

腾讯研发类笔试面试试题(C++方向)(转)
原文转自 https://www.cnblogs.com/freebird92/p/9595244.html
1、C和C++的特点与区别?
答:(1)C语言特点:
1.作为一种面向过程的结构化语言,易于调试和维护;
2.表现能力和处理能力极强,可以直接访问内存的物理地址;
3.C语言实现了对硬件的编程操作,也适合于应用软件的开发;
4.C语言还具有效率高,可移植性强等特点。
(2)C++语言特点:
1.在C语言的基础上进行扩充和完善,使C++兼容了C语言的面向过程特点,又成为了一种面向对象的程序设计语言;
2.可以使用抽象数据类型进行基于对象的编程;
3.可以使用多继承、多态进行面向对象的编程;
4.可以担负起以模版为特征的泛型化编程。
C++与C语言的本质差别:在于C++是面向对象的,而C语言是面向过程的。或者说C++是在C语言的基础上增加了面向对象程序设
计的新内容,是对C语言的一次更重要的改革,使得C++成为软件开发的重要工具。
2、C++的多态
答:C++的多态性用一句话概括:在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来
调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
1):用virtual关键字申明的函数叫做虚函数,虚函数肯定是类的成员函数;
2):存在虚函数的类都有一个一维的虚函数表叫做虚表,类的对象有一个指向虚表开始的虚指针。虚表是和类对应的,虚表指针是
和对象对应的;
3):多态性是一个接口多种实现,是面向对象的核心,分为类的多态性和函数的多态性。;
4):多态用虚函数来实现,结合动态绑定.;
5):纯虚函数是虚函数再加上 = 0;
6):抽象类是指包括至少一个纯虚函数的类;
纯虚函数:virtual void fun()=0;即抽象类,必须在子类实现这个函数,即先有名称,没有内容,在派生类实现内容。
3、虚函数实现
答:简单地说,每一个含有虚函数(无论是其本身的,还是继承而来的)的类都至少有一个与之对应的虚函数表,其中存放着该类
所有的虚函数对应的函数指针。例:
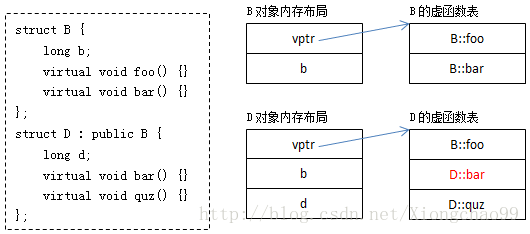
其中:
B的虚函数表中存放着B::foo和B::bar两个函数指针。
D的虚函数表中存放的既有继承自B的虚函数B::foo,又有重写(override)了基类虚函数B::bar的D::bar,还有新增的虚函数D::quz。
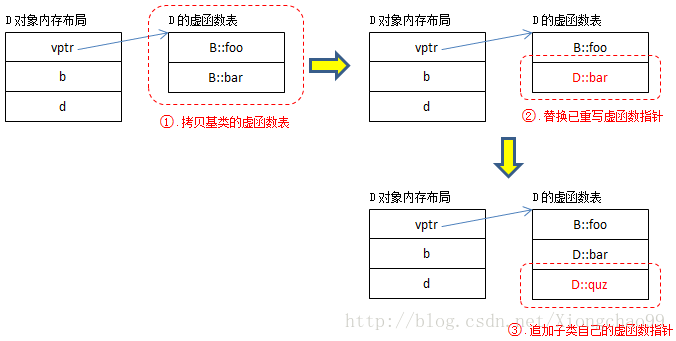
虚函数表构造过程:
从编译器的角度来说,B的虚函数表很好构造,D的虚函数表构造过程相对复杂。下面给出了构造D的虚函数表的一种方式(仅供参考):
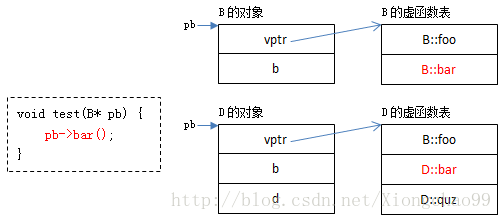
虚函数调用过程
以下面的程序为例:
4、C和C++内存分配问题
答:(1)C语言编程中的内存基本构成
C的内存基本上分为4部分:静态存储区、堆区、栈区以及常量区。他们的功能不同,对他们使用方式也就不同。
1.栈 ——由编译器自动分配释放;
2.堆 ——一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收;
3.全局区(静态区)——全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量
和未初始化的静态变量在相邻的另一块区域(C++中已经不再这样划分),程序结束释放;
4.另外还有一个专门放常量的地方,程序结束释放;
(a)函数体中定义的变量通常是在栈上;
(b)用malloc, calloc, realloc等分配内存的函数分配得到的就是在堆上;
(c)在所有函数体外定义的是全局量;
(d)加了static修饰符后不管在哪里都存放在全局区(静态区);
(e)在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用;
(f)在函数体内定义的static表示只在该函数体内有效;
(g)另外,函数中的"adgfdf"这样的字符串存放在常量区。
(2)C++编程中的内存基本构造
在C++中内存分成5个区,分别是堆、栈、全局/静态存储区、常量存储区和代码区;
1、栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清楚的变量的存储区,里面的变量通常是局部变量、函数参数等。
2、堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如
果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
3、全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在
