Spark 要点总结及优化
Spark Components:
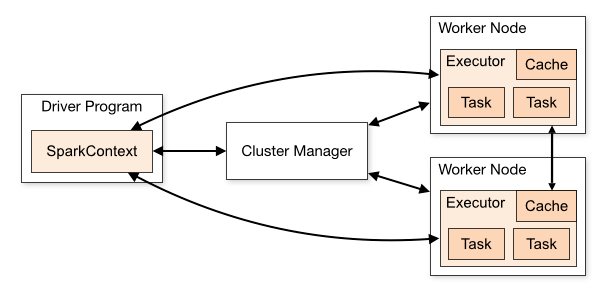
角色组成:
Driver : 由SparkContext创建,运行在main方法,负责资源申请与调度,程序分发,接收每个分区的计算结果
Cluster manager: 获取集群内资源(模式standalone ,Mesos, YARN)的外部服务
Worker node: 集群中能够运行计算程序的节点
Executor: work node上启动的一个进程,能够运行tasks,能在memory 或者 disk上存储数据,每个application都有自己的Executors
Task: 发送给executor的一个执行单元(task是以thread形式执行)
Job: actions生成的多个任务组成的并行计算,每个action对应一个job
Statge: 每个job划分为阶段性的小型任务集合(一个节点上顺序完成的一次计算)
架构说明:
1, 每个application都有自己的Executor进程,每个Executor可以多线程执行任务,存在整个application生命周期内,多个application之间互相独立(每个app对应一个jvm实例),多个spark application之间只能通过将数据写入外存储才能进行数据共享
2,spark计算层与集群管理模式无关,只要获取到Executor,并且Executor之间能够互相通信,它就能在集群中运行
3,driver负责监听接收Executor上的计算结果,driver必须确保其它Worker能够通过网络地址寻找到Executor,driver负责管理集群上的task分发,把task运行在较近的worker nodes上,如果执行task在远端的集群上,他会通过RPC方式提交operations到较近的节点运行task
Spark是以MapReduce为基础在其上进行功能扩展的集群计算框架,spark计算面向是RDD(resilient distributed dataset)数据源
RDD是编程抽象概念,代表可以跨机器进行分割的只读的数据集合,所有对数据操作都需通过RDD来处理。
RDD操作:
