

性能测试实战
1、什么是性能测试?
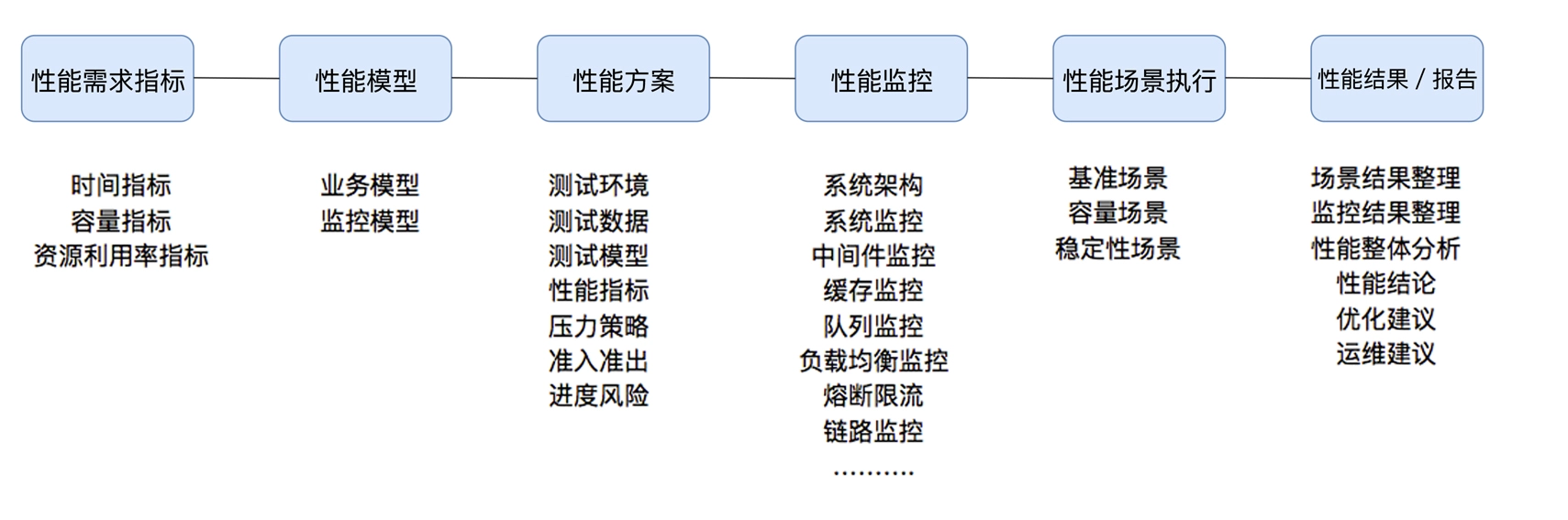
性能测试就是针对系统的性能指标,建立性能测试模型,制定性能测试方案,制定监控策略,在场景条件之下执行性能场景,分析判断性能瓶颈并调优,最终得出性能结果来评估系统的性能指标是否满足既定值。
性能测试需要有指标:理论上合理的,并且应该有的指标是:时间指标、容量指标和资源利用率指标。而这里的指标又会有细分,细分的概念又是一团乱。这个话题我们后面再描述。
性能测试需要有模型:模型是什么?它是真实场景的抽象,可以告诉性能测试人员,业务模型是什么样子。性能测试要选择适合自己系统业务逻辑的方式,用最低的成本、最快的时间来做事情。
性能测试要有方案:方案规定的内容中有几个关键点,分别是测试环境、测试数据、测试模型、性能指标、压力策略、准入准出和进度风险。基本上有这些内容就够了,这些内容具体的信息还需要精准。
性能测试中要有监控:这个部分的监控,要有分层、分段的能力,要有全局监控、定向监控的能力。关于这一点,我将在第三模块详细说明。
性能测试要有预定的条件:这里的条件包括软硬件环境、测试数据、测试执行策略、压力补偿等内容。要是展开来说,在场景执行之前,这些条件应该是确定的。
性能测试中要有场景:在既定的环境(包括动态扩展等策略)、既定的数据(包括场景执行中的数据变化)、既定的执行策略、既定的监控之下,执行性能脚本,同时观察系统各层级的性能状态参数变化,并实时判断分析场景是否符合预期。
性能测试中要有分析调优:针对给定的系统,做全面的性能测试,同时将系统调优到最优状态。
性能测试肯定要有结果报告:在报告中写上调优前后的 TPS、响应时间以及资源对比图。
2、性能综述-TPS和响应时间之间是什么关系
性能场景:有基准性能场景、容量性能场景、稳定性性能场景、异常性能场景。
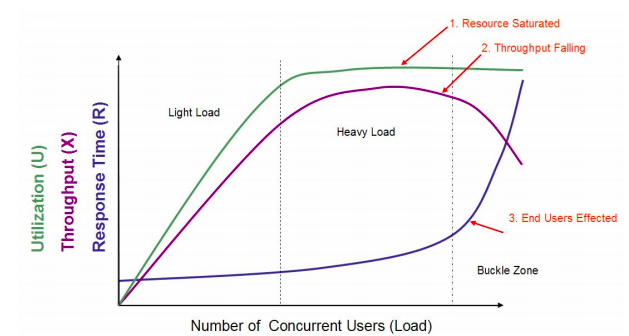
在这个图中,定义了三条曲线、三个区域、两个点以及三个状态描述。
1、三条曲线:吞吐量的曲线(紫色)、利用率(绿色)、响应时间曲线(深蓝色)。
2、三个区域:轻负载区(Light Load)、重负载区(Heavy Load)、塌陷区(Buckle Zone)。
3、两个点:最优并发用户数(The Optimum Number of Concurrent Users)、最大并发用户数(The Maximum Number of Concurrent Users)。
4、三个状态描述:资源饱和(Resource Saturated)、吞吐下降(Throughput Falling)、用户受影响(End Users Effected)。
我们简化出另一个图形,以说明更直接一点的关系。如下所示:
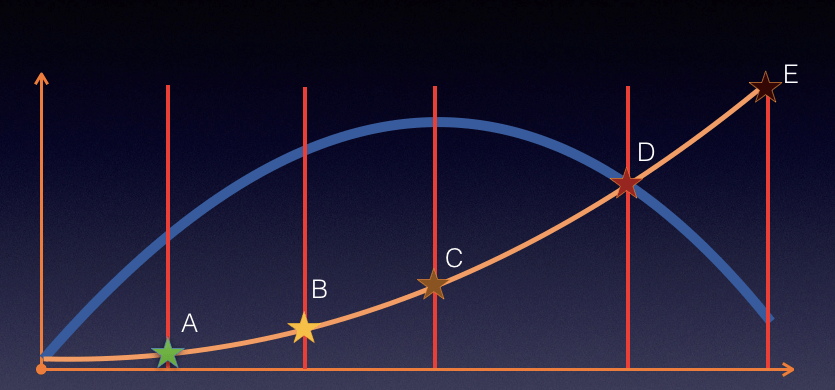
上图中蓝线表示 TPS,黄色表示响应时间。
在 TPS 增加的过程中,响应时间一开始会处在较低的状态,也就是在 A 点之前。接着响应时间开始有些增加,直到业务可以承受的时间点 B,这时 TPS 仍然有增长的空间。再接着增加压力,达到 C 点时,达到最大 TPS。我们再接着增加压力,响应时间接着增加,但 TPS 会有下降(请注意,这里并不是必然的,有些系统在队列上处理得很好,会保持稳定的 TPS,然后多出来的请求都被友好拒绝)。最后,响应时间过长,达到了超时的程度。

总之,在具体的性能项目中,性能场景是一个非常核心的概念。因为它会包括压力发起策略、业务模型、监控模型、性能数据(性能中的数据,我一直都不把它称之为模型,因为在数据层面,测试并没有做过什么抽象的动作,只是使用)、软硬件环境、分析模型等。
3、性能综述:怎么理解TPS、QPS、RT、吞吐量这些性能指标?
