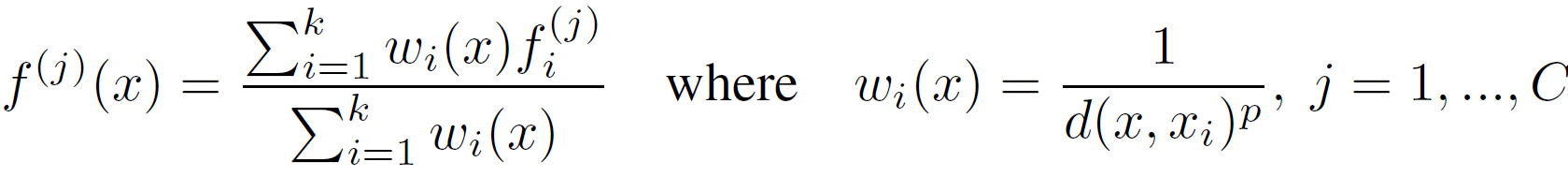3D检测---PointNet
点云数据
点云数据具有如下特性:
- 无序性
点云数据是一个集合,对数据的顺序是不敏感的。这就意味这处理点云数据的模型需要对数据的不同排列保持不变性。 - 不变性
点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。
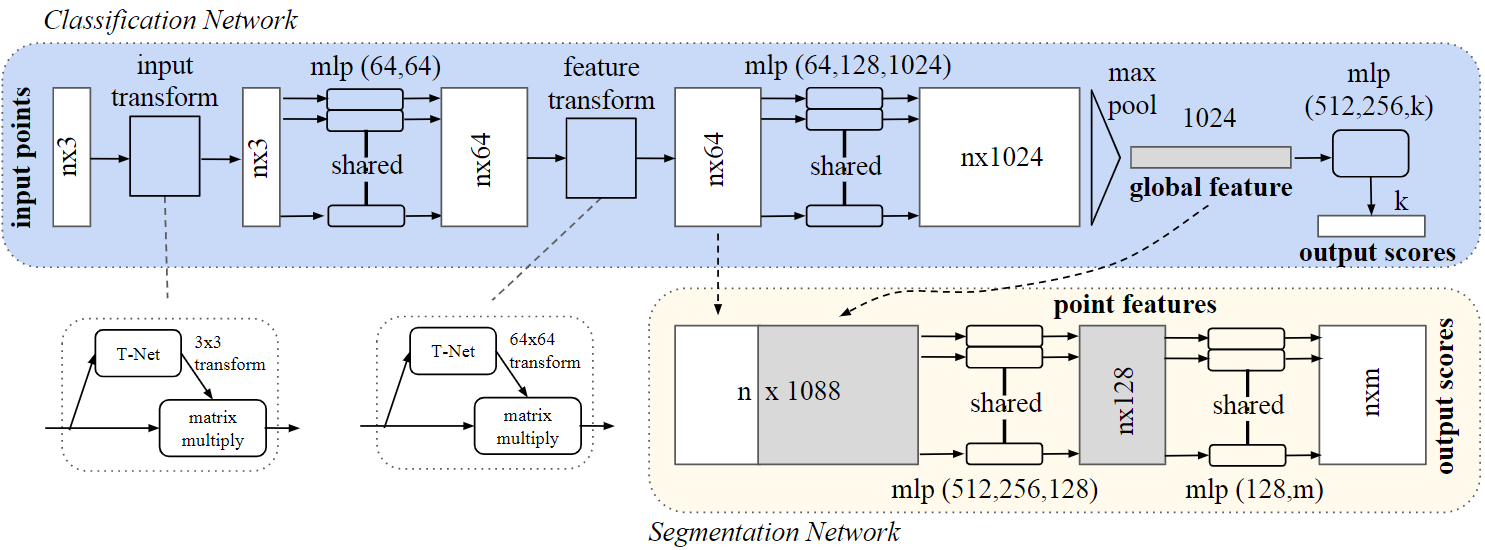
PointNet
网络结构
其中的两个旋转矩阵是通过神经网络输出[3 x 3]个数字。约束其属于正交矩阵。
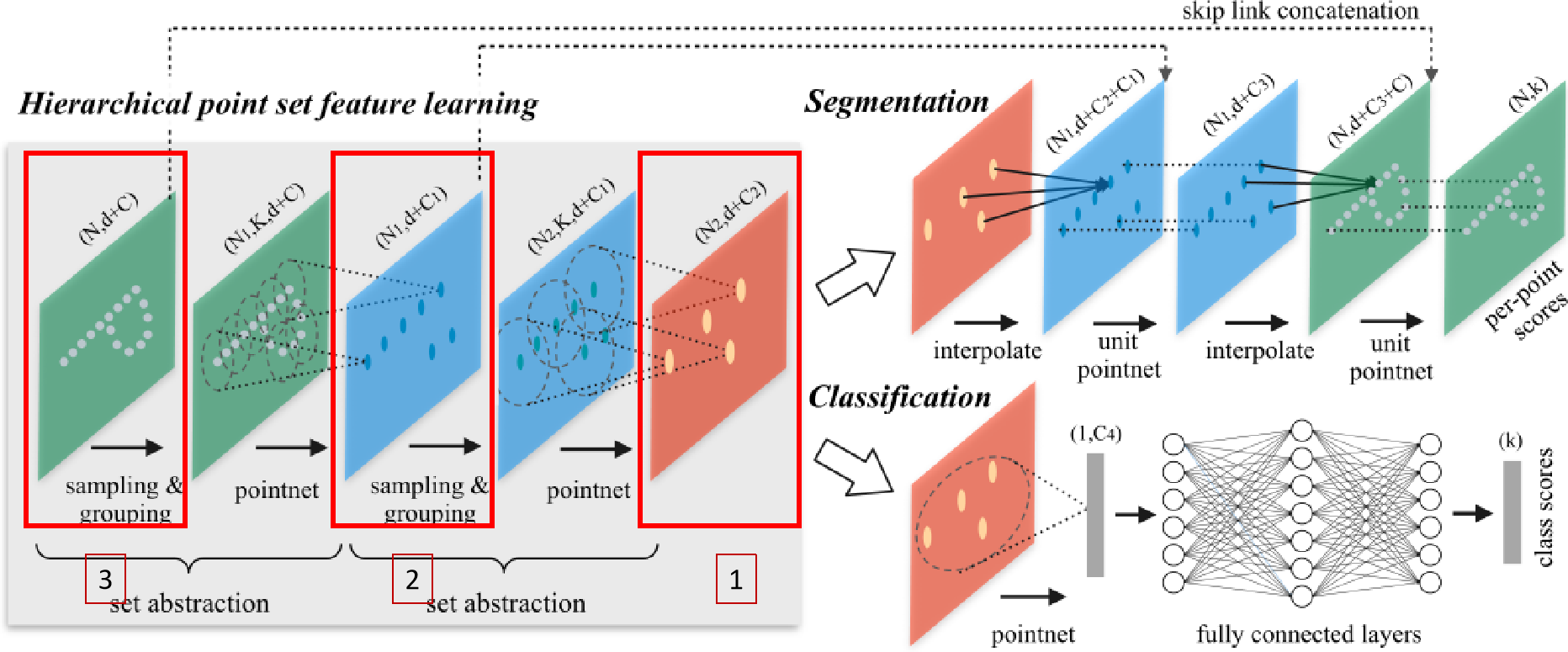
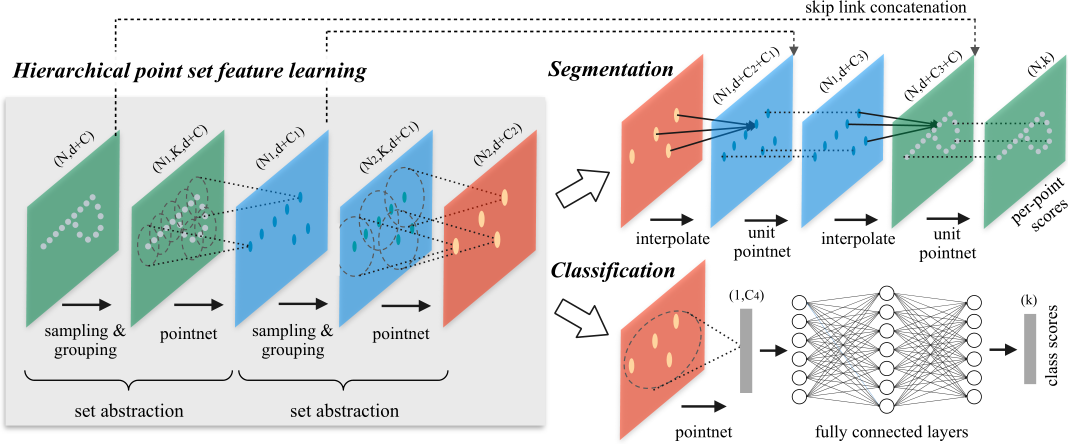
PointNet++
PintNet在对点进行特征提取时,只考虑了单一点的特征而没有考虑局部特征。
该方法的提出解决了 4 个问题:
- 一个点云图往往有非常多的点,这会造成计算量过大而限制模型使用,如何解决?
- 如何将点集划分为不同的区域,并获取不同区域的局部特征?
