
python构造一个freebuf新闻发送脚本
前言:
放假学习完web漏洞后。想写一个脚本
然而自己菜无法像大佬们一样写出牛逼的东西
尝试写了,都以失败告终。
还有一个原因:上学时间不能及时看到,自己也比较懒。邮件能提醒自己。
需要安装的模块:
requests模块
smtplib模块
email模块
正文:
这个脚本的原理其实很简单把freebuf上的a标签抓取
然后获去href里面的链接与title的标题写入到txt,读取txt。发送邮箱
架空txt。间隔12个小时发一次,加上循环。

代码:
import requests
from bs4 import BeautifulSoup
import smtplib
import re
from email.mime.text import MIMEText
from email.header import Header
import time
while True:
def freebuf():
url="http://www.freebuf.com"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
res=requests.get(url,headers)
bw=res.content.decode('utf-8')
allsectool=re.findall('<a href="http://www.freebuf.com/sectool/.*?.html" target="_blank" title=".*?">',bw)
allsectoolurl=BeautifulSoup(str(allsectool),'html.parser')
osw=allsectoolurl.find_all('a')
for u1 in osw:
u3=u1.get('href')
u4=u1.get('title')
print(u3,"标题:",u4,file=open('freebuf.txt','a',encoding='utf-8'))
networkall=re.findall('<a href="http://www.freebuf.com/articles/network/.*?.html" target="_blank" title=".*?">',bw)
neturl=BeautifulSoup(str(networkall),'html.parser')
netus=neturl.find_all('a')
for y in netus:
neturls=y.get('href')
netiles=y.get('title')
print(neturls,"标题:",netiles,file=open('freebuf.txt','a',encoding='utf-8'))
jobsall=re.findall('<a href="http://www.freebuf.com/jobs/.*?.html" target="_blank" title=".*?">',bw)
jobsurl=BeautifulSoup(str(jobsall),'html.parser')
jobsurly=jobsurl.find_all('a')
for m in jobsurly:
m2=m.get('href')
m3=m.get('title')
print(m2,"标题:",m3,file=open('freebuf.txt','a',encoding='utf-8'))
newsall=re.findall('<a href="http://www.freebuf.com/news/.*?.html" target="_blank" title=".*?">',bw)
newsurl=BeautifulSoup(str(newsall),'html.parser')
usd=newsurl.find_all('a')
for g2 in usd:
psw=g2.get('href')
pswt=g2.get('title')
print(psw,"标题:",pswt,file=open('freebuf.txt','a',encoding='utf-8'))
vulsall=re.findall('<a href="http://www.freebuf.com/vuls/.*?.html" target="_blank" title=".*?">',bw)
vulsallurl=BeautifulSoup(str(vulsall),'html.parser')
gew=vulsallurl.find_all('a')
for hp in gew:
hpw=hp.get('href')
gpw2=hp.get('title')
print(hpw,"标题:",gpw2,file=open('freebuf.txt','a',encoding='utf-8'))
system=re.findall('<a href="http://www.freebuf.com/articles/system/166121.html" target="_blank" title=".*?">',bw)
systemurl=BeautifulSoup(str(system),'html.parser')
sys=systemurl.find_all('a')
for v in sys:
v1=v.get('href')
v2=v.get('title')
print(v1,"标题:",v2,file=open('freebuf.txt','a',encoding='utf-8'))
freebuf()
def Email():
try:
lk = open('freebuf.txt', 'r',encoding='utf-8')
pg = lk.read()
lk.close()
except Exception as g:
print('[-]报错', g)
sender="发送人"
recivs="接收人"
message=MIMEText('''
freebuf新闻快报\n
{}\n
'''.format(str(pg)),'plain','utf-8')
message['From']=Header('发送人')
sub="freebuf安全快报"
message['subject']=Header(sub,'utf-8')
try:
smtp=smtplib.SMTP()
smtp.connect("smtp服务",25)
smtp.login("你自己的邮箱","你自己的邮箱密码")
smtp.sendmail(sender,recivs,message.as_string())
print('[+]发送成功')
except Exception as l:
print('[-]发送失败',l)
ws=open('freebuf.txt','w')
Email()
time.sleep(43200)
运行截图

qq邮箱接收到的:
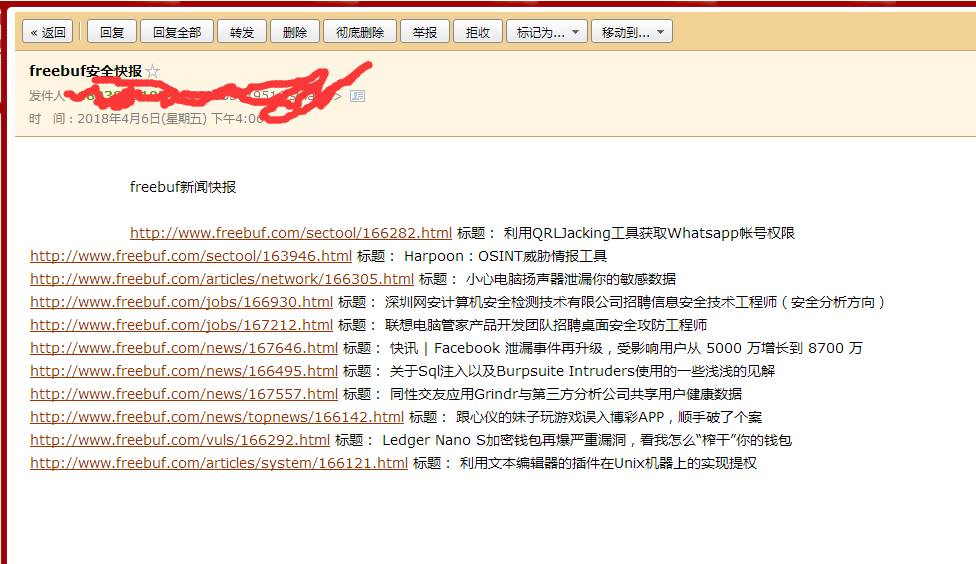
可以根据自己的喜好去抓取。


