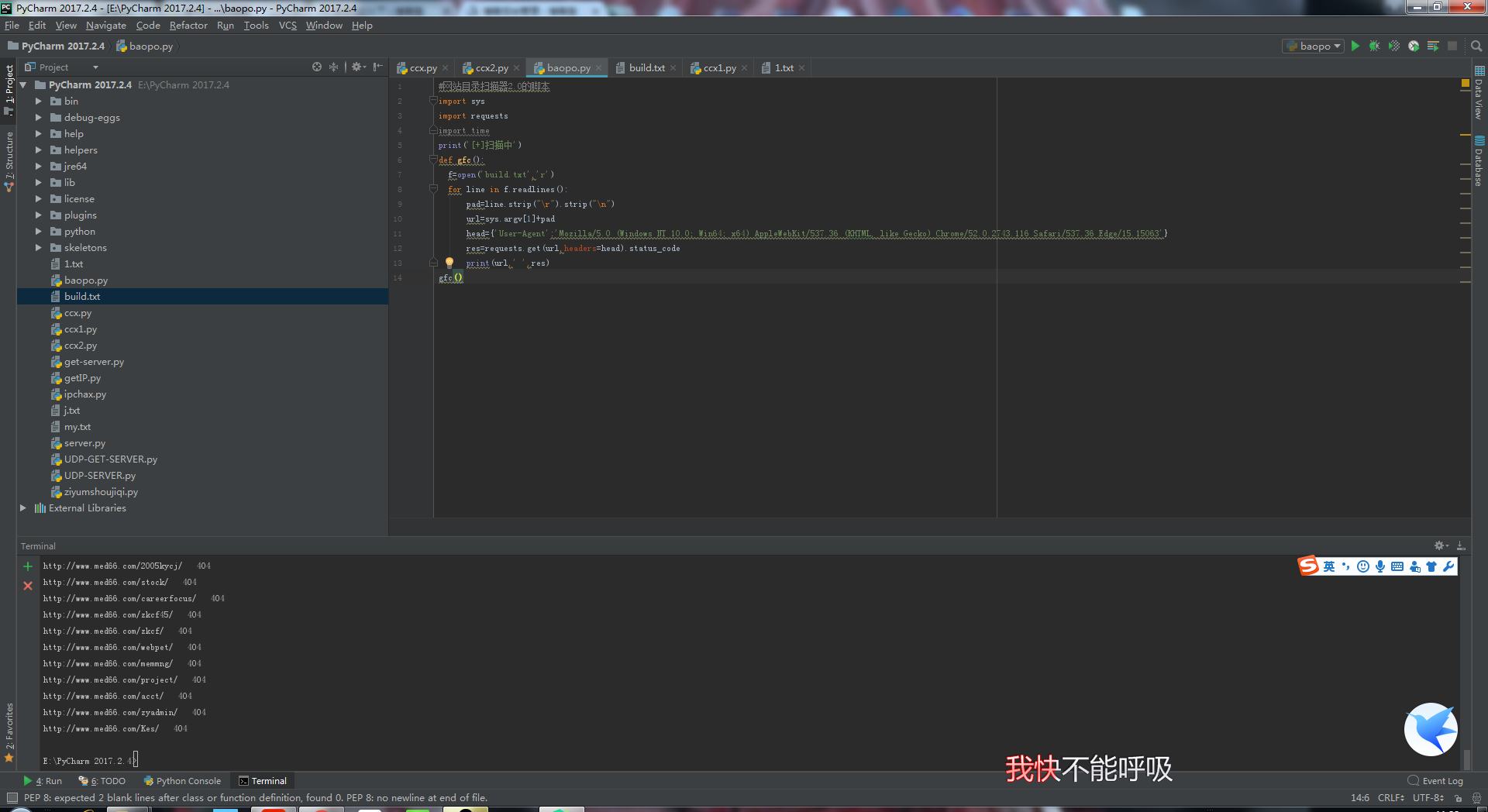
python网站目录扫描器2.0版
改进了上次乱的要死的。
#网站目录扫描器2.0的脚本
import sys
import requests
import time
print('[+]扫描中')
def gfc():
f=open('build.txt','r')
for line in f.readlines():
pad=line.strip("\r").strip("\n")
url=sys.argv[1]+pad
head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
res=requests.get(url,headers=head).status_code
print(url,' ',res)
gfc()
运行截图: