python查询完结篇
0x00
网上找一个查询网站,然后自己写的一个脚本
0x01
代码送上:
import requests
import time
from bs4 import BeautifulSoup
strat=time.time()
def chax():
lid=input('请输入你要查询的域名:')
head={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url="http://site.ip138.com/{}/".format(lid)
urldomain="http://site.ip138.com/{}/domain.htm".format(lid)
url2="http://site.ip138.com/{}/beian.htm".format(lid)
url3="http://site.ip138.com/{}/whois.htm".format(lid)
rb=requests.get(url,headers=head)
rb1=requests.get(urldomain,headers=head)
rb2=requests.get(url2,headers=head)
rb3=requests.get(url3,headers=head)
gf=BeautifulSoup(rb.content,'html.parser')
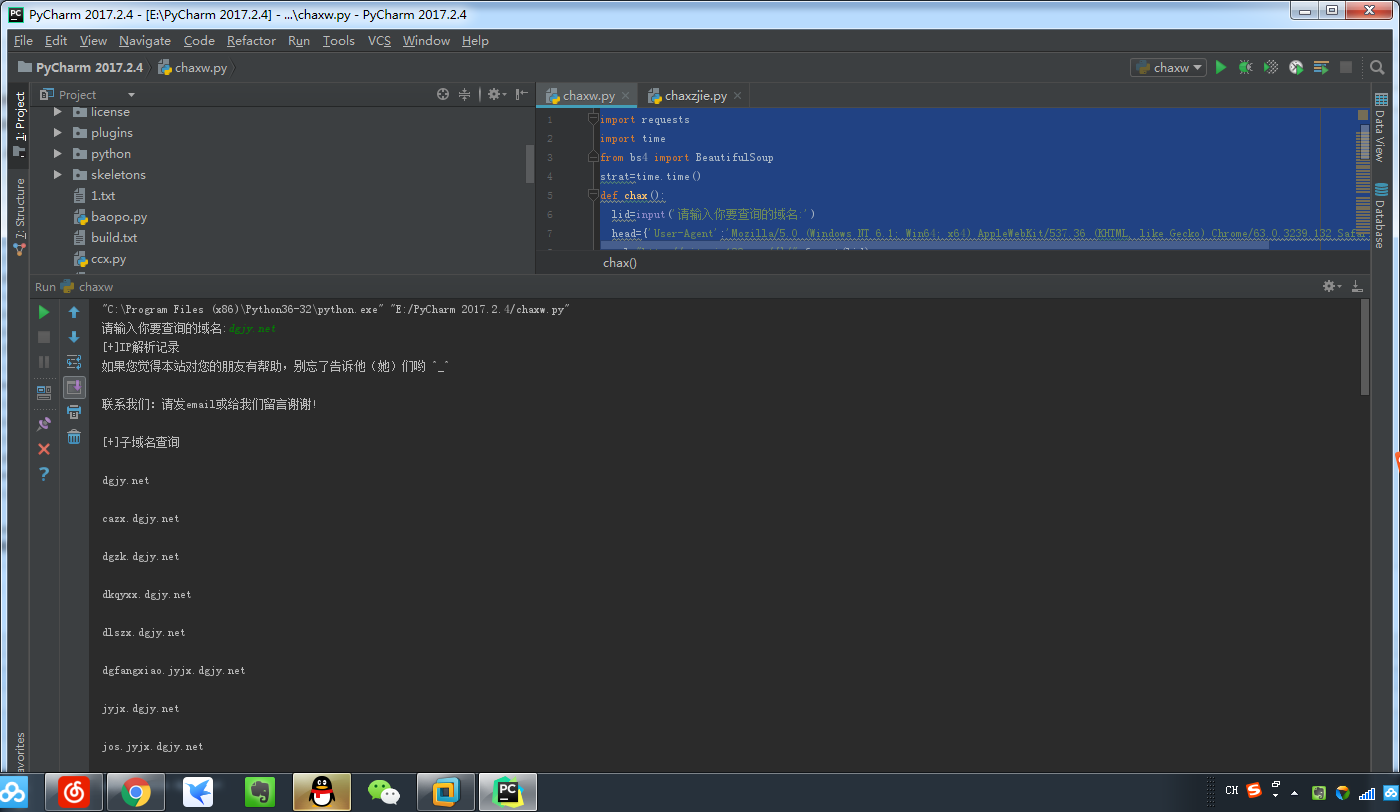
print('[+]IP解析记录')
for x in gf.find_all('p'):
link=x.get_text()
print(link)
gf1=BeautifulSoup(rb1.content,'html.parser')
print('[+]子域名查询')
for v in gf1.find_all('p'):
