3D检测---VoxelNet
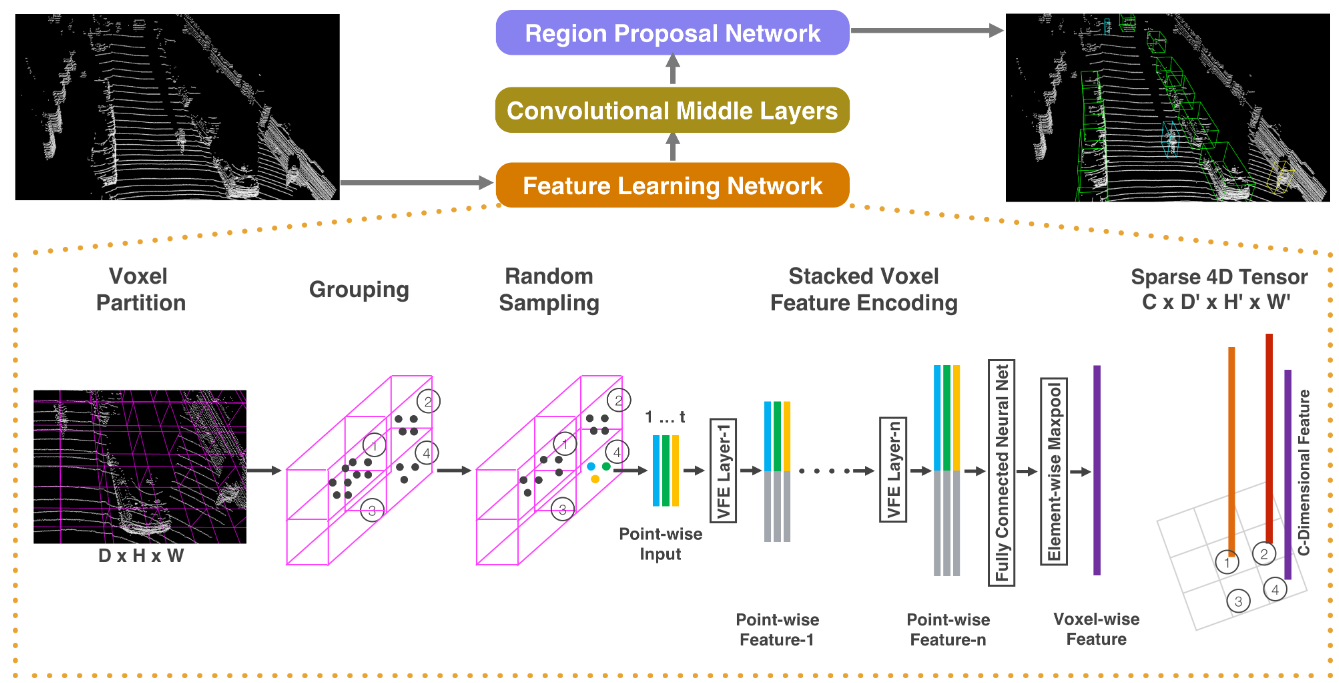
网络流程
Voxel Partition
| 3D点云在Z, Y, X的范围 | $$(D, H, W)$$ |
|---|---|
| voxel大小 | $$(v_D, v_H, v_W)$$ |
| 3D voxel grid的大小(个数) | $$(D'=D/v_D, H'=H/v_H, W'=W/v_W)$$ |
Grouping
将点云划分给它所在的voxel
Random Sampling
对于点云数量多余T的voxel,随机采样T个,作用是:
- 节省计算量
-
decreases the imbalance of points between the voxelswhich reduces the sampling bias, and adds more variationto training
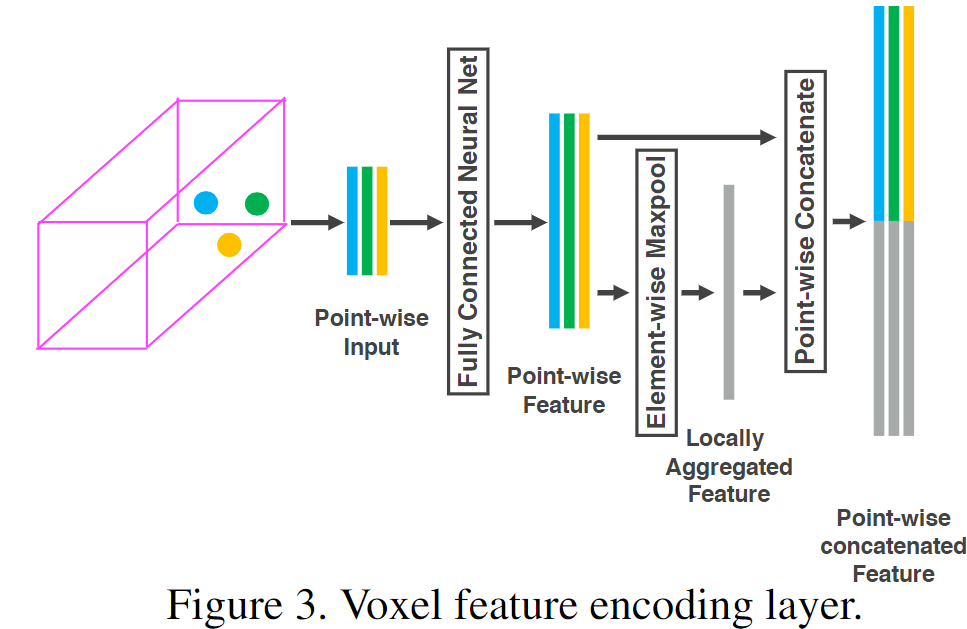
Stacked Voxel Encoding
类似PointNet的语义分割部分,最终得到的每个点的concate输出既包含了point-wise特征,也包含了局部聚合特征(maxpool),使得对这个voxel的编码能够学习具备描述性的形状信息。
Sparse Tensor Representation
通过多个VFE Layer层的处理,最终每个Voxel都被提取抽象成一个1维的特征向量,点云最终输出的是一个4D Tensor:(C, D', H', W')
