Multi-task Learning 理论(多任务学习)
一. 多任务学习理论
1.1 多任务学习的定义
如果有\(n\)个任务(传统的深度学习方法旨在使用一种特定模型仅解决一项任务),而这\(n\)个任务或它们的一个子集彼此相关但不完全相同,则称为多任务学习(以下简称为MTL) 。通过使用所有\(n\)个任务中包含的知识,将有助于改善特定模型的学习
多任务学习本质上是迁移学习的一种方式,通过共享表示信息,同时学习多个相关任务,使这些任务取得比单独训练一个任务更好的效果,可以在一定程度上缓解模型的过拟合,提高模型的泛化能力
通过权衡主任务与辅助的相关任务中的训练信息来提升模型的泛化性与表现。从机器学习的视角来看,MTL可以看作一种inductive transfer(先验知识),通过提供inductive bias(某种对模型的先验假设)来提升模型效果。比如,使用L1正则,对模型的假设模型偏向于sparse solution(参数要少)。在MTL中,这种先验是通过auxiliary task来提供,更灵活,告诉模型偏向一些其他任务,最终导致模型会泛化得更好。
1.2 多任务学习的发展
MTL思想在1993年Rich Caruana首次提出,并应用于道路追踪和肺炎预测。2008年被Collobert和Weston等人首次在自然语言处理领域应用于神经网络,他们也因此获得2018年机器学习国际会议ICML的test-of-time奖。如今,多任务学习在自然语言处理领域广泛使用
1.3 多任务学习的有效性
多任务学习能提效,主要是由于以下几点原因:
-
隐式数据增强:每个任务都有自己的样本,如果使用MTL的话,模型的样本量会提升很多。而且数据都会有噪声,如果单学A任务,模型会把A数据的噪声也学进去,如果是多任务学习,模型因为要求B任务也要学习好,就会忽视掉A任务的噪声,同理,模型学A的时候也会忽视掉B任务的噪声,因此MTL可以学到一个更精确的嵌入表达
-
注意力聚焦:如果任务的数据噪声非常多,数据很少且非常高维,模型对相关特征和非相关特征就无法区分。多任务学习可以帮助模型聚焦到有用的特征上,因为不同任务都会反应特征与任务的相关性
-
特征信息窃取:有些特征在任务B中容易学习,在任务A中较难学习,主要原因是任务A与这些特征的交互更为复杂,且对于任务A来说其他特征可能会阻碍部分特征的学习,因此通过MTL,模型可以高效的学习每一个重要的特征
-
表达偏差:MTL使模型学到所有任务都偏好的向量表示。这也将有助于该模型推广到未来的新任务,因为假设空间对于足够多的训练任务表现良好,对于学习新任务也表现良好
-
正则化:对于一个任务而言,其他任务的学习都会对该任务有正则化效果
![单任务与多任务对比[1].png](https://img2022.cnblogs.com/blog/1917315/202211/1917315-20221111154546996-1603090723.png)
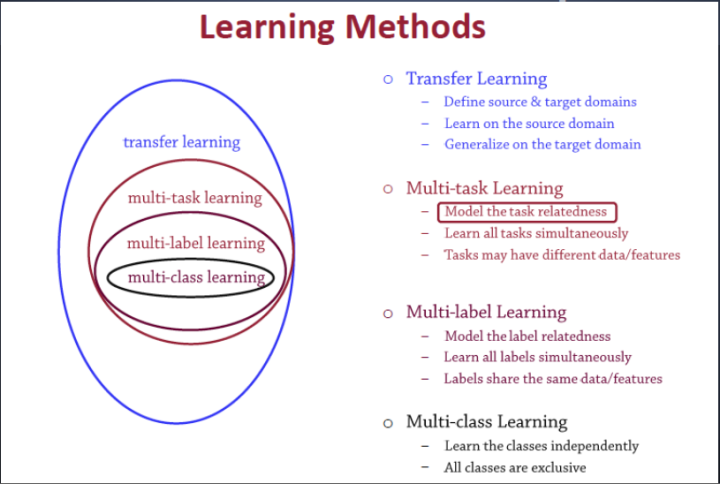
1.4 多任务学习和其他学习算法的关系
-
transfer learning:定义一个源域一个目标域,从源域学习,然后把学习的知识信息迁移到目标域中,从而提升目标域的泛化效果。迁移学习一个非常经典的案例就是图像处理中的风格迁移
-
multi-task:训练模型的时候目标是多个相关目标共享一个表征,比如人的特征学习,一个人,既可以从年轻人和老人这方面分类,也可以从男人女人这方面分类,这两个目标联合起来学习人的特征模型,可以学习出来一个共同特征,适用于这两种分类结果,这就是多任务学习
-
multi-label:打多个标签,或者说进行多种分类,还是拿人举例啊,一个人,他可以被打上标签{青年,男性,画家}这些标签。如果还有一个人他也是青年男性,但不是画家,那就只能打上标签{青年,男性}。它和多任务学习不一样,它的目标不是学习出一个共同的表示,而是多标签
-
multi-class:多分类问题,可选类别有多个但是结果只能分到一类中,比如一个人他是孩子、少年、中年人还是老人
二. 多任务学习基本原理与方法
2.1 多任务学习的范式
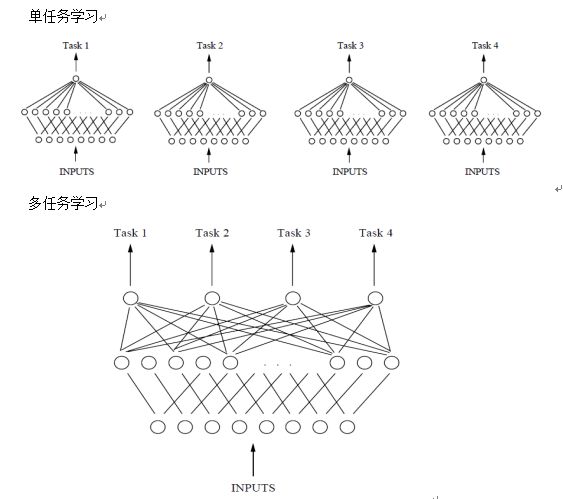
在深度学习模型中,多任务学习的最直接实现方法是多个Task共享底层的多层网络参数,同时在模型输出层针对不同任务配置基层Task-specific的参数。这样,底层网络可以在学习多个Task的过程中从不同角度提取样本信息。然而,这种Hard Parameter Sharing的方法,往往会出现跷跷板现象。不同任务之间虽然存在一定的关联,但是也可能存在冲突。联合训练导致不相关甚至冲突的任务之间出现负迁移的现象,影响最终效果
从下图中可以发现,单任务学习时,各个任务之间的模型空间Trained Model是相互独立的。多任务学习时,多个任务之间的模型空间Trained Model是共享的。假设用含一个隐含层的神经网络来表示学习一个任务,单任务学习和多任务学习可以表示如图所示:
2.2 隐层参数的硬共享机制
在所有任务之间共享隐藏层,同时保留几个特定任务的输出层来实现。降低了过拟合的风险。直观来讲,越多任务同时学习,模型就能捕捉到越多任务的同一个表示,从而导致在原始任务上的过拟合风险越小
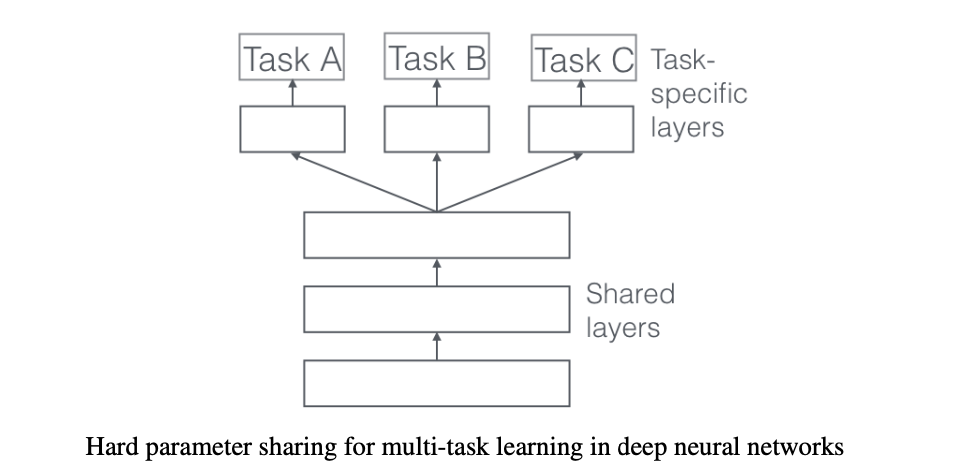
此方法表示的是不同任务通过共享一些底部的层学习一些共有的低层次的特征,为了保证任务的独特性,每个任务在顶部拥有自己独特的层学习高层次的特征。这种方法底层共享的参数是完全相同的。所有任务在保留任务特有的输出层的同时可以共享一些相关的隐藏层。这种多任务学习的方法通过平均噪声能有效地降低过拟合的风险。而且相关的任务越多,目标任务的过拟合风险越小
2.3 隐层参数的软共享机制
当任务关系不是特别紧密的时候,软参数共享的方法可能学习得到更好的结果
每个任务都有自己的模型,自己的参数。模型参数之间的距离是正则化的,以便鼓励参数相似化
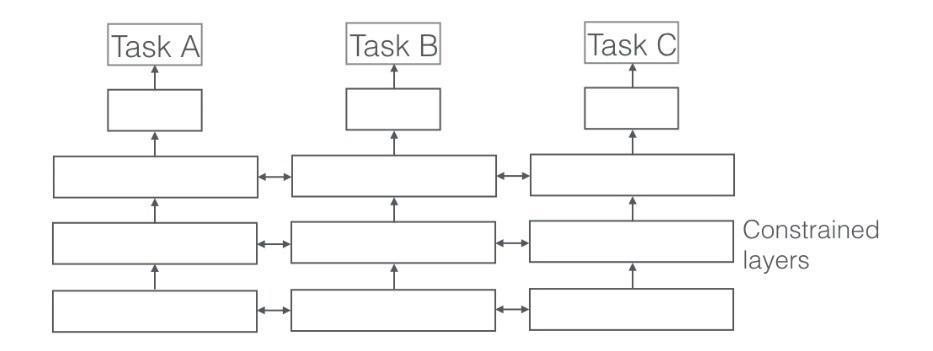
相对于硬参数约束的多任务深度学习模型,软约束的多任务学习模型的约束更加宽松,底层的参数不一定完全一致,底层共享一部分参数,自己还有独特的一部分参数不共享,因此研究人员关注的重点在于如何把底层共享、不共享的参数融合到一起送到各自任务的顶层
2.4 多任务学习的工程实现范式
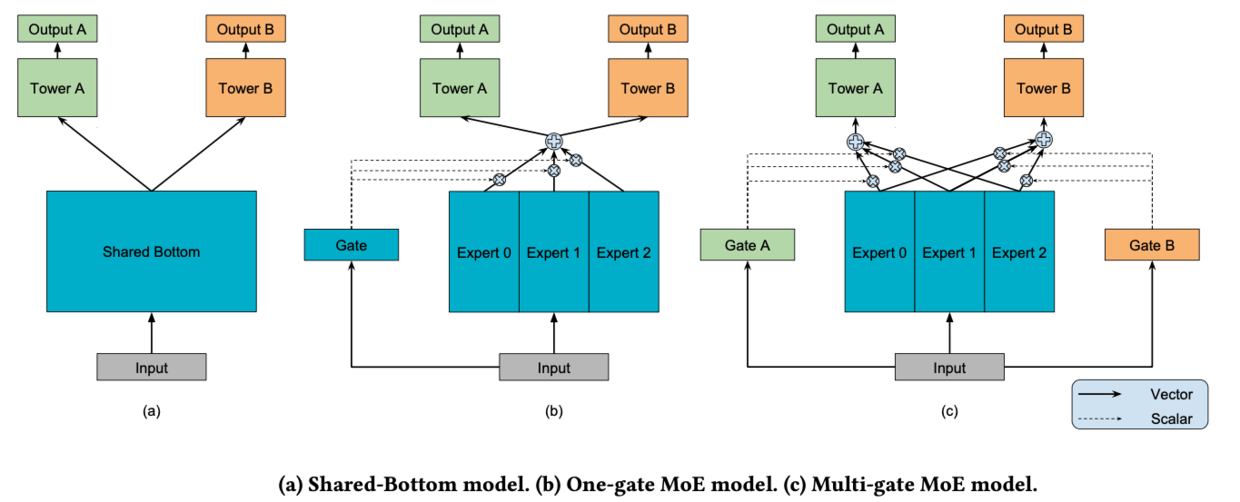