- 在密集数据上学习到的特征不能泛化到稀疏采样区域上,导致在稀疏点云上训练的模型不能识别细粒度的局部结构
- 连续的Set Abstraction(SA)层对原始点进行下采样而获得数量更少的特征点,如何从这些特征点中实现原始点云数据的分割任务呢?
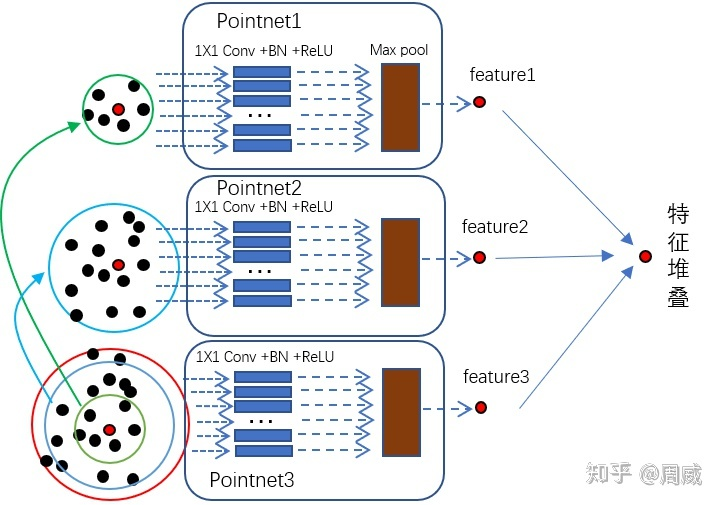
网络的主要结构是Sampling + Grouping + PointNet。需要注意的是,Sampling和Grouping只是将点进行了区域划分,并没有减少点的数量,PointNet进行特征聚合(maxpooling)时,减少了点的数量。(层次点特征学习部分同颜色的图中点云的特征一样,只是重新排列:(N, d+c)-->(N', K, d+C))(可能存在过滤和填充!)
Sampling layer
通过最远点采样算法,将原始输入点云:N x (3 + C)采样为:N' x (3 + C),其中C为反射强度等其他点云属性数量。
最远点采样算法(FPS)
- 输入点云包含N个点,从点云中选取P0作为起始点,得到采样点集合S=
- 计算所有N个点到采样点集合的距离,得到L[N],从L中选择最大值对应的点P1(距离采样点集合最远的点),加入采样点集合S=
- 重新计算N个点到P1的距离,如果某个点 i 到P1的距离小于L[i],则更新L[i] = d(Pi, P1),因此,数组L中存储的一直是每一个点到采样点集合S的最近距离;
- 从L中选择最大值对应的点P2(距离采样点集合最远的点),加入采样点集合S=
- 重复3-4步,一直到采样到目标数量的采样点为止。
点击查看代码
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1]
return centroids
Grouping layer
对采样得到的点进行Ball Query,得到点云特征N' x K x (3 + C)
Ball Quary:
- 预测搜索区域半径
R和子区域内点数K - 以FPS采样得到的
N'个点作为中心,搜索每个中心以半径为R内的区域,将区域内的点按照距离中心的距离排序,选取前K个,不够则对某个点重采样 - 获得
N'个子区域,每个子区域内包含K个点
Multi-scale grouping(MSG)
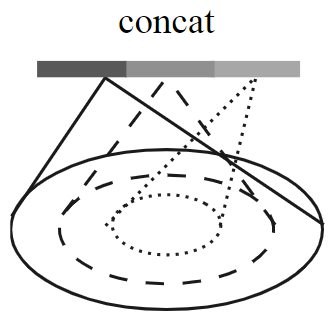
在同一层次上对一个点的不同半径内的点运用PointNet进行特征提取后拼接
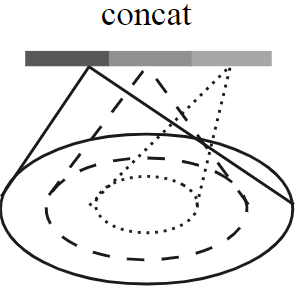
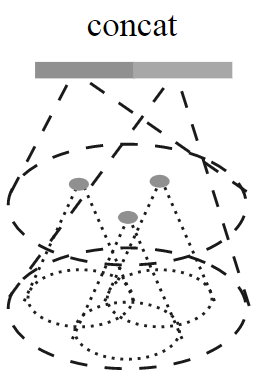
Multi-resolution grouping(MRG)
考虑到MSG计算量太大,可改为在不同层次上特征提取后拼接
Feature Propagation
- 从2中找到在1中消失的点{p1, p2, p3,...}依次进行:
- 在1中选取k个p1的近邻点(特征为
(N2, d+C2)),以距离为权重进行插值特征叠加,再将2图特征叠加上去,经过unit point(类似1 x 1CNN)进行特征提取