hadoop集群spark作业执行较慢、入库较慢相关问题排查及调优
1、反馈
业务侧反馈日常进行spark作业跑不动,执行速度特别慢,影响当天任务生成,后续活动执行;
主要现象及影响:
1、regionserver频繁挂,日志出现大量gc信息
2、spark类型的作业跑得慢,跟业务一起做测试定位原因,发现主要是hbase get比较耗时
3、标签入库较慢(将数据put到hdfs,从hdfs入到hbase中)
参数调整及优化:
1、发现regionserver日志有频繁gc延迟的信息,主机CPU高的时候延迟就高,09.29修改hbase-env.sh的如下相关相关参数,重启hbase,将延迟控制到3s以内
修改前:
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -server -Xmx32768m -Xms32768m -Xmn1024m -XX:SurvivorRatio=1 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:-DisableExplicitGC"
第一次修改:
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -server -Xmx32768m -Xms32768m -Xmn4096m -XX:SurvivorRatio=1 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:-DisableExplicitGC"
第二次修改:
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -XX:SurvivorRatio=2 -server -Xmx32768m -Xms32768m -Xmn4096m -Xss256k -XX:PermSize=256m -XX:MaxPermSize=256m -XX:+UseParNewGC -XX:MaxTenuringThreshold=15 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75 -XX:-DisableExplicitGC"
2、观察hbase master及hdfs namenode监控页面,发现hdfs小文件数比较多,hbase表比较多,且很多表已经不用,对集群性能有一定影响,用distcp将hbase相关数据备份到测试环境,告知业务侧将不再使用的五千张表删除。09.29删除五千多张hbase表后,hbase get速度有所提升,但还是有get一条数据耗时3~4s的情况。
后续规划:建议业务侧进行数据清理,减少hdfs小文件,主要是hive数据
3、0930凌晨,通过yarn监控页面,发现sparksumit占用资源较多,而业务测spark作业以及mapreduce作业同时并发时 ,集群300cpu占满,调整spark启动参数,减少sparksumint资源占用,腾出相应的CPU,供spark作业使用
调整前:
/e3base/spark/sbin/start-thriftserver.sh --master yarn --deploy-mode client --driver-memory 8G --driver-cores 8 --num-executors 16 --executor-memory 8G --executor-cores 6 --queue straapp &
调整后:
/e3base/spark/sbin/start-thriftserver.sh --master yarn --deploy-mode client --driver-memory 8G --driver-cores 2 --num-executors 16 --executor-memory 8G --executor-cores 2 --queue straapp &
分队列后:
/e3base/spark/sbin/start-thriftserver.sh --master yarn --deploy-mode client --driver-memory 8G --driver-cores 2 --num-executors 16 --executor-memory 8G --executor-cores 2 --queue e3base &
4、0930凌晨,通过调整spark启动参数,腾出cpu,继而修改业务侧spark作业启动参数,按1:4配置cpu和内存参数,提高各作业执行效率
调整前:
spark-submit --master yarn-cluster \
--driver-memory 4g --driver-cores 2 --num-executors 8 --executor-memory 4g --executor-cores 2 \
--conf "spark.driver.extraJavaOptions=-XX:PermSize=1g -XX:MaxPermSize=1g" \
--queue generate \
增大executor-memory参数:
spark-submit --master yarn-cluster \
--driver-memory 4g --driver-cores 2 --num-executors 8 --executor-memory 8g --executor-cores 2 \
--conf "spark.driver.extraJavaOptions=-XX:PermSize=1g -XX:MaxPermSize=1g" \
--queue straapp \
将原来每个作业8*2的并发数调整到10*3个并发,但发现效率没有得到提升:
spark-submit --master yarn-cluster \
--driver-memory 4g --driver-cores 1 --num-executors 10 --executor-memory 12g --executor-cores 3 \
--conf "spark.driver.extraJavaOptions=-XX:PermSize=1g -XX:MaxPermSize=1g" \
--queue straapp \
最终将作业启动参数调整如下:
spark-submit --master yarn-cluster \
--driver-memory 4g --driver-cores 1 --num-executors 8 --executor-memory 8g --executor-cores 2 \
--conf "spark.driver.extraJavaOptions=-XX:PermSize=1g -XX:MaxPermSize=1g" \
--queue generate \
5、为避免业务测比较重要的spark作业资源不够用,09.30晚上,增加generate队列,只跑sparksumit作业,通过队列的内存、cpu、权重配置,尽量避免资源争抢
调整前:只有straapp和e3base两个队列,业务侧有mapreduce作业和spark作业,以及sparksubmit全部跑在straapp队列上,有资源抢占,prom部门每天晚上会跑几个特别小的作业在e3base队列上
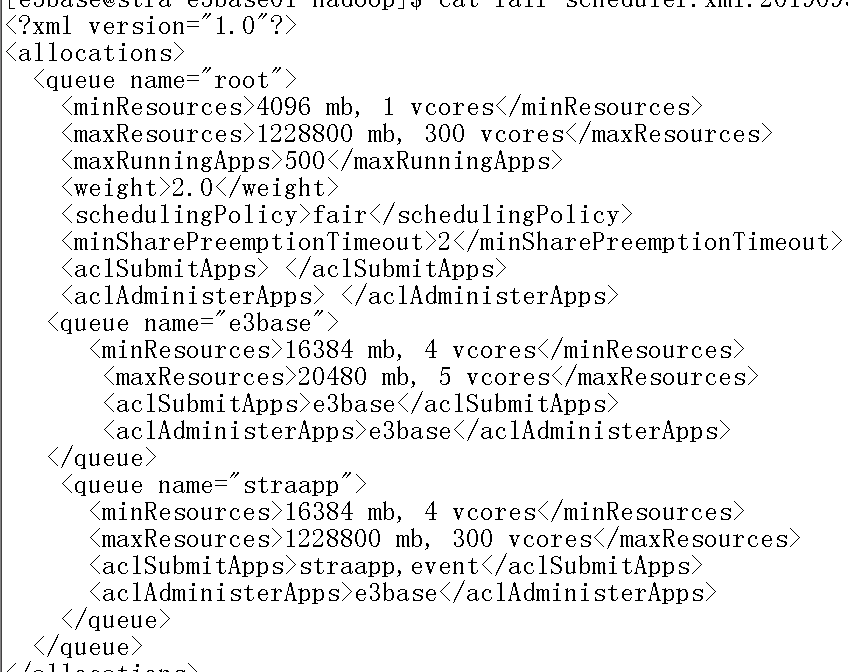
调整后:
新加了generate队列,只跑spark类型的作业,mapreduce跑在straapp队列上 ,sparksubmit提交到到e3base队列上

