hadoop业务积压分析及处理
一、现象:2021年5月12日,17:05分,业务处理能量下降,开始积压
二、集群指标检查
运行脚本检查各项指标,发现2个指标异常如下
1、17点后每个节点出现大量的slow 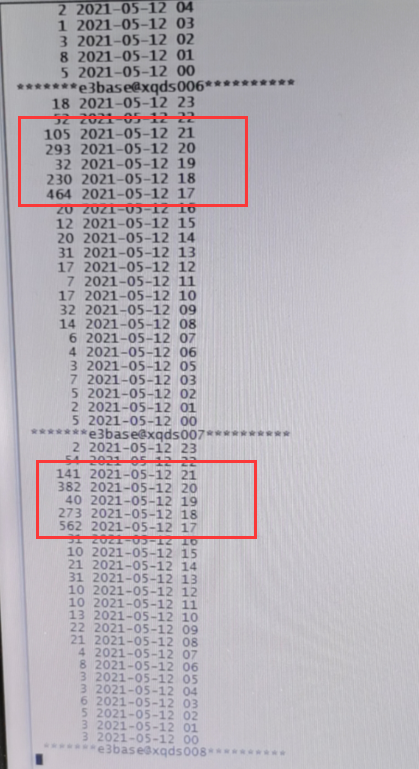
2、发现每台主机的底层IO等待较高
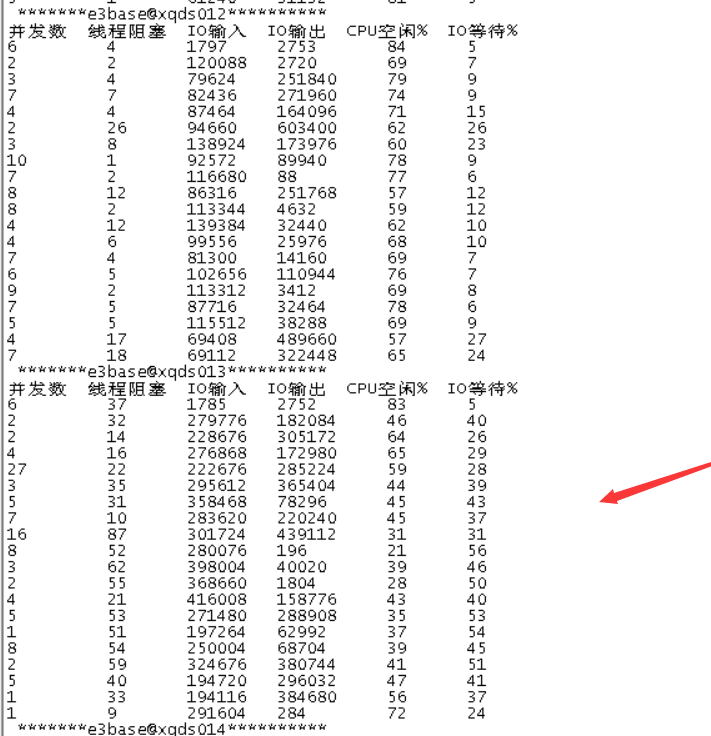
三、问题分析
1、17:05其中一台数据节点磁盘故障,datanode掉线,此节点的数据会自动复制到剩余的数据节点,因此加大了底层IO读写
2、五一后业务量增加了20%(业务并未告知)
3、 17:00-19:00为业务最繁忙的时候
四、结论
原本集群底层IO就繁忙的大前提下(五一前底层IO也有少许等待,但并不影响业务,更主要的是用户坚持不扩容),再根据以上3点加剧了底层IO等待
五、临时解决方案
1、尽快更换磁盘,重启datanode
2、等待底层datanode完成数据回流
注:20:20完成磁盘更换,预计21:20左右完成数据回流,此时底层IO等待已降低,业务恢复 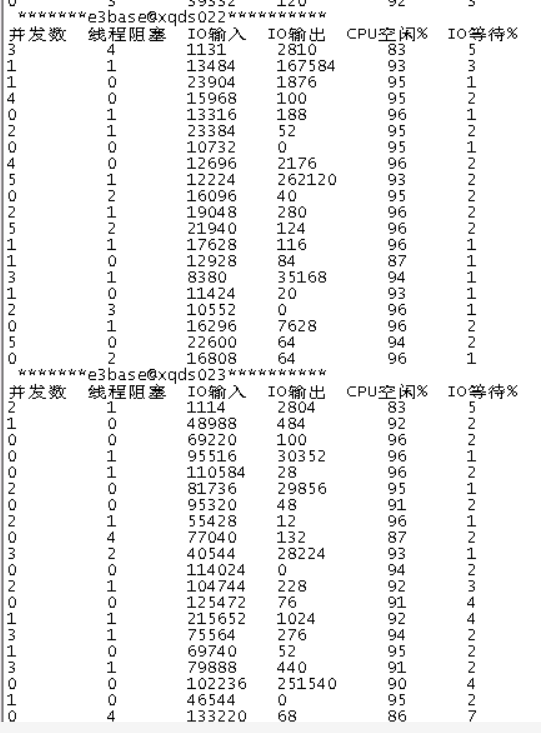
六、解决方案
1、 整理扩容需求量
2、再次提出扩容需求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号