
TiDB是一个开源的分布式NewSQL数据库,设计的目标是满足100%的OLTP和80%的OLAP,支持SQL、水平弹性扩展、分布式事务、跨数据中心数据强一致性保证、故障自恢复的高可用、海量数据高并发实时写入与实时查询
1. 整体架构
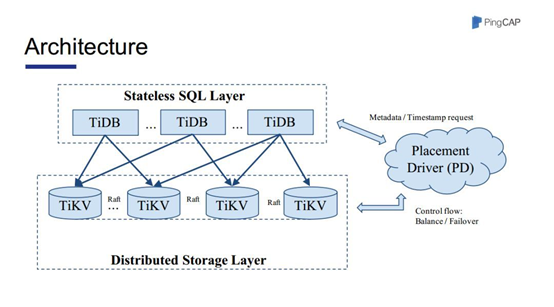
TiDB分层架构如上图,由TiDB节点、TiKV节点、PD节点组成。
TiDB节点 SQL解析执行节点。Go语言开发。完全兼容Mysql协议。
职责是,负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过PD找到存储计算所需数据的TiKV 节点地址,与TiKV交互获取数据,最终返回结果。
TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展。
TiKV节点 分布式KV存储引擎,底层单机存储引擎是RocksDB, 基于Raft一致性协议的数据复制由Rust语言实现。
PD节点 元数据管理,Key Range与TiKV node映射关系。
2.TiDB
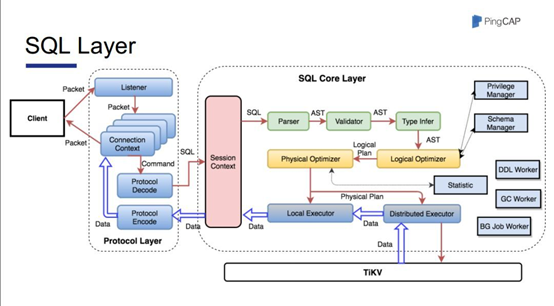
SQL计算节点,负责SQL的解析、优化、执行、结果集归并计算等功能。
3. TiKV
TiKV 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。可以将 TiKV看做一个巨大的 Map,其中 Key 和 Value 都是原始的 Byte 数组,在这个 Map 中,Key 按照 Byte 数组总的原始二进制比特位比较顺序排列。
存储数据的基本单位是 Region,首先是Region的概念,它是指一段连续key的key-value对的集合。所有的数据都是以Region为一个基本单位来组织调度的。
每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。
数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度,现在一个Region的大小是96MB,当Region快要填满时,Region会发生分裂,整个分裂的过程都是由PD来调度,完全不需要人为干预。
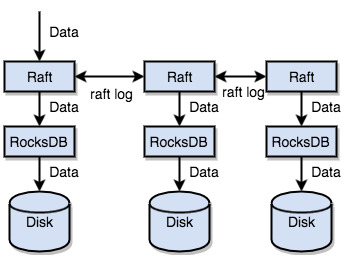
Region是分层的。最底层的是RocksDB,这一层负责键值对的存储。 之上是Raft Group,不同节点上的多个Region 构成一个 Raft Group,互为副本。每一个Region都是通过Raft协议来保证数据的一致性的。

整个Key-Value空间分成很多段,每一段是一系列连续的key,每一段叫做一个Region, TiKV是以Region为单位做数据的复制,一个Region在一个节点上只会有一份,但会有多个副本在其它节点上,一般情况下数据会保存在3个节点。
Raft Group内数据的复制是由Raft协议来做的,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到Raft Group的多数节点中。
4. PD
PD主要负责元数据的管理。PD的主要作用:
1、路由功能,通过PD可以获取每一段范围key的数据具体Tikv节点;任意一个 Key 就能查询到这个 Key 在哪个Region 中,以及这个Region目前在哪个Tikv节点上
2、全局时间戳功能,相当于全局事务ID,TIDB的分布式事务就是基于乐观锁的版本校验机制来实现的。这个功能还是非常重要的。
5. 总结一些思考
- TiDB 负责SQL的解析、优化、执行、结果集归并,是否可以采用Mysql分库分表中间件的形式,用java开发
- 不同节点上的三个 Region 构成一个 Raft Group,组间的数据复制算法Raft协议来做,读和写都在leader上,是否可以采用类似Zookeeper的paxos算法来做读写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号