6、10.1凌晨,观察业务侧标签入库作业,没有发现相关报错,但正常情况入库只需要两个小时多,而这几天入库需要六个小时,甚至八个小时。调整mapred-site.xml文件中,原注释的mapreduce.input.fileinputformat.split.minsize,mapreduce.input.fileinputformat.split.maxsize两个参数,开启,并将值改成128M,默认block size=256M。由于入库期间集群资源充足,增加并发写hbase

结论:调整参数后,入库效率明显提升30~40%
7、10.01白天,修改hbase的flush size大小,参数:hbase.hregion.memstore.flush.size,目前默认配置128M,配置为256M,block size是256M, 每次update之后会检查此region memstore是否达到这个大小,达到之后就会请求flush, 调大此参数,减少flush次数

8、10.01白天,协助业务侧相关建表语句预分区调整
create 'stra_opr:RM_USERLABEL_INFO_TEMP',{ NAME => 'a', COMPRESSION => 'snappy'},{SPLITS => ['03','06','09','12','15','18','21','24','27','30','33','36','39','42','45','48','51','54','57','60','63','66','69','72','75','78','82','86','90']}
create 'stra_opr:RM_USERLABEL_INFO',{ NAME => 'a', COMPRESSION => 'snappy'},{SPLITS => ['025','050','075','100','125','150','175','200','225','250','275','300','325','350','375','400','425','450','475','500','525','550','575','600','625','650','675','700','725','750','775','800','825','850','875','900','925','950','975']}
9、调整hbase参数,hbase.hstore.compaction.min.size和hbase.regionserver.thread.compaction.small,减少compact的压力

10、每天晚上10点~11点,HBASE脚本动执行
flush 'stra_opr:RM_USERLABEL_INFO'
major_compact 'stra_opr:RM_USERLABEL_INFO'
![]()
![]()
![]()
![]()
20191003晚修改参数
11、修改hbase regionserver堆内存配置
修改如下:
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -XX:SurvivorRatio=2 -server -Xmx32768m -Xms32768m -Xmn4096m -Xss256k -XX:PermSize=1g -XX:MaxPermSize=1g -XX:+UseParNewGC -XX:MaxTenuringThreshold=15 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75 -XX:-DisableExplicitGC"
12、修改hbase master的堆内存配置
修改前:
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Xmx16384m -Xms16384m -Xmn1500m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70"
修改后:
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Xmx32g -Xms32g -Xmn1500m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70"
13、修改yarn nodemanager并发
将cpu30改成15,内存不变,比例变成1:8
修改前:

修改后:
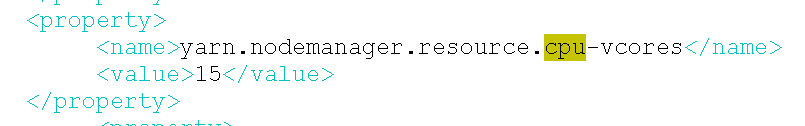
14、修改各队列资源
将cpu内存1:4改成1:8
修改前:

修改后:

15、修改业务侧spark作业内存,将cpu与内存改成1:8
修改前:
spark-submit --master yarn-cluster \
--driver-memory 4g --driver-cores 1 --num-executors 8 --executor-memory 8g --executor-cores 2 \
--conf "spark.driver.extraJavaOptions=-XX:PermSize=1g -XX:MaxPermSize=1g" \
--queue generate \
修改后:
spark-submit --master yarn-cluster \
--driver-memory 4g --driver-cores 1 --num-executors 8 --executor-memory 16g --executor-cores 2 \
--conf "spark.driver.extraJavaOptions=-XX:PermSize=1g -XX:MaxPermSize=1g" \
--queue generate \
后续待办
(1)集群规模扩容,目前yarn作业数量较多时,每台主机30个并发,跑起来集群资源占用率很高,尤其CPU,怀疑就是因为CPU导致hbase集群出现异常,已经将每台主机的并发改成15,目前运行稳定,已经跟局方申请主机
(2)建议业务侧修改入库代码,减少重复部分,或改用mapreduce方式
调优后遗留问题:
1、业务侧标签入库耗时2~2.5小时,可以整改入库方式,缩短时间
2、仍然不定时出现regionserver异常
3、每天有标签入库、spark作业、spark thriftserver2、kafka、mapreduce这几种作业,目前集群共150c,spark thriftserver2和kafka是常驻进程,共占用67c,目前spark作业并没有全部启动,每天只跑十几个作业,后续局方通知跑全部活动的话,资源可能不够用,有可能还是不能当天跑完所有作业,扩容后能否完成要到时候观察


 浙公网安备 33010602011771号
浙公网安备 33010602011771号