做题记录
P5227 [AHOI2013] 连通图
考虑线段树分治。和模板题类似,只不过在模板题(二分图)中,如果一个区间加完之后已经不是二分图,那么每个子树内的点都不是二分图,因为奇环必然存在。
在这题中,如果一个区间加完已经是连通的,那么每个子树都是连通的。
注意可撤销并查集不能路径压缩。
#include <iostream>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <vector>
#include <stack>
using namespace std;
const int N = 2e5 + 5;
int n, m, k;
vector<int> V[N];
int u[N], v[N];
class Union_Find
{
public:
int fa[N], sz[N];
void Init()
{
for (int i = 0; i < N; i++) fa[i] = i, sz[i] = 1;
}
int find(int u)
{
return(fa[u] == u ? u : find(fa[u]));
}
pair<int, int> merge(int u, int v)
{
if ((u = find(u)) == (v = find(v)))
{
exit(-1);
}
if (sz[u] < sz[v]) swap(u, v);
fa[v] = u;
sz[u] += sz[v];
return make_pair(u, v);
}
void del(int u, int v)
{
fa[v] = v;
sz[u] -= sz[v];
}
}uf;
class SegmentTree
{
public:
struct Node
{
int l, r;
vector<pair<int, int>> v;
}tr[N << 2];
void build(int u, int l, int r)
{
tr[u] = { l, r };
tr[u].v.clear();
tr[u].v.shrink_to_fit();
if (l == r) return;
int mid = l + r >> 1;
build(u << 1, l, mid);
build(u << 1 | 1, mid + 1, r);
}
void update(int u, int l, int r, auto v)
{
if (tr[u].l >= l and tr[u].r <= r)
{
tr[u].v.emplace_back(v);
return;
}
int mid = tr[u].l + tr[u].r >> 1;
if (l <= mid) update(u << 1, l, r, v);
if (r > mid) update(u << 1 | 1, l, r, v);
}
void solve(int u)
{
stack<pair<int, int>> st;
for (auto& j : tr[u].v)
{
if (uf.find(j.first) == uf.find(j.second)) continue;
st.push(uf.merge(j.first, j.second));
}
if (uf.sz[uf.find(1)] == n)
{
for (int i = tr[u].l; i <= tr[u].r; i++)
{
cout << "Connected\n";
}
}
else
{
if (tr[u].l == tr[u].r) cout << "Disconnected\n";
else
{
solve(u << 1);
solve(u << 1 | 1);
}
}
while (st.size())
{
uf.del(st.top().first, st.top().second);
st.pop();
}
}
}sgt;
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> u[i] >> v[i];
}
cin >> k;
sgt.build(1, 1, k);
uf.Init();
for (int i = 1; i <= k; i++)
{
int c;
cin >> c;
for (int j = 1; j <= c; j++)
{
int x;
cin >> x;
V[x].emplace_back(i);
}
}
for (int i = 1; i <= m; i++)
{
if (V[i].empty())
{
sgt.update(1, 1, k, make_pair(u[i], v[i]));
}
else
{
if (V[i].front() != 1)
{
sgt.update(1, 1, V[i].front() - 1, make_pair(u[i], v[i]));
}
for (int j = 1; j < V[i].size(); j++)
{
int l = V[i][j - 1] + 1, r = V[i][j] - 1;
if (l <= r) sgt.update(1, l, r, make_pair(u[i], v[i]));
}
if (V[i].back() != k) sgt.update(1, V[i].back() + 1, k, make_pair(u[i], v[i]));
}
}
sgt.solve(1);
return 0;
}CF1140F Extending Set of Points
手玩一下发现,如果我们建一个二分图,对于点集
于是我们可以愉快地线段树分治,使用可撤销并查集动态更新答案即可,复杂度线性对数平方。
启发:对于一些看似难以下手的操作,通常可以手玩一下发现规律。尝试转化问题。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <map>
#include <vector>
#include <stack>
#include <utility>
using namespace std;
#define int long long
const int N = 7e5 + 5;
long long nowans = 0LL;
int n, q;
class Union_Find
{
public:
int fa[N], sz[N], sz1[N], sz2[N];
void Init()
{
for (int i = 0; i < N; i++) fa[i] = i, sz[i] = 1, sz1[i] = (i <= 300000), sz2[i] = (i > 300000);
}
int find(int u)
{
return (fa[u] == u ? u : find(fa[u]));
}
pair<int, int> merge(int u, int v)
{
if ((u = find(u)) == (v = find(v))) return make_pair(-1, -1);
if (sz[u] < sz[v]) swap(u, v);
fa[v] = u;
nowans -= 1LL * sz1[u] * sz2[u] + 1LL * sz1[v] * sz2[v];
sz[u] += sz[v];
sz1[u] += sz1[v], sz2[u] += sz2[v];
nowans += 1LL * sz1[u] * sz2[u];
return make_pair(u, v);
}
void del(int u, int v)
{
sz[u] -= sz[v];
nowans -= 1LL * sz1[u] * sz2[u];
sz1[u] -= sz1[v], sz2[u] -= sz2[v];
nowans += 1LL * sz1[u] * sz2[u] + 1LL * sz1[v] * sz2[v];
fa[v] = v;
}
}uf;
class SegmentTree
{
public:
struct Node
{
int l, r;
vector<pair<int, int>> v;
}tr[N << 2];
void build(int u, int l, int r)
{
tr[u] = { l, r };
tr[u].v.clear(), tr[u].v.shrink_to_fit();
if (l == r) return;
int mid = l + r >> 1;
build(u << 1, l, mid);
build(u << 1 | 1, mid + 1, r);
}
void update(int u, int l, int r, auto v)
{
if (tr[u].l >= l and tr[u].r <= r)
{
tr[u].v.emplace_back(v);
return;
}
int mid = tr[u].l + tr[u].r >> 1;
if (l <= mid) update(u << 1, l, r, v);
if (r > mid) update(u << 1 | 1, l, r, v);
}
void solve(int u)
{
stack<pair<int, int>> st;
for (auto& j : tr[u].v)
{
auto p = uf.merge(j.first, j.second + 300000);
if (p.first != -1) st.push(p);
}
if (tr[u].l == tr[u].r)
{
cout << nowans << " ";
}
else
{
solve(u << 1);
solve(u << 1 | 1);
}
while (st.size())
{
uf.del(st.top().first, st.top().second);
st.pop();
}
}
}sgt;
map<pair<int, int>, int> mp;
signed main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> q;
sgt.build(1, 1, q);
for (int i = 1; i <= q; i++)
{
int x, y;
cin >> x >> y;
if (mp[make_pair(x, y)])
{
sgt.update(1, mp[make_pair(x, y)], i - 1, make_pair(x, y));
//cout << "!!!!!: " << mp[make_pair(x, y)] << " " << i - 1 << " " << x << " " << y << "\n";
mp[make_pair(x, y)] = 0;
}
else mp[make_pair(x, y)] = i;
}
for (auto& [x, y] : mp)
{
if (y <= q && y >= 1)
{
sgt.update(1, y, q, make_pair(x.first, x.second));
//cout << "!!!!!: " << y << " " << q << " " << x.first << " " << x.second << "\n";
}
}
uf.Init();
sgt.solve(1);
return 0;
}KDOI S 模拟赛 T1。
由于我可能没有脑子,所以做法较为复杂。但是个人认为很好想,赛时看题
比较显然的是,至多进行一次操作
考虑在
注意到
时间复杂度线性对数。
启发:对于题目需要最优化达到目标的代价之类时,考虑某一个或多个操作在最优情况下的方案。
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N = 5e5 + 5, MOD = 1e9 + 7; // Remember to change
int n, m, q, t, a[N], b[N], c[N];
bool vs[N];
namespace FastIo
{
#define QUICKCIN ios::sync_with_stdio(0), cin.tie(0), cout.tie(0)
int read()
{
char ch = getchar();
