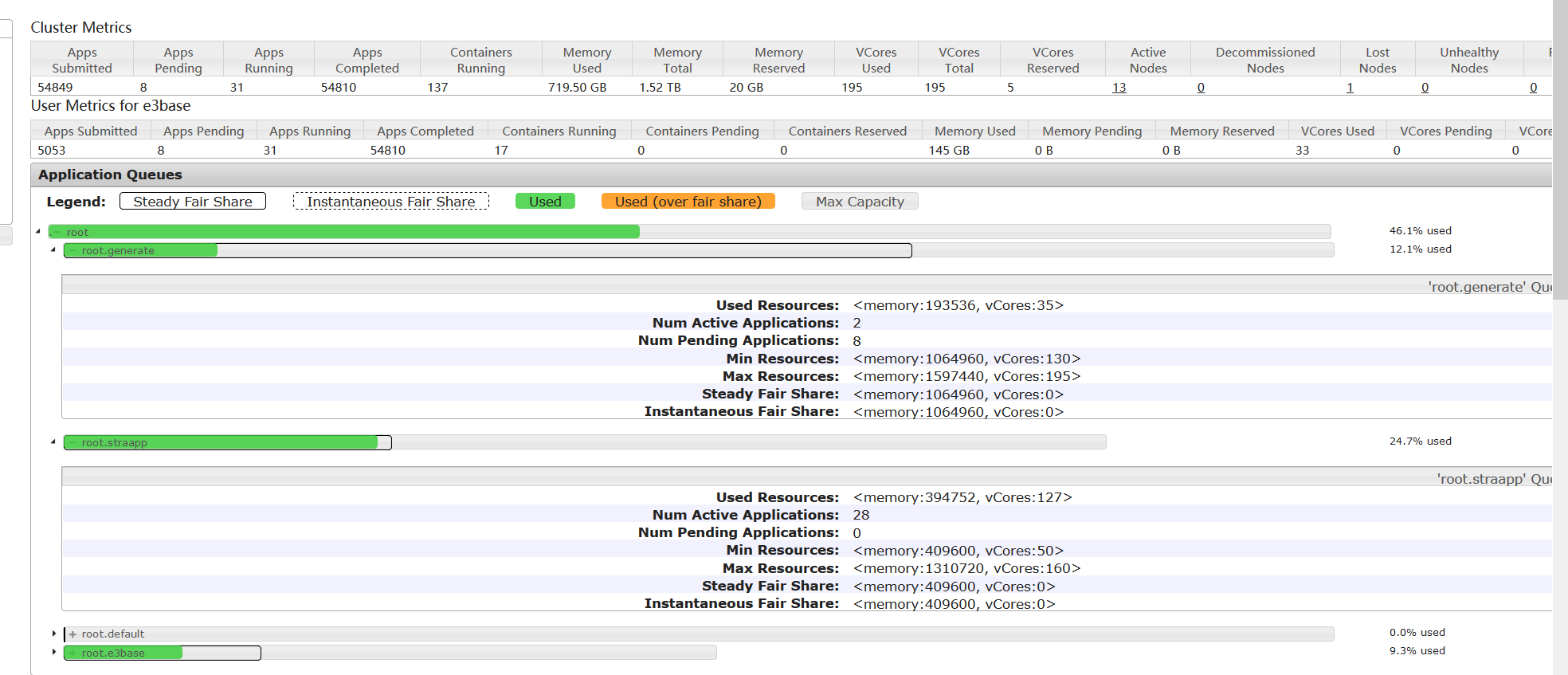
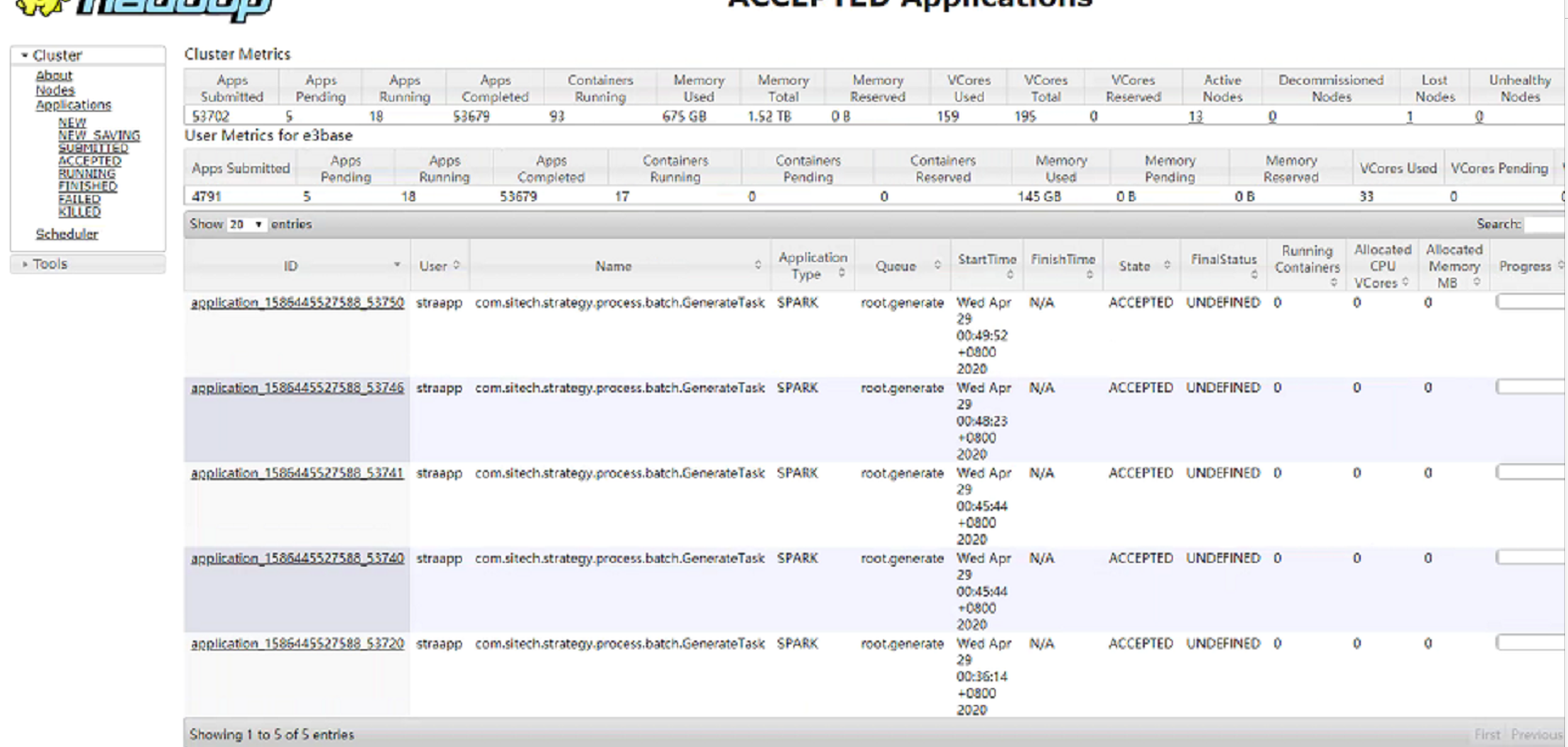
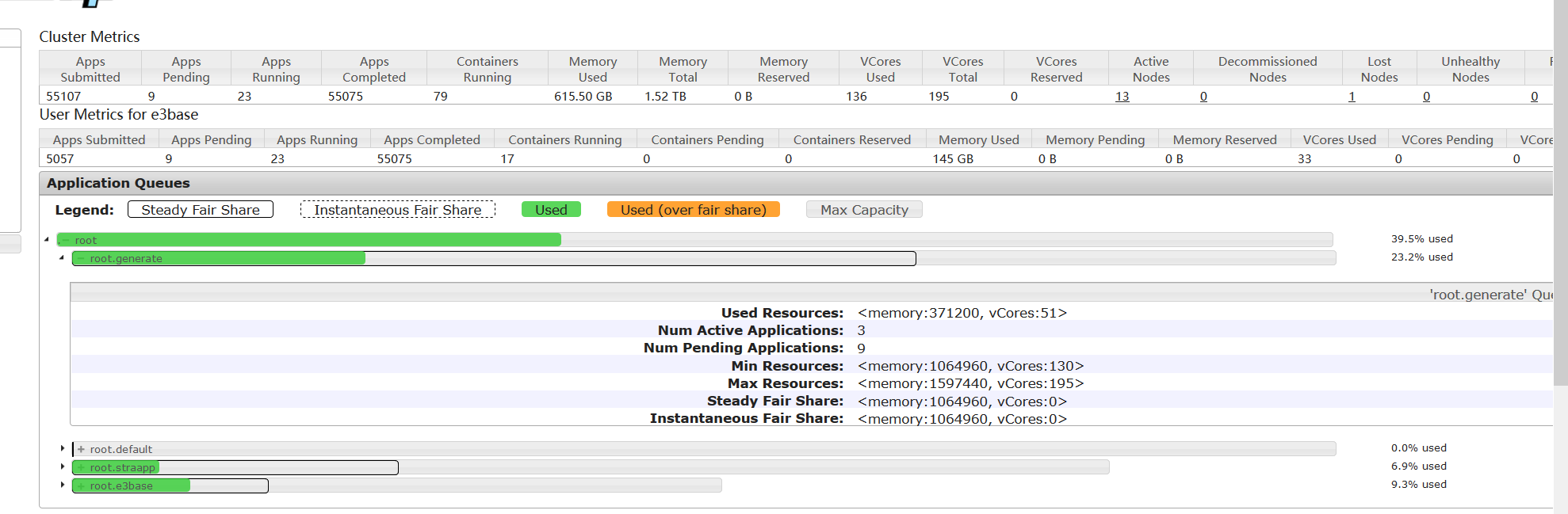
2、集群资源空闲的情况
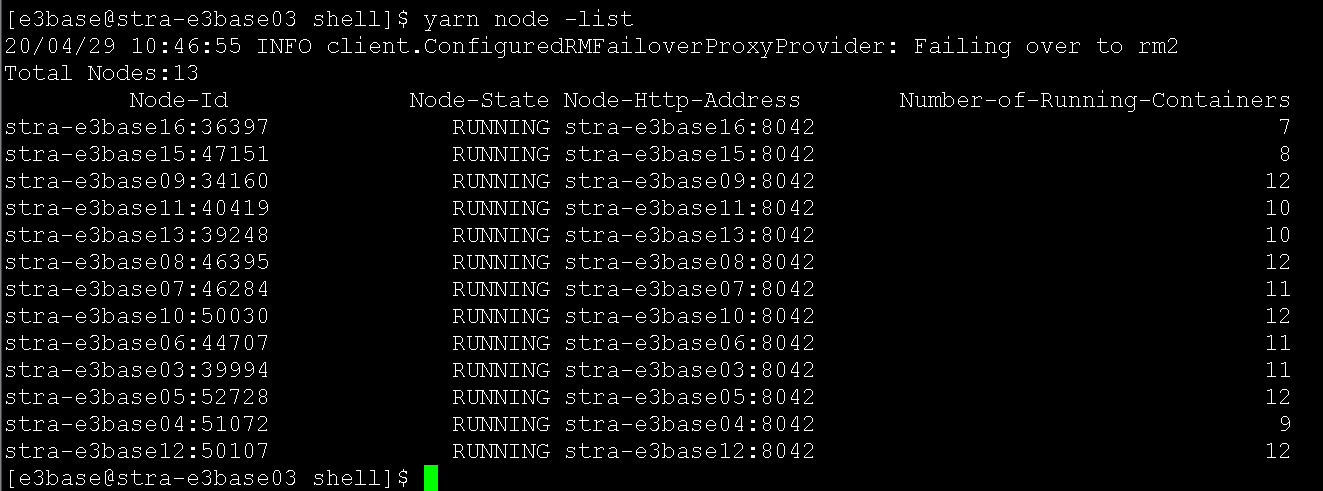
集群资源没有被用尽,straapp队列的mr作业也大部分都执行完成,但是generate还是只能同时提交两个作业,最多只占用34c、35c,其他作业全部都在accepted状态排队,只要能到running状态的作业,都能正常完成。并且同时观察各个数据节点的主机资源使用情况,cpu、磁盘等都属于比较闲的状态,yarn node -list看到有两台主机的Container个数是10,其余只有两三个,从日志看到该主机资源剩余只有1c
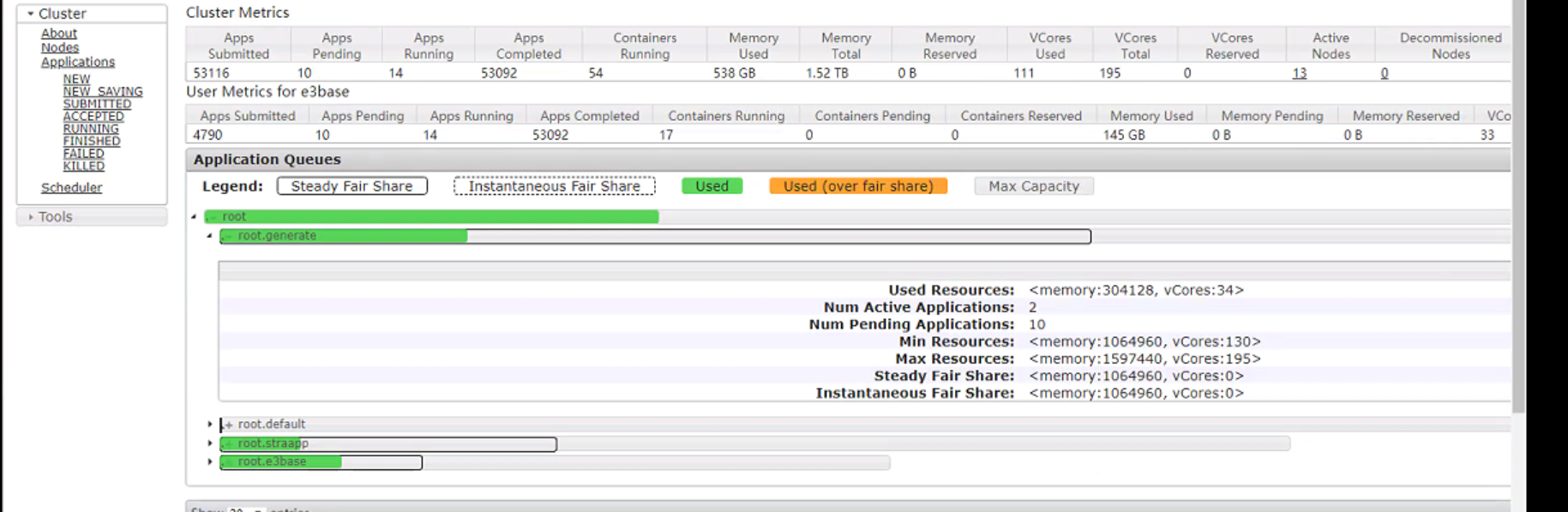
四、目前做过的测试:
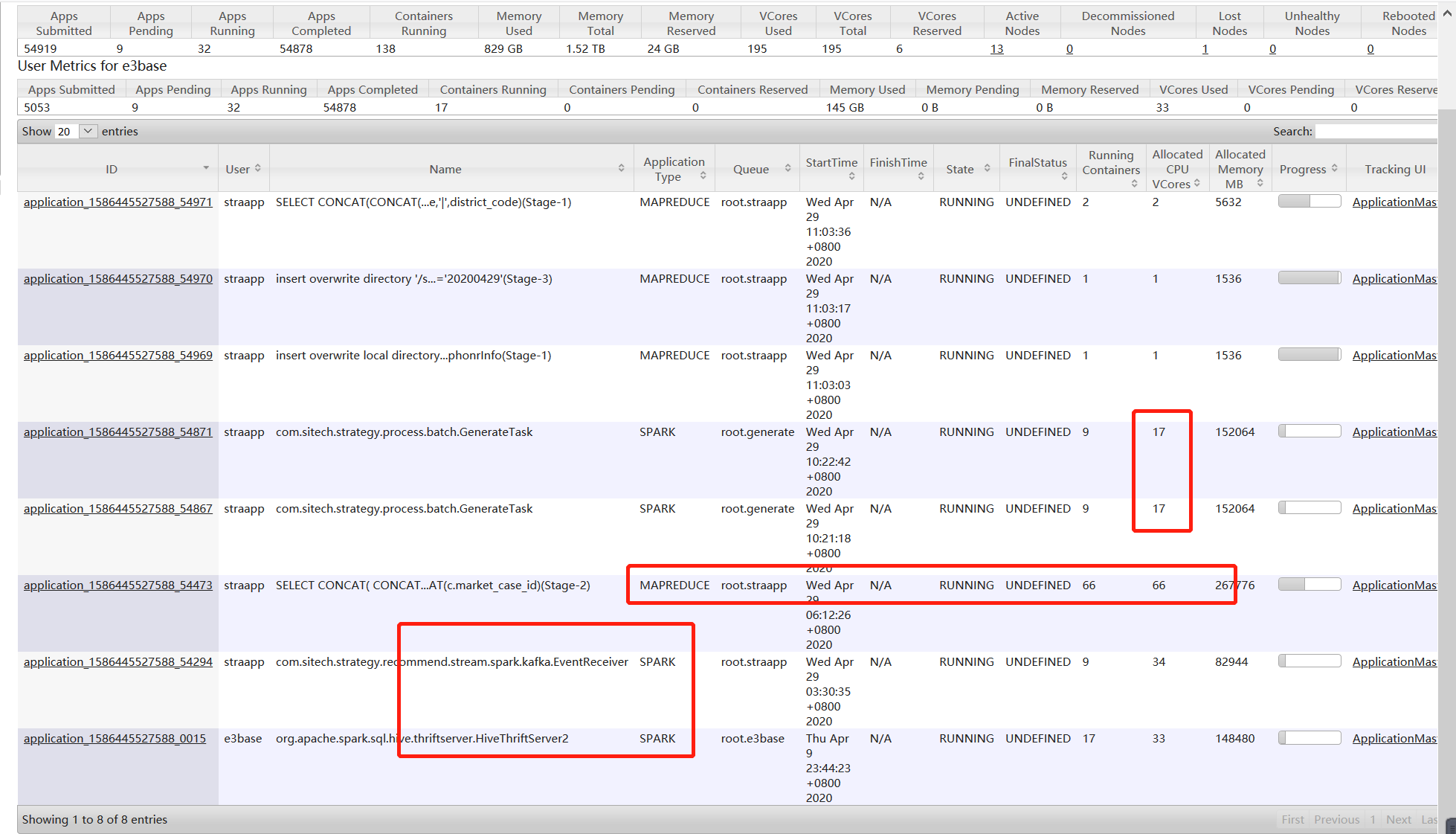
1、杀掉占用比较高的mr作业,释放资源
此时集群占用比较多的是mapreduce作业,是straapp队列,最下面的kafka和spark thriftserver是两个长进程,一直存在的,现场测试过把这个占用比较高的mr作业杀掉,释放集群资源,spark的并发还是上不去
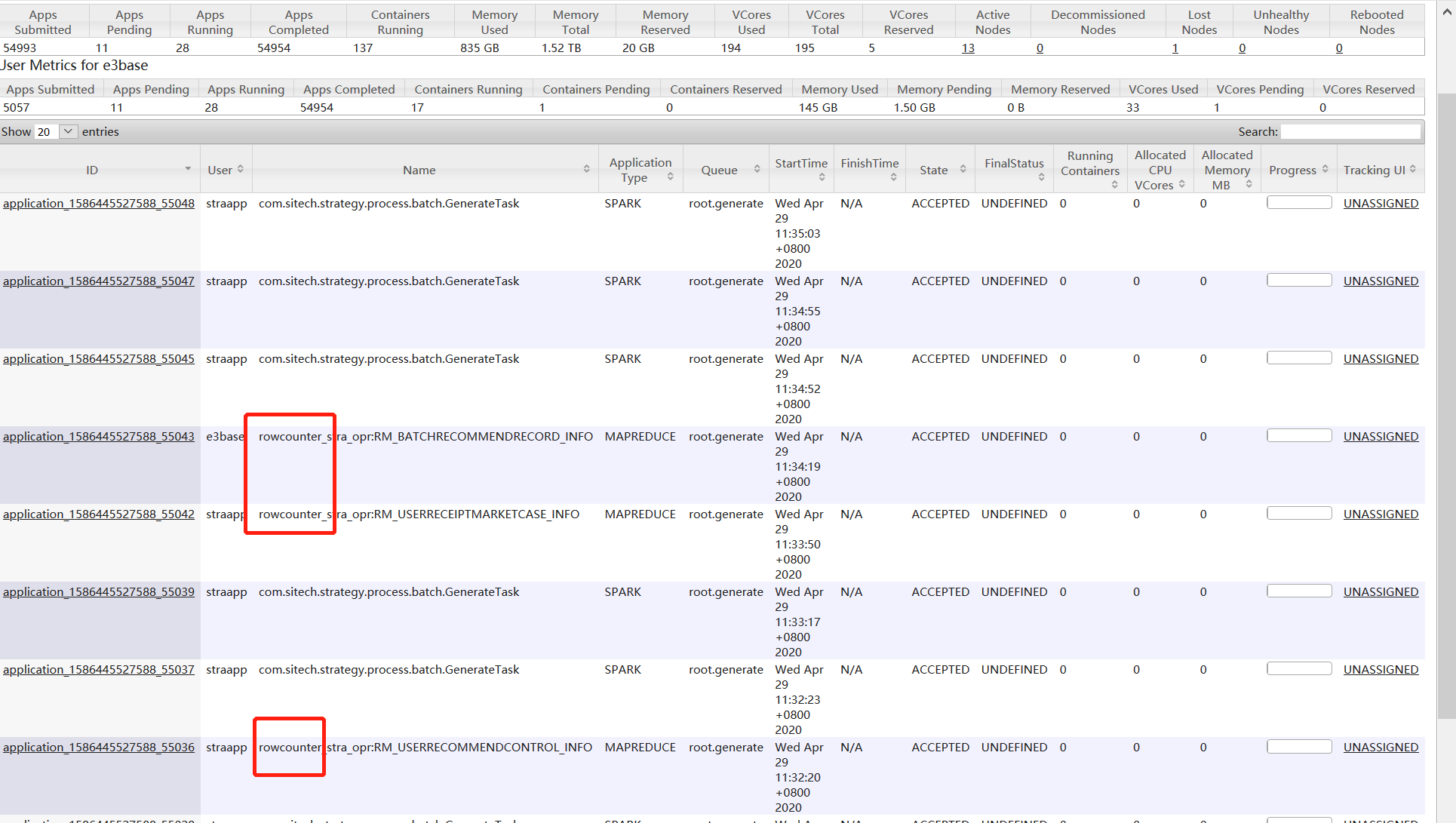
2、提交一个mr作业到generate队列,看generate队列能不能占用更多的资源
hbase org.apache.hadoop.hbase.mapreduce.RowCounter -Dmapreduce.job.queuename=generate 'stra_opr:RM_BATCHRECOMMENDRECORD_INFO'
