2022年最新大众点评的字体反爬,落地技术也是绝了,Python实现
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 621 篇原创博客
从订购之日起,案例5年内保证更新
⛳️ 大众 实战场景 点评
本次要用来学习的站点也是比较大众的站点,这个站点中碰到了【套娃】字体加密。
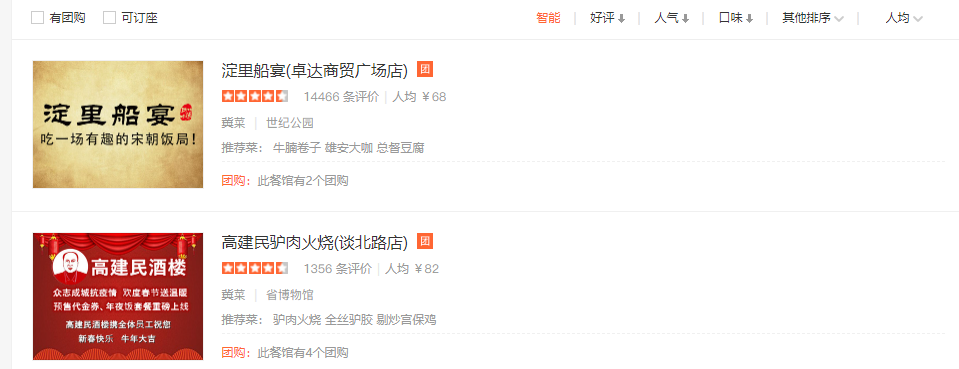
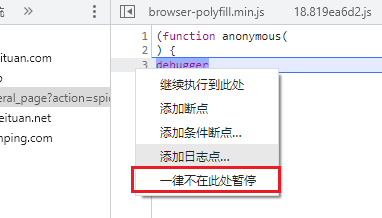
打开开发者工具刷新站点,可以得到如下字体文件请求,打开开发者工具碰到无限 debugger,取消掉即可。
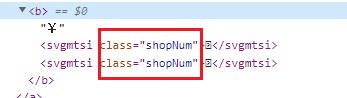
文字所在标签添加的样式如下所示。
然后顺着这个思路进行下去,得到了4层字体套娃。
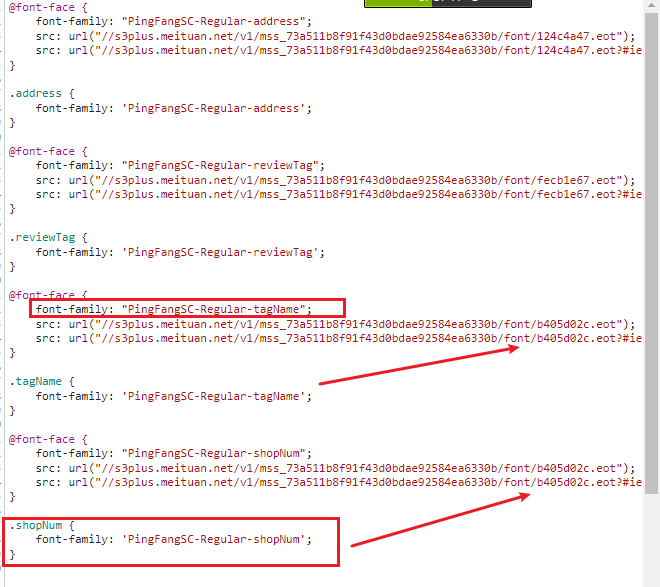
而该CSS文件,在页面中竟然每次刷新也发生变化。

⛳️ 大众 实战场景 点评
编写页面获取代码,得到【图文混排CSS】文件。
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
"HOST": "www.dianping.com"
}
res = requests.get('http://www.dianping.com/shijiazhuang/ch10',headers=headers)
tree = etree.HTML(res.text)
print(tree.xpath('//link/@href')[8])
得到 CSS 文件之后,在截取其中的字体文件。
这里不在过多解析,查阅一下字体文件每次刷新,是否发生编码变化。
第一次获取的字体文件,随意选择一份
多次测试之后,发现CSS文件和字体文件并未切换名称和修改顺序。
获取字体文件编码,与浏览器字符对应关系
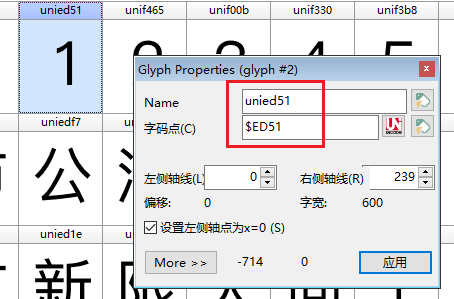
检索源码得到如下内容:
:对应 7;:对应 5。
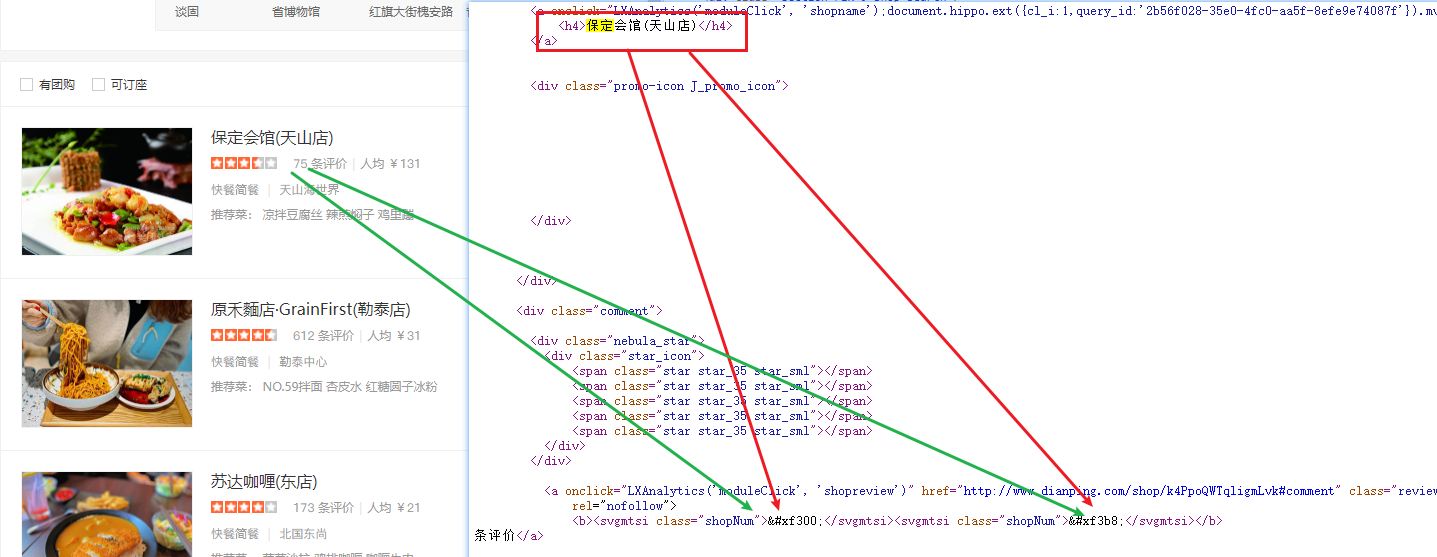
再次回到字体文件中找到7和5对应的编码。

本案例结束~ 🤪🤪🤪🤪
📣📣📣📣📣📣
右下角有个大拇指,点赞的漂亮加倍
欢迎大家订阅专栏:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号