- Shared-Bottom model:多任务的学习的本质在于共享表示层,并使得任务之间相互影响,在预测的目标之间的相关性比较高的情况下(比如:猫分类和狗分类,他们通常会有比较接近的底层特征,比如皮毛、颜色等等),这样参数共享层不会带来太大的损失,参数共享层能够加强参数共享,多个目标的模型可以联合训练,减小模型的参数规模,防止模型过拟合。Shared-Bottom网络通常位于底部,表示为函数\(f\),多个任务共用这一层。往上,\(K\)个子任务分别对应一个tower network,表示为\(h^k\),每个子任务的输出为\(y_k=h^k(f(x))\)
- One-gate MoE model:用一组由专家网络(expert network)组成的神经网络结构来替换掉Shared-Bottom部分函数,这里的每个专家都是一个前馈神经网络,再加上一个门控网络,就构成了MoE结构的MTL模型。因为只有一个Gate网络,为了与MMoE对应,也称这种结构为OMoE(One-gate Mixture-of-Experts),MoE模型可以形式化表示为:
其中,\(f_i(i=1,...,n)\)是\(n\)个expert network(expertnet work可认为是一个神经网络),\(g\)是组合experts结果的门控网络(gating network),\(y=\sum_{i=1}^ng(x)_i=1\),具体来说\(g\)产生\(n\)个experts上的概率分布,最终的输出是所有experts的带权加和。显然,MoE可看做基于多个独立模型的集成方法。这里注意MoE只对应上图中的一部分,我们把得到的带权结果\(n\)输入到子任务分别对应的tower network中进行学习。上文中也提到了有些文章将MoE作为一个基本的组成单元,将多个MoE结构堆叠在一个大网络中。比如一个MoE层可以接受上一层MoE层的输出作为输入,其输出作为下一层的输入使用
- Multi-gate MoE model:底层特征共享方式的一大特点是在任务之间都比较相似或者相关性比较大的场景下能带来很好的效果,归纳偏置的作用也能够很好的发挥出来,而对于任务间差异比较大的场景,这种共享结构就有点捉襟见肘了。MMoE为每一个模型目标设置一个gate,所有的目标共享多个expert,每个expert通常是数层规模比较小的全连接层。gate用来选择每个expert的信号占比。每个expert都有其擅长的预测方向,最后共同作用于上面的多个目标,MMoE可以形式化表达为:
其中,\(g^k\)是第\(k\)个任务中组合experts结果的门控网络(gating network),注意每一个任务都有一个独立的门控网络。它的输入是input feature,输出就是所有Experts上的权重
一方面,因为gating networks通常是轻量级的,而且expert networks是所有任务共用,所以相对于论文中提到的一些baseline方法在计算量和参数量上具有优势
另一方面,MMoE其实是MoE针对多任务学习的变种和优化,相对于OMoE的结构中所有任务共享一个门控网络,MMoE的结构优化为每个任务都单独使用一个门控网络。这样的改进可以针对不同任务得到不同的Experts权重,从而实现对Experts的选择性利用,不同任务对应的门控网络可以学习到不同的Experts组合模式,因此模型更容易捕捉到子任务间的相关性和差异性
三. 推荐里面为什么需要引入多任务学习
在搜索和推荐等信息检索场景下,最基础的一个目标就是用户的CTR,即用户看见了一篇内容之后会不会去点击阅读。但其实用户在产品上的行为是多种多样的。比如用户可以点赞、收藏、分享评论等,此类行为需要模型通过统一的范式标准进行衡量
