YARN生产MR异常处理过程
问题描述:
部分mr任务提交较慢,跟踪日志发现,reduce的过程中,进度条还会倒退,如:已经reduce至80%,下一刻会慢慢下降79%,78%...
分析过程:
1、根据日志描述,任务不存在于缓存中 
2、查看主机资源利用率情况
调nmon查看记录,异常时,主机资源利用率虽然偶尔出现较高的峰值,但并未持续,总体均算正常包括cpu,内存,网络,磁盘
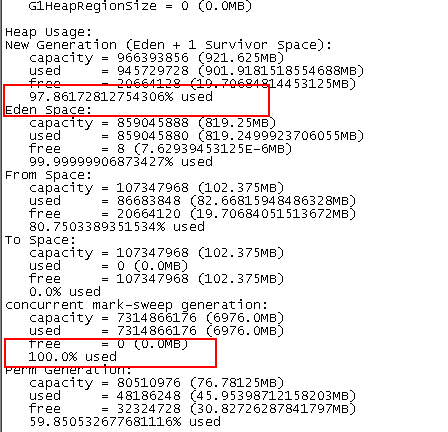
3、查看nodemanager内存堆
发现2,3数据节点的nm进程的内存堆(老年代)已经使用至100%(设置为8G)
4、nm GC情况:
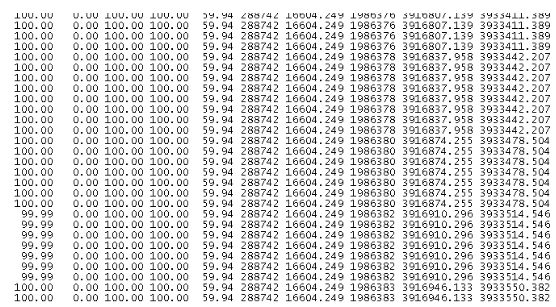
故障分析:参考https://issues.apache.org/jira/browse/YARN-4095 当前版本的NodeManager的缺陷,ShuffleHandler未复用AllocatorPerContext对象造成重复创建对象造成的堆内存的高使用。nm内存中存在大量存活对象,gc无法清理出足够的空间来创建新对象,导致节点YarnChild进程卡死。
处理方案:
优化nm堆内存配置及其相关参数:
1.mr客户端参数:(mapred-site.xml)
mapreduce.map.memory.mb调整为2048(目前为1024)
mapreduce.reduce.memory.mb调整为4096(目前为1024)
mapred.child.java.opts调整为-Xmx1024m(目前为-Xmx512m)
2.yarn资源参数:(yarn-site.xml)
yarn.scheduler.minimum-allocation-mb调整为2048(目前为1024)
3.nm堆内存参数:(yarn-env.sh)
YARN_NODEMANAGER_OPTS="-Xmx12000m -Xms12000m -Xmn1024m"(目前为"-Xmx8000m -Xms8000m -Xmn1024m")
4.rpc服务listen线程相关参数:
core-site.xml添加以下参数:ipc.server.listen.queue.size ipc 1024(默认128)
系统内核参数:/proc/sys/net/core/somaxconn 调整为1024 (目前为128)
影响范围:
参数修改后需要重启整个集群,重启期间业务会中断,预计修改及重启所需30分钟

 浙公网安备 33010602011771号
浙公网安备 33010602011771号