Distributed Representations of Words and Phrases and their Compositionality论文阅读及实战
本文讲解 skip-gram 模型以及优化和扩展。主要包括层次 Softmax、负采样、学习短语的表示。
先提一下词向量:
- 词向量(也叫词嵌入,word embedding),简单地说就是用一个低维向量表示一个词。由于独热编码(one-hot encoding)存在维度灾难,即稀疏性,且无法理解词与词之间的内在联系,词向量的出现就可解决这些问题,大大简化了操作。
- 特点:
- 维度大小是固定值
- 维度值是实数,不限于0和1,可表示连续空间,可通过计算距离表示词之间的相似性,还可类比
- 使用嵌入矩阵表示词向量
介绍
- Mikolov等人在《Efficient estimation of word representations in vector space》中提出Skip-gram模型,是一种高效的可从大量无结构文本数据中学习高质量词向量表示的方法。该模型的训练不涉及密集的矩阵乘法,这使得模型训练很快。
-
该论文提出了几点优化扩展,比如对高频率词进行重采样,可以提高训练速度(大约 2倍 - 10倍),并且提高了低频词的向量表示。此外还提出了一种简化的噪声对比估计(Noise Contrastive Estimation, NCE),与之前使用层次 Softmax 相比,能够更快的训练和更好的表示频繁单词。
从基于单词的模型扩展到基于短语的模型相对简单,文中使用数据驱动的方法识别大量的短语,然后将短语作为单独的标记来处理。为了评估短语向量的质量,作者开发了一套包含单词和短语的类比推理任务测试集,效果如下:
vec(“Montreal Canadiens”) - vec(“Montreal”) + vec(“Toronto”) is vec(“Toronto Maple Leafs”)
- 还发现简单的向量加法可得出有意思的结果,比如
vec(“Russia”) + vec(“river”) is close to vec(“Volga River”), and vec(“Germany”) + vec(“capital”) is close to vec(“Berlin”)
Skip-gram model
- Skip-gram 的训练目标是给定中心词,能够预测该词在一定半径内可能出现的词。

而Cbow模型是给定中心词 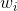
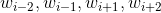
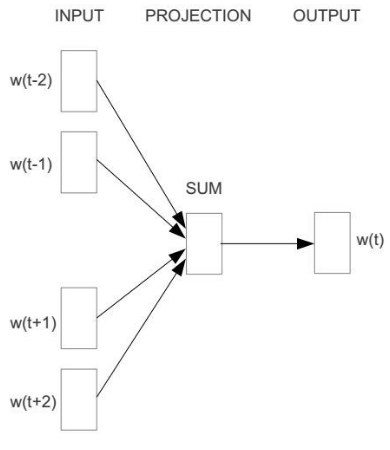
- 层次softmax
本文使用霍夫曼二叉树来表示输出层,W 个词分别作为叶子节点,每个节点都表示其子节点的相对概率。总词汇中的每个词都有一条从二叉树根部到自身的路径。用 n(w,j) 来表示从根节点到 w 词这条路径上的第 j 个节点,用 ch(n) 来表示 n 的任意一个子节点,设如果 x 为真则[x]=1[x]=1,否则[x]=−1[x]=−1。那么 Hierarchical Softmax 可以表示为:

好处:
1.霍夫曼二叉树的节点离高频词距离更近,从而可以进行快速训练。之前已经观察到,通过频率将单词分组在一起,对于基于神经网络的语言模型来说,是一种非常简单的加速技术,效果很好。
2. 最多计算logW个节点
- 负采样
Noise Contrastive Estimation (NCE)-噪声对比估计,NCE表面,一个好的模型应该能够通过逻辑回归将数据与噪声区分开。
因为 skip-gram 更关注于学习高质量的词向量表达,所以可以在保证词向量质量的前提下对 NCE 进行简化。于是定义了 NEG(Negative Sampling):

实验表明,在5-20范围内k值对于小的训练数据集是有用的,而对于大数据集,k可以小到2-5。NCE 和 NEG 的区别在于 NCE 在计算时需要样本和噪音分布的数值概率,而 NEG 只需要样本。
- 高频词的二次采样
为了克服稀有词和频繁词之间的不平衡,我们使用了一种简单的次抽样方法:训练集中的每个单词以公式计算的概率被丢弃。

其中,是单词
的频率,
是选择的阈值,通常在
左右。选择这个次抽样公式,是因为它在保持频率排序的同时,对频率大于t的词进行了积极的子采样。同时发现它在实践中效果很好。它加速了学习,甚至显着地提高了r的学习向量的准确性。
- 结果:

通过比较,作者们发现,似乎最好的短语表示是通过一个层次 softmax 和 Subsampling 结合的模型来学习的。
- 学习短语
许多短语的含义并不是由单个单词的含义组成的。要学习短语的向量表示,首先要找到经常出现在一起的单词,并且组成一个 Token 作为一个词处理。通过这种方式,我们可以构成许多合理的短语,而不会大大增加词汇量;从理论上讲,我们可以使用所有n-gram训练Skip-gram模型,但这会占用大量内存。于是使用了一个基于 unigram, bigram 的数据驱动方法:

其中用作折扣系数,防止由非常不常用的单词组成的短语过多。然后将分数超过所选阈值的作为短语使用。这是用来评价性能的工具。
代码:来自https://github.com/graykode/nlp-tutorial/tree/master/1-2.Word2Vec
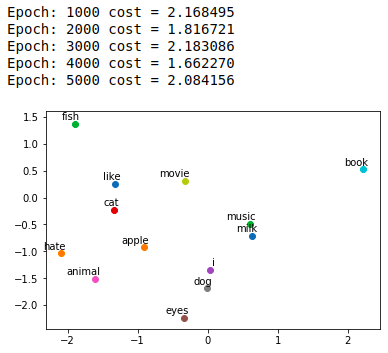
''' code by Tae Hwan Jung(Jeff Jung) @graykode ''' import numpy as np import torch import torch.nn as nn import torch.optim as optim from torch.autograd import Variable import matplotlib.pyplot as plt %matplotlib inline dtype = torch.FloatTensor # 定义一个多维张量torch # 3 Words Sentence sentences = [ "i like dog", "i like cat", "i like animal", "dog cat animal", "apple cat dog like", "dog fish milk like", "dog cat eyes like", "i like apple", "apple i hate", "apple i movie book music like", "cat dog hate", "cat dog like"] word_sequence = " ".join(sentences).split() word_list = " ".join(sentences).split() word_list = list(set(word_list)) #enumerate是一个枚举的关键词,i是键,w是值,这样就将所有单词按照自然数编成字典 word_dict = {w: i for i, w in enumerate(word_list)} # Word2Vec Parameter batch_size = 20 # To show 2 dim embedding graph embedding_size = 2 # To show 2 dim embedding graph voc_size = len(word_list) def random_batch(data, size): random_inputs = [] random_labels = [] # 随机选取sample random_index = np.random.choice(range(len(data)), size, replace=False) for i in random_index: random_inputs.append(np.eye(voc_size)[data[i][0]]) # target random_labels.append(data[i][1]) # context word return random_inputs, random_labels # Make skip gram of one size window #构建输入的samples skip_grams = [] for i in range(1, len(word_sequence) - 1): target = word_dict[word_sequence[i]] context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]] for w in context: skip_grams.append([target, w]) # Model class Word2Vec(nn.Module): def __init__(self): super(Word2Vec, self).__init__() # W and WT is not Traspose relationship # 初始化从输入到隐藏层的嵌入矩阵,参数随机初始化在(-1,1] self.W = nn.Parameter(-2 * torch.rand(voc_size, embedding_size) + 1).type(dtype) # voc_size > embedding_size Weight # 随机初始化从隐藏层到输出层的系数矩阵,参数随机初始化在(-1,1] self.WT = nn.Parameter(-2 * torch.rand(embedding_size, voc_size) + 1).type(dtype) # embedding_size > voc_size Weight # 前向传播 def forward(self, X): # X : [batch_size, voc_size] hidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size] output_layer = torch.matmul(hidden_layer, self.WT) # output_layer : [batch_size, voc_size] return output_layer model = Word2Vec() # 定义损失函数和优化 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # Training for epoch in range(5000): input_batch, target_batch = random_batch(skip_grams, batch_size) # 被定义为Varialbe类型的变量可以认为是一种常量,在pytorch反向传播过程中不对其求导 input_batch = Variable(torch.Tensor(input_batch)) target_batch = Variable(torch.LongTensor(target_batch)) optimizer.zero_grad() output = model(input_batch) # output : [batch_size, voc_size], target_batch : [batch_size] (LongTensor, not one-hot) loss = criterion(output, target_batch) if (epoch + 1)%1000 == 0: print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward() optimizer.step() for i, label in enumerate(word_list): # model.parameters()是获取模型的参数 W, WT = model.parameters() x, y = float(W[i][0]), float(W[i][1]) plt.scatter(x, y) plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.show()
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号