create:通过hfile 或 scala collection作为数据源
transformation:处理计算转换,map,flatmap,filter
controler:对中间结果可存储在memory 或file供其它RDD数据复用
actions:驱动RDD执行计算
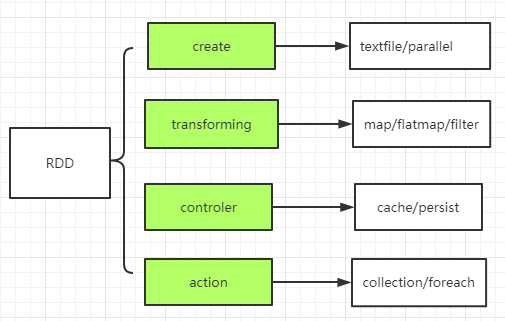
Spark程序是一个惰性计算,通过action调用来驱动程序运行,代码被分发到集群上,由各个RDD分区上的worker来执行,然后结果会被发送回Driver进行聚合处理。
驱动程序创建一个或多个RDD,调用transform来转换RDD,然后调用reduce处理被转换后的RDD。在程序处理数据过程中使用的是pipleLine方式。
WordCount执行流程:
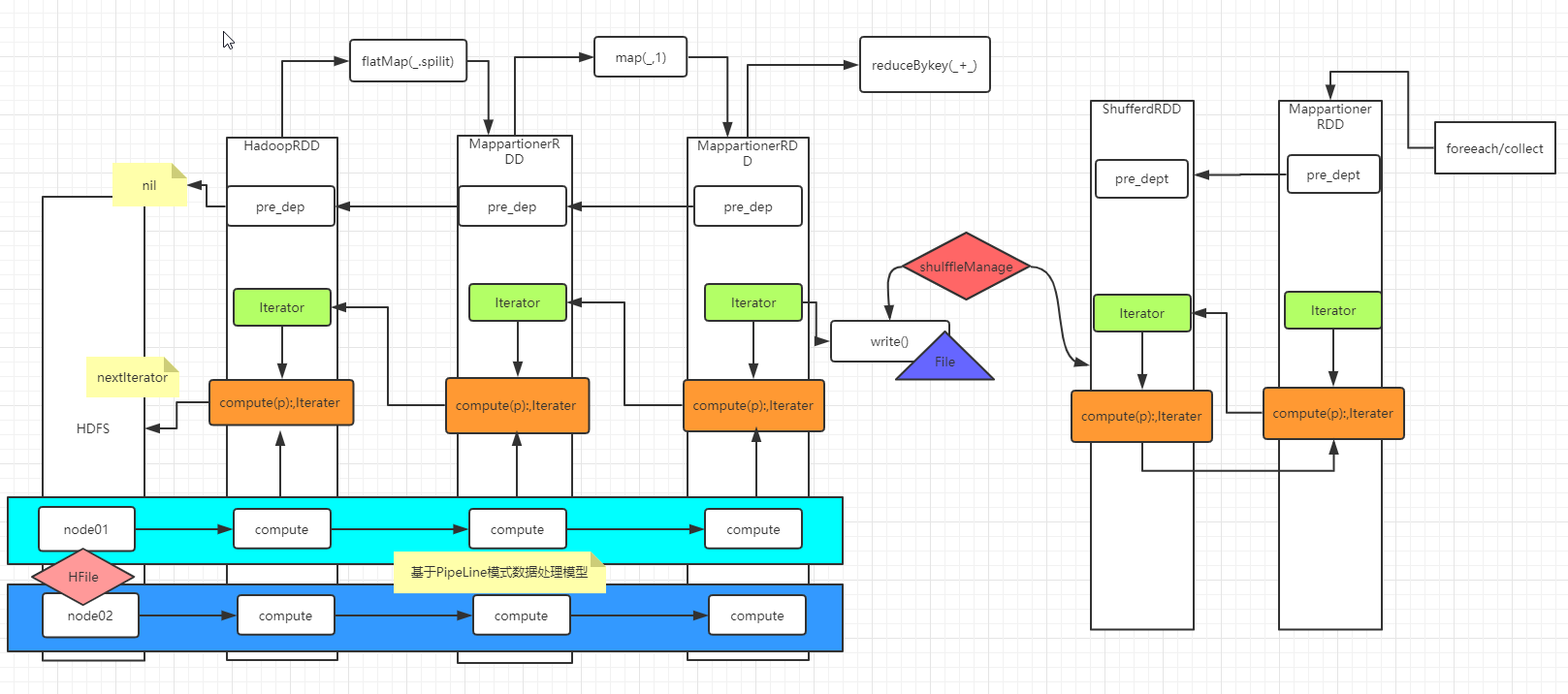
spark集群及逻辑划分:
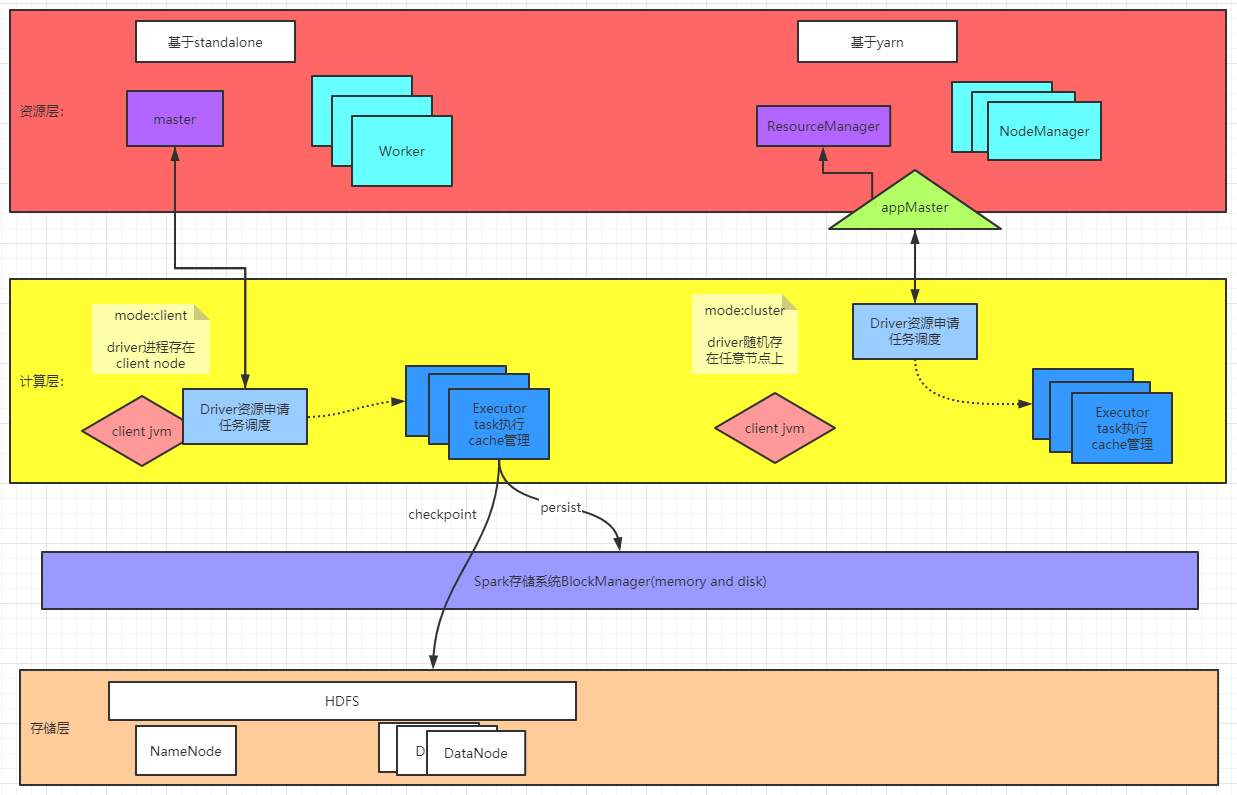
任务分发及调度:
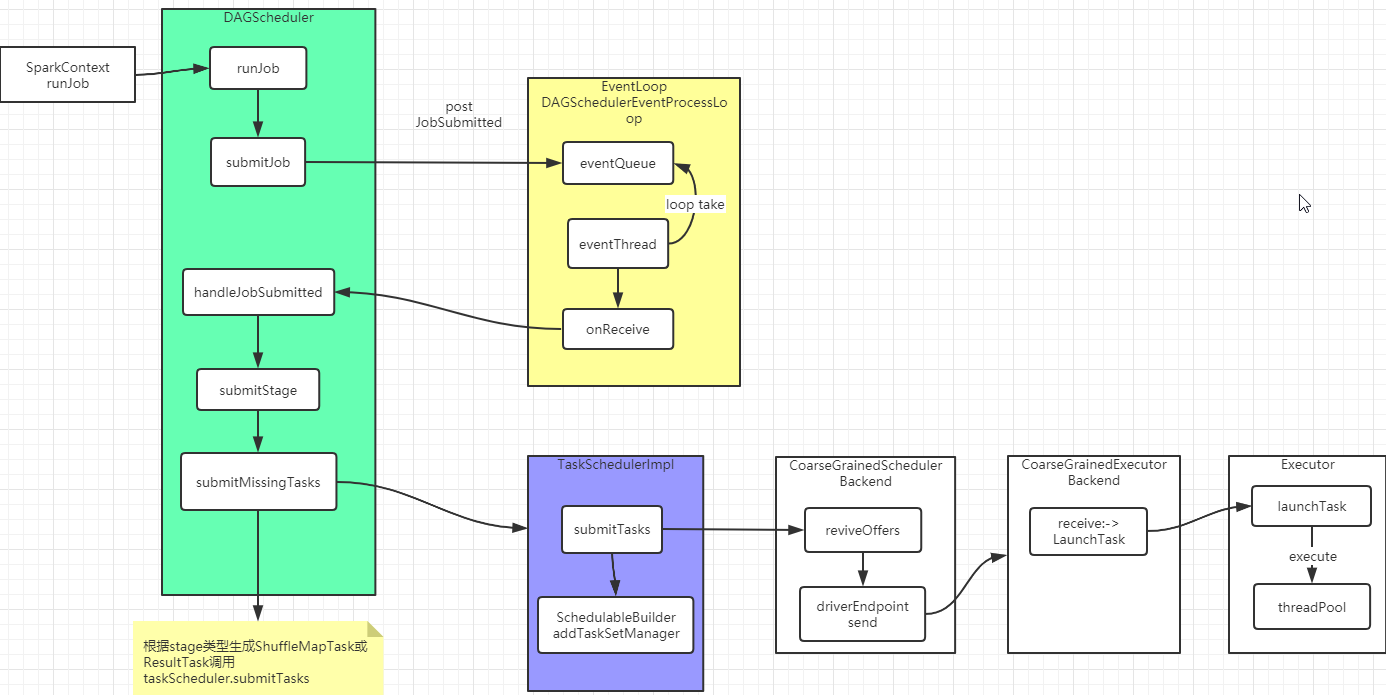
Spark 存储管理:
BlockManager管理内存,磁盘,堆外内存。其中主要内存使用分为execution和storage。execution主要在shuffles, joins, sorts 和 aggregations时使用,storage用于cache,集群中间数据传递。execution与storage内存可共享使用,没有execution任务,storage可以使用全部内存,当execution需要内存时,剔除storage到一定比例阈值空间。当有计算使用内存时,storage不可挤占execution的内存。
数据缓存分类:
persist:发生pipeline处理时内部存储
checkpoint: 外存储点,存储执行会在下一个action算子执行后开始执行(即滞后执行)且会重复执行,需要结合persist使用
broadcast:发生在driver,获取得到blockmanager ID,传到executor,执行时如没有数据则从blockmanager获取处理,下一次可直接使用