int x = 0, f = 1;
while ((ch < '0' || ch > '9') && ch != '-') ch = getchar();
while (ch == '-')
{
f = -f;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
template<class T>
void write(T x)
{
if (x < 0)
{
putchar('-');
x = -x;
}
if (x > 9) write(x / 10);
putchar(x % 10 + '0');
}
template<class T>
void writeln(T x)
{
write(x);
putchar('\n');
}
}
bool res[N];
using namespace FastIo;
class SegmentTree
{
public:
struct Node
{
int l, r, minn, tag;
}tr[N << 2];
void pushup(int u)
{
tr[u].minn=min(tr[u<<1].minn, tr[u<<1|1].minn);
}
void pushdown(int u)
{
if(tr[u].tag)
{
tr[u<<1].tag+=tr[u].tag;
tr[u<<1].minn+=tr[u].tag;
tr[u<<1|1].tag+=tr[u].tag;
tr[u<<1|1].minn+=tr[u].tag;
tr[u].tag=0;
}
}
void build(int u, int l, int r, int *p)
{
tr[u]={l,r,p[l],0LL};
if(l==r) return;
int mid=l+r>>1;
build(u<<1,l,mid, p);
build(u<<1|1,mid+1,r,p);
pushup(u);
}
void update(int u, int l, int r, int v)
{
if (tr[u].l>=l and tr[u].r<=r)
{
tr[u].tag+=v;
tr[u].minn+=v;
return;
}
pushdown(u);
int mid=tr[u].l+tr[u].r>>1;
if(l<=mid) update(u<<1,l,r,v);
if(r>mid) update(u<<1|1,l,r,v);
pushup(u);
}
int query(int u, int l,int r)
{
if(tr[u].l>=l and tr[u].r<=r)
{
return tr[u].minn;
}
pushdown(u);
int mid=tr[u].l+tr[u].r>>1,res=2e18;
if(l<=mid) res=query(u<<1,l,r);
if(r>mid) res=min(res, query(u<<1|1,l,r));
return res;
}
}sgt;
int p[N];
signed main()
{
// freopen("reserve4.in", "r", stdin);
// freopen("reserve4.out", "w", stdout);
n=read();
int psum=0;
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=n;i++) b[i]=read(),psum+=b[i];
for(int i=1;i<=n;i++) c[i]=read();
for(int i=n;i>=1;i--)p[i]=p[i+1]+b[i+1];
for(int i=1;i<=n;i++) p[i]+=a[i];
sgt.build(1,1,n,p);
m=read();
while(m--)
{
int p;
p=read();
vector<int> v;
int ans=psum;
for(int i=1;i<=p;i++)
{
int g=read();
v.emplace_back(g);
res[g]=1;
ans-=b[g];
}
for(auto&j:v)
{
if(j>1) sgt.update(1,1,j-1,-b[j]);
}
int nsum=0;
for(auto&j:v)
{
nsum+=c[j];
int res=sgt.query(1,j,j)+nsum;
ans=min(ans,res);
}
//处理1~v.front()-1段
if(v.size()&&v.front()-1>=1)
{
ans=min(ans, sgt.query(1,1,(int)(v.front()-1)));
}
else if(!v.size())
{
ans=min(ans, sgt.query(1,1,n));
}
//处理v.back()+1到n段
if(v.size()&&v.back()+1<=n)
{
ans=min(ans, sgt.query(1,v.back()+1,n)+nsum);
}
//处理每两个之间
int nowsums=(v.size()?c[v.front()]:0);
for(int i=1;i<(int)v.size();i++)
{
int l=v[i-1]+1,r=v[i]-1;
if(l>r)
{
nowsums+=c[v[i]];
continue;
}
int res=sgt.query(1,l,r)+nowsums;
ans=min(ans, res);
nowsums+=c[v[i]];
}
for(auto&j:v)
{
if(j>1) sgt.update(1,1,j-1,b[j]);
}
writeln(ans);
}
return 0;
}P3825 [NOI2017] 游戏
直接思考是困难的,突破点在于 x 对应的是什么。然而直接枚举是
注意到一个如果是 a,那么就可以选 B 和 C,如果是 b,就可以选 A 和 C。意味着我们对于每个 x 只枚举 a 和 b 即可包括全部方案。
a,那么要么填 B,要么填 C。b 和 c 同理。对于
容易发现这可以使用 2-SAT 维护,对于
启发:可以从题目的数据范围下手,将题目转化成容易处理的问题。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 5;
int n, d, m;
string s;
int id[N][3];
int a[N], b[N];
char ca[N], cb[N];
vector<int> v, G[N];
int dfn[N], low[N], idx, scc_cnt, idd[N];
int stk[N], top;
bool in_stk[N];
vector<int> vvv[N];
void Init()
{
for (int i = 0; i < N; i++) dfn[i] = low[i] = stk[i] = idd[i] = in_stk[i] = 0, G[i].clear(), vvv[i].clear(), id[i][0] = id[i][1] = id[i][2] = 0;
idx = top = scc_cnt = 0;
}
void tarjan(int u)
{
dfn[u] = low[u] = ++idx;
stk[++top] = u;
in_stk[u] = 1;
for (auto &j : G[u])
{
if (!dfn[j])
{
tarjan(j);
low[u] = min(low[u], low[j]);
}
else if (in_stk[j]) low[u] = min(low[u], dfn[j]);
}
if (dfn[u] == low[u])
{
scc_cnt++;
int y = 0;
do
{
y = stk[top--];
in_stk[y] = 0;
idd[y] = scc_cnt;
} while (y != u);
}
}
void solve()
{
Init();
for (int i = 1; i <= n; i++)
{
if (s[i] == 'a') id[i][1] = i, id[i][2] = i + n;
else if (s[i] == 'b') id[i][0] = i, id[i][2] = i + n;
else id[i][0] = i, id[i][1] = i + n;
for (int j = 0; j <= 2; j++)
{
if (id[i][j]) vvv[i].emplace_back(id[i][j]);
}
}
for (int i = 1; i <= m; i++)
{
if (id[a[i]][ca[i] - 'a'] == 0) continue;
if (id[b[i]][cb[i] - 'a'] == 0)
{
G[id[a[i]][ca[i] - 'a']].emplace_back(id[a[i]][ca[i] - 'a'] == vvv[a[i]][0] ? vvv[a[i]][1] : vvv[a[i]][0]);
continue;
}
G[id[a[i]][ca[i] - 'a']].emplace_back(id[b[i]][cb[i] - 'a']);
G[(id[b[i]][cb[i] - 'a'] == vvv[b[i]][0] ? vvv[b[i]][1] : vvv[b[i]][0])].emplace_back((id[a[i]][ca[i] - 'a'] == vvv[a[i]][0] ? vvv[a[i]][1] : vvv[a[i]][0]));
}
for (int i = 1; i <= 2 * n; i++)
{
if (!dfn[i]) tarjan(i);
}
for (int i = 1; i <= n; i++)
{
if (idd[vvv[i][0]] == idd[vvv[i][1]])
{
return;
}
}
for (int i = 1; i <= n; i++)
{
if (idd[vvv[i][0]] > idd[vvv[i][1]])
{
cout << (s[i] == 'a' ? 'C' : s[i] == 'b' ? 'C' : 'B');
}
else cout << (s[i] == 'a' ? 'B' : 'A');
}
cout << "\n";
exit(0);
}
void dfs(int u)
{
if (u == v.size())
{
solve();
return;
}
s[v[u]] = 'a';
dfs(u + 1);
s[v[u]] = 'b';
dfs(u + 1);
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> d >> s >> m;
s = " " + s;
for (int i = 1; i <= n; i++)
{
if (s[i] == 'x') v.emplace_back(i);
}
for (int i = 1; i <= m; i++)
{
cin >> a[i] >> ca[i] >> b[i] >> cb[i];
ca[i] = tolower(ca[i]);
cb[i] = tolower(cb[i]);
}
if (d == 0)
{
for (int i = 1; i <= n; i++)
{
if (s[i] == 'a') id[i][1] = i, id[i][2] = i + n;
else if (s[i] == 'b') id[i][0] = i, id[i][2] = i + n;
else id[i][0] = i, id[i][1] = i + n;
for (int j = 0; j <= 2; j++)
{
if (id[i][j]) vvv[i].emplace_back(id[i][j]);
}
}
for (int i = 1; i <= m; i++)
{
if (id[a[i]][ca[i] - 'a'] == 0) continue;
if (id[b[i]][cb[i] - 'a'] == 0)
{
