
hbase集群不一致处理处理的经典案例
一、场景一
集群信息:
7台管理节点+51台数据节点 ###此为一套多租户集群
问题描述:
4月13 10:30 其中一台数据节点因硬件故障,突然宕机,同时业务出现入库缓慢现象
故障检查:
hbase hbck ###检查hbase健康情况,结果为:INCONSISTENT,不一致的记录共80条
故障分析及处理:
根据错误信息及进行修复:
ERROR: Found lingering reference file hdfs://drmcluster/hbase/data/ngmkt/mk_cligprs_6_202004/a8a613fe08c7afda9f7f8201aa09c640/cf/c5d3b16021154c24ad6687e83c564258.19043d9ea30df6a11c60586a4dbeaeb0
修复方法:hbase hbck -fixReferenceFiles
ERROR: Region { meta => ngmkt:mk_cligprs_6_202004,62060228051,1586860178148.995a683a71e76cdee7049872f0e67898., hdfs => hdfs://drmcluster/hbase/data/ngmkt/mk_cligprs_6_202004/995a683a71e76cdee7049872f0e67898, deployed => , replicaId => 0 } not deployed on any region server.
修复方法:hbase hbck -fixMeta -fixAssignments # 根据hdfs清理mete表,hdfs存在的信息添加至meta表,hdfs不存在的从meta表中删除,然后进行重新上线
ERROR:Multiple region have the same startkey:
修复方法:hbase hbck -fixHdfsOverlaps #修复多个region 的startkeytg
ERROR: Region { meta => ngmkt:mk_cligprs_6_202004,62026143787,1586860178148.a8a613fe08c7afda9f7f8201aa09c640., hdfs => null,deployed =>,replicaId => 0} found in META,but not in HDFS or deployed on any region server.
修复方法:hbase hbck -fixAssignments -fixMeta # 针对Region在meta表和Regionserver中存在,但是在hdfs不存在情况修复
修复结果:
经过多次修复后hbase状态已经恢复正常
二、场景二
2021年1月3日早6点,业务反馈无法select表。

集群信息:2台管理节点+14台数据节点
Select表涉及语句:
SELECT DISTINCT phone_no FROM rm_batchreceiptrecord_info WHERE touch_result = "1" AND position_id IN ("POSITION_01_01","POSITION_01_04","POSITION_01_05","POSITION_01_06","POSITION_01_07","POSITION_01_08","POSITION_04_01","POSITION_04_02","POSITION_04_03","POSITION_04_05") AND SUBSTR(touch_time,1,8) > 20201104;
问题检查:
1.通过hbase监控页面检查到regionserver 13号节点丢失,节点恢复后业务仍没有恢复;
2.查询hbase表的锁定情况,目标问题表并未锁定;
3.检查yarn监控页面,CPU、内存资源占用并不高;
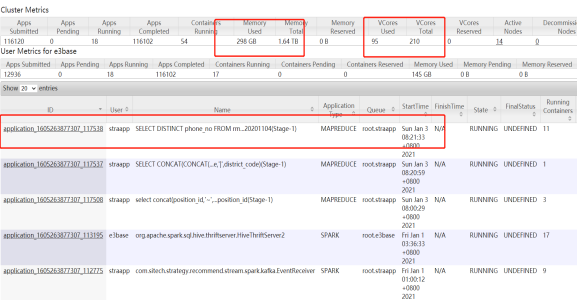
4.在hbase shell 中count表名,发现regionserver7号节点异常
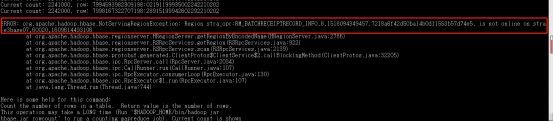
注:Hbase统计行数应使用hbase org.apache.hadoop.hbase.mapreduce.RowCounter
5.执行hbase hbck检查,结果有37张表不一致,详细日志见附件
6.调整业务程序,将有异常表从程序中过滤,然后继续运行保障业务连续性
7.与业务沟通删除其中35张无用的表数据
8.修复hbase不一致
错误信息中共2类信息,具体处理方法如下:
-
根据错误信息“ERROR: There is a hole in the region chain between and . You need to create a new .regioninfo and region dir in hdfs to plug the hole”,作以下修复
hbase hbck -fixHdfsOrphans #修复regioninfo信息
-
根据错误信息ERROR: Region { meta => stra_opr:RM_CUSTGROUP_20181211115158017116968_DETAIL_INFO,,1544500621573.060230f65a1390a3c01df610e96e4729., hdfs => hdfs://drmcluster/hbase/data/stra_opr/RM_CUSTGROUP_20181211115158017116968_DETAIL_INFO/060230f65a1390a3c01df610e96e4729, deployed => , replicaId => 0 } not deployed on any region server. 作以下修复:
hbase hbck -fixMeta -fixAssignments #更新meta表,然后重新上线
-
查看修复结果fixmeta.log,发现新错误”Region failed to move out of transition within timeout XXXXXXms”。
此错误为有region处于rit状态,计划切换master,刷新缓存信息
Kill -9 masterID #切换前检查备master状态正常
-
再次hbck检查hbase
检查正常,无不一致信息
9.重新启用目标问题表,再次测试业务数据运行,业务正常运行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号