内存划分:300M空间系统预留,40%空间存储数据结构,spark元数据,应对不正常大对象产生的oom预留位,60%空间用于execution和storage
BlockManager组成结构:
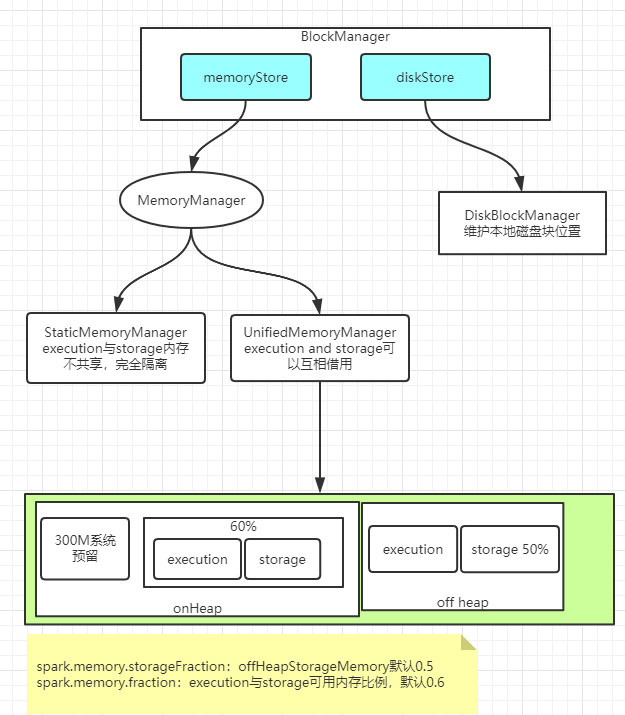
spark RDD之间 Dependence类别:
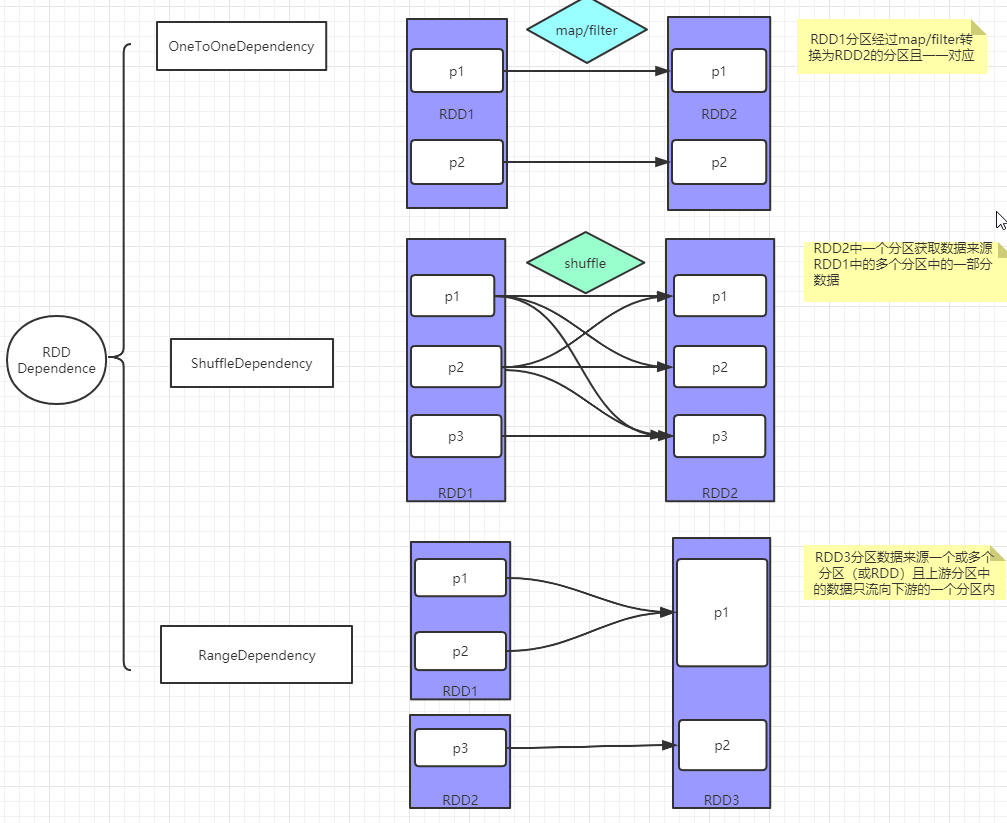
spark shuffle组成:
Spark优化:
1,相同的数据使用一个RDD:避免多次计算相同数据的RDD
2,多次使用的RDD计算结果持久化:当一个RDD相同的算子执行多次时,为避免重复计算需要将计算结果进行缓存/持久化,加快下一次的计算
持久化级别:
MEMORY_ONLY(对象内存存储)
MEMORY_AND_DISK(内存不够时写一部分到磁盘)
MEMORY_ONLY_SER(序列化为字节数组存储在内存,相比memory_only对象存储更省空间,多出来的性能开销是序列化与反序列化的开销)
MEMORY_AND_DISK_SER(序列化存储内存磁盘)
DISK_ONLY(仅磁盘)
策略选择:
(1)数据量较少优选MEMORY_ONLY,如果使用MEMORY_ONLY级别时发生了内存溢出,建议尝试使用MEMORY_ONLY_SER级别,此时每个partition是一个字节数组,降低了内存占用,如果RDD中数据量过多还是可能导致OOM
(2)如果内存级别都无法使用,那么建议使用MEMORY_AND_DISK_SER,而不是MEMORY_AND_DISK。到了这一步说明RDD的数据量很大,内存无法完全放下,序列化后的数据比较少,可以节省内存和磁盘的空间开销。
同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。不建议使用DISK_ONLY和后缀为_2的级别,因为完全基于磁盘文件的数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。
(3)后缀为_2的级别所有数据都复制一份副本,并发送到其它节点上,数据复制及网络传输会导致较大的性能开销
