模型融合
记个笔记,进一步理解了模型融合,开心,整理一下模型融合方式:stacking、blending和voting
直接上代码(来自网络大佬的分享),理论后续补。
-
blending
'''创建训练的数据集''' data, target = make_blobs(n_samples=50000, centers=2, random_state=0, cluster_std=0.60) '''模型融合中使用到的各个单模型''' clfs = [RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'), RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'), ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'), ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'), GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)] '''切分一部分数据作为测试集''' X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.33, random_state=2017) '''切分训练数据集为d1,d2两部分''' X_d1, X_d2, y_d1, y_d2 = train_test_split(X, y, test_size=0.5, random_state=2017) dataset_d1 = np.zeros((X_d2.shape[0], len(clfs))) dataset_d2 = np.zeros((X_predict.shape[0], len(clfs))) for j, clf in enumerate(clfs): '''依次训练各个单模型''' # print(j, clf) '''使用第1个部分作为预测,第2部分来训练模型,获得其预测的输出作为第2部分的新特征。''' # X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test] clf.fit(X_d1, y_d1) y_submission = clf.predict_proba(X_d2)[:, 1] dataset_d1[:, j] = y_submission '''对于测试集,直接用这k个模型的预测值作为新的特征。''' dataset_d2[:, j] = clf.predict_proba(X_predict)[:, 1] print("val auc Score: %f" % roc_auc_score(y_predict, dataset_d2[:, j])) '''融合使用的模型''' # clf = LogisticRegression() clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30) clf.fit(dataset_d1, y_d2) y_submission = clf.predict_proba(dataset_d2)[:, 1] print("Linear stretch of predictions to [0,1]") y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min()) print("blend result") print("val auc Score: %f" % (roc_auc_score(y_predict, y_submission)))结果:
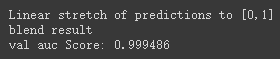
-
stacking
'''创建训练的数据集''' data1, target1 = make_blobs(n_samples=50000, centers=2, random_state=0, cluster_std=0.60) '''模型融合中使用到的各个单模型''' clfs = [RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'), RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'), ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'), ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'), GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)] '''切分一部分数据作为测试集''' X, X_predict, y, y_predict = train_test_split(data1, target1, test_size=0.33, random_state=2017) dataset_blend_train = np.zeros((X.shape[0], len(clfs))) dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs))) '''5折stacking''' n_folds = 5 skf = list(StratifiedKFold(n_splits=n_folds).split(X,y)) for j, clf in enumerate(clfs): '''依次训练各个单模型''' # print(j, clf) dataset_blend_test_j = np.zeros((X_predict.shape[0], len(skf))) for i, (train, test) in enumerate(skf): '''使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。''' # print("Fold", i) X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test] clf.fit(X_train, y_train) y_submission = clf.predict_proba(X_test)[:, 1] dataset_blend_train[test, j] = y_submission dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1] '''对于测试集,直接用这k个模型的预测值均值作为新的特征。''' dataset_blend_test[:, j] = dataset_blend_test_j.mean(1) print("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j])) # clf = LogisticRegression() clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30) clf.fit(dataset_blend_train, y) y_submission = clf.predict_proba(dataset_blend_test)[:, 1] print("Linear stretch of predictions to [0,1]") y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min()) print("blend result") print("val auc Score: %f" % (roc_auc_score(y_predict, y_submission)))结果:

-
voting(加和投票)
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.33, random_state=2017) # 训练模型 r1 = RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini') r1.fit(X, y) r2 = RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy') r2.fit(X, y) e1 = ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini') e1.fit(X, y) e2 = ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy') e2.fit(X, y) g = GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5) g.fit(X, y) # 预测标签 y_r1 = r1.predict_proba(X_predict) y_r2 = r2.predict_proba(X_predict) y_e1 = e1.predict_proba(X_predict) y_e2 = e2.predict_proba(X_predict) y_g = g.predict_proba(X_predict) # 转为one-hot标签形式 y_r1 = np.rint(y_r1) y_r2 = np.rint(y_r2) y_e1 = np.rint(y_e1) y_e2 = np.rint(y_e2) y_g = np.rint(y_g) # 加和投票 y_en = y_r1 + y_r2 + y_e1 + y_e2 + y_g y_pre_en = y_en.argmax(axis=1) print(classification_report(y_predict, y_pre_en, digits=4))结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号