G[id[a[i]][ca[i] - 'a']].emplace_back(id[a[i]][ca[i] - 'a'] == vvv[a[i]][0] ? vvv[a[i]][1] : vvv[a[i]][0]);
continue;
}
G[id[a[i]][ca[i] - 'a']].emplace_back(id[b[i]][cb[i] - 'a']);
G[(id[b[i]][cb[i] - 'a'] == vvv[b[i]][0] ? vvv[b[i]][1] : vvv[b[i]][0])].emplace_back((id[a[i]][ca[i] - 'a'] == vvv[a[i]][0] ? vvv[a[i]][1] : vvv[a[i]][0]));
}
for (int i = 1; i <= 2 * n; i++)
{
if (!dfn[i]) tarjan(i);
}
for (int i = 1; i <= n; i++)
{
if (idd[vvv[i][0]] == idd[vvv[i][1]])
{
cout << "-1\n";
return 0;
}
}
for (int i = 1; i <= n; i++)
{
if (idd[vvv[i][0]] > idd[vvv[i][1]])
{
cout << (s[i] == 'a' ? 'C' : s[i] == 'b' ? 'C' : 'B');
}
else cout << (s[i] == 'a' ? 'B' : 'A');
}
cout << "\n";
}
else
{
dfs(0);
cout << "-1\n";
}
return 0;
}P4755 Beautiful Pair
处理这类问题的经典方法是枚举
另一种常见做法是分治。solve(l,r) 表示求
于是考虑瓶颈在哪里,发现最大值是难以处理的。如果我们能固定最大值,就可以更加方便的统计答案了。于是我们不用
形式化地,我们想要求出有多少
不妨枚举
然而枚举
启发:求满足条件的
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 5;
int a[N], n, ra[N];
long long ans = 0LL;
vector<int> b;
int rt[N];
class SegmentTree
{
public:
int idx;
struct Node
{
int l, r, sum;
}tr[N * 20];
void pushup(int u)
{
tr[u].sum = tr[tr[u].l].sum + tr[tr[u].r].sum;
}
int ins(int p, int x, int l, int r)
{
int u = ++idx;
tr[u] = tr[p];
if (l == r)
{
tr[u].sum++;
return u;
}
int mid = l + r >> 1;
if (x <= mid) tr[u].l = ins(tr[p].l, x, l, mid);
else tr[u].r = ins(tr[p].r, x, mid + 1, r);
pushup(u);
return u;
}
int query(int p, int q, int l, int r, int nl, int nr)
{
if (l >= nl && r <= nr) return tr[q].sum - tr[p].sum;
int res = 0, mid = l + r >> 1;
if (nl <= mid) res = query(tr[p].l, tr[q].l, l, mid, nl, nr);
if (nr > mid) res += query(tr[p].r, tr[q].r, mid + 1, r, nl, nr);
return res;
}
}sgt;
int query(int l, int r, int x)
{
if (l > r) return 0;
return sgt.query(rt[l - 1], rt[r], 1, n, 1, x);
}
class ST
{
public:
int LG2[N], f[N][21];
void Init()
{
for (int i = 2; i < N; i++)
{
LG2[i] = LG2[i / 2] + 1;
}
for (int i = 1; i <= n; i++) f[i][0] = i;
for (int j = 1; j <= LG2[n]; j++)
{
for (int i = 1; (i + (1 << j) - 1) <= n; i++)
{
int x = a[f[i][j - 1]], y = a[f[i + (1 << (j - 1))][j - 1]];
if (x > y) f[i][j] = f[i][j - 1];
else f[i][j] = f[i + (1 << (j - 1))][j - 1];
}
}
}
int query(int l, int r)
{
int p = LG2[r - l + 1];
int x = a[f[l][p]], y = a[f[r - (1 << p) + 1][p]];
return (x > y ? f[l][p] : f[r - (1 << p) + 1][p]);
}
}st;
void solve(int l, int r)
{
if (l > r) return;
if (l == r)
{
return;
}
int place = st.query(l, r);
int nl = l, nr = place;
if (r - place + 1 < place - l + 1) nl = place, nr = r;
for (int i = nl; i <= nr; i++)
{
// j * ra[a[i]] <= ra[a[place]]
// => j <= ra[a[place]] / ra[a[i]]
int maxn = ra[a[place]] / ra[a[i]];
if (b.front() > maxn) continue;
int g = upper_bound(b.begin(), b.end(), maxn) - b.begin();
if (nl == place && nr == r)
{
//cout << "!!!!!: " << l << " " << r << " " << place << " " << i << " " << query(l, place - 1, g) << "\n";
ans += query(l, place - 1, g);
}
else
{
ans += query(place + 1, r, g);
}
}
if (nl > nr) return;
if (nl == place && nr == r)
{
solve(l, place - 1);
solve(place, r);
}
else solve(l, place), solve(place + 1, r);
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i], b.emplace_back(a[i]);
sort(b.begin(), b.end());
b.erase(unique(b.begin(), b.end()), b.end());
for (int i = 1; i <= n; i++)
{
ans += (a[i] == 1);
int r = a[i];
a[i] = lower_bound(b.begin(), b.end(), a[i]) - b.begin() + 1;
ra[a[i]] = r;
rt[i] = sgt.ins(rt[i - 1], a[i], 1, n);
}
st.Init();
solve(1, n);
cout << ans << "\n";
return 0;
}P6378 [PA2010] Riddle
恰有一个关键点,一条边至少有一个关键点。想到 2-SAT。
对于每条边,如果
对于每一个部分
容易发现这是一个类似 2-SAT 的逻辑,但是直接连边复杂度不对,因为每个部分的复杂度是
考虑优化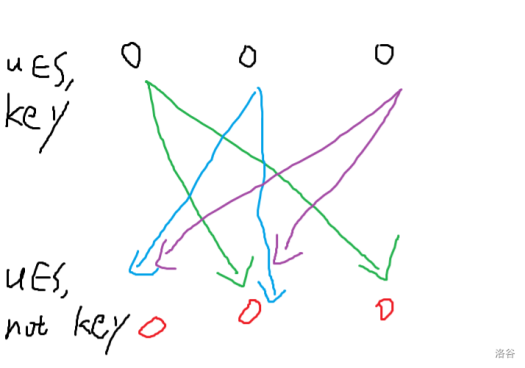
直接连大概是这样子,我们对于第一行每个点新建一个前缀点和后缀点,如下图:
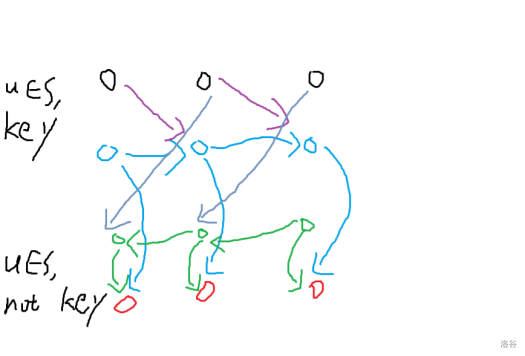
发现与原图等价,并且边数是
启示:逻辑、命题有关的考虑 2-SAT。一个点连向一个前缀或后缀考虑前后缀优化建图。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e7 + 5;
int n, m, k;
vector<int> G[N];
int dfn[N], low[N], stk[N], top, idx, cnt;
bool in_stk[N];
int p[N], p2[N], nidx;
int id[N];
void tarjan(int u)
{
dfn[u] = low[u] = ++idx;
stk[++top] = u;
in_stk[u] = 1;
for (auto &j : G[u])
{
if (!dfn[j])
{
tarjan(j);
low[u] = min(low[u], low[j]);
}
else if (in_stk[j]) low[u] = min(low[u], dfn[j]);
}
if (dfn[u] == low[u])
{
cnt++;
int y = 0;
do
{
y = stk[top--];
in_stk[y] = 0;
id[y] = cnt;
} while (y != u);
}
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m >> k;
for (int i = 1; i <= m; i++)
{
int u, v;
cin >> u >> v;
G[u + n].emplace_back(v);
G[v + n].emplace_back(u);
}
nidx = 2 * n;
for (int i = 1; i <= k; i++)
{
int w;
cin >> w;
vector<int> v;
for (int j = 1; j <= w; j++)
{
int x;
cin >> x;
v.emplace_back(x);
p[x] = ++nidx;
p2[x] = ++nidx;
G[p[x]].emplace_back(x + n);
G[p2[x]].emplace_back(x + n);
if (j != 1)
{
G[p[v[v.size() - 2]]].emplace_back(p[x]);
G[p2[x]].emplace_back(p2[v[v.size() - 2]]);
}
}
for (int j = 1; j <= w; j++)
{
if (j != w) G[v[j - 1]].emplace_back(p[v[j]]);
if (j != 1) G[v[j - 1]].emplace_back(p2[v[j - 2]]);
}
}
for (int i = 1; i <= nidx; i++) if (!dfn[i]) tarjan(i);
for (int i = 1; i <= n; i++)
{
if (id[i] == id[i + n])
{
cout << "NIE\n";
return 0;
}
}
cout << "TAK\n";
return 0;
}CF1890E1 Doremy's Drying Plan (Easy Version)
Hard Version 的做法貌似是 DP,但是 Easy Version 的做法也十分有启发性。
Easy Version 中
设
对于进行两次操作,两个区间中分别的
不妨这样考虑:枚举第一次操作,先计算第二次操作中两个区间没有交集的贡献。接着枚举区间中每个
注意到我们只枚举
具体地,
对于
我写的比较丑,所以带个
启示:操作两次或求满足条件