一张示意图以便理解业务指标和性能指标之间的关系:
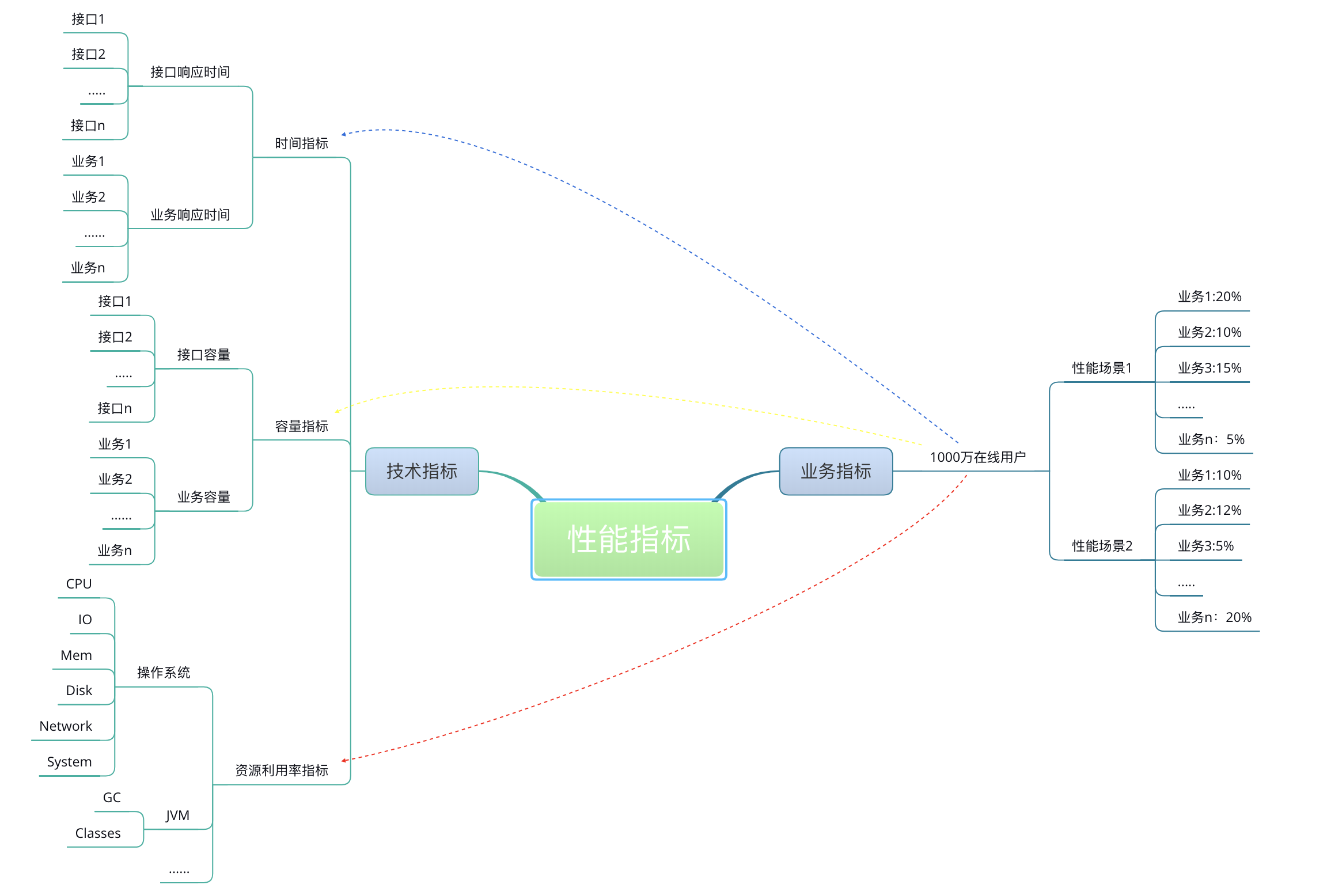
性能测试行业常用的性能指标表示法:

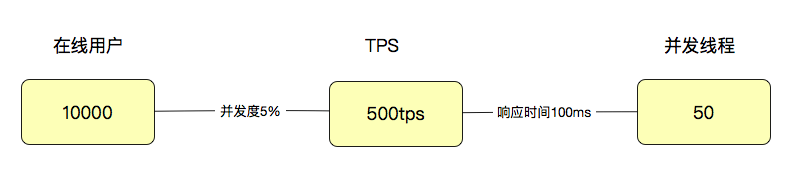
那么用户数怎么来定义呢?
涉及到用户就会比较麻烦一点。因为用户有了业务含义,所以有些人认为一个系统如果有 1 万个用户在线,那就应该测试 1 万的并发线程,这种逻辑实在是不技术。通常,我们会对在线的用户做并发度的分析,在很多业务中,并发度都会低于 5%,甚至低于 1%。
拿 5% 来计算,就是 10000 用户 x5%=500(用户级 TPS),注意哦,这里是 TPS,而不是并发线程数。如果这时响应时间是 100ms,那显然并发线程数是 500TPS/(1000ms/100ms)=50(并发线程)。通过这样简单的计算逻辑,我们就可以看出来用户数、线程数和 TPS 之间的关系了。
性能测试概念中:性能指标、性能模型、性能场景、性能监控、性能实施、性能报告。
性能场景中:基准场景、容量场景、稳定性场景、异常场景。
性能指标中:TPS、RT。 (记住 T 的定义是根据不同的目标来的)
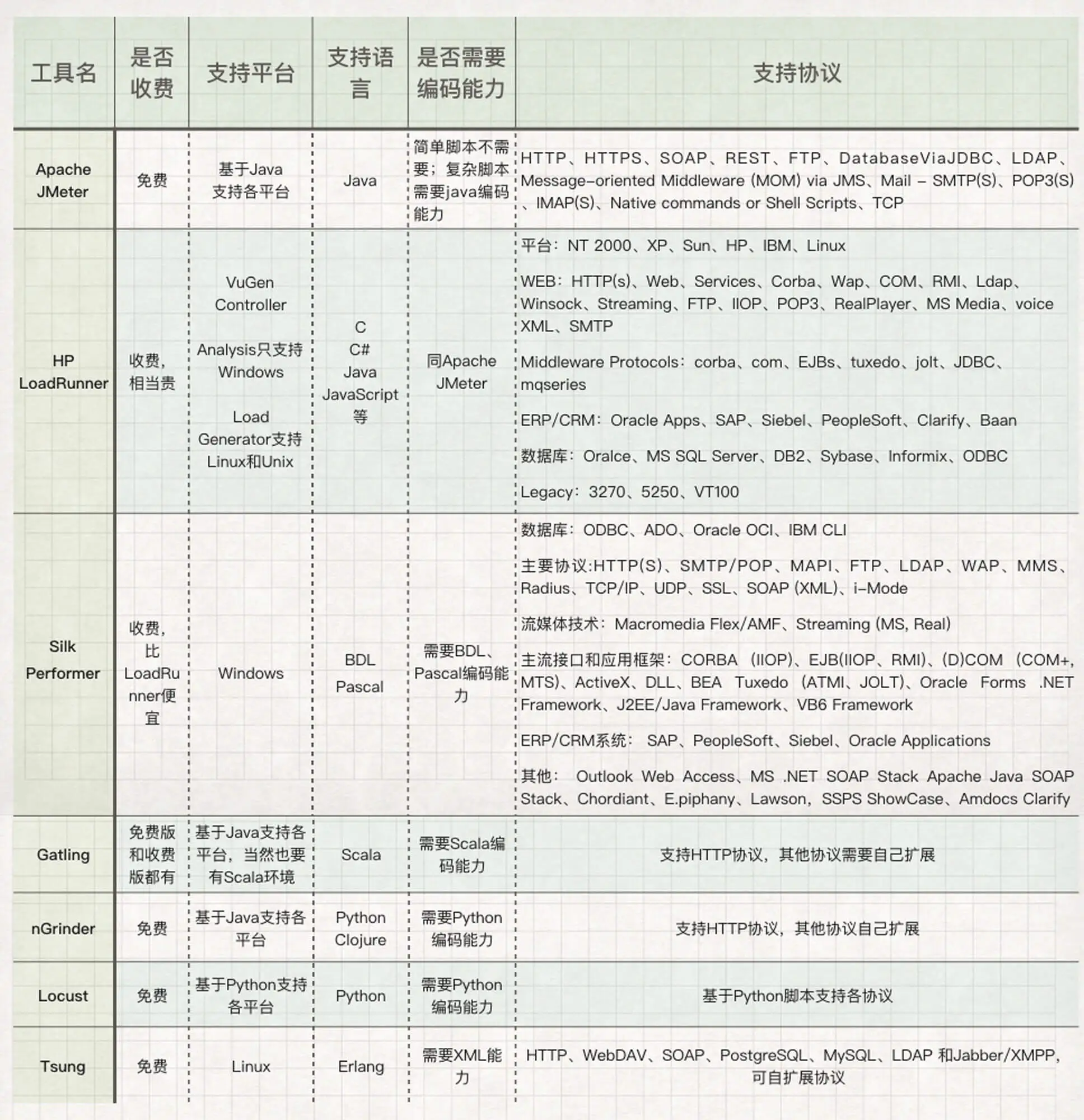
下面列一下市场上大大小小、老老少少、长长短短的性能测试工具,以备大家查阅:

下面我对一些比较常见的工具做下比对,这些工具主要包括 Apache JMeter、HP LoadRunner、Silk Performer、Gatling、nGrinder、Locust 和 Tsung:
4、指标关系:你知道并发用户数应该怎么算吗?
那么如何来描述并发用户数呢?在这里我建议用 TPS 来承载“并发”这个概念。并发数是 16TPS,就是 1 秒内整个系统处理了 16 个事务。
为了能 hold 住更多的用户,我们通常都会把一些数据放到 Redis 这样的缓存服务器中。所以在线用户数怎么算呢,如果仅从上面这种简单的图来看的话,其实就是缓存服务器能有多大,能 hold 住多少用户需要的数据。最多再加上在超时路上的用户数。如下所示:
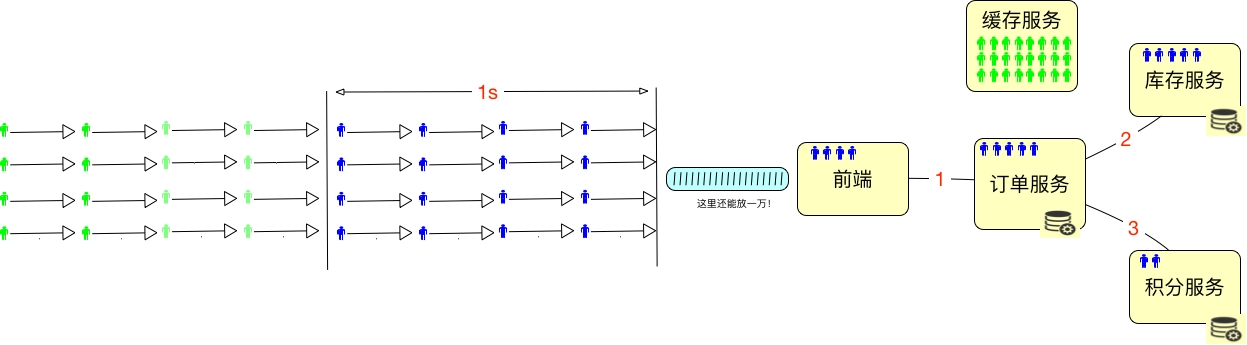
所以我们要是想知道在线的最大的用户数是多少,对于一个设计逻辑清晰的系统来说,不用测试就可以知道,直接拿缓存的内存来算就可以了。假设一个用户进入系统之后,需要用 10k 内存来维护一个用户的信息,那么 10G 的内存就能 hold 住 1,048,576 个用户的数据,这就是最大在线用户数了。在实际的项目中,我们还会将超时放在一起来考虑。
但并发用户数不同,他们需要在系统中执行某个动作。我们要测试的重中之重,就是统计这些正在执行动作的并发用户数。

通过这个图,我们可以看到一个简单的计算逻辑:如果有 10000 个在线用户数,同时并发度是 1%,那显然并发用户数就是 100。如果每个线程的 20TPS,显然只需要 5 个线程就够了(请注意,这里说的线程指的是压力机的线程数)。这时对 Server 来说,它处理的就是 100TPS,平均响应时间是 50ms。50ms 就是根据 1000ms/20TPS 得来的(请注意,这里说的平均响应时间会在一个区间内浮动,但只要 TPS 不变,这个平均响应时间就不会变)。如果我们有两个 Server 线程来处理,那么一个线程就是 50TPS,这个很直接吧。请大家注意,这里我有一个转换的细节,那就是并发用户数到压力机的并发线程数。这一步,我们通常怎么做呢?就是基准测试的第一步。关于这一点,我们在后续的场景中交待。而我们通常说的“并发”这个词,依赖 TPS 来承载的时候,指的都是 Server 端的处理能力,并不是压力工具上的并发线程数。在上面的例子中,我们说的并发就是指服务器上 100TPS 的处理能力,而不是指 5 个压力机的并发线程数。请你切记这一点,以免沟通障碍。
压测场景,在压力机上启动 10 个线程。结果如下:
summary + 11742 in 00:00:30 = 391.3/s Avg: 25 Min: 0 Max: 335 Err: 0 (0.00%) Active: 10 Started: 10 Finished: 0
summary = 55761 in 00:02:24 = 386.6/s Avg: 25 Min: 0 Max: 346 Err: 0 (0.00%)
summary + 11924 in 00:00:30 = 397.5/s Avg: 25 Min: 0 Max: 80 Err: 0 (0.00%) Active: 10 Started: 10 Finished: 0
summary = 67685 in 00:02:54 = 388.5/s Avg: 25 Min: 0 Max: 346 Err: 0 (0.00%)
summary + 11884 in 00:00:30 = 396.2/s Avg: 25 Min: 0 Max: 240 Err: 0 (0.00%) Active: 10 Started: 10 Finished: 0
summary = 79569 in 00:03:24 = 389.6/s Avg: 25 Min: 0 Max: 346 Err: 0 (0.00%)
平均响应时间在 25ms,我们来计算一处,(1000ms/25ms)*10=400TPS,而最新刷出来的一条是 396.2,是不是非常合理?再回来看看服务端的线程:

5 个线程,现在就忙了很多。
并发用户数(TPS)是 396.2TPS。如果并发度为 5%,在线用户数就是 396.2/5%=7924。响应时间是 25ms。压力机并发线程数是 10。这一条,我们通常也不对非专业人士描述,只要性能测试工程师自己知道就可以了。
如果要有公式的话,这个计算公式将非常简单:
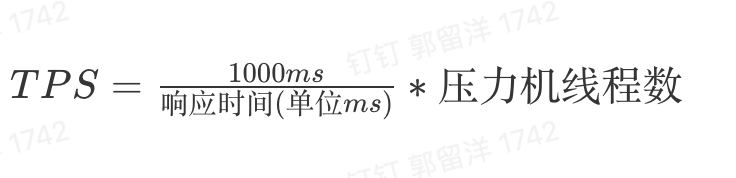
5、性能测试分析的能力阶梯视图,如下:
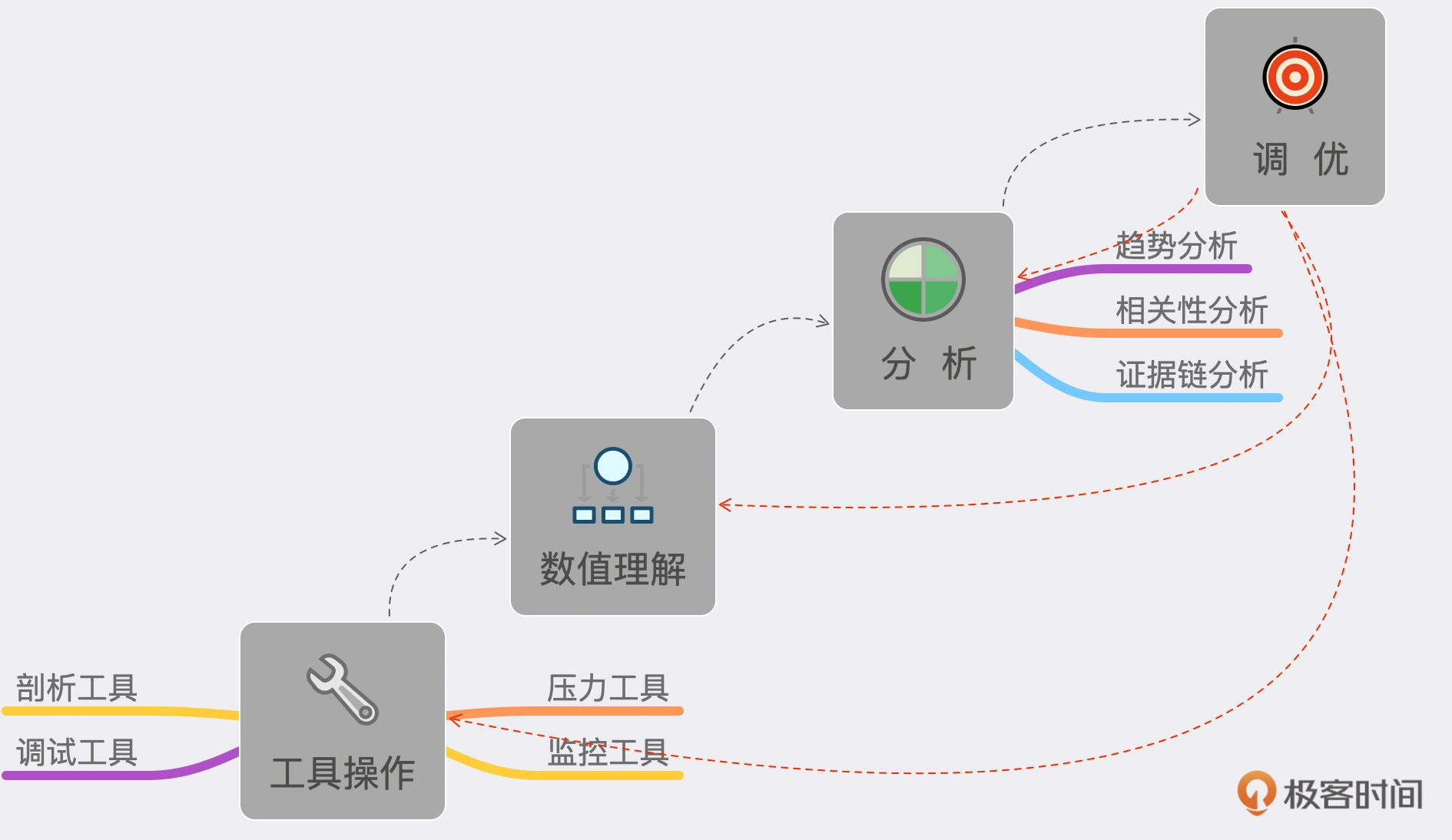
工具操作:包括压力工具、监控工具、剖析工具、调试工具。数值理解:包括上面工具中所有输出的数据。趋势分析、相关性分析、证据链分析:就是理解了工具产生的数值之后,还要把它们的逻辑关系想明白。这才是性能测试分析中最重要的一环。最后才是调优:有了第 3 步之后,调优的方案策略就有很多种了,具体选择取决于调优成本和产生的效果。
对一个系统来说,如果仅在改变压力策略(其他的条件比如环境、数据、软硬件配置等都不变)的情况下,系统的最大 TPS 上限是固定的。
对于场景中线程(有些工具中叫虚拟用户)递增的策略,我们要做到以下几点:
1、场景中的线程递增一定是连续的,并且在递增的过程中也是有梯度的。
2、场景中的线程递增一定要和 TPS 的递增有比例关系,而不是突然达到最上限。后面在场景的篇幅中我们会再说它们之间的比例关系。
3、上面两点针对的是常规的性能场景。对于秒杀类的场景,我们前期一定是做好了系统预热的工作的,在预热之后,线程突增产生的压力,也是在可处理范围的。这时,我们可以设计线程突增的场景来看系统瞬间的处理能力。如果不能模拟出秒杀的陡增,就是不合理的场景。
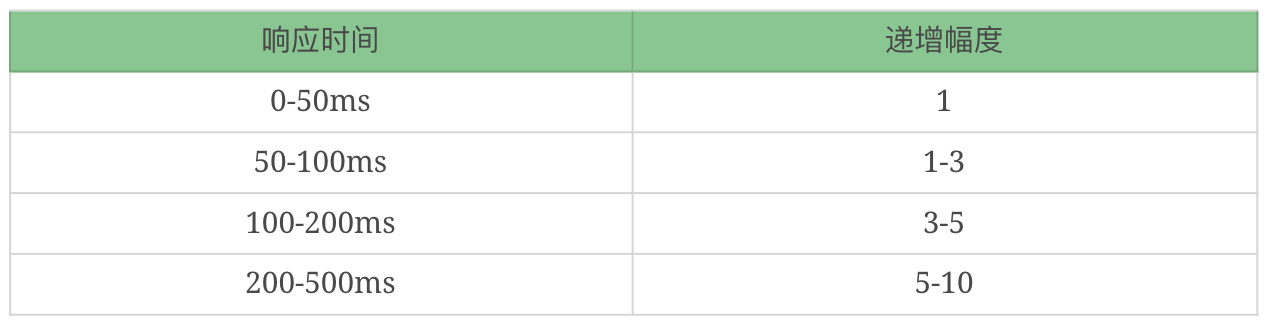
这里给出我做性能场景递增的经验值:
6、性能衰减的过程
我们先看一个压力过程中产生的结果图。
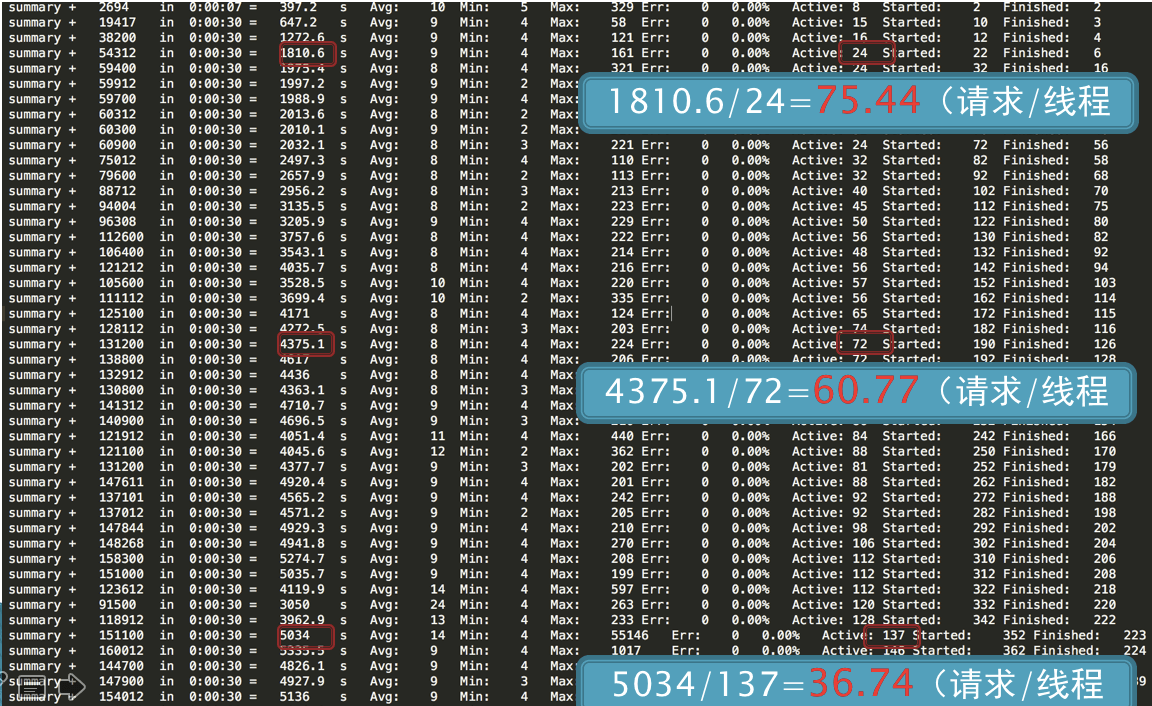
在递增的压力过程中,随着用户数的增加。我们可以做几次计算。
第一次计算,在线程达到 24 时,TPS 为 1810.6,也就是每线程每秒发出 75.44 个请求。
第二次计算,在线程达到 72 时,TPS 为 4375.1,也就是每线程每秒发出 60.77 个请求。
第三次计算,在线程达到 137 时,TPS 为 5034,也就是每线程每秒发出 36.74 个请求。
通过这三次计算,我们是不是可以看到,每线程每秒发出的请求数在变少,但是整体 TPS 是在增加的。
但实际上,通过我们的计算可以知道,性能是在不断地衰减的。我们来看一张统计图:
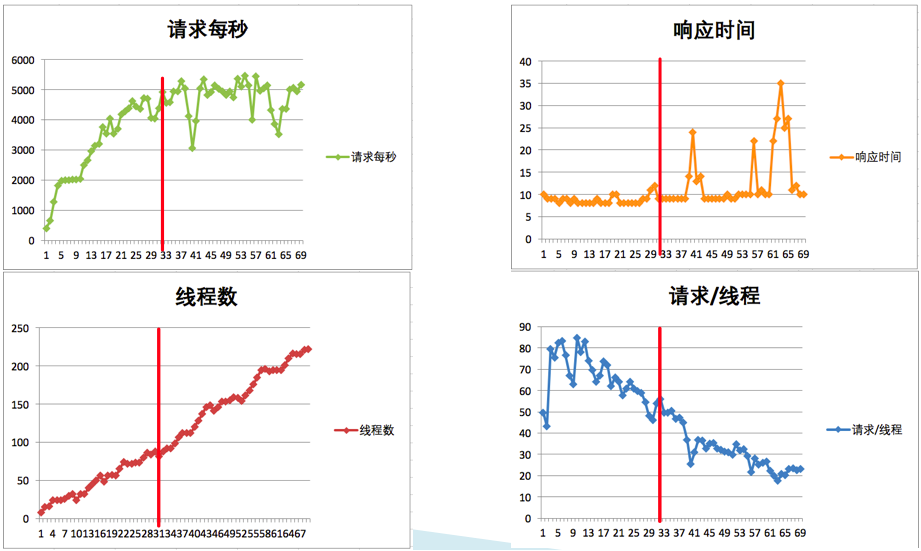
其实我就是想告诉你,只要每线程每秒的 TPS 开始变少,就意味着性能瓶颈已经出现了。但是瓶颈出现之后,并不是说服务器的处理能力(这里我们用 TPS 来描述)会下降,应该说 TPS 仍然会上升,在性能不断衰减的过程中,TPS 就会达到上限。
7、响应时间的拆分
在性能分析中,响应时间的拆分通常是一个分析起点。因为在性能场景中,不管是什么原因,只要系统达到了瓶颈,再接着增加压力,肯定会导致响应时间的上升,直到超时为止。
如果我们是这样的架构,拆分时间应该是比较清楚的。