3,尽量减少shuffle计算:shuffle最耗性能,shuffle不同节点上相同的key拉取到一台机器进行聚合操作,涉及到磁盘IO和网络传输,byKey、join,distinct、repartition等算子会触发shuffle操作
尽量使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子在本地进行combiner较少拉取的数据量,而groupByKey算子是不会进行聚合全量数据会在集群的各个节点之间分发和传输,性能较差。
4,算子优化:
mapPartitions替代map:partition数据量不是很大时效率较高。一次调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些,但如果内存不够可能出现OOM异常
foreachPartitions替代foreach:类似mapPartitions替代map 如将RDD中所有数据写MySQL等外存储时避免foreach频繁地创建和销毁数据库连接,每个partition使用一个connection,提高性能
repartitionAndSortWithinPartitions替代repartition与sort:可以一边进行重分区的shuffle操作,一边进行排序,shuffle与sort两个操作同时进行
mapValues/flatmapValues:当分区器,分区数没有变化,key没有变化,只对value进行转化可使用 mapValues->map 和 flatmapValues->flatmap 来避免产生不必要的shuffle操作
//例wordcount 对统计的value进行转换且进行分组
val words: RDD[String] = data.flatMap(_.split(" "))
val kv: RDD[(String, Int)] = words.map((_,1))
val res: RDD[(String, Int)] = kv.reduceByKey(_+_)
// val res01: RDD[(String, Int)] = res.map(x=>(x._1,x._2*10))
val res01: RDD[(String, Int)] = res.mapValues(x=>x*10)
val res02: RDD[(String, Iterable[Int])] = res01.groupByKey()
res02.foreach(println)
broadcast外部变量:在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本,如果变量本身比较大,task比较多,会占用过多内存和传输性能问题
广播后的变量会保证每个Executor内存中只有一份变量副本,同一个EXcutor内的task共享一个节省内存
5,数据结构优化:
1)减少java包装类的使用(object header 16byte)尽量使用基础类型替代
2)使用array+ primitive types替换HashMap,List
3)避免使用过多的小对象嵌套结构
4)使用数值或枚举类型替换string作为key(string编码及长度等占用)
5)内存小于32 GB 调整JVM flag -XX:+UseCompressedOops,使pointers 由8byte到4byte
6,数据本地化:
1)PROCESS_LOCAL,待处理的数据在相同的jvm实例内运行,这是最佳级别
2)NODE_LOCAL,数据在一个节点(例如在同一个HDFS节点或者同一个节点的另一个Excutor上)
3)NO_PREF,没有位置偏好,从任何地方访问一样快(Redis,mysql,HBase)
4)RACK_LOCAL,同一机架上的节点
5)ANY,数据不在同一个机架,在网络任意节点
当task在等待executor执行超时时,有任何空闲executor上没有未处理数据的情况下,Spark 会切换到较低的local level执行task。
两种执行策略:a), 等待,直到繁忙的 CPU 释放后,再次在这节点上启动task。 b) 立即在需要将数据传输到远端节点上启动新的task执行。
Spark 通常是等待一段时间等待 CPU 释放,超时过期后它开始将数据从远处移动到空闲CPU的节点上执行。每个级别之间的等待超时时间可以单独配置,也可以一起配置在一个参数spark.locality
相关参数:
spark.locality.wait //本地进程内超时等待时间
spark.locality.wait.node//本机超时等待时间