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N = 5e5 + 5, MOD = 1e9 + 7; // Remember to change
int n, m, k, c[N], t;
int l[N], r[N], p[N], g[N], gp[N];
int ps[N];
namespace FastIo
{
#define QUICKCIN ios::sync_with_stdio(0), cin.tie(0), cout.tie(0)
int read()
{
char ch = getchar();
int x = 0, f = 1;
while ((ch < '0' || ch > '9') && ch != '-') ch = getchar();
while (ch == '-')
{
f = -f;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
template<class T>
void write(T x)
{
if (x < 0)
{
putchar('-');
x = -x;
}
if (x > 9) write(x / 10);
putchar(x % 10 + '0');
}
template<class T>
void writeln(T x)
{
write(x);
putchar('\n');
}
}
signed main()
{
ios::sync_with_stdio(0), cin.tie(nullptr), cout.tie(nullptr);
cin >> t;
while (t--)
{
cin >> n >> m >> k;
for (int i = 1; i <= n; i++) c[i] = p[i] = gp[i] = g[i] = ps[i] = 0;
for (int i = 1; i <= m; i++)
{
cin >> l[i] >> r[i];
p[r[i] + 1]--;
p[l[i]]++;
gp[r[i] + 1] -= i;
gp[l[i]] += i;
}
int ans = 0;
set<int> pp;
multiset<int> st;
for (int i = 1; i <= n; i++)
{
c[i] = c[i - 1] + p[i], g[i] = g[i - 1] + gp[i];
ans += (c[i] == 0), ps[i] = ps[i - 1] + (c[i] == 1);
if (c[i] == 2) pp.insert(i);
}
int maxn = 0;
for (int i = 1; i <= m; i++)
{
st.insert(ps[r[i]] - ps[l[i] - 1]);
}
for (int i = 1; i <= m; i++)
{
map<int, int> cc;
int g = ps[r[i]] - ps[l[i] - 1], rg = g;
st.erase(st.find(g));
if (st.size()) g += *(st.rbegin());
st.insert(rg);
auto it = pp.lower_bound(l[i]);
for (; it != pp.end() && *it <= r[i]; ++it)
{
cc[::g[*it] - i]++;
}
for (auto &[x, y] : cc)
{
int h = ps[r[i]] - ps[l[i] - 1] + ps[r[x]] - ps[l[x] - 1];
g = max(g, h + y);
}
maxn = max(maxn, g);
}
cout << ans + maxn << "\n";
}
return 0;
}P4234 最小差值生成树
题意:带边权无向图,求最大边权减最小边权最小的生成树。
对于这种两个相减,一种想法是固定其中一个。例如固定最小值。我们将边按照边权从大到小排序,从前往后依次添加每一条边。我们钦定了最小值为当前枚举的这条边,那么为了让最大值最小,我们需要在这段前缀中寻找瓶颈生成树。显然根据结论这就是最小生成树,最大的边权即为最小生成树的最大值。
现在我们要维护的即,添加一条边,动态维护最小生成树。显然的,可以用动态树维护,最小生成树的最大边可以用 multiset 维护,复杂度
LCT 中边权转点权的方法:对于每一条边,添加一个新点向两端分别连边,点权为这条边的边权。原图上的点边权为
启示:遇到两个含有
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <stack>
#include <cstring>
#include <set>
#include <string>
#include <vector>
using namespace std;
const int N = 1e6 + 5;
int n, m;
struct Edge
{
int u, v, w;
Edge() = default;
Edge(int u, int v, int w)
: u(u), v(v), w(w)
{
}
bool operator==(const Edge& other) const = default;
}p[N];
int idx;
class Link_Cut_Tree
{
public:
struct Node
{
int val, son[2], fa, maxn, maxid;
bool rev;
}tr[N];
int get(int u)
{
return (u == tr[tr[u].fa].son[1]);
}
bool isroot(int u)
{
return (tr[tr[u].fa].son[0] != u && tr[tr[u].fa].son[1] != u);
}
void pushup(int u)
{
if (tr[u].val > tr[tr[u].son[0]].maxn && tr[u].val > tr[tr[u].son[1]].maxn)
{
tr[u].maxn = tr[u].val;
tr[u].maxid = u;
}
else
{
if (tr[tr[u].son[0]].maxn > tr[tr[u].son[1]].maxn)
{
tr[u].maxn = tr[tr[u].son[0]].maxn;
tr[u].maxid = tr[tr[u].son[0]].maxid;
}
else
{
tr[u].maxn = tr[tr[u].son[1]].maxn;
tr[u].maxid = tr[tr[u].son[1]].maxid;
}
}
}
void rev(int u)
{
tr[u].rev ^= 1;
swap(tr[u].son[0], tr[u].son[1]);
}
void pushdown(int u)
{
if (tr[u].rev)
{
rev(tr[u].son[0]);
rev(tr[u].son[1]);
tr[u].rev = 0;
}
}
void rotate(int x)
{
int y = tr[x].fa, z = tr[y].fa;
int chkx = get(x), chky = get(y), p = isroot(y);
tr[y].son[chkx] = tr[x].son[chkx ^ 1];
if (tr[x].son[chkx ^ 1]) tr[tr[x].son[chkx ^ 1]].fa = y;
tr[x].son[chkx ^ 1] = y;
tr[y].fa = x;
tr[x].fa = z;
if (z && !p) tr[z].son[chky] = x;
pushup(y), pushup(x);
}
void update(int x)
{
stack<int> st;
st.push(x);
while (!isroot(x))
{
x = tr[x].fa;
st.push(x);
}
while (!st.empty())
{
pushdown(st.top());
st.pop();
}
}
void splay(int u)
{
update(u);
while (!isroot(u))
{
int y = tr[u].fa, z = tr[y].fa;
if (!isroot(y))
{
if (get(u) != get(y)) rotate(u);
else rotate(y);
}
rotate(u);
}
}
void access(int x)
{
int z = x;
for (int y = 0; x; y = x, x = tr[x].fa)
{
splay(x);
tr[x].son[1] = y;
pushup(x);
}
splay(z);
}
int findroot(int u)
{
access(u);
while (tr[u].son[0])
{
pushdown(u);
u = tr[u].son[0];
}
splay(u);
return u;
}
void makeroot(int u)
{
access(u);
rev(u);
}
int split(int u, int v)
{
if (findroot(u) != findroot(v)) return -1;
makeroot(u);
access(v);
return v;
}
void link(int u, int v)
{
makeroot(u);
if (findroot(v) != u)
{
tr[u].fa = v;
}
}
void cut(int u, int v)
{
makeroot(u);
if (findroot(v) == u && tr[v].fa == u && !tr[v].son[0])
{
tr[u].son[1] = tr[v].fa = 0;
pushup(u);
}
}
}lct;
class Union_Find
{
public:
int fa[N], sz[N];
void Init()
{
for (int i = 0; i < N; i++) fa[i] = i, sz[i] = 1;
}
int find(int u)
{
return (fa[u] == u ? u : fa[u] = find(fa[u]));
}
void merge(int u, int v)
{
if ((u = find(u)) == (v = find(v))) return;
fa[v] = u;
sz[u] += sz[v];
}
}uf;
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
uf.Init();
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> p[i].u >> p[i].v >> p[i].w;
}
idx = n;
sort(p + 1, p + m + 1, [&](const Edge& x, const Edge& y) {return x.w > y.w; });
int ans = 2e9;
multiset<int> st;
for (int i = 1; i <= m; i++)
{
idx++;
int u = p[i].u, v = p[i].v;
uf.merge(u, v);
if (lct.findroot(u) != lct.findroot(v))
{
lct.link(u, idx);
lct.link(v, idx);
lct.splay(idx);
lct.tr[idx].val = p[i].w;
lct.pushup(idx);
st.insert(p[i].w);
}
else
{
int g = lct.split(u, v);
if (~g)
{
if (lct.tr[g].maxn > p[i].w)
{
st.erase(st.find(lct.tr[g].maxn));
st.insert(p[i].w);
int c = lct.tr[g].maxid;
lct.cut(p[c - n].u, c);
lct.cut(p[c - n].v, c);
lct.link(u, idx);
lct.link(v, idx);
lct.splay(idx);
lct.tr[idx].val = p[i].w;
lct.pushup(idx);
}
}
}
if (uf.sz[uf.find(1)] == n)
{
ans = min(ans, *st.rbegin() - p[i].w);
}
}
cout << ans << "\n";
return 0;
}CF1895E Infinite Card Game
赛时差一点过,因为缺少了一个关键性质的观察。
容易发现可以
注意到当我打出这张牌,对手一定会打出攻击力大于这张牌的防御力并且那张牌防御力最大,显然可以二分,然后就可以将图的边数减小了。这就是关键性质。
启示:这种题考虑有向图博弈,边过多时考虑对方的最优策略。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 5, MOD = 1e9 + 7; // Remember to change
int n, m, q, t, a[N];
int ax[N], ay[N], bx[N], by[N];
namespace FastIo
{
#define QUICKCIN ios::sync_with_stdio(0), cin.tie(0), cout.tie(0)
int read()
{
char ch = getchar();
int x = 0, f = 1;
while ((ch < '0' || ch > '9') && ch != '-') ch = getchar();
while (ch == '-')
{
f = -f;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
template<class T>
void write(T x)
{
if (x < 0)
{
putchar('-');
x = -x;
}
if (x > 9) write(x / 10);
putchar(x % 10 + '0');
}
template<class T>
void writeln(T x)
{
write(x);
putchar('\n');
}
}
vector<int> G[N];
int in[N];
int dp[N];
bool vis[N];
struct Node
{
int x, y, id;
Node(int _x, int _y, int _i): x(_x), y(_y), id(_i){}
Node() = default;
bool operator<(const Node& g) const
{
return (x ^ g.x) ? (x < g.x) : (y < g.y);
}
}g[N], gg[N];
int sufmax[N];
signed main()
{
ios::sync_with_stdio(0), cin.tie(nullptr), cout.tie(nullptr);
cin>>t;
while(t--)
{
cin>>n;
for(int i=1;i<=n;i++) cin>>ax[i];
for(int i=1;i<=n;i++) cin>>ay[i];
cin>>m;
vector<pair<int, int>> v;
for(int i=1;i<=m;i++) cin>>bx[i];
for(int i=1;i<=m;i++) cin>>by[i];
for(int i=1;i<=m;i++)
{
g[i]=Node(bx[i],by[i],i);
gg[i]=g[i];
}
for(int i=1;i<=n+m;i++) G[i].clear(),in[i]=0,dp[i]=-1,vis[i]=0;
sort(g+1,g+m+1);
sufmax[m]=m;
for(int i=m-1;i>=1;i--)
{
if(g[i].y>g[sufmax[i+1]].y) sufmax[i]=i;
else sufmax[i]=sufmax[i+1];
}
for(int i=1;i<=n;i++)
{
int maxnid=0;
auto j=upper_bound(g+1,g+m+1,Node(ay[i],100000000,0))-g;
if(j>=1&&j<=m)
{
int maxnid=sufmax[j];
maxnid=g[maxnid].id;
G[n+maxnid].emplace_back(i),in[i]++;
}
}
/*
for(int i=1;i<=m;i++)
{
int maxnid=0;
for(int j=1;j<=n;j++)
{
if(ax[j]>by[i])
{
if(ay[j]>ay[maxnid])
{
maxnid=j;
}
}
}
if(maxnid) G[maxnid].emplace_back(i+n),in[i+n]++;
}*/
for(int i=1;i<=n;i++) g[i]=Node(ax[i],ay[i],i);
sort(g+1,g+n+1);
sufmax[n]=n;
for(int i=n-1;i>=1;i--)
{
if(g[i].y>g[sufmax[i+1]].y) sufmax[i]=i;
else sufmax[i]=sufmax[i+1];
}
for(int i=1;i<=m;i++)
{
int maxnid=0;
auto j=upper_bound(g+1,g+n+1,Node(by[i],100000000,0))-g;
if(j>=1&&j<=n)
{
int maxnid=sufmax[j];
maxnid=g[maxnid].id;
G[maxnid].emplace_back(i+n),in[i+n]++;
}
}
queue<int> q;
for(int i=1;i<=n+m;i++)
{
if(in[i]==0)
{
q.push(i);
dp[i]=1;
}
}
while(q.size())
{
auto u = q.front();
q.pop();
for(auto&j:G[u])
{
if(vis[j]) continue;
in[j]--;
if(dp[u]==1)
{
dp[j]=0;
vis[j]=1;
q.push(j);
}
else if(in[j]==0)
{
dp[j]=1;
q.push(j);
vis[j]=1;
}
}
}
int a1=0,a2=0,a3=0;
for(int i=1;i<=n;i++)
{
a1+=(dp[i]==1);
a2+=(dp[i]==-1);
a3+=(dp[i]==0);
}
cout<<a1<< " " << a2 << " " << a3 << "\n";
}
return 0;
}P3402 可持久化并查集
比较容易的主席树应用题,自己想到了。
一般的并查集通过路径压缩或按秩合并保证复杂度,然而在主席树中,由于难以进行对版本的修改,路径压缩的复杂度是错误的,考虑用按秩合并维护。线段树每个节点维护
合并时使用子树大小和深度复杂度都是对的。总体复杂度为
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <vector>
#include <queue>
using namespace std;
const int N = 4e5 + 5;
int n, m, rt[N];
class Chariman_Tree
{
public:
int idx;
struct Node
{
int lson, rson, sz, fa;
}tr[N * 25];
int build(int l, int r)
{
int u = ++idx;
tr[u] = { 0, 0, 1, l };
if (l == r) return u;
int mid = l + r >> 1;
tr[u].lson = build(l, mid);
tr[u].rson = build(mid + 1, r);
return u;
}
pair<int, int> query(int u, int l, int r, int x)
{
if (!u) return make_pair(-1, -1);
if (l == r) return make_pair(tr[u].fa, tr[u].sz);
int mid = l + r >> 1;
if (x <= mid) return query(tr[u].lson, l, mid, x);
return query(tr[u].rson, mid + 1, r, x);
}
int update_fa(int p, int x, int y, int l, int r)
{
int u = ++idx;
tr[u] = tr[p];
if (l == r)
{
tr[u].fa = y;
return u;
}
int mid = l + r >> 1;
if (x <= mid) tr[u].lson = update_fa(tr[p].lson, x, y, l, mid);
else tr[u].rson = update_fa(tr[p].rson, x, y, mid + 1, r);
return u;
}
int update_sz(int p, int x, int y, int l, int r)
{
int u = ++idx;
tr[u] = tr[p];
if (l == r)
{
tr[u].sz = max(tr[u].sz, y + 1);
return u;
}
int mid = l + r >> 1;
if (x <= mid) tr[u].lson = update_sz(tr[p].lson, x, y, l, mid);
else tr[u].rson = update_sz(tr[p].rson, x, y, mid + 1, r);
return u;
}
}sgt;
int getfa(int x, int p)
{
auto g = sgt.query(p, 1, n, x);
if (g.first == x) return x;
return getfa(g.first, p);
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m;
rt[0] = sgt.build(1, n);
for (int i = 1; i <= m; i++)
{
int op;
cin >> op;
if (op == 1)
{
rt[i] = rt[i - 1];
int x, y;
cin >> x >> y;
x = getfa(x, rt[i]);
y = getfa(y, rt[i]);
if (x == y) continue;
int k = sgt.query(rt[i], 1, n, y).second;
if (sgt.query(rt[i], 1, n, x).second < k) swap(x, y);
// sz_x > sz_y
k = sgt.query(rt[i], 1, n, y).second;
rt[i] = sgt.update_fa(rt[i], y, x, 1, n);
rt[i] = sgt.update_sz(rt[i], x, k, 1, n);
}
else if (op == 2)
{
int k;
cin >> k;
rt[i] = rt[k];
}
else
{
int x, y;
cin >> x >> y;
rt[i] = rt[i - 1];
cout << (getfa(x, rt[i]) == getfa(y, rt[i]) ? 1 : 0) << "\n";
}
}
return 0;
}[ARC069F] Flags
考虑二分答案。
每个点要么选
直接建边的话,枚举
考虑优化,发现如果按
由于数据范围很小,
启示:直接连边很慢时,考虑一些性质,例如连的是一段区间或前后缀时,可以优化建图。
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 5;
vector<int> G[N];
int dfn[N], low[N], idx, cnt, id[N];
bool in_stk[N];
int stk[N], top;
int n, m;
int len;
int cc;
struct Node
{
int a, b, id;
Node(int _a, int _b, int _i): a(_a), b(_b), id(_i){}
Node() = default;
}p[N];
inline int get(int x)
{
return x / len;
}
inline int L(int x)
{
return max(1, x * len);
}
int idp[N];
void add(int u, int l, int r)
{
if (l > r) return;
if (r - l <= len + 5)
{
for (int i = l; i <= r; i++)
{
G[u].emplace_back(p[i].id + n);
}
return;
}
int L = get(l) + 1, R = get(r) - 1;
for (int i = L; i <= R; i++)
{
G[u].emplace_back(idp[i]);
}
for (; get(l) != L; l++) G[u].emplace_back(p[l].id + n);
for (; get(r) != R; r--) G[u].emplace_back(p[r].id + n);
}
void add2(int u, int l, int r)
{
if (l > r) return;
if (r - l <= len + 5)
{
for (int i = l; i <= r; i++)
{
//cout << "Edge: ";
G[u].emplace_back(p[i].id);
}
return;
}
int L = get(l) + 1, R = get(r) - 1;
for (int i = L; i <= R; i++)
{
G[u].emplace_back(idp[i]);
}
for (; get(l) != L; l++) G[u].emplace_back(p[l].id);
for (; get(r) != R; r--) G[u].emplace_back(p[r].id);
}
void tarjan(int u)
{
dfn[u] = low[u] = ++idx;
stk[++top] = u;
in_stk[u] = 1;
for (auto &j : G[u])
{
if (!dfn[j])
{
tarjan(j);
low[u] = min(low[u], low[j]);
}
else if (in_stk[j]) low[u] = min(low[u], dfn[j]);
}
if (dfn[u] == low[u])
{
cnt++;
int y = 0;
do
{
y = stk[top--];
in_stk[y] = 0;
id[y] = cnt;
} while (y != u);
}
}
inline bool check(int x)
{
sort(p + 1, p + n + 1, [&](const Node& x, const Node& y){return x.a < y.a;});
sort(p + n + 1, p + n + n + 1, [&](const Node& x, const Node& y){return x.b < y.b;});
for (int i = 1; i <= cc; i++)
{
G[i].clear(), dfn[i] = low[i] = id[i] = in_stk[i] = 0;
}
cc = 2 * n;
top = 0;
for (int i = get(1); i <= get(n); i++)
{
idp[i] = ++cc;
int l = L(i), r = min(n, L(i + 1) - 1);
for (int j = l; j <= r; j++)
{
G[cc].emplace_back(p[j].id + n);
//cout << "Edge: " << cc << " " << p[j].id + n << "\n";
}
}
for (int i = 1; i <= n; i++)
{
int l = p[i].a - x + 1, r = p[i].a + x - 1;
int ll = lower_bound(p + 1, p + n + 1, Node(l, 0, 0), [&](const Node& x, const Node& y){return x.a < y.a;}) - p;
int rr = upper_bound(p + 1, p + n + 1, Node(r, 0, 0), [&](const Node& x, const Node& y){return x.a < y.a;}) - p - 1;
if (ll >= 1 && ll <= n && rr >= 1 && rr <= n && rr >= ll)
{
add(p[i].id, ll, i - 1);
add(p[i].id, i + 1, rr);
}
}
for (int i = 1; i <= n; i++)
{
int l = p[i].b - x + 1, r = p[i].b + x - 1;
int ll = lower_bound(p + 1, p + n + 1, Node(l, 0, 0), [&](const Node& x, const Node& y){return x.a < y.a;}) - p;
int rr = upper_bound(p + 1, p + n + 1, Node(r, 0, 0), [&](const Node& x, const Node& y){return x.a < y.a;}) - p - 1;
if (ll >= 1 && ll <= n && rr >= 1 && rr <= n && rr >= ll)
{//cout << "djb: " << i << " " << ll << " " << rr << "\n";
if (i >= ll && i <= rr)
{
add(p[i].id + n, ll, i - 1);
add(p[i].id + n, i + 1, rr);
}
else add(p[i].id + n, ll, rr);
}
}
//
for (int i = get(0); i <= get(2 * n); i++)
{
idp[i] = ++cc;
int l = L(i), r = min(2 * n, L(i + 1) - 1);
for (int j = l; j <= r; j++)
{
//cout << "Edge: " << cc << " " << p[j].id << "\n";
G[cc].emplace_back(p[j].id);
}
}
for (int i = n + 1; i <= 2 * n; i++)
{
int l = p[i].a - x + 1, r = p[i].a + x - 1;
int ll = lower_bound(p + n + 1, p + 2 * n + 1, Node(0, l, 0), [&](const Node& x, const Node& y){return x.b < y.b;}) - p;
int rr = upper_bound(p + n + 1, p + 2 * n + 1, Node(0, r, 0), [&](const Node& x, const Node& y){return x.b < y.b;}) - p - 1;
if (ll >= n && ll <= 2 * n && rr >= n && rr <= 2 * n && rr >= ll)
{
if (i >= ll && i <= rr)
{
add2(p[i].id, ll, i - 1);
add2(p[i].id, i + 1, rr);
}
else add2(p[i].id, ll, rr);
}
}
for (int i = n + 1; i <= 2 * n; i++)
{
int l = p[i].b - x + 1, r = p[i].b + x - 1;
int ll = lower_bound(p + n + 1, p + 2 * n + 1, Node(0, l, 0), [&](const Node& x, const Node& y){return x.b < y.b;}) - p;
int rr = upper_bound(p + n + 1, p + 2 * n + 1, Node(0, r, 0), [&](const Node& x, const Node& y){return x.b < y.b;}) - p - 1;
if (ll >= n && ll <= 2 * n && rr >= n && rr <= 2 * n && rr >= ll)
{
add2(p[i].id + n, ll, i - 1);
add2(p[i].id + n, i + 1, rr);
}
}
for (int i = 1; i <= cc; i++) if (!dfn[i]) tarjan(i);
for (int i = 1; i <= n; i++)
{
if (id[i] == id[i + n]) return 0;
}
return 1;
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n;
len = sqrt(n);
for (int i = 1; i <= n; i++)
{
cin >> p[i].a >> p[i].b, p[i].id = i;
}
for (int i = 1; i <= n; i++) p[i + n] = p[i];
int l = 0, r = (int)1e9, ans = 0;
while (l <= r)
{
int mid = l + r >> 1;
if (check(mid)) ans = mid, l = mid + 1;
else r = mid - 1;
}
cout << ans << "\n";
return 0;
}P3514 [POI2011] LIZ-Lollipop
简要题意:一个只包含
范围
考虑一个重要性质,如果存在区间和为
证明:考虑区间两侧。由于
于是只需要求和最大的且和是奇(偶)数的区间即可。
考虑区间和为奇,意味着区间中有奇数个
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int N = 1e6 + 5;
int n, m, a[N], sum[N], cnt[N];
int maxj, maxo, jl, jr, ol, of;
pair<int, int> ans[2 * N];
void solve()
{
jl = jr = ol = of = -1;
int lstpos = n + 1;
for (int i = n; i; i--)
{
if (a[i] == 1)
{
lstpos = i;
break;
}
}
for (int i = 1; i <= n; i++)
{
int nowcnt = cnt[n] - cnt[i - 1];
if (nowcnt & 1)
{
if (sum[n] - sum[i - 1] > maxj)
{
maxj = sum[n] - sum[i - 1];
jl = i, jr = n;
}
if (lstpos != n + 1)
{
int p = lstpos - 1;
if (p >= i && sum[p] - sum[i - 1] > maxo)
{
maxo = sum[p] - sum[i - 1];
ol = i, of = p;
}
}
}
else
{
if (sum[n] - sum[i - 1] > maxo)
{
maxo = sum[n] - sum[i - 1];
ol = i, of = n;
}
if (lstpos != n + 1)
{
int p = lstpos - 1;
if (p >= i && sum[p] - sum[i - 1] > maxj)
{
maxj = sum[p] - sum[i - 1];
jl = i, jr = p;
}
}
}
}
int nowres = maxo;
while (nowres > 0)
{
ans[nowres] = make_pair(ol, of);
if (a[ol] == a[of] && a[ol] == 1) ol++, of--;
else
{
if (a[ol] == 2) ol++;
else of--;
}
nowres -= 2;
}
nowres = maxj;
while (nowres > 0)
{
ans[nowres] = make_pair(jl, jr);
if (a[jl] == a[jr] && a[jl] == 1) jl++, jr--;
else
{
if (a[jl] == 2) jl++;
else jr--;
}
nowres -= 2;
}
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m;
for (int i = 1; i <= n; i++)
{
char c;
cin >> c;
if (c == 'T') a[i] = 2;
else a[i] = 1;
sum[i] = sum[i - 1] + a[i];
}
for (int i = 1; i <= n; i++) cnt[i] = cnt[i - 1] + (a[i] == 1);
solve();
while (m--)
{
int x;
cin >> x;
if (x & 1)
{
if (maxj >= x) cout << ans[x].first << " " << ans[x].second;
else cout << "NIE";
}
else
{
if (maxo >= x) cout << ans[x].first << " " << ans[x].second;
else cout << "NIE";
}
if (m != 0)
{
cout << "\n";
}
}
return 0;
}P2291 [PA2011] Prime prime power 质数的质数次方
我们注意到
考虑对于小的
对于
启示:对于很难处理的问题,考虑一些值的范围。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <vector>
#include <set>
using namespace std;
const int N = 6e6 + 5;
int prime[N], cnt;
bool vis[N];
void Init()
{
for (int i = 2; i < N; i++)
{
if (!vis[i])
{
prime[++cnt] = i;
}
for (int j = 1; j <= cnt && 1LL * i * prime[j] < N; j++)
{
vis[i * prime[j]] = 1;
if (i % prime[j] == 0) break;
}
}
}
long long n;
int k;
bool isprime(long long x)
{
if (x == 1) return 0;
for (long long i = 2; i * i <= x; i++)
{
if (x % i == 0) return 0;
}
return 1;
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
set<long long> v;
cin >> n >> k;
Init();
for (int i = 1; i <= cnt; i++)
{
long long g = prime[i];
int nowp = 1;
for (int j = 1; j <= cnt; j++)
{
while (nowp < prime[j])
{
nowp++;
g *= prime[i];
if (g > (long long)1e18) goto E;
}
v.insert(g);
}
E:;
}
long long p = (long long)ceil(sqrt(n));
for (int i = 1; i <= 5000; i++)
{
if (p * p > (long long)1e18) break;
if (isprime(p))
{
v.insert(p * p);
}
p++;
}
while (*v.begin() <= n) v.erase(v.begin());
auto it = v.begin();
for (int i = 1; i <= k; i++)
{
++it;
}
--it;
cout << *it << "\n";
return 0;
}P3417 [POI2005] BANK-Cash Dispenser
考虑爆搜。
对于每一个动作,枚举每一个长度为
现在的问题在于,怎么判断一个串是否是可能的 PIN。
即,将这个串中相邻的相同都变成一个后,判断是否是原串的子序列。例如 1989 仍然是 1989,而 0064 就要变成 064。
接着判断这个是否是原串的子序列。直接做复杂度是
启示:判断子序列时,如果原串固定,但有很多匹配串时,子序列自动机可以做到优秀的复杂度。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <map>
#include <string>
#include <set>
#include <vector>
using namespace std;
unordered_map<string, int> mp;
int n;
string p;
bool f = 1;
int x;
bool v[50];
vector<int> g[50];
int son[10005][10];
void dfs(int u, string s)
{
if (u == 4)
{
int now = 0;
int j = 0;
for (int p = 0; p < s.size(); p++)
{
char k = s[p];
if (p && k == s[p - 1]) continue;
if (son[j][k - '0'] == -1) return;
j = son[j][k - '0'];
}
mp[s]++;
return;
}
for (int i = 0; i <= 9; i++)
{
if (!v[i]) continue;
dfs(u + 1, s + (char)(i + '0'));
}
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> x;
cin >> p;
for (int j = 0; j <= 9; j++) v[j] = 0, g[j].clear();
for (auto &j : p) v[j - '0'] = 1;
for (int j = 1; j <= x; j++) g[p[j - 1] - '0'].emplace_back(j);
for (int j = 0; j <= x; j++)
{
for (int k = 0; k <= 9; k++) son[j][k] = -1;
for (int k = 0; k <= 9; k++)
{
auto it = upper_bound(g[k].begin(), g[k].end(), j);
if (it != g[k].end())
{
son[j][k] = *it;
}
}
}
dfs(0, "");
}
int ans = 0;
for (auto& y : mp)
{
if (y.second == n)
{
ans++;
}
}
cout << ans << "\n";
return 0;
}P3435 [POI2006] OKR-Periods of Words
5min 想出来了。
题解区基本都是 KMP 做法,我这个哈希感觉很另类。
我们考虑常见套路,枚举
有一个重要性质是,如果
显然,因为
所以我们只需要维护对于当前
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <set>
#include <queue>
using namespace std;
const int N = 1e6 + 5;
int n;
string s;
long long ans = 0LL;
using ull = unsigned long long;
ull hs[N], powe[N];
const ull BASE = 71;
void Init()
{
powe[0] = 1;
for (int i = 1; i < N; i++) powe[i] = powe[i - 1] * BASE;
for (int i = 1; i <= n; i++) hs[i] = hs[i - 1] * BASE + (ull)(s[i] - 'a' + 1);
}
ull subhash(int l, int r)
{
return hs[r] - hs[l - 1] * powe[r - l + 1];
}
bool issame(int l1, int r1, int l2, int r2)
{
return (subhash(l1, r1) == subhash(l2, r2));
}
bool isperiod(int i, int j)
{
if (i * 2 < j || i >= j) return 0;
int rmlen = j - i;
if (!issame(1, rmlen, i + 1, j)) return 0;
return 1;
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> s;
s = " " + s;
Init();
vector<int> v;
for (int i = 2; i <= n; i++)
{
for (int j = v.size() - 1; j >= 0; j--)
{
if (!isperiod(v[j], i))
{
v.pop_back();
}
else break;
}
if (isperiod(i - 1, i)) v.emplace_back(i - 1);
if (v.size()) ans += v.back();
}
cout << ans << "\n";
return 0;
}P3465 [POI2008] CLO-Toll
简单构造。
图不一定连通,我们对每个连通块单独考虑。
无解当且仅当存在一个连通块为树。容易发现如果是树,确实无法构造,因为任选一个点作为根,根的入度不可能为
那为什么不是树时一定有解?考虑经典套路,通过 DFS 生成树构造答案。注意到最终一若最终答案是外向基环树森林则必定为合法构造,而只要连通块不是树,就一定存在环。通过 DFS 生成树找到任意一个简单环并且往外连外向基环树即可。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <bitset>
#include <vector>
using namespace std;
const int N = 1e5 + 5;
int ans[N], n, m;
vector<int> G[N];
bitset<N> vis;
int fa[N];
bool flag = 0;
int tp;
void dfs(int u, int f)
{
vis[u] = 1;
fa[u] = f;
for (auto& j : G[u])
{
if (j == f) continue;
if (!vis[j])
{
dfs(j, u);
}
else if (!flag && vis[j])
{
flag = 1;
tp = u;
}
}
}
void solve(int u, int f)
{
ans[u] = f;
for (auto& j : G[u])
{
if (j == f) continue;
if (!ans[j])
{
solve(j, u);
}
}
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m;
if (m <= n - 1)
{
cout << "NIE\n";
return 0;
}
for (int i = 1; i <= m; i++)
{
int u, v;
cin >> u >> v;
G[u].emplace_back(v);
G[v].emplace_back(u);
}
for (int i = 1; i <= n; i++)
{
if (!vis[i])
{
flag = 0;
dfs(i, i);
solve(tp, 0);
if (!flag)
{
cout << "NIE\n";
return 0;
}
}
}
cout << "TAK\n";
for (int i = 1; i <= n; i++)
{
cout << ans[i] << "\n";
}
return 0;
}CF903G Yet Another Maxflow Problem
比较好想,但是细节比较多。
我们考虑到最大流
由于图的特殊性质,左侧
我们假设左侧选的是割
又注意到,我们修改的仅仅是左侧
修改时只需要修改
注意上述讨论都基于两边都割一条边,但事实上可以选择不割两边只割中间,割一边不割另一边。讨论一下即可。
启示:题目中的一些特殊限制可以启发做法。
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N = 2e5 + 5;
using ll = long long;
int n, m, q;
ll a[N], b[N];
ll res[N];
vector<pair<int, ll>> v[N], vv[N];
class SegmentTree
{
public:
struct Node
{
int l, r;
ll minn, tag;
}tr[N << 2];
void pushup(int u)
{
tr[u].minn = min(tr[u << 1].minn, tr[u << 1 | 1].minn);
}
void pushtag(int u, ll t)
{
tr[u].tag += t;
tr[u].minn += t;
}
void pushdown(int u)
{
if (tr[u].tag)
{
pushtag(u << 1, tr[u].tag);
pushtag(u << 1 | 1, tr[u].tag);
tr[u].tag = 0;
}
}
void build(int u, int l, int r, ll *b)
{
tr[u] = { l, r, b[l], 0LL };
if (l == r) return;
int mid = l + r >> 1;
build(u << 1, l, mid, b);
build(u << 1 | 1, mid + 1, r, b);
pushup(u);
}
void update(int u, int l, int r, ll v)
{
if (tr[u].l >= l and tr[u].r <= r)
{
pushtag(u, v);
return;
}
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
if (l <= mid) update(u << 1, l, r, v);
if (r > mid) update(u << 1 | 1, l, r, v);
pushup(u);
}
}sgt, s2;
ll s[N];
signed main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m >> q;
for (int i = 2; i <= n; i++)
{
cin >> a[i] >> b[i];
}
bool f = 1;
ll ss2 = 0;
ll ss = 0;
for (int i = 1; i <= m; i++)
{
int x, y;
ll z;
cin >> x >> y >> z;
if (y == n) ss += z;
else f = 0;
ss2 += z;
v[x].emplace_back(make_pair(y, z));
vv[y].emplace_back(make_pair(x, z));
}
b[1] = (int)1e15;
sgt.build(1, 1, n, b);
for (int i = 2; i <= n; i++)
{
ll tot = 0;
for (auto &[j, v] : ::v[i - 1])
{
sgt.update(1, 1, j, v);
tot += v;
}
res[i] = sgt.tr[1].minn;
res[i] += a[i];
s[i] = s[i - 1] + tot;
res[i] = min(res[i], a[i] + s[i]);
}
res[1] = (int)1e15;
s2.build(1, 1, n, res);
ll ress = ss + (!f ? b[n] : 0LL);
ll sus = 0;
for (int i = n - 1; i >= 2; i--)
{
ll sp = ss + b[i];
for (auto &[k, v] : vv[i]) sus += v;
ress = min(ress, sp + sus);
}
cout << min(s2.tr[1].minn, min(ress, ss2)) << "\n";
while (q--)
{
int x, y;
cin >> x >> y;
x++;
s2.update(1, x, x, -a[x]);
a[x] = y;
s2.update(1, x, x, a[x]);
cout << min(s2.tr[1].minn, min(ress, ss2)) << "\n";
}
return 0;
}[AGC001D] Arrays and Palindrome
考虑回文的本质是什么。即第一个和最后一个相等,第二个和倒数第二个相等,……。
先考虑如果给定
图连通的必要条件是边数 impossible。
把
#include <iostream>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int N = 1e5 + 5;
int n, m, a[N];
vector<int> ans;
void solve_1()
{
for (int i = 1; i <= n / 2; i++) ans.emplace_back(2);
ans.emplace_back(1);
}
void solve_2()
{
for (int i = 1; i < n / 2; i += 2)
{
ans.emplace_back(2);
}
ans.emplace_back(1);
for (int i = n / 2 + 2; i < n; i += 2) ans.emplace_back(2);
ans.emplace_back(1);
}
bool vis[N];
int na[N];
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> a[i];
}
if (m == 1)
{
if (n & 1) solve_1();
else solve_2();
cout << a[1] << "\n";
cout << ans.size() << "\n";
for (auto& i : ans) cout << i << " ";
return 0;
}
int sum = 0;
for (int i = 1; i <= m; i++)
{
sum += (a[i] >> 1);
}
if (sum + (n / 2) < n - 1)
{
cout << "Impossible\n";
return 0;
}
bool f = 0;
int c = 0;
for (int i = 1; i <= m; i++)
{
if (a[i] & 1)
{
c++;
vis[i] = 1;
if (!f)
{
na[1] = a[i];
f = 1;
}
else na[m] = a[i];
}
}
int idx = (f ? 2 : 1);
for (int i = 1; i <= m; i++)
{
if (!(a[i] & 1))
{
na[idx++] = a[i];
}
}
ans.emplace_back(na[1] + 1);
for (int i = 2; i < m; i++) ans.emplace_back(na[i]);
if (na[m] != 1) ans.emplace_back(na[m] - 1);
for (int i = 1; i <= m; i++) cout << na[i] << " ";
cout << "\n";
cout << ans.size() << "\n";
for (auto& i : ans) cout << i << " ";
cout << "\n";
return 0;
}[AGC001E] BBQ Hard
简要题意:
题目的特殊限制在与值域小于等于
考虑
为什么?从
接着考虑原式,
考虑平移坐标系,方案数不变。于是把原点从
这样我们就把
然而这样做会对
注意
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const long long MOD = 1e9 + 7;
const int N = 5e5 + 5;
int n, a[N], b[N];
long long f[4005][4005];
// 0, 0 -> a_i+a_j, b_i+b_j
//
// -a_i -b_i -> a_j b_j
long long fact[N];
long long qpow(long long a, long long b)
{
long long res = 1LL, base = a;
while (b)
{
if (b & 1LL)
{
res = res * base;
res %= MOD;
}
base = base * base % MOD;
b >>= 1LL;
}
return res;
}
long long binom(long long x, long long y)
{
return fact[x] * qpow(fact[y], MOD - 2LL) % MOD * qpow(fact[x - y], MOD - 2LL) % MOD;
}
long long ans = 0LL;
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
fact[0] = 1;
for (int i = 1; i < N; i++) fact[i] = fact[i - 1] * i % MOD;
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i] >> b[i];
for (int i = 1; i <= n; i++)
{
f[-a[i] + 2001][-b[i] + 2001]++;
}
for (int i = 0; i < 4005; i++)
{
for (int j = 0; j < 4005; j++)
{
if (j > 0) f[i][j] += f[i][j - 1];
if (i > 0) f[i][j] += f[i - 1][j];
f[i][j] %= MOD;
}
}
for (int i = 1; i <= n; i++)
{
ans += f[a[i] + 2001][b[i] + 2001];
ans %= MOD;
}
for (int i = 1; i <= n; i++)
{
ans = (ans - binom(a[i] + b[i] + a[i] + b[i], a[i] + a[i]) + MOD) % MOD;
}
cout << ans * qpow(2LL, MOD - 2LL) % MOD << "\n";
return 0;
}

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现