

SQL Server 2005 hash联接算法
哈希联接可以有效处理未排序的大型非索引输入。它们对复杂查询的中间结果很有用,因为:
· 中间结果未经索引(除非已经显式保存到磁盘上然后创建索引),而且通常不为查询计划中的下一个操作进行适当的排序。
· 查询优化器只估计中间结果的大小。由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。
原理
Hash join一般用于一张小表和一张大表进行join时。Hash join的过程大致如下(下面所说的内存就指sort area,关于过程,后
面会作详细讨论):
1. 一张小表被hash在内存中。因为数据量小,所以这张小表的大多数数据已经驻入在内存中,剩下的少量数据被放置在临时表空间中;
2. 每读取大表的一条记录,就和小表中内存中的数据进行比较,如果符合,则立即输出数据(也就是说没有读取临时表空间中的小表的数
据)。而如果大表的数据与小表中临时表空间的数据相符合,则不直接输出,而是也被存储临时表空间中。
3. 当大表的所有数据都读取完毕,将临时表空间中的数据以其输出。
如果小表的数据量足够小(小于hash area size),那所有数据就都在内存中了,可以避免对临时表空间的读写。
如果是并行环境下,前面中的第2步就变成如下了:
2.每读取一条大表的记录,和内存中小表的数据比较,如果符合先做join,而不直接输出,直到整张大表数据读取完毕。如果内存足够,
Join好的数据就保存在内存中。否则,就保存在临时表空间中。
1,处理大量、未排序、无索引的数据
2 ,Hash Join一个较大限制是它只能应用于等值联结(equality join),这主要是由于哈希函数及其桶的确定性及无序性所导致的。
我们在这里看看blog中的例子:
原贴: http://www.cnblogs.com/perfectdesign/archive/2008/04/24/sql_tuning.html
USE TempDB
GO
CREATE TABLE b1 (blat1 nCHAR(5) NOT NULL)
CREATE TABLE b2 (blat2 VARCHAR(200) NOT NULL)
GO
INSERT b1
SELECT LEFT(AddressLine1, 5) AS blat1 FROM AdventureWorks.Person.Address
INSERT b2
SELECT AddressLine1 AS blat2
FROM AdventureWorks.Person.Address
GO
然后执行如下的查询语句:
SELECT * FROM b1
JOIN b2 ON b2.blat2 LIKE b1.blat1 + '%'
上面牛人blog提出的问题,不建立任何对象(索引,索引视图等),优化这个语句。其实这就是考察hash联结的使用。
分析语句:
1. 选择算法:
1,由于hash联结只能用相等联结才能使用,这时两个表b1,b2通过like来联结,结果肯定不会是hash联结
2,由于这里的联结是inner join 而这时使用merge联结同样需要两个字段关联查询,结果肯定不会是merge联结
3,由于3个联结2个不满足条件,这时优化器只能采用loop嵌套循环联结
2,如何执行loop联结
通过上面的分析,我们已经看到了只能采用loop嵌套循环。b1,b2都没有索引。
假如b1有1万条,b2有2万条。
看看执行结果:根据嵌套循环算法,是两个循环。由于都没有索引,系统先表扫描b1表1万,在通过逐条表扫描b2两万条。
最少IO总数: 1万(b1的行数)*表b2的扫描IO次数+b1表扫描IO次数。
测试上面IO次数计算例子:
表 [zping.com]中有1000条记录,id为唯一32id,通过id插入数据到b1,b2中。两个表各写入1000行,返回io数:
(1002 行受影响)
表 'Worktable'。扫描计数 2,逻辑读取 12068 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'b2'。扫描计数 2,逻辑读取 16 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'b1'。扫描计数 3,逻辑读取 4 次,物理读取 0 次,预读 24 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
按照上面的公式:4+1002*8=8020次IO 和这里IO次数比较比较起来,差距较大。
可以看出,IO数要比上面的公式大。
如果要优化就不能使用嵌套循环算法 。一些网友也给出了解决办法:最优的方法是:
from (select blat1 s from b1) a
join (select left(blat2,5) s from b2) b
on a.s=b.s
如果换成了
from (select distinct blat1 s from b1) a
join (select distinct left(blat2,5) s from b2) b
on a.s=b.s
对比成本,发现hash联结要比merge联结要快,因为这里有一个distinct显示排序操作,数据库会自动采取合并算法。
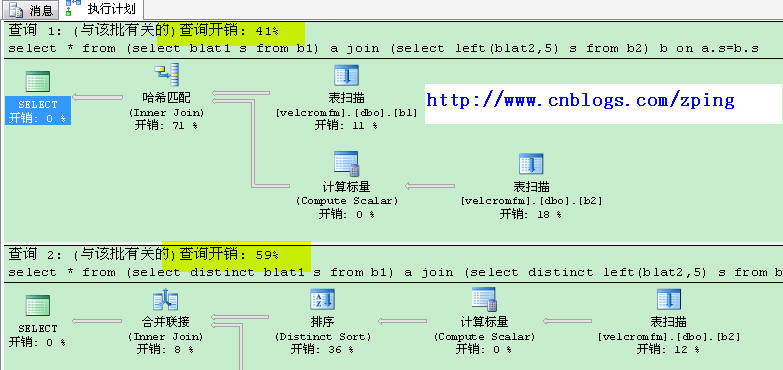
因为有了排序操作,成本就比hash慢。
因此最佳优化的SQL语句:
from (select blat1 s from b1) a
join (select left(blat2,5) s from b2) b
on a.s=b.s
如何使用Hash联结。
今天又看了一下阿里巴巴的dba,在Oracle里的研究hash联结的优化和例子:
http://www.alidba.net/index.php/archives/83
他得出的结论:
1. hash的时候一定要用小记录集做驱动.
2. 大/小记录集作驱动时, 读取数据文件的cost两者是一样的.但是前者的记录集在大到一定程度的时候, 在构建hash桶会产生很多物理读, 而且这些物理读根本无法消除, 每次执行都会产生.
我们测试一下,看看不同的驱动表对hash联结的性能影响:
表workflowinfo1 有50多万条记录,表workflowlog1有70多万数据。
执行一下语句:
inner hash join dbo.workflowlog1 b on a.workflowid=b.workflowid
select * from dbo.workflowlog1 a
inner hash join dbo.workflowinfo1 b on a.workflowid=b.workflowid
一个是以workflowinfo1为驱动表,一个是以workflowlog1为驱动表。对比成本:
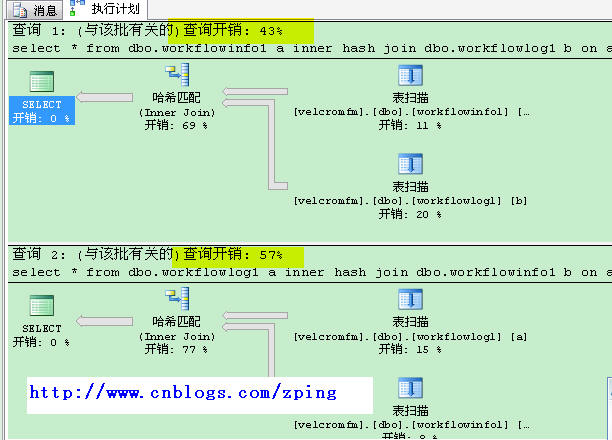
这时发现以小的驱动表(workflowinfo1,50多万)成本较少。而多的驱动表(workflowlog1,70多万)成本较高。
这里我们得出结论:
1,hash联结适合输入和输出都是大型数据集的情况。
2,联结列必须相等联结,(不相等可以如上方法换成相等联结)
3,使用较少的表为驱动表。(在使用hash提示联结尤其注意)