spark.locality.wait.rack//同一机架超时等待时间
spark.locality.wait.process//本地无引用的外部
其它参数调优
num-executors:作业总共要用多少个Executor进程。如果不设置的话,默认只会给你启动少量的Executor进程,此时Spark作业运行速度是非常慢,一般设置50~100个左右 太少无法充分利用资源,太多无法给予充分的资源
executor-memory:每个Executor进程的内存。内存设置4G~8G较为合适,num-executors乘以executor-memory不能超过队列的最大内存
executor-cores:每个Executor进程的CPU core数量。设置为2~4个较为合适
driver-memory:Driver进程的内存。如果使用collect算子将RDD的计算结果数据全部拉取到Driver上处理,那么必须确保Driver的内存足够大
spark.default.parallelism:设置每个stage的默认task数量,Spark默认设置的数量是偏少,不会使用足够的资源。如果task数量偏少的话,就会导致前面设置好的Executor的参数白费,无论有多少资源,只有1,2个task导致资源浪费,
官网推荐设置原则是每个core2-3个task,总的为num-executors * executor-cores的2~3倍较为合适
spark.storage.memoryFraction:RDD持久化数据在Executor内存中能占的比例,默认是0.5。有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。如发现作业由于频繁的gc导致运行缓慢,
task执行用户代码的内存不够用,建议调低。作业中的shuffle操作比较多,而持久化操作比较少,建议调低
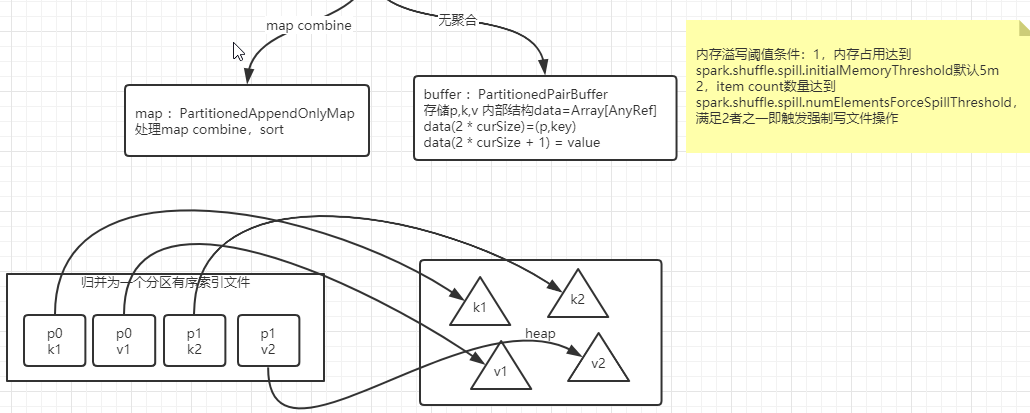
spark.shuffle.file.bufferbuffer 文件溢写缓冲大小,默认32k
spark.shuffle.memoryFraction shuffle使用executor内存占比,默认0.2
