烂题推荐
没事干放博客上了
A
给定集合 \(S\),要求对 \(\forall 1\le s\le m\),统计点权在 \(S\) 内且点权和为 \(s\) 的二叉树个数,对 \(998244353\) 取模。
\(n,m\le 10^5\)。
考虑 dp。
设 \(f_n\) 表示点权和为 \(n\) 的二叉树个数,那么可以推出递推方程:
这个复杂度是 \(O(n^2)\),观察到式子像卷积形式以及神奇模数 \(998244353\),考虑使用多项式优化。
设 \(F(x)\) 和 \(G(x)\) 分别表示 \(f\) 和 \([x\in S]\) 的生成函数,则有
解得
那么使用 多项式开根 + 多项式求逆 即可。
推荐理由:多项式优化 dp。
B
Yuno loves sqrt technology III
强制在线区间众数。
\(n,m\le 5\times 10^5\),\(0\le a_i\le 10^9\)
考虑序列分块,设块长 \(S\)。
离散化后预处理 \(f_{i,j}\) 表示第 \(i\) 块到第 \(j\) 块的区间众数,这个可以区间 dp,复杂度 \(O(\frac{n^2}{S^2}\times S)=O(\frac{n^2}{S})\)。
询问时先用预处理值算出整块的贡献,考虑怎么算零散部分,即需要查询 \(O(S)\) 个数加入一个块端点到块端点的部分可能对答案造成的影响。
常规做法是值域分块,但是我们只要在 \(O(1)\) 时间内查询这个数在区间内出现次数是不是 \(n+1\) 即可,然而这个根本不要分块。
对每个数开个 vector,按照顺序存储这个值的所有下标,以及每个数在对应 vector 中的位置。
如果现在 check 的是 \(x\),区间是 \([l,r]\),设 \(x\) 对应的位置是 \(y\),那么我们只要查 \(y\pm ans\) 是不是在这个区间里面即可,这里取加还是减取决于 \(x\) 关于 \([l,r]\) 的方位,则复杂度为 \(O(1)\)。
查询总复杂度为 \(O(S)\),取 \(S=\sqrt n\) ,总复杂度 \(O((n+m)\sqrt n)\)。
推荐理由:这个做法比之前的做法空间,常数,以及代码复杂度都小了很多,可谓是分块之鉴。
放一下代码,以证明其代码复杂度之小。
const int N=500005,S=715;
int n,m,bl,num,a[N],b[N],L[S],R[S],f[S][S],tot[N],pl[N];
vector<int>v[N];
int query(int l,int r){
int ret=0;
if(b[l]==b[r]){
for(int i=l;i<=r;i++)ret=max(ret,++tot[a[i]]);
for(int i=l;i<=r;i++)tot[a[i]]=0;
return ret;
}
ret=f[b[l]+1][b[r]-1];
for(int i=l;i<=R[b[l]];i++)while(pl[i]+ret<v[a[i]].size()&&v[a[i]][pl[i]+ret]<=r)ret++;
for(int i=L[b[r]];i<=r;i++)while(pl[i]-ret>=0&&v[a[i]][pl[i]-ret]>=l)ret++;
return ret;
}
int main(){
IO>>n>>m;
for(int i=1;i<=n;i++)IO>>a[i],b[i]=a[i];
sort(b+1,b+n+1);
num=unique(b+1,b+n+1)-b-1;
for(int i=1;i<=n;i++)a[i]=lower_bound(b+1,b+num+1,a[i])-b,pl[i]=v[a[i]].size(),v[a[i]].push_back(i);
bl=sqrt(n);
for(int i=1;i<=n;i++)b[i]=(i-1)/bl+1;
num=b[n];
for(int i=1;i<=num;i++)L[i]=R[i-1]+1,R[i]=i*bl;
R[num]=n;
for(int i=1;i<=num;i++){
memset(tot,0,sizeof(tot));
for(int j=i;j<=num;j++){
f[i][j]=f[i][j-1];
for(int k=L[j];k<=R[j];k++)f[i][j]=max(f[i][j],++tot[a[k]]);
}
}
memset(tot,0,sizeof(tot));
for(int lastans=0;m--;){
int l,r;
IO>>l>>r;
l^=lastans,r^=lastans;
IO<<(lastans=query(l,r))<<'\n';
}
return 0;
}
C
给定一表达式(含有括号、加减乘法),支持单点修改,区间查询表达式的值。
这道题比较复杂,讲几个部分分。
1. 无括号无修改
考虑使用 FHQ 平衡树维护序列,每个节点维护两个信息:子树表达式的值和子树前有个 - (无括号)时的表达式的值,维护直接根据统计信息合并。
查询把区间 split 出来后即可。
下面是 pushup 部分的代码:
void pushup(ll x){
sz[x]=sz[ch[x][0]]+sz[ch[x][1]]+1;
if(isdigit(op[x])){
val[x]=val2[x]=(pw[1+sz[ch[x][1]]]*val[ch[x][0]]%P+pw[sz[ch[x][1]]]*(op[x]-'0')%P+val[ch[x][1]])%P;
}else if(op[x]=='+'){
if(!ch[x][0]||!ch[x][1]||val[ch[x][0]]==-1||val[ch[x][1]]==-1)val[x]=val2[x]=-1;
else val[x]=(val[ch[x][0]]+val[ch[x][1]])%P,val2[x]=(val2[ch[x][0]]-val[ch[x][1]]+P)%P;
}else if(op[x]=='-'){
if(!ch[x][0]||!ch[x][1]||val[ch[x][0]]==-1||val[ch[x][1]]==-1)val[x]=val2[x]=-1;
else val[x]=(val[ch[x][0]]-val2[ch[x][1]]+P)%P,val2[x]=(val2[ch[x][0]]+val2[ch[x][1]])%P;
}else{
if(!ch[x][0]||!ch[x][1]||val[ch[x][0]]==-1||val[ch[x][1]]==-1)val[x]=val2[x]=-1;
else val[x]=val2[x]=val[ch[x][0]]*val[ch[x][1]]%P;
}
}
\(O(n\log n)\)。
2. 无括号有修改
修改只要把点 split 出来,然后改完再 merge 即可。
\(O(nk\log n)\)。
3.有括号无修改
大致是加上一种新的括号节点,有三个儿子,左儿子是左括号,右儿子是右括号,中间儿子是中间的表达式,维护方法和之前一样,用折线法 rmq 可以判断括号合法。
4.有括号有修改
对修改操作,如果修改不是括号,与第二个类似,不过这里只要和最内层括号的表达式分裂合并就行。
如果修改的是括号,可以分解以下几个操作:
- 加入一个括号
- 删除一对括号
- 加入或删除一个其他结点
第三个操作讲过了,第二个操作只要把左儿子,中儿子和右儿子合并即可,下面考虑第一个操作。
对于第一个操作,多了一个不成对的括号,可以视为在无穷远处加了个匹配括号。
贺一张图:
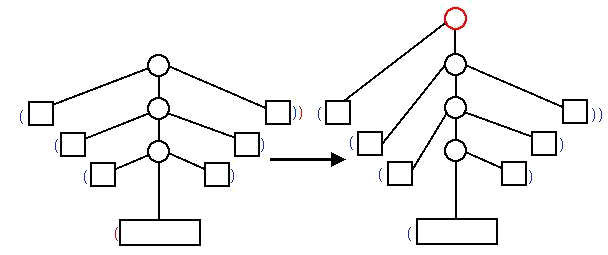
图中圆点是特殊节点,方点是其他节点圆方树?,蓝色括号表示原来树中括号,红色括号表示新加入的括号。
\(O(nk\log n)\)。
推荐理由:平衡树的妙用。
D
原创
给定 \(n\) 个点,有以下三种操作:
- 加边
- 删边
- 查询一个叶子结点的从下到上的第 \(u\) 个祖先。
规定一颗树的根节点是编号最小的点。
因为有加删边,所以考虑 LCT。
考虑查询操作,发现常规做法(split 之类的)不能用。
我们观察 access 这个操作,会发现它恰好会把点到根的实链搞出来,又注意到查询点是叶节点,所以可以用 access 来搞。
只要 access 一下,然后找这个点所在 splay 的 \(k\) 大节点(即中序遍历第 \(k\) 大),就做完了。
\(O(m\log n)\)。
推荐理由:access 的妙用。
E
原创
给定一个字符串 \(s\),对每个点 \(i\),希望求出最大的 \(l\),使得 \(\exist l-1\le j<i,s.t.s[j-l+1,j-l+2,\dots,j]=s[i-l+1,i-l+2,\dots,i]\)。
这道题有三种做法,优点各异。
Sol 1
这是一个 离线 做法,不支持单点查询。
考虑建出 \(s\) 对应的后缀自动机,我们要求的就是每个 \(i\) 所属的深度最深且 \(i\) 不是最小值的 \(\operatorname{endpos}\) 集。
自底向上,对当前节点 \(u\),标记 \(\operatorname{endpos}(u)\) 中除了最小值以外的那些位置,并且把这些位置在父节点的 \(\operatorname{endpos}\) 中删除。
复杂度 \(O(n)\)。
Sol 2
这是一个 在线 做法,但不支持单点查询。
考虑加入一个字符 \(c\) 后,我们可以先找到(目前)整个字符串对应的状态 \(last\)。
观察到答案具有单调性,我们可以使用二分答案。
由于终止状态都是 parent tree 上 \(last\) 的祖先,可以利用前面 D 题的做法,找到这个后缀对应的状态 \(u\)。
为判断这个后缀是否可行,我们考虑动态维护每个状态对应的 \(\operatorname{endpos}\) 的最小值 \(\operatorname{firstpos}\)。
为了动态维护 \(\operatorname{firstpos}\),我们考虑 SAM 的扩展函数的步骤,并尝试维护。
我们创建新状态 \(cur\) 时,令 \(\operatorname{firstpos}(u)=\operatorname{len}(cur)-1\);
我们把 \(q\) 复制到 \(clone\) 时,令 \(\operatorname{firstpos}(clone)=\operatorname{firstpos}(q)\)。
那么我们只要判断 \(\operatorname{firstpos}(u)<i\) 即可。
由于外层有二分,里面还有个 LCT,所以总复杂度是个大常数的 \(O(n\log^2n)\)。
Sol 3
这是一个 离线 做法,支持 单点查询。
考虑计算出 \(s\) 的 SA,rank 和 height 数组,并且对 height 数组处理 ST 表或者线段树,对 rank 数组处理可持久化平衡树或者权值线段树。
查询 \(i\) 的时候,还是先二分答案,判断可行性时我们可以考虑利用 \(lcp(i,j)=\min\{height[rk_i+1\dots rk_j]\}\) 这一性质,二分+ST 表或者线段树找到 \(rk_j\) 的范围,必然是个区间。
接下来我们在 \(i-l\) 号历史版本的可持久化线段树/平衡树上查找这个区间有没有数即可。
由于二分里面套了个(二分或者线段树)以及一个可持久化线段树,所以总复杂度是个比前面小一点的常数的 \(O(n\log^2 n)\)。
如果不要求单点查询的话,那就不需要可持久化线段树,直接上值域树状数组,常数会变小,复杂度不变。
推荐理由:做法多且各有优劣(虽然我只想了两个劣复杂度算法),考查了各种各样的知识(字符串和数据结构)以及对各种算法的熟悉程度,是一道不可多得的毒瘤题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号