首先我们需要查看 Nginx 上的时间。日志里就可以通过配置 requesttimeupstream_response_time 得到日志如下信息:
14.131.17.129 - - [09/Dec/2019:08:08:09 +0000] "GET / HTTP/1.1" 200 25317 0.028 0.028
最后两列中,前面是请求时间的 28ms,后面是后端响应时间的 28ms。同时,我们再到 Tomcat 上去看时间。
172.18.0.1 - - [09/Dec/2019:08:08:09 +0000] "GET / HTTP/1.1" 200 25317 28 27 http-nio-8080-exec-1
请求时间消耗了 28ms,响应时间消耗了 27ms。接着再来看一下前端的时间消耗。

从这里可以看到,从发出请求到接收到第一个字节,即 TTFB 是 55.01ms,内容下载用了 11.75ms。从这就可以看得出 Nginx 基本上没消耗时间,因为它和 Tomcat 上的请求响应时间非常接近。
那么网络上的消耗时间怎么样呢?我看到有很多人用 TTFB 来描述网络的时间。先来说明一下,TTFB 中显然包括了后端一系列处理和网络传输的时间。如下图所示。

8、构建分析决策树
分析决策树,对性能测试分析人员实在是太重要了,是性能分析中不可或缺的一环。它是对架构的梳理,是对系统的梳理,是对问题的梳理,是对查找证据链过程的梳理,是对分析思路的梳理。它起的是纵观全局,高屋建瓴的指导作用。
性能做到了艺术的层级之后,分析决策树就是提炼出来的,可以触类旁通的方法论。而我要在这里跟你讲的,就是这样的方法论。应该说,所有的技术行业在面对自己的问题时,都需要有分析决策树。再广而推之的话,所有的问题都要有分析决策树来协助。通过上面的几个步骤,我们就会知道时间消耗在了哪个节点上。那么之后呢?又当如何?总要找到根本的原因才可以吧,我画了如下的分析决策图:
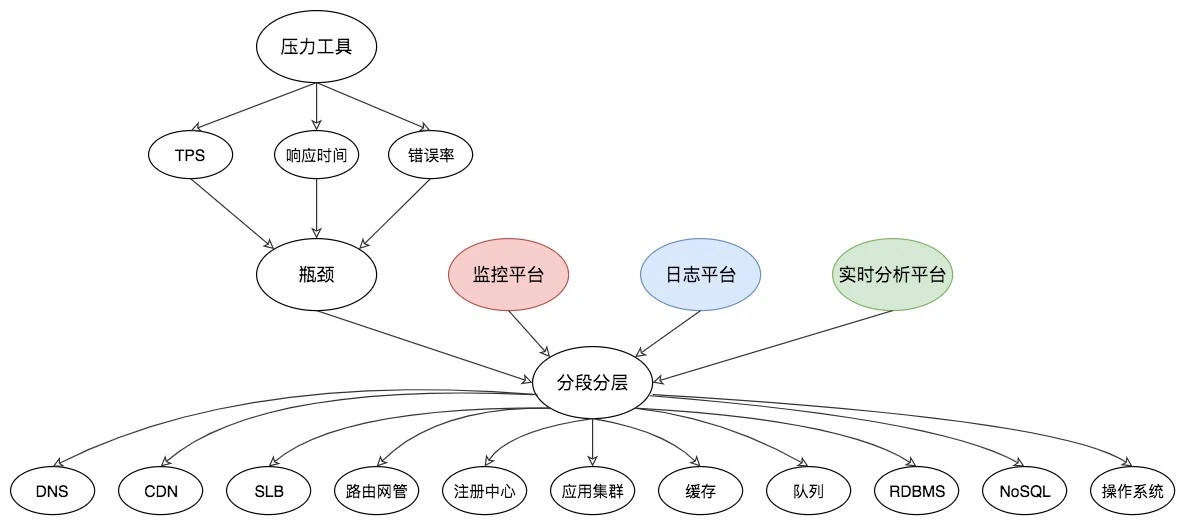
我在这里,以数据库分析和操作系统分析举一下例子。首先我们看一下数据库分析决策树。比如针对 RDBMS 中的 MySQL,我们就可以画一个如下的决策树:

由于这里面的内容实在过多,无法一次性展现在这里。我举几个具体的例子给你说明一下。MySQL 中的索引统计信息有配置值,有状态值。我们要根据具体的结果来判断是否需要增加 key_buffer_size 值的大小。比如这种就无所谓了。
Buffer used 3.00k of 8.00M %Used: 0.0004
从上面的数据可以看到,key buffer size 就用到了 4%,显然不用增加。
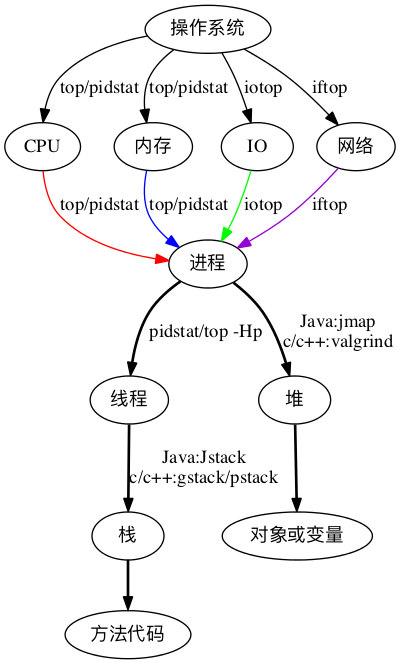
我们再来看一下操作系统分析决策树,我在这里需要强调一下,操作系统的分析决策树,不可以绕过。
9、场景的比对
因为我看到很多人对瓶颈的判断,并不那么精确,所以想写一下场景比对的建议。其实简单来说,就一句话:当你觉得系统中哪个环节不行的时候, 又没能力分析它,你可以直接做该环节的增加。举例来,我们现在有一个如下的架构:
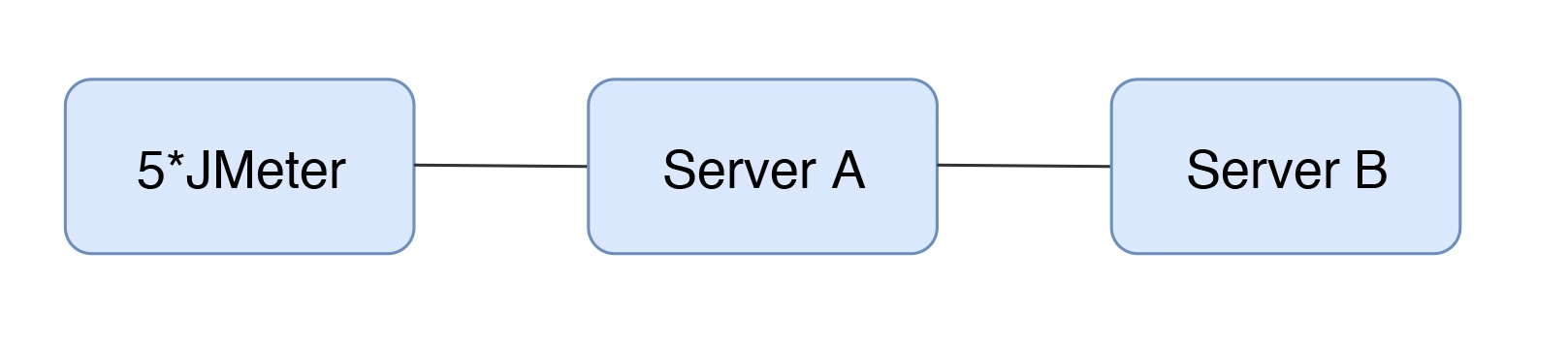
可以得到这样的结果:
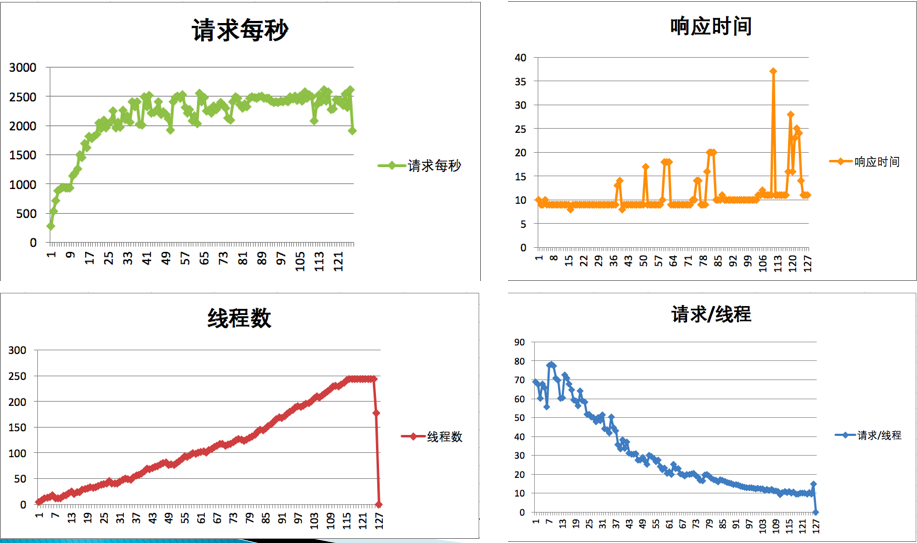
从 TPS 曲线中,我们可以明显看到系统是有瓶颈的,但是并不知道在哪里。鉴于系统架构如此简单,我们索性直接在某环节上加上一台服务器,变成这样:
然后得到如下数据:
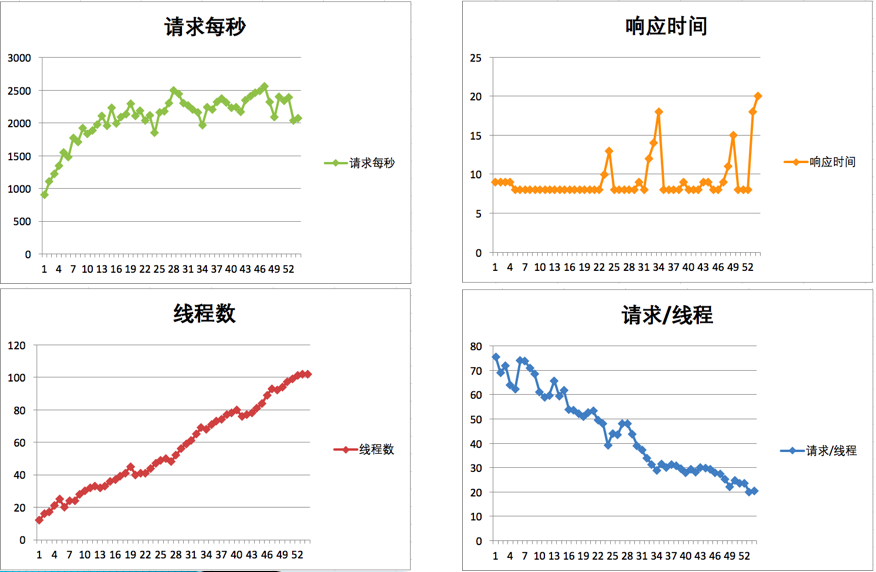
哟,没好使!怎么办?再接着加其他节点,我加了更多的 JMeter 机器。
再来看下结果:
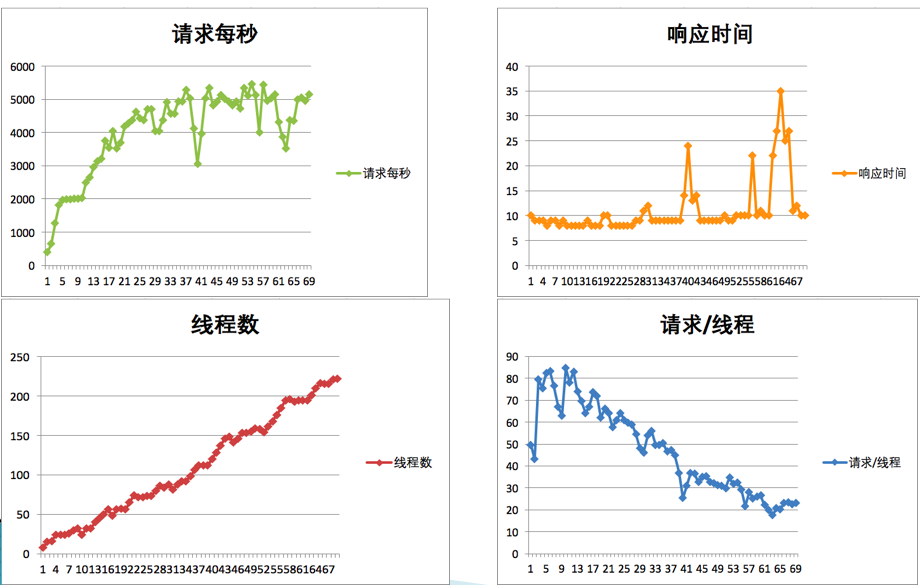
真巧,TPS 增加了!看到了吧,这就是我说的场景比对。当我们不知道系统中哪个环节存在性能瓶颈时,对架构并不复杂的系统来说,可以使用这样的手段,来做替换法,以快速定位问题。
10、性能测试工具及性能场景篇
一个性能测试工具来说,如果能实现以下几大功能,那么就基本上就满足了性能测试工具的功能。
1、录制或编写脚本功能
2、参数化功能
3、关联功能
4、场景功能
5、报告生成功能
性能工具中的录制功能:
录制功能从原理上来说,分成两种:本地录制:通过截取并解析与服务器的交互协议包,生成脚本文件。比如说 LoadRunner 调起 IE 的时候,不用修改 IE 的代理设置,就可以直接抓取 HTTP 包,并通过自己的解析器解析成脚本。代理录制:通过代理服务器设置,转发客户端和服务器的交互协议包,生成脚本文件。JMeter 中的脚本录制功能就是这样做的。
11、
12、
13、
14、
15、
16、
17、
18、