spark.reducer.maxSizeInFlight shuffle read buffer 一次数据拉取量,默认48m
spark.shuffle.spill.numElementsForceSpillThreshold 强制文件溢写数据的条目数阈值,默认integer最大值
spark.shuffle.spill.initialMemoryThreshold 强制文件溢写数据量内存占用多少空间,默认5m
数据倾斜问题:
发现问题:
1,sample countByKey() wc查看结果。
2,在Spark Web UI查看一下当前这个stage各个task分配的数据量,执行时长
解决方案:
1,双重聚合:rdd进行key值随机前缀N 先进行一步combiner,然后去掉前缀再次combiner
2,向上采样:对rdd内数据随机key前缀,较少数据的rdd内相同的key进行N(excutor core task)倍的扩容在进行join处理
3,broadcast处理:如果有较少的数据量rdd与较大的rdd进行join则小的rdd进行broadcast后数据量多的rdd进行map join
4,过滤异常数据,如某些无用冗余数据量较大,则先过滤处理
5,提高并行度(缓解作用并未根本解决)RDD多分区,通过算子指定并行度,例如,reduceByKey(_+_,10),配置spark.default.parallelism
推测计划问题:
当spark task中0.75已执行完成,剩余task执行时间达到已完成task中位数的1.5倍,则spark会重新调度一个新的task执行此task未完成的任务。(spark默认关闭,map reduce有开启)
导致问题:1,导致计算结果数据重复 2,如有数据倾斜发生会使task无法执行完
相关参数配置:
spark.speculation//计划是否开启,默认false
spark.speculation.interval//检测间隔 100ms
spark.speculation.multiplier//执行缓慢时间界定,是多少倍的已执行完task中位数 1.5
spark.speculation.quantile//所有已完成task中占总数的比例 0.75

