hdfs及hbase相关优化方案
1、Hadoop集群小文件太多
Hadoop集群小文件太多,数据节点太少,消耗大量缓存,随着业务数据量变多,hdfs反应速度会越来越慢,效率越来越低
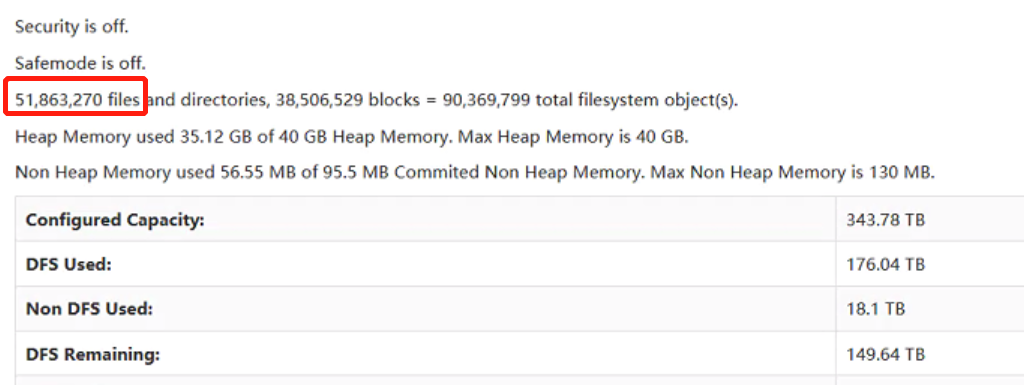
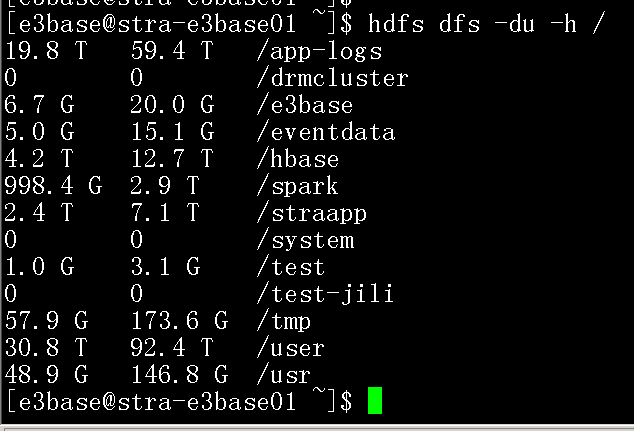
(1)yarn日志(paas侧清理)
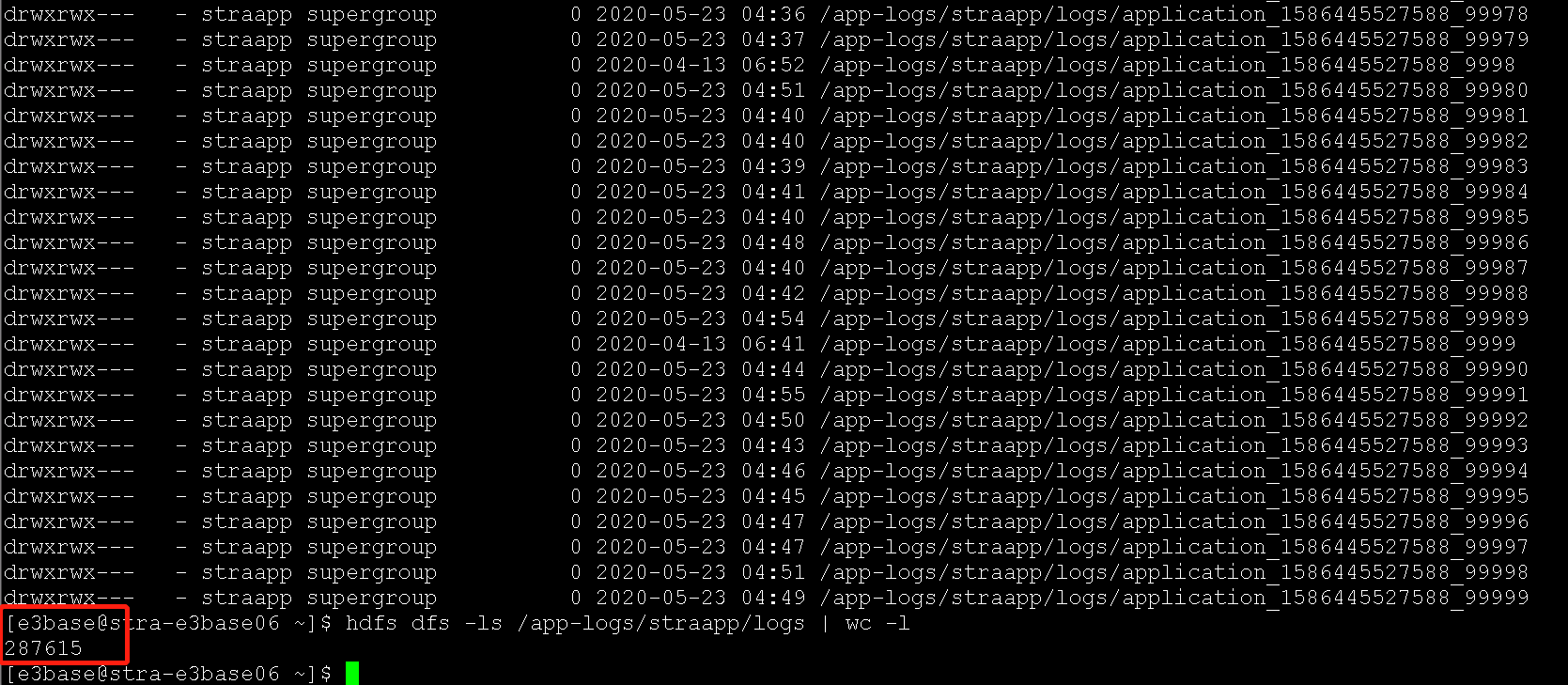
(2)hbase表,虽然整体数据量不算大,但是表太多,很多表是2017、2018、2019年的表,建议清理(CRM_MCI侧清理)
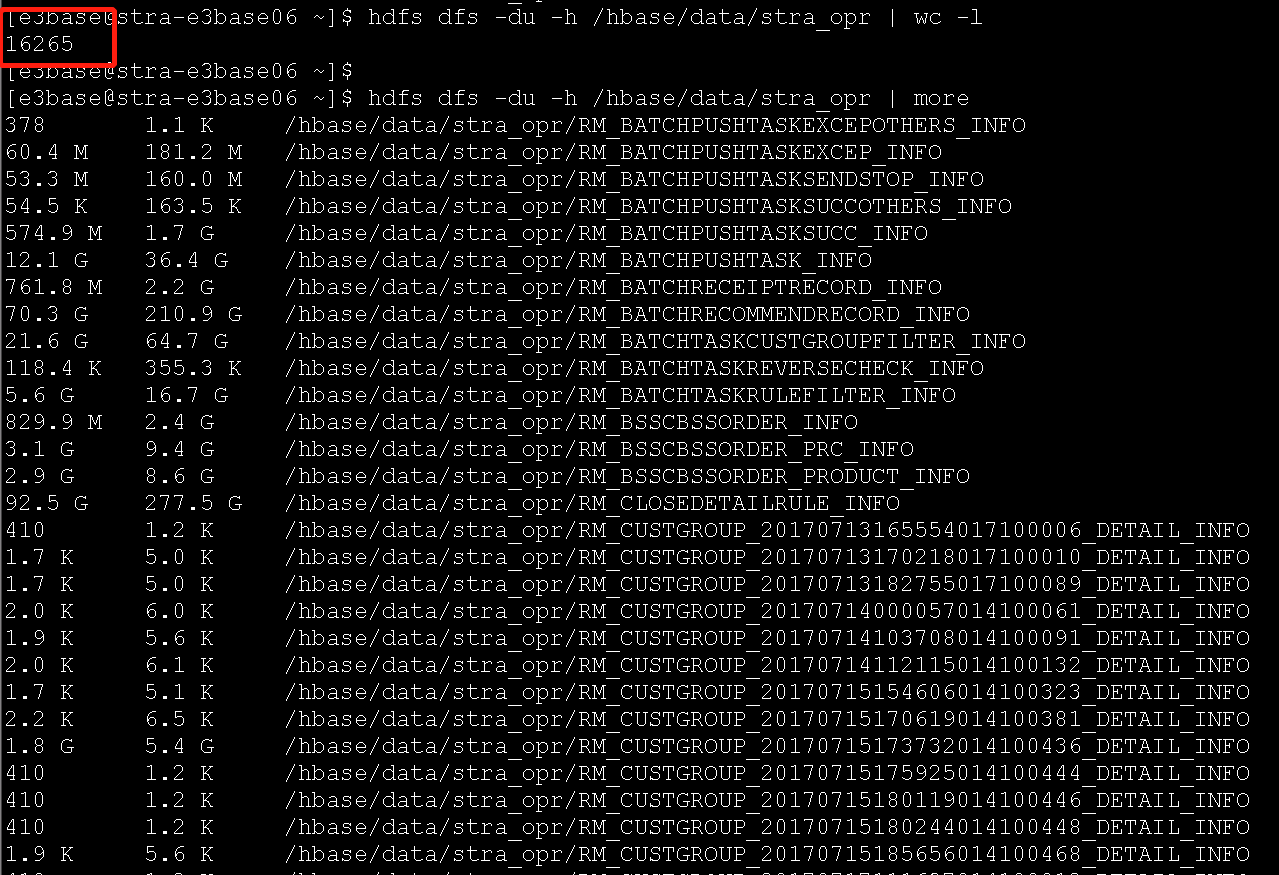
(3)hive表,2017、2018、2019年的表建议清理(CRM_MCI侧清理)
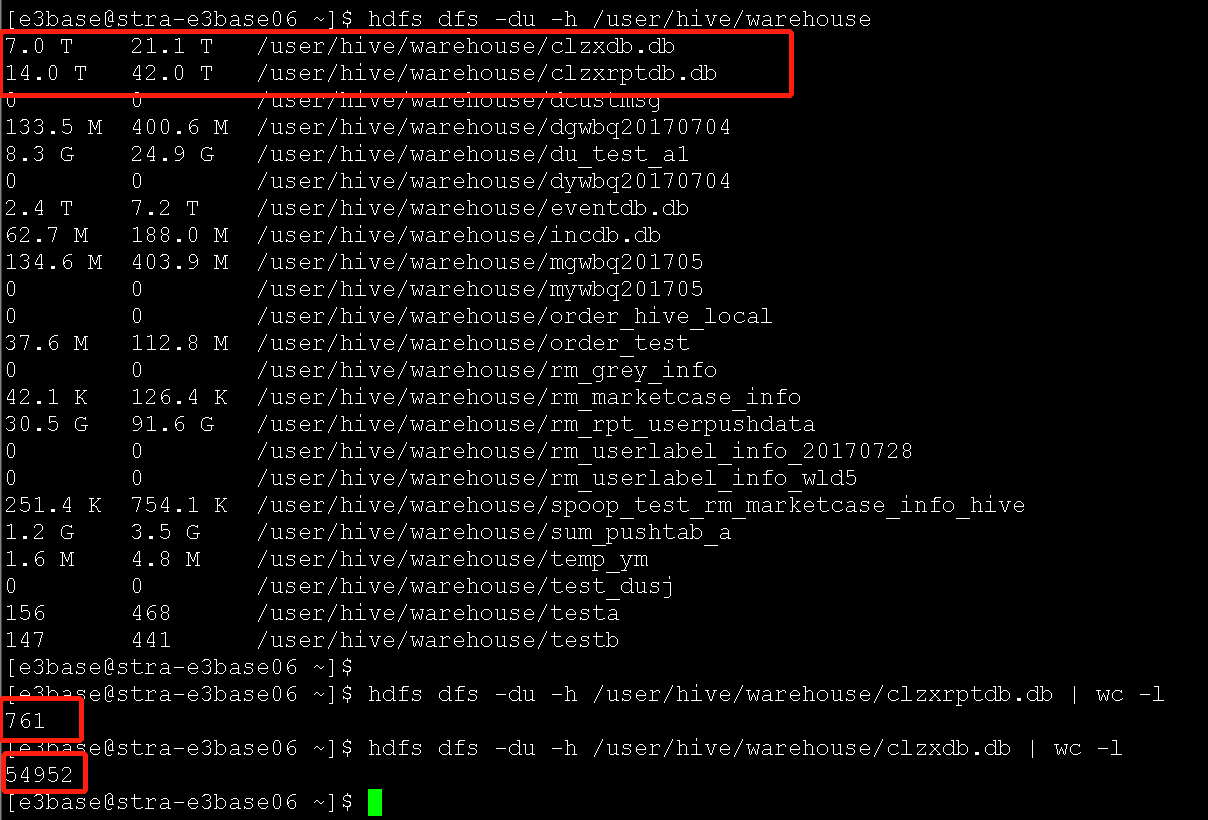
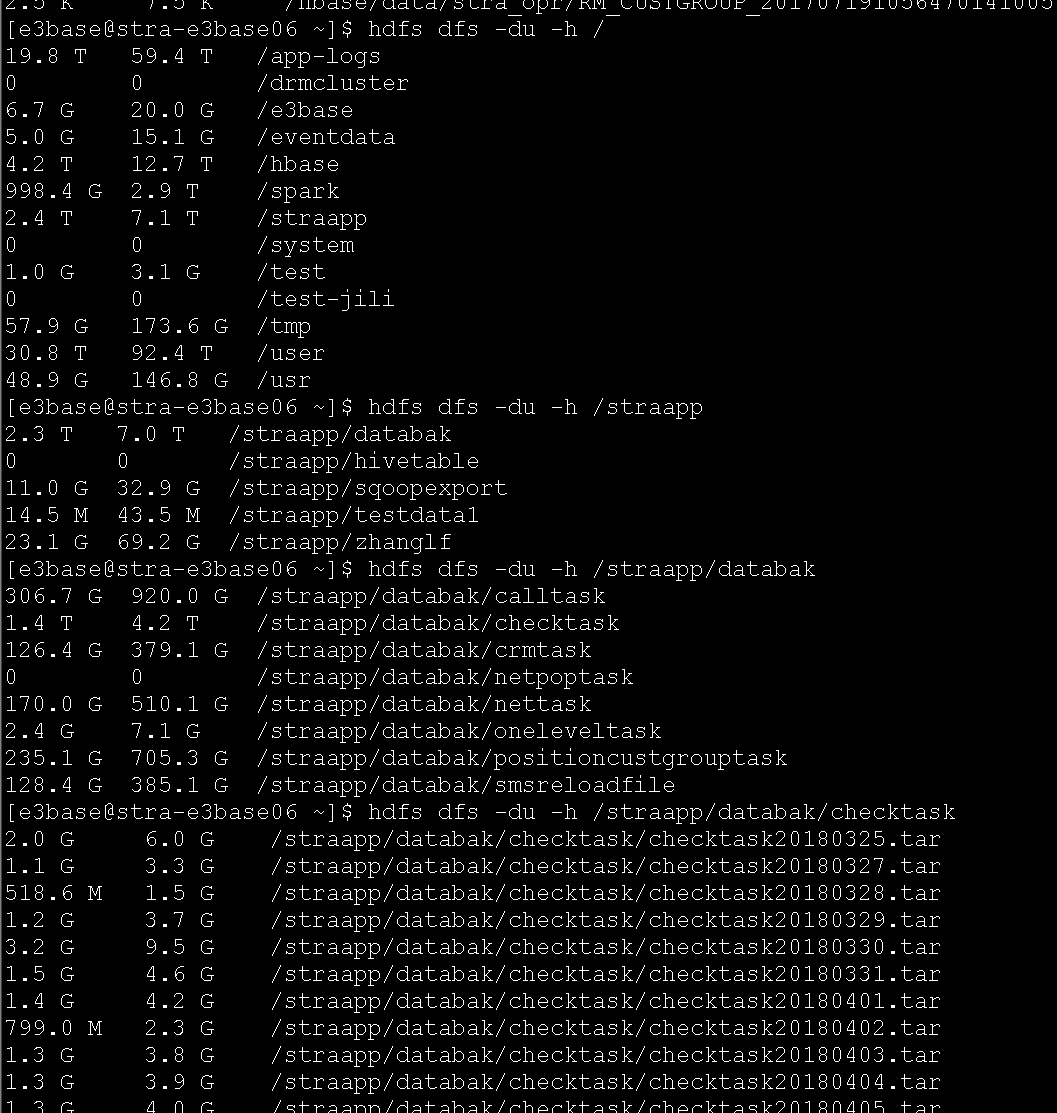
(4)hdfs上有一个全触点自己使用的目录,存放了一些历史文件,请及时清理(CRM_MCI侧清理)
2、hbase访问热点
从监控页面上可以看到,request访问不均匀,部分主机到达两三万访问的时候,有的主机才一二百,存在数据热点
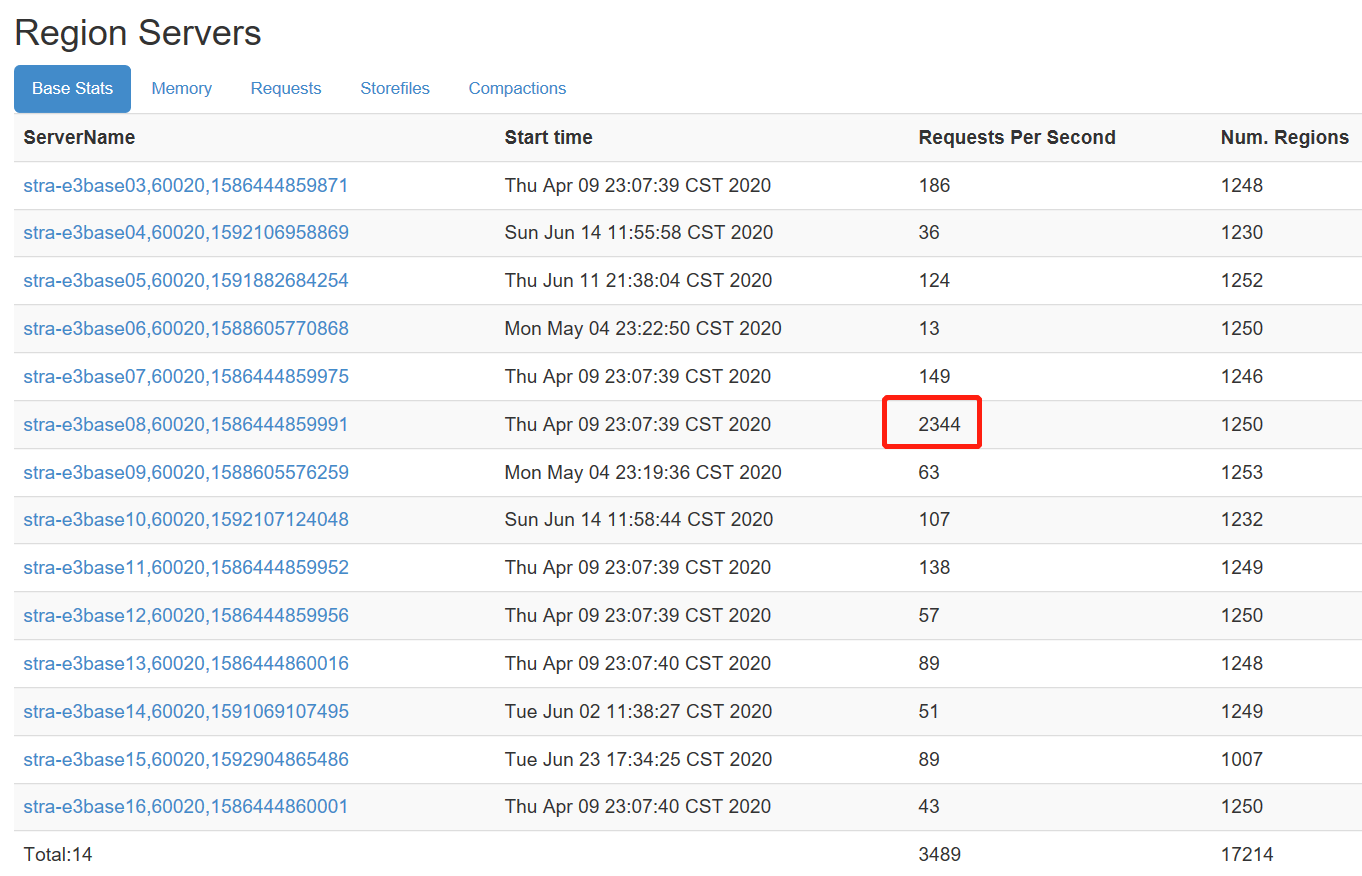
优化:
(1)找到每台主机访问比较高的表,查看每张表对应得region分布是否均匀,如果region数较少,可以手动分裂,做到region均匀分布在各个数据节点上
(2)建议每张表的region个数至少是数据节点得个数,只有1个region的表是不合理得,修改建表语句,对每张表做reigion预划分
目前的业务逻辑每天会新增很多表,每张表做预划分提高hbase效率得同时,会增多hdfs文件个数,给hdfs集群带来压力,建议业务侧修改业务逻辑,不要每天建这么多表,或者定义较短的数据生命周期,只保留几天得表


 浙公网安备 33010602011771号
浙公网安备 33010602011771号