即使点云团有超过 ~100k个点,但是通常90%的voxel都是空的,因此最终得到的4D Tensor是稀疏的。
Convolutional Middle Layers
2D卷积:卷积目标是图像,(H, W),每个位置有C个通道,一个卷积核大小为(h, w),每个位置也有C个通道,一个卷积核得到的结果是(H', W', 1)
3D卷积:卷积目标是体积,(D, H, W),每个位置有C个通道,一个卷积和大小为(d, h, w),每个位置也有C个通道,一个卷积核的结果是(D', H', W', 1),多一个卷积核则每个位置通道数多1
对于车辆检测,在D方向两次S=2,其他方向不变。
# input tensor:(128, 10, 400, 352)
# Conv3D(cin, cout, k, s, p)
Conv3D(128, 64, 3, (2,1,1), (1,1,1))
Conv3D(64, 64, 3, (1,1,1), (0,1,1))
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
# output tensor: (64, 2, 400, 352)
reShape:(128, 400, 352)
RPN
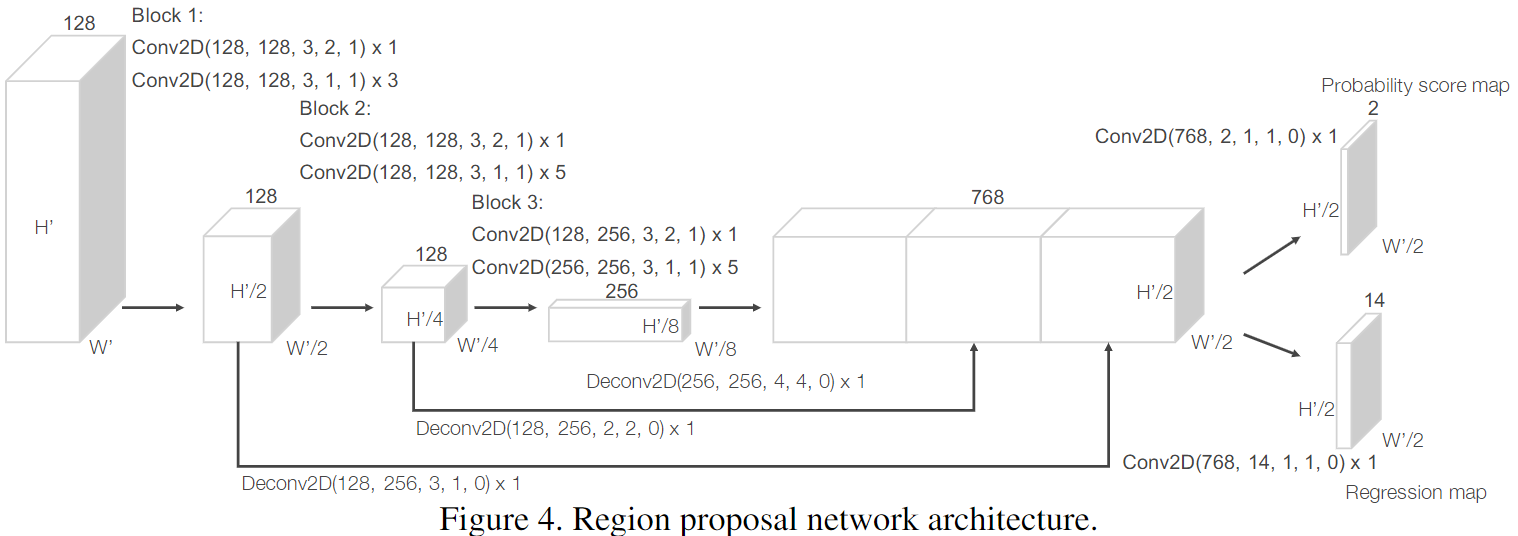
训练
正负样本匹配
- 正样本anchor:
- 与一个GT具有最大的IoU
- 与GT的IoU大于0.6
- 负样本anchor:与GT的IoU小于0.45
- 忽略样本: 与GT的0.45 < IoU < 0.6