link2=v.get_text()
print(link2)
gf2=BeautifulSoup(rb2.content,'html.parser')
print('[+]备案查询')
for s in gf2.find_all('p'):
link3=s.get_text()
print(link3)
gf3=BeautifulSoup(rb3.content,'html.parser')
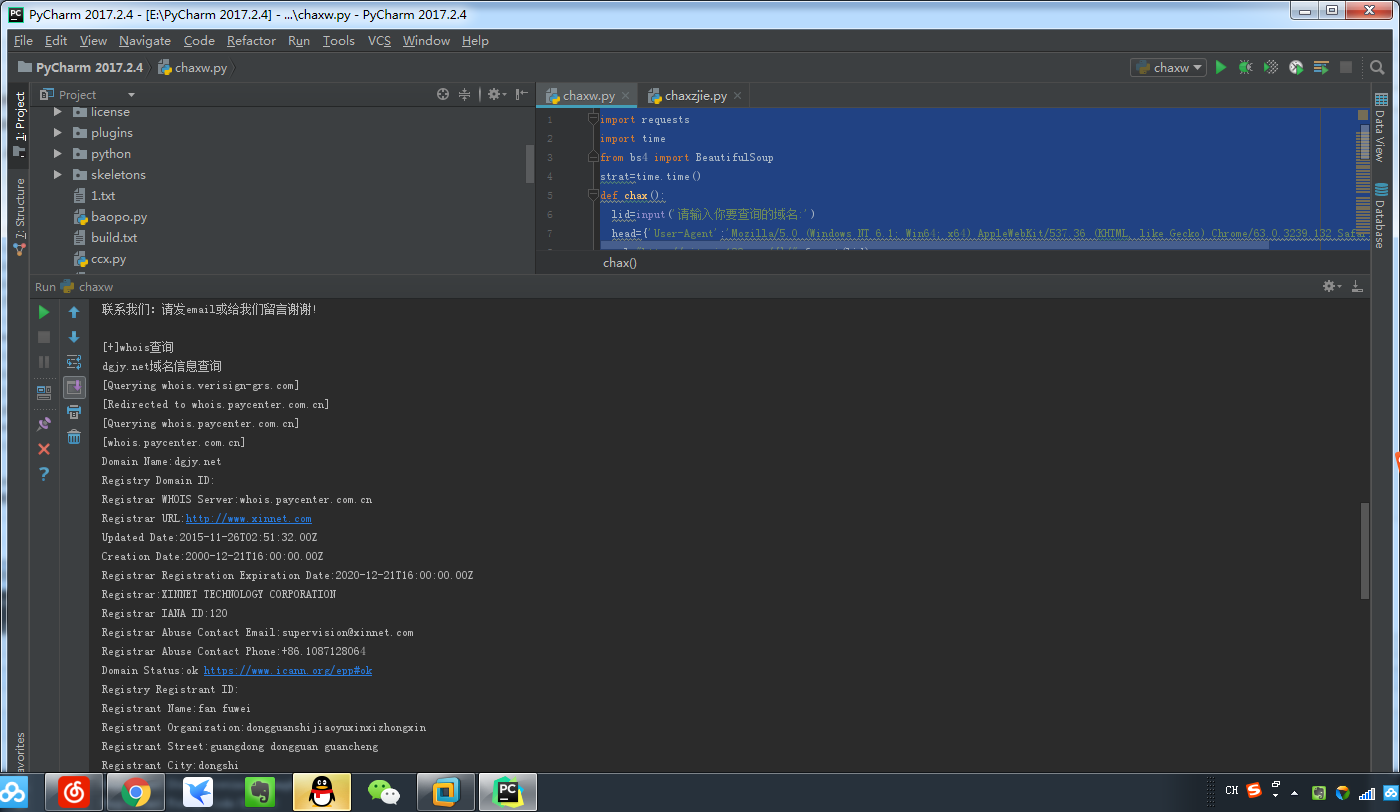
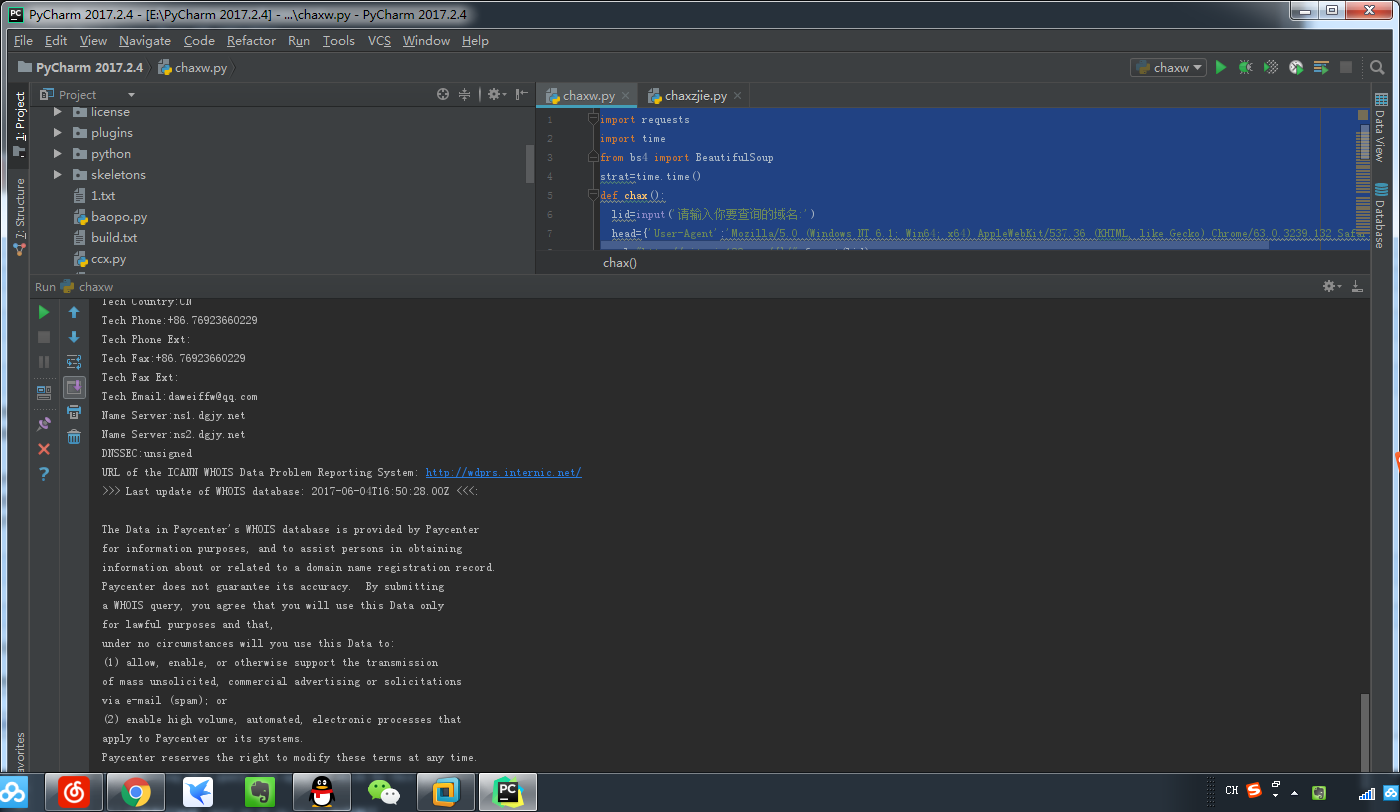
print('[+]whois查询')
for k in gf3.find_all('p'):
link4=k.get_text()
print(link4)
chax()
end=time.time()
print('查询耗时:',end-strat)
运行截图: