zookeeper要点总结
简述:zookeeper分布式协调服务,节点数据存储在内存,高吞吐,低延时,zkserver cluster组建zookeeper service保证自身高可用
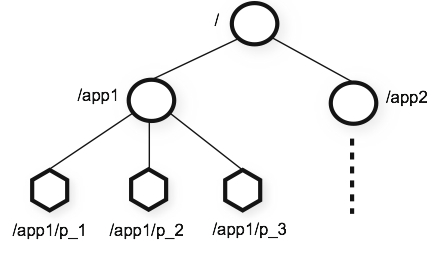
zookeeper数据模型为类文件目录树结构的文件系统,node节点可以存放1m数据(主要用于存储同步数据及节点元数据,注:数据存储在内存,log存储于磁盘)
角色组成:
- Leader:负责zxid维护,数据同步,与follower之间消息队列维护
- Follower:接受client请求,负责写请求转到leader数据的读取
- Observer:监控指定节点数据变化
数据模型:
zookeeper节点类型:
- 持久节点:(persistent):client默认创建的znode节点,都是持久节点
- 临时节点(Ephemeral Nodes):client与zookeeper保持连接时有效,断开znode节点消失。用于session,session结束节点删除,此节点不能有子节点
- 顺序节点(Sequence Nodes):可以是临时也可以是持久的。zookeeper维护一个计数器,保证在相同父节点下,节点的唯一性,注:计数器使用4bytes的int存储下一个节点序号
zookeeper特征/保证:
- 顺序一致性:按client发送过来顺序对数据进行更新
- 原子性:数据更新只有失败和成功两种状态,没有其它结果
- 相同的视图:client无论连接到哪个server,client都将看到相同的视图
- 可靠性:一旦数据更新,从更新的那个时刻一直延续到下一次覆盖更新
- 及时性:clint的视图保证在特定时间内,client看到的视图是最新的
zookeeper角色关联:
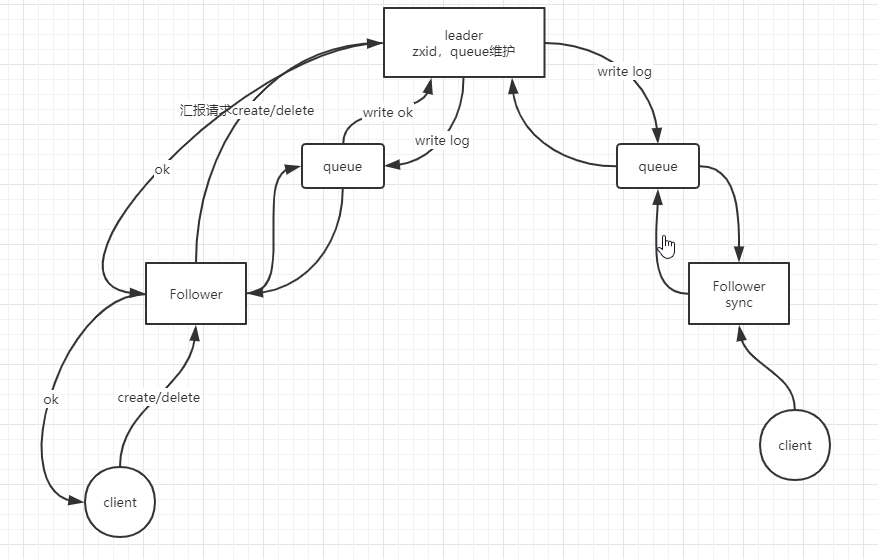
注:当leader挂掉,没有新的leader时则zookeeper拒绝对外服务
zookeeper会话(session):
client与server建立连接zookeeper会分配id,client在特定时间间隔内发送心跳到server保持session有效,如果指定时间未收到心跳,则认为client无效,session中创建的ephemeral节点会被删除
zookeeper监控(Watch):
client在读取特定的节点上设置watch,当此节点发生变化时,会向注册watch的client发送通知。注:这里指触发一次,如client想再次获取通知,则必须通过另一个读取操作来完成,client断开则watch也被删除
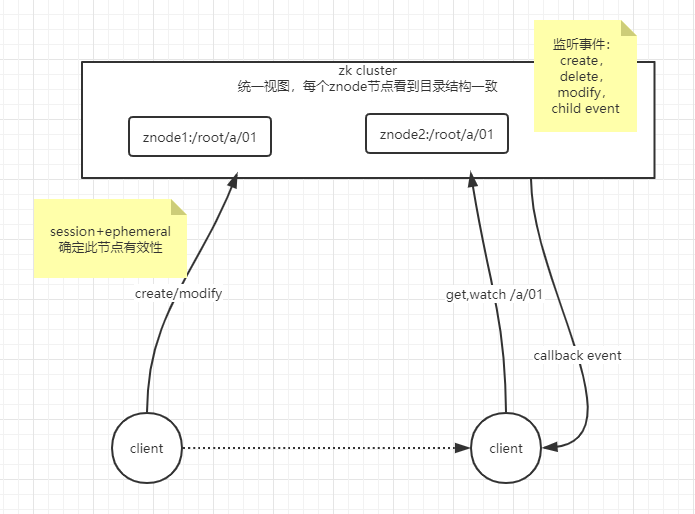
zookeeper应用:
1,HA,主的选举:
2,分布式锁:ephemeral特点