提交三四个统计条数的作业,都在排队,排了十几分钟,都开始执行,generate的资源使用也提高到70、80c,执行完了以后,spark作业还是只能同时提交两个,generate队列资源最多使用30、40c
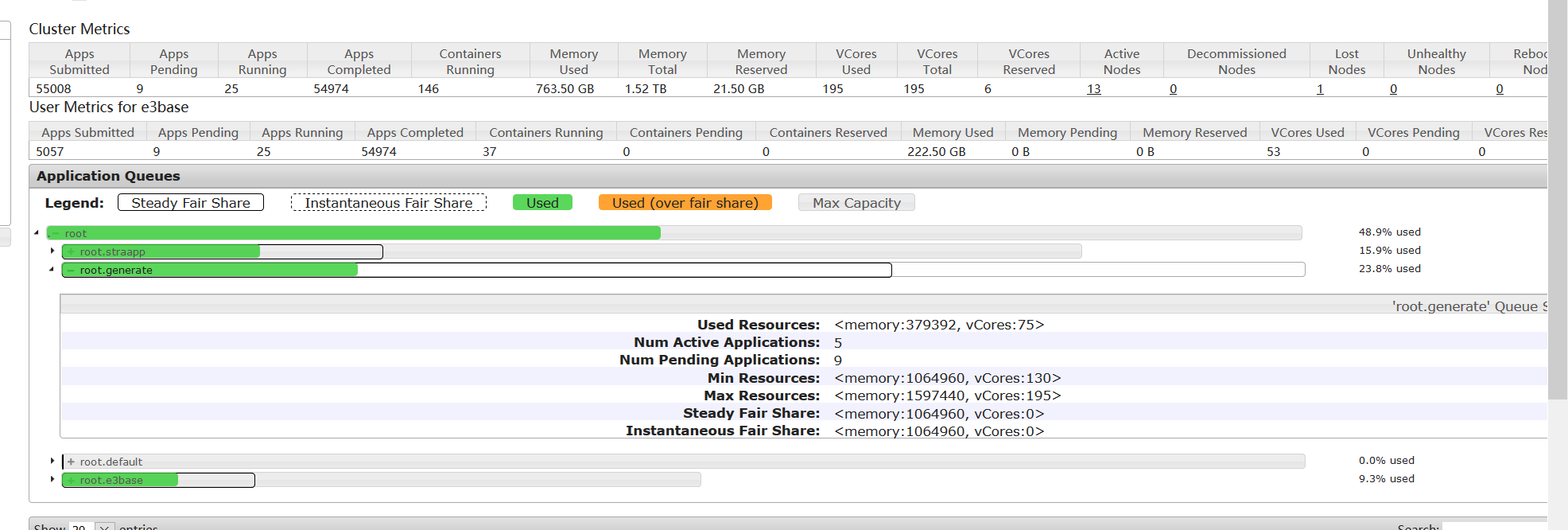
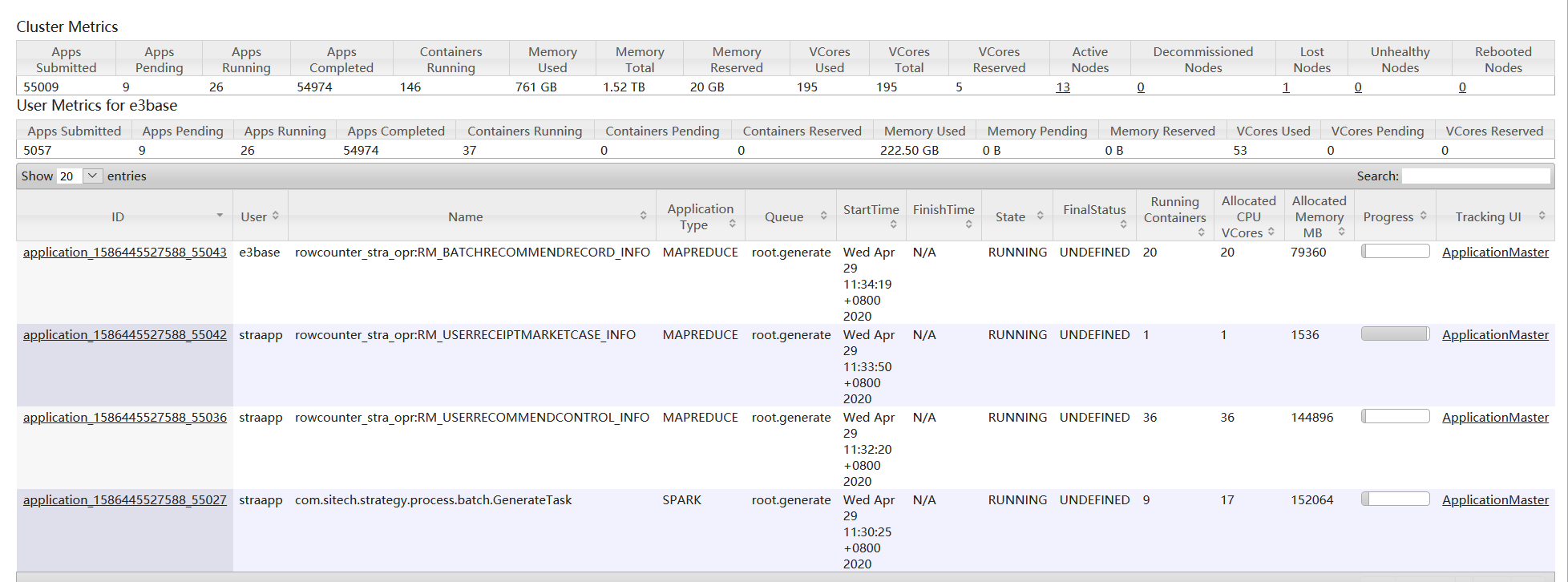
3、把占用比较高的mr作业杀掉,释放资源以后,提交多个hbase统计条数的作业
一个running,两个都在排队,此时集群资源还有空闲,但是还是有很多排队,而且hbase统计条数执行的挺慢的
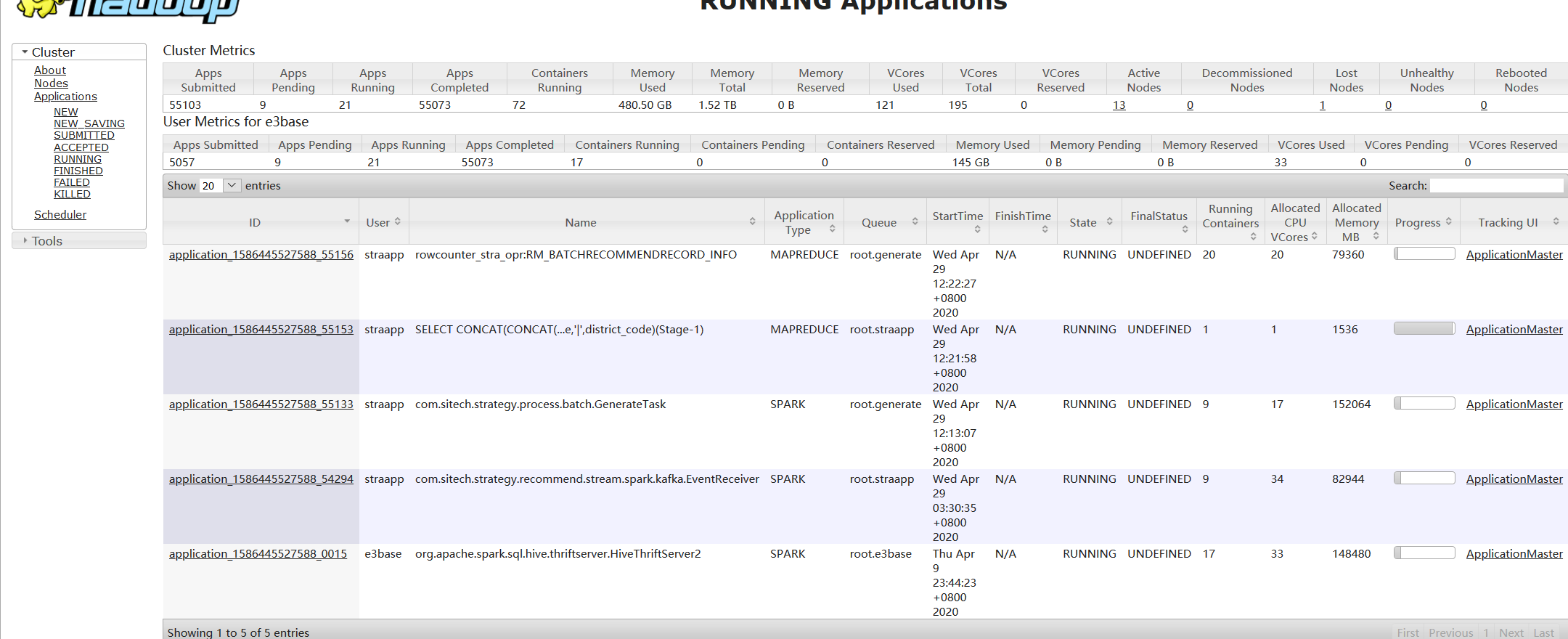
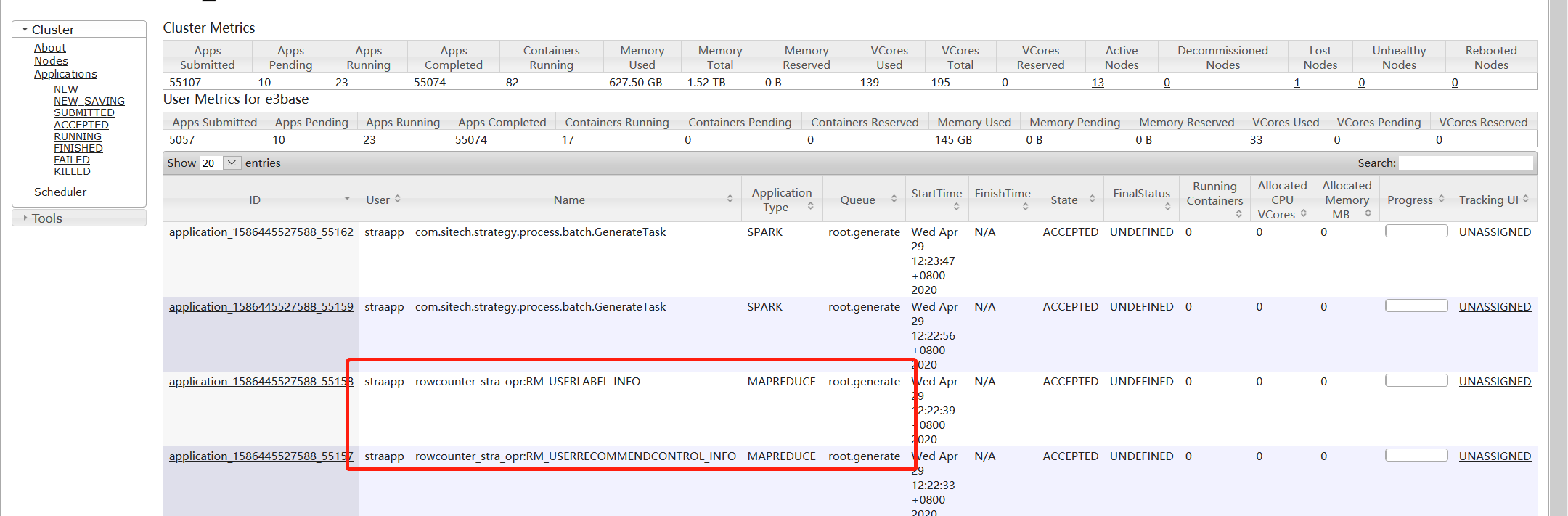
4、新提交多个作业到straapp队列上,不需要排队,直接就能执行
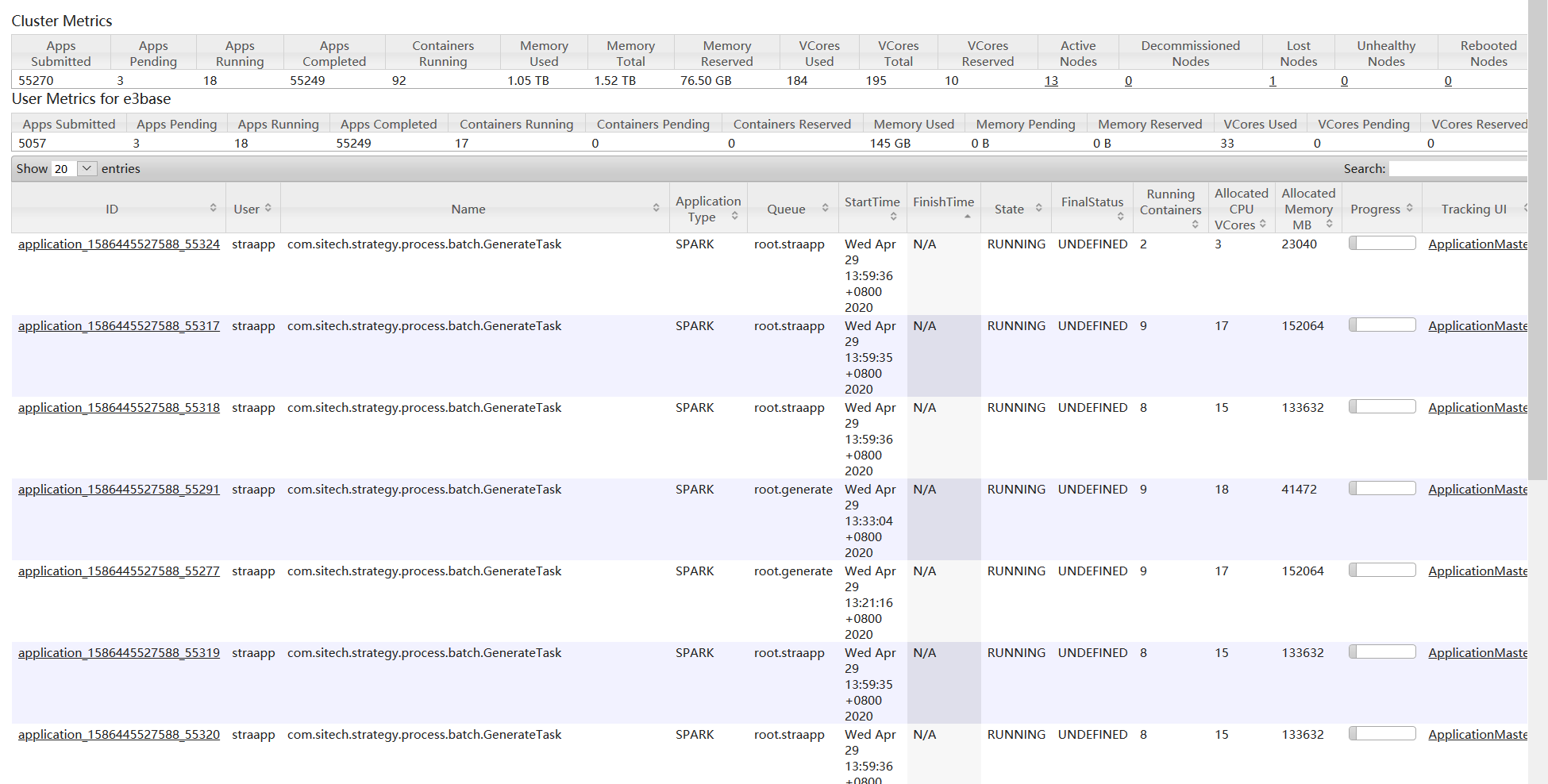
五、解决办法
经过多种测试,确认yarn、spark均正常,除了generate队列外,其他队列均可以提交多个作业,同时并发,效率大大提示,怀疑是generate队列配置有问题
1、修改generate队列参数,使其与其他队列保持一致,杀掉当前generate队列得作业,重新提交,还是不能并发
2、新增队列sparktask,将当前generate队列得作业杀掉,提交到新的队列上,成功实现并发,可以提交多个作业并顺利执行完成
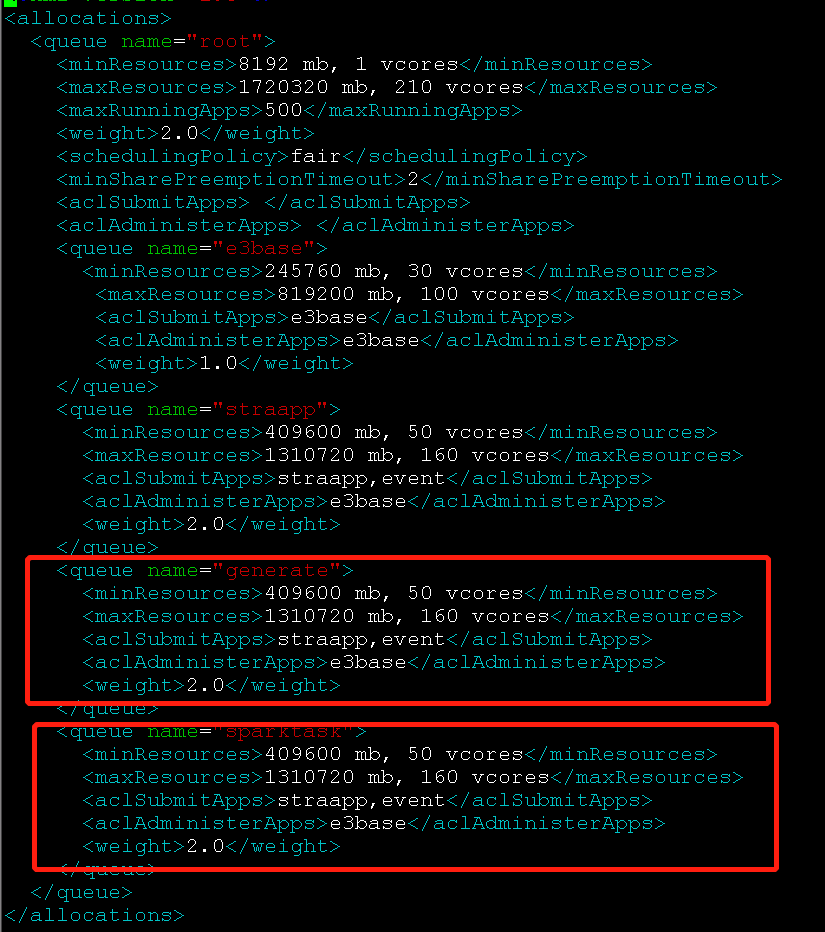
六、问题点
没有找到generate队列异常得原因,目前检查配置文件也是没问题得,和其他队列一样,但是不管怎么提交,最多同时只有两个作业,导致效低
20201117更新
再次出现集群占用不高,大量作业排队accepted状态的情况,观察发现,能提交到running状态的作业执行速度都很快
(1)weiqm协助排查,发现各主机nodemanager节点cpu占用高达600%,对其中一台主机的YARN_NODEMANAGER_OPTS参数进行修改。
修改前:
#export YARN_NODEMANAGER_OPTS="-Xmx8192m -Xms8192m -Xmn1024m -XX:-UseGCOverheadLimit -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=60 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.port=13015 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false ${YARN_NODEMANAGER_OPTS}"
修改后:
export YARN_NODEMANAGER_OPTS="-Xmx12288m -Xms12288m -Xmn4096m -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=8 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:-UseGCOverheadLimit -Dcom.sun.management.jmxremote=false -Dcom.sun.management.jmxremote.port=13015 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false ${YARN_NODEMANAGER_OPTS}"
20201117更新
再次出现集群占用不高,大量作业排队accepted状态的情况,观察发现,能提交到running状态的作业执行速度都很快
(1)weiqm协助排查,发现各主机nodemanager节点cpu占用高达600%,对其中一台主机的YARN_NODEMANAGER_OPTS参数进行修改。
修改前:
#export YARN_NODEMANAGER_OPTS="-Xmx8192m -Xms8192m -Xmn1024m -XX:-UseGCOverheadLimit -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=60 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.port=13015 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false ${YARN_NODEMANAGER_OPTS}"
修改后:
export YARN_NODEMANAGER_OPTS="-Xmx12288m -Xms12288m -Xmn4096m -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=8 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:-UseGCOverheadLimit -Dcom.sun.management.jmxremote=false -Dcom.sun.management.jmxremote.port=13015 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false ${YARN_NODEMANAGER_OPTS}"
(2)修改后重启改主机nodemanager节点
修改前nm节点cpu:
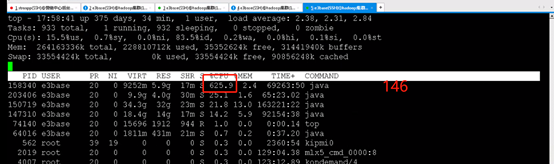
修改后nm节点cpu:
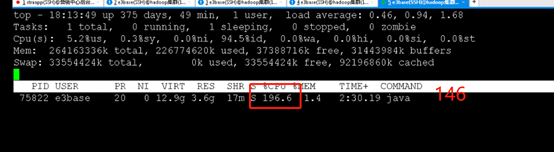
修改后,nm节点的cpu占用明显下降,修改了两个节点后,作业并发running的个数明显提升,修改了四个节点后,各主机nm节点的cpu占用均有所下降
(3)轮询修改完所有nm节点后,业务侧反馈并发数量明显提升,所有作业执行速度有所提升

 浙公网安备 33010602011771号
浙公网安备 33010602011771号