burpsuite扫描web目录
1.进行抓包
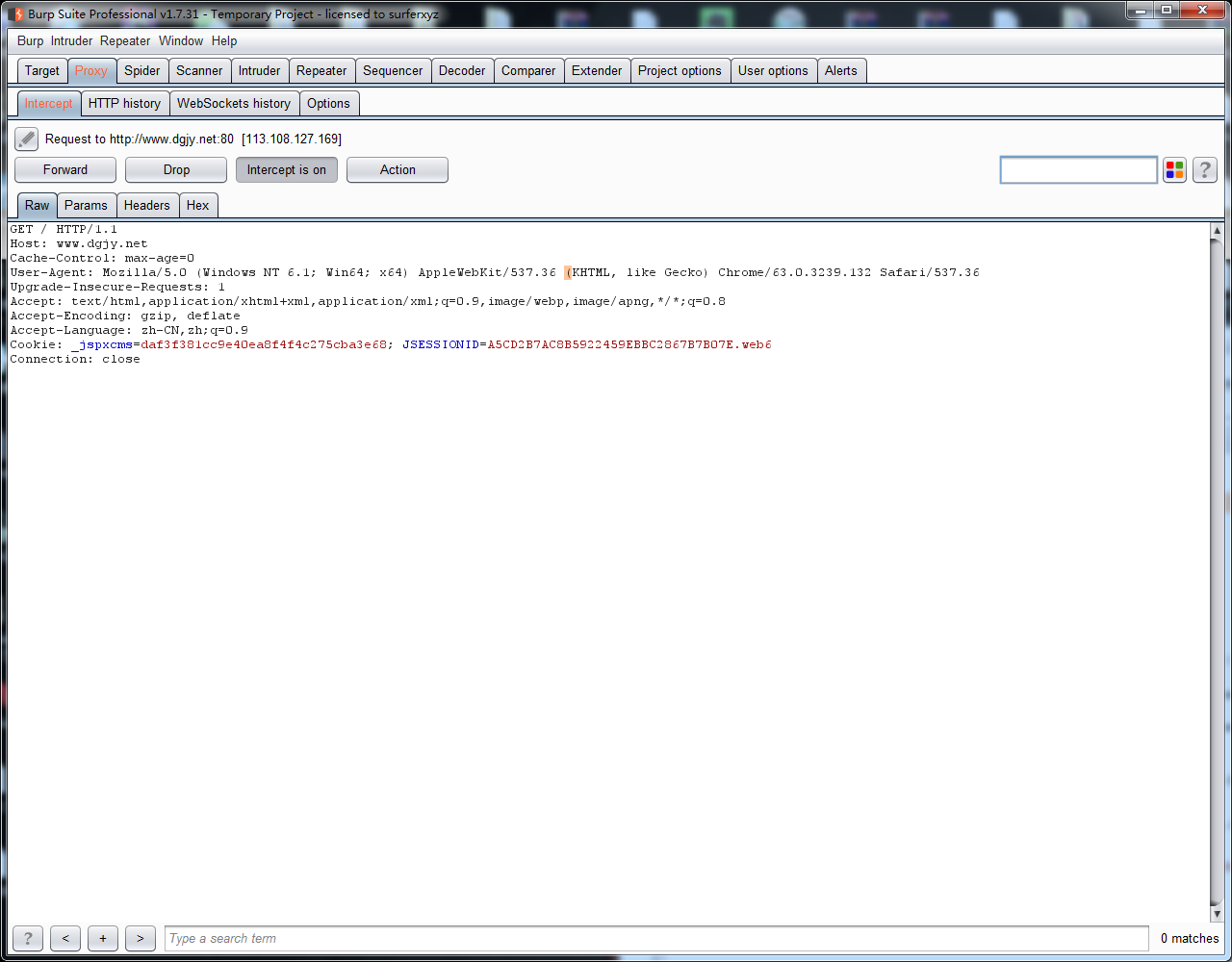
2.将其发送到lntruder
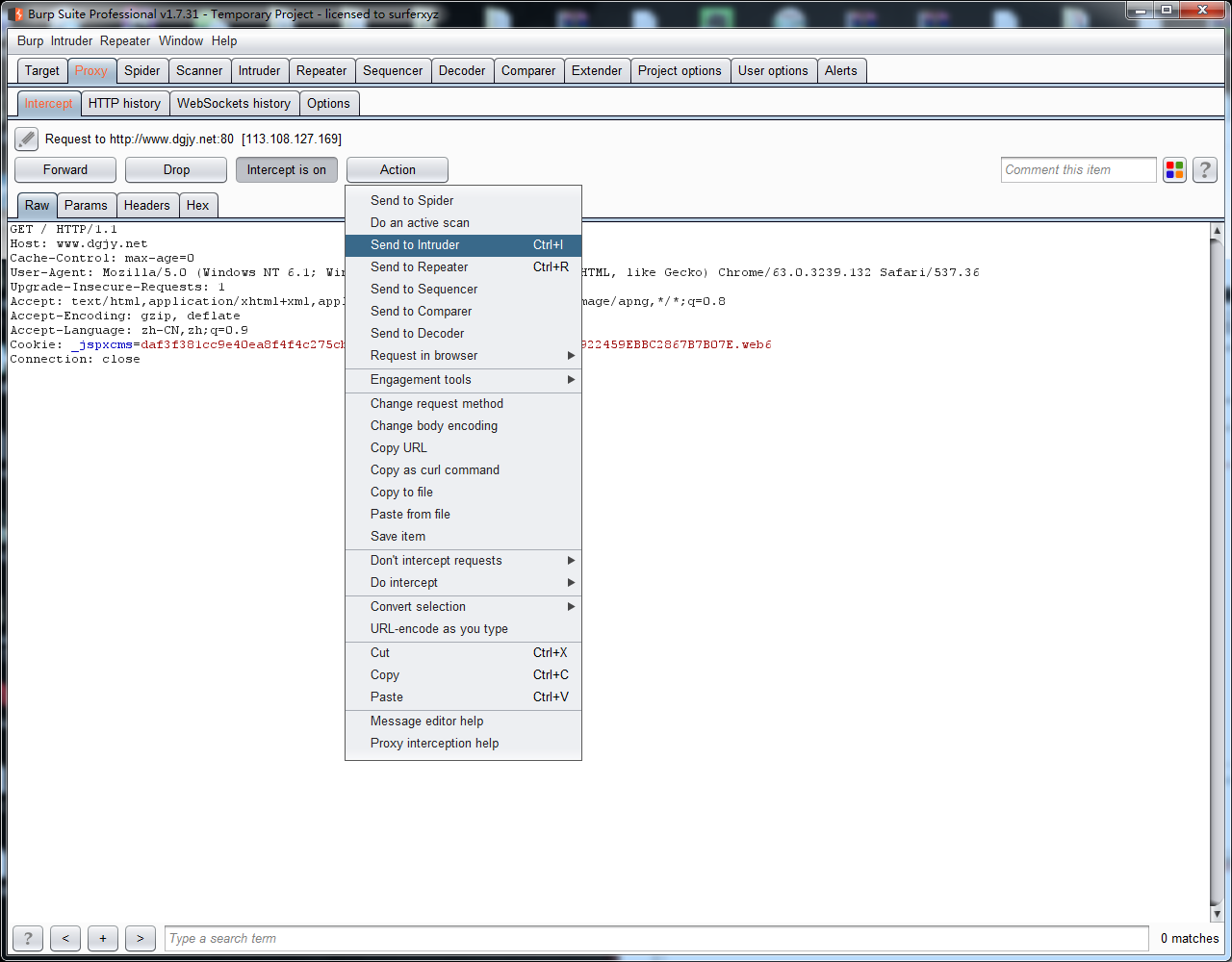
3.使用替换脚本替换掉/
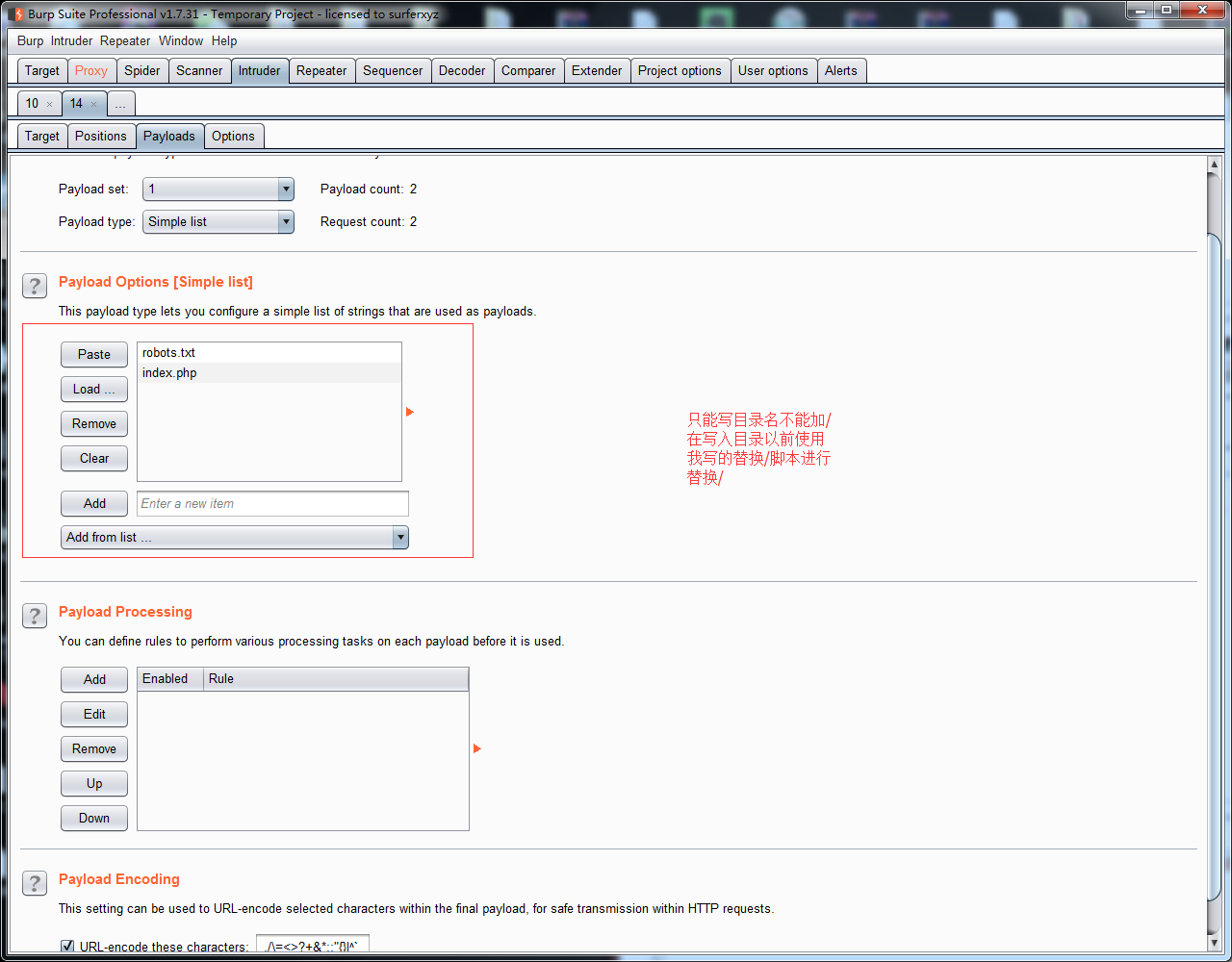
4.替换![]()
5.替换结果

6.将多余的$$删除,在/后面添加$$ //$$就是payload
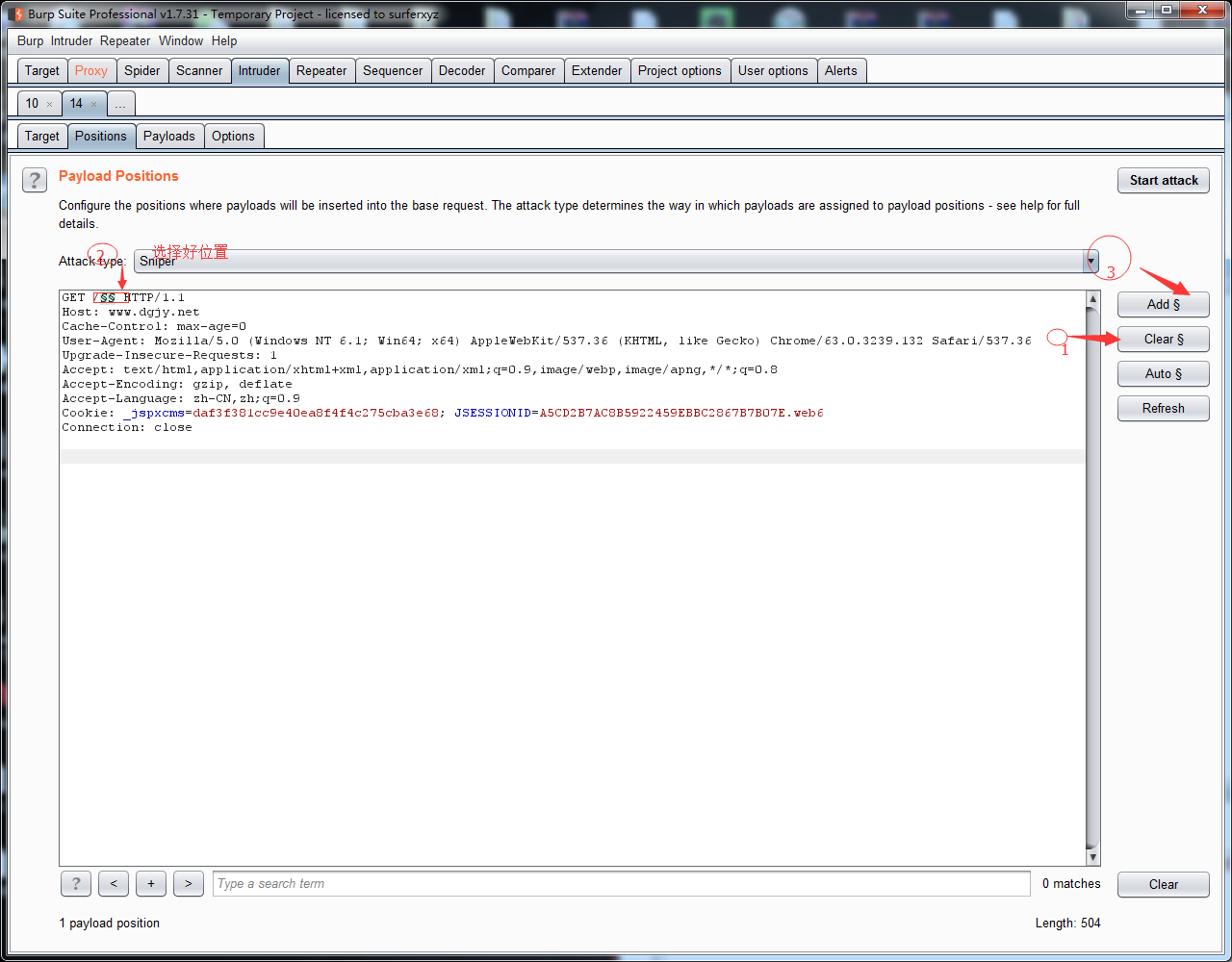
7.测试结果

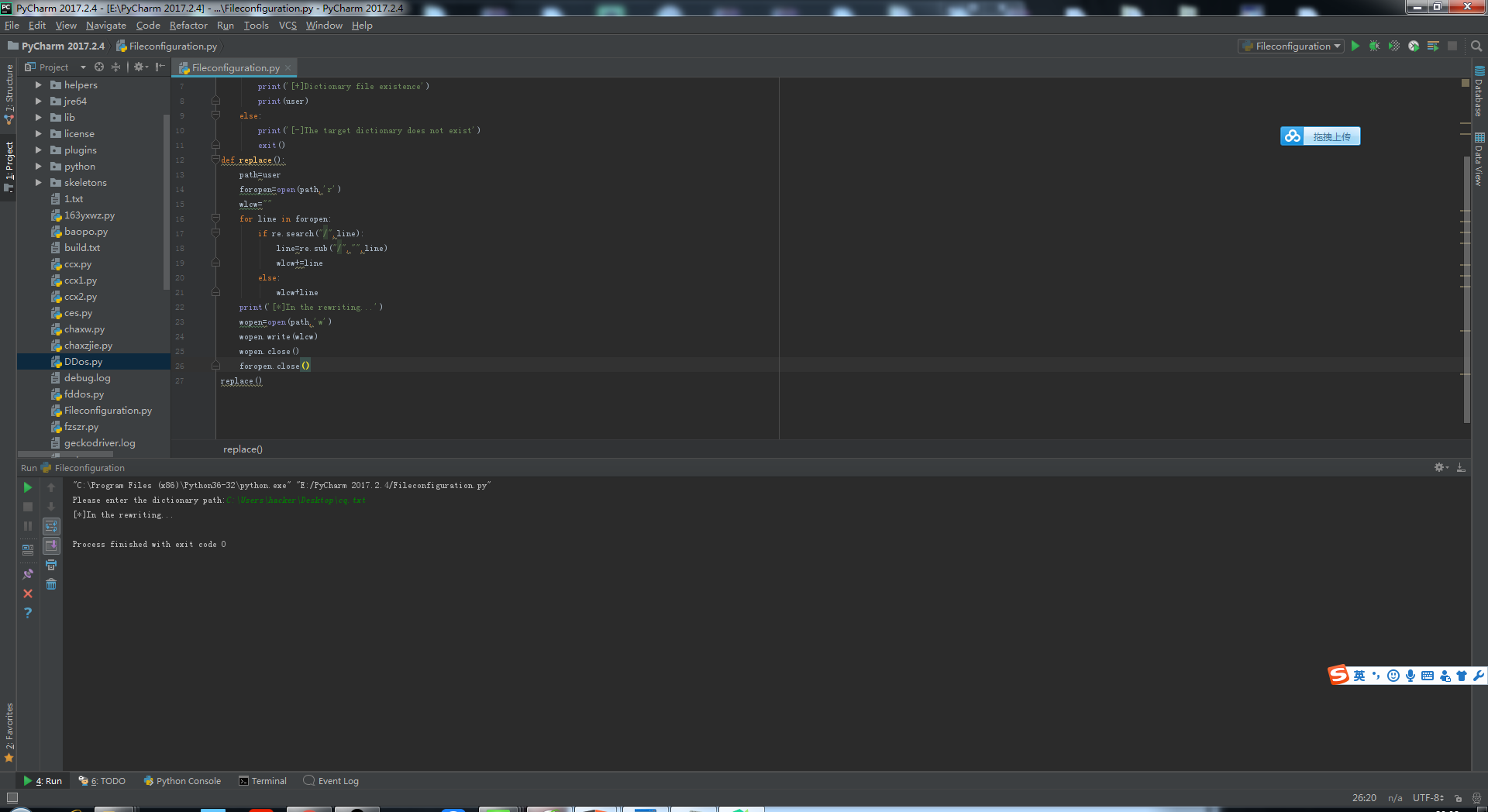
替换脚本代码:
import os
import re
user = input('Please enter the dictionary path:')
def config():
path="{}".format(user)
if os.path.exists(path):
print('[+]Dictionary file existence')
print(user)
else:
print('[-]The target dictionary does not exist')
exit()
def replace():
path=user
foropen=open(path,'r')
wlcw=""
for line in foropen:
if re.search("/",line):
line=re.sub("/","",line)
wlcw+=line
else:
wlcw+line
print('[*]In the rewriting...')
wopen=open(path,'w')
wopen.write(wlcw)
wopen.close()
foropen.close()
replace()