虽然可以对用户的CTR进行单个目标的优化,但是这样的做法也会带来负面影响:靠用户点击这个行为推荐出来的内容并不一定是用户非常满意的内容,比如有人可能看到一些热门的内容就会去点击,或者看到一些阅读门槛低的内容,像一些引发讨论的热点事件、社会新闻,或者是一些轻松娱乐的内容,用户也会点击。这样造成的后果就是:CTR的指标非常高,但是用户接收到的推荐结果并不是他们最满意的
如果我们深入思考会发现,用户的每种行为一定程度上都代表了某个内容是否能满足他不同层面的需求。比如说点击,代表着用户在这个场景下,想要看这个内容;赞同,代表用户认为这个内容其实写的很不错;收藏,代表这个内容对用户特别有用,要把它收藏起来,要仔细的去看一看;分享,代表用户希望其他的人也能看到这个内容
而单目标CTR优化到了一个比较高的点之后,用户的阅读量虽然上去了,但是其他的各种行为(收藏、点赞、分享等等)是下降的。这个下降代表着:用户接收到太多的东西是他认为不实用的。于是,推荐系统研究者开始思考:能不能预估用户在其他行为上的概率?这些概率实际上就是模型要学习的目标,多种目标综合起来,包括阅读、点赞、收藏、分享等等一系列的行为,归纳到一个模型里面进行学习,这就是推荐系统的多目标学习
做推荐算法肯定绕不开多目标。点击率模型、时长模型和完播率模型是大部分信息流产品推荐算法团队都会尝试去做的模型。单独优化点击率模型容易推出来标题党,单独优化时长模型可能推出来的都是长视频或长文章,单独优化完播率模型可能短视频短图文就容易被推出来,所以多目标就应运而生。多目标排序就是有多个目标函数,找到一种排序方法使得多个目标都达到整体最优
四. 推荐系统领域中多任务学习的应用
4.1 ESSM——阿里妈妈
ESMM模型利用用户行为序列数据在完整样本空间建模,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。另一方面,ESMM模型的贡献在于其提出的利用学习CTR和CTCVR的辅助任务,迂回地学习CVR的思路。ESMM模型中的BASE子网络可以替换为任意的学习模型,因此ESMM的框架可以非常容易地和其他学习模型集成,从而吸收其他学习模型的优势,进一步提升学习效果,想象空间巨大
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate——SIGIR-2018
动机:传统的CVR预估问题存在着两个主要的问题:样本选择偏差和稀疏数据。下面的图中,把给用户曝光过的产品看作是整个样本空间\(X\)的话,用户点击过的产品仅是中间灰色的部分,定义为\(X_c\),而用户购买过的产品仅是图中黑色的部分
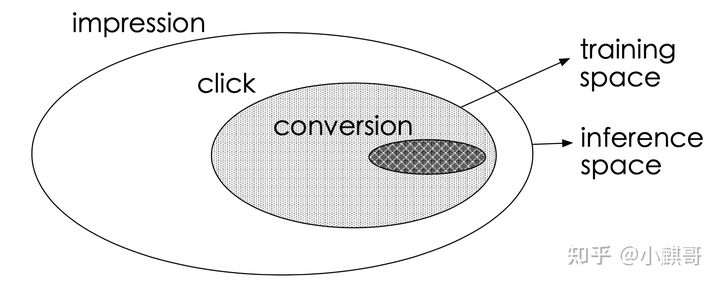
样本选择偏差(sample selection bias, SSB):传统的推荐系统仅用\(X_c\)中的样本来训练CVR预估模型,但训练好的模型是在整个样本空间\(X\)去做推断的。由于点击事件相对于曝光事件来说要少很多,因此只是样本空间\(X\)的一个很小的子集,从\(X_c\)上提取的特征相对于从X中提取的特征而言是有偏的,甚至是很不相同。从而,按这种方法构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中独立同分布的假设。这种训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。样本选择偏差会伤害学到的模型的泛化性能
数据稀疏(data sparsity, DS):推荐系统展现给用户的商品数量要远远大于被用户点击的商品数量,同时有点击行为的用户也仅仅只占所有用户的一小部分,因此有点击行为的样本空间\(X_c\)相对于整个样本空间\(X\)来说是很小的,在淘宝公开的训练数据集上,\(X_c\)只占整个样本空间\(X\)的4%,高度稀疏的训练数据使得模型的学习变得相当困难
模型结构:ESMM模型借鉴了多任务学习的思路,引入了两个辅助的学习任务,分别用来拟合\(pCTR\)和\(pCTCVR\),从而同时消除了上文提到的两个挑战。ESMM模型能够充分利用用户行为的顺序性模式,其模型架构下图所示:
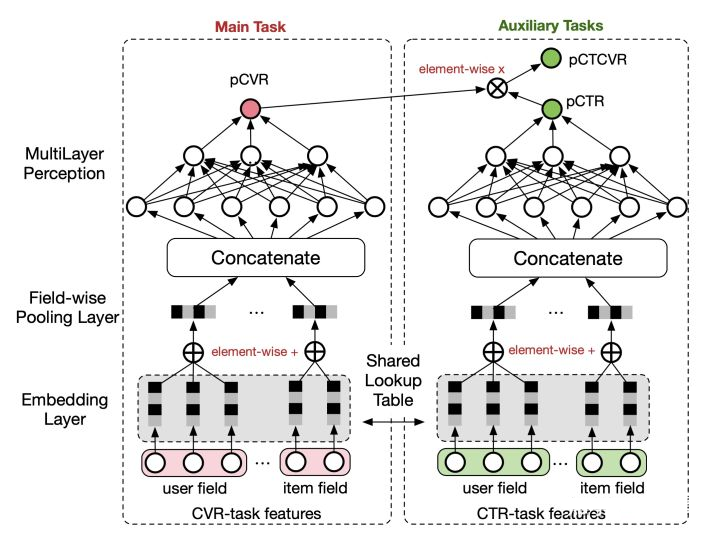
可以看到,ESSM模型由两个子网络组成,左边的子网络用来拟合\(pCVR\),右边的子网络用来拟合\(pCTR\),同时,两个子网络的输出相乘之后可以得到\(pCTCVR\)。因此,该网络结构共有三个子任务,分别用于输出\(pCTR\)、\(pCVR\)和\(pCTCVR\)。假设用\(x\)表示feature(即impression),\(y\)表示点击,\(z\)表示转化,那么根据\(pCTCVR = pCTR*pCVR\),可以得到\(p(y=1,z=1|x)=p(y=1|x)×p(z=1|y=1,x)\)
将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本,来做\(CTR\)预估的任务。将同时有点击行为和购买行为的曝光事件作为正样本,其他作为负样本来训练\(CTCVR\)的预估部分。用来训练两个任务的输入\(x\)其实是相同的,但是\(label\)是不同的。\(CTR\)任务预估的是点击\(y\),\(CTCVR\)预估的是转化\(z\)。因此,将\((x,y)\)输入到\(CTR\)任务中,得到\(CTR\)的预估值,将\((x,z)\)输入到\(CVR\)任务中,得到\(CVR\)的预估值,\(CTR\)和\(CVR\)的预估值相乘,便得到了\(CTCVR\)的预估值。因此,模型的损失函数可以定义为:
其中,\(\theta_{ctr}\)和\(\theta_{cvr}\)分别是CTR网络和CVR网络的参数,\(l(⋅)\)是交叉熵损失函数
ESMM模型借鉴迁移学习的思路,在两个子网络的embedding层共享embedding向量(特征表示)词典。网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于\(CTR\)任务的训练样本量要大大超过\(CVR\)任务的训练样本量,ESMM模型中特征表示共享的机制能够使得\(CVR\)子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
def ESMM(dnn_feature_columns, tower_dnn_hidden_units=(256, 128, 64), l2_reg_embedding=0.00001, l2_reg_dnn=0,
seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False, task_types=('binary', 'binary'),task_names=('ctr', 'ctcvr')):
features = build_input_features(dnn_feature_columns)
inputs_list = list(features.values())
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,l2_reg_embedding, seed)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
ctr_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
cvr_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
ctr_logit = Dense(1, use_bias=False)(ctr_output)
cvr_logit = Dense(1, use_bias=False)(cvr_output)
ctr_pred = PredictionLayer('binary', name=task_names[0])(ctr_logit)
cvr_pred = PredictionLayer('binary')(cvr_logit)
ctcvr_pred = Multiply(name=task_names[1])([ctr_pred, cvr_pred]) # CTCVR=CTR*CVR
model = Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
return model
4.2 MMOE——谷歌大脑
MMoE(Multi-gate Mixture-of-Experts)是一种新颖的的多任务学习结构。MMoE 模型刻画了任务相关性,基于共享表示来学习特定任务的函数,避免了明显增加参数的缺点。
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts——KDD2018
MoE(Mixture of Experts) 由许多“专家”组成,每个“专家”都有一个简单的前馈神经网络和一个可训练的门控网络(gating network),该门控网络选择“专家”的一个稀疏组合来处理每个输入,它可以实现自动分配参数以捕获多个任务可共享的信息或是特定于某个任务的信息,而无需为每个任务添加很多新参数,而且网络的所有部分都可以通过反向传播一起训练。其底层由一个长度为\(N\)的\(gate\)向量\(G(x)\)和\(N\)个\(expert\)向量\(Ei(x)\)组成,运行流程如下:
- 每个\(expert\)共享底层输入\(x\),其中第\(i\)个\(expert\)经过若干全连接层后得到对应的\(E_i(x)\)
- \(E_i(x)\)与\(gate\)向量的第\(i\)维向量相乘得到加权输出$G(x)_i * E_i(x) $
- 将所有的加权输出相加得到最终的输出,\(y=\sum_i^N G(x)_i * E_i(x)\)
- 将\(y\)输入到指定塔,经过若干全连接层后得到塔的最终输出。