C++里面没有这个区分了,他们共同占用同一块内存区。
4、常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)。
5、代码区 (.text段),存放代码(如函数),不允许修改(类似常量存储区),但可以执行(不同于常量存储区)。
预备知识----程序的内存分配
C++编译器将计算机内存分为代码区和数据区,很显然,代码区就是存放程序代码,而数据区则是存放程序编译和执行过程出现的变量和常量。数据区又分为静态数据区、动态数据区以及常量区,动态数据区包括堆区和栈区。
内存模型组成部分:自由存储区,动态区、静态区;
根据c/c++对象生命周期不同,c/c++的内存模型有三种不同的内存区域,即:自由存储区,动态区、静态区。
自由存储区:局部非静态变量的存储区域,即平常所说的栈;
动态区: 用new ,malloc分配的内存,即平常所说的堆;
静态区:全局变量,静态变量,字符串常量存在的位置;
注:代码虽然占内存,但不属于c/c++内存模型的一部分;
一个正在运行着的C编译程序占用的内存分为5个部分:代码区、初始化数据区、未初始化数据区、堆区 和栈区;
(1)代码区(text segment):代码区指令根据程序设计流程依次执行,对于顺序指令,则只会执行一次(每个进程),如果反复,则需要使用跳转指令,如果进行递归,则需要借助栈来实现。注意:代码区的指令中包括操作码和要操作的对象(或对象地址引用)。如果是立即数(即具体的数值,如5),将直接包含在代码中;
(2)全局初始化数据区/静态数据区(Data Segment):只初始化一次。
(3)未初始化数据区(BSS):在运行时改变其值。
(4)栈区(stack):由编译器自动分配释放,存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈。
(5)堆区(heap):用于动态内存分配。
为什么分成这么多个区域?
主要基于以下考虑:
#代码是根据流程依次执行的,一般只需要访问一次,而数据一般都需要访问多次,因此单独开辟空间以方便访问和节约空间。
#未初始化数据区在运行时放入栈区中,生命周期短。
#全局数据和静态数据有可能在整个程序执行过程中都需要访问,因此单独存储管理。
#堆区由用户自由分配,以便管理。
更多内容见:http://www.cnblogs.com/Stultz-Lee/p/6751522.html
5、协程
答:定义:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置;
线程是抢占式,而协程是协作式;
协程的优点:
跨平台
跨体系架构
无需线程上下文切换的开销
无需原子操作锁定及同步的开销
方便切换控制流,简化编程模型
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
协程的缺点:
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU;
进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序:这一点和事件驱动一样,可以使用异步IO操作来解决。
6、CGI的了解
答:CGI:通用网关接口(Common Gateway Interface)是一个Web服务器主机提供信息服务的标准接口。通过CGI接口,Web服务
器就能够获取客户端提交的信息,转交给服务器端的CGI程序进行处理,最后返回结果给客户端。
CGI通信系统的组成是两部分:一部分是html页面,就是在用户端浏览器上显示的页面。另一部分则是运行在服务器上的Cgi程序。
7、进程间通信方式和线程间通信方式
答:(1)进程间通信方式:
# 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
# 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
# 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
# 共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
# 套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
(2)线程间通信方式:
#全局变量;
#Messages消息机制;
#CEvent对象(MFC中的一种线程通信对象,通过其触发状态的改变实现同步与通信)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2018-08-15 第20章 HOOK和数据库访问
2018-08-15 第19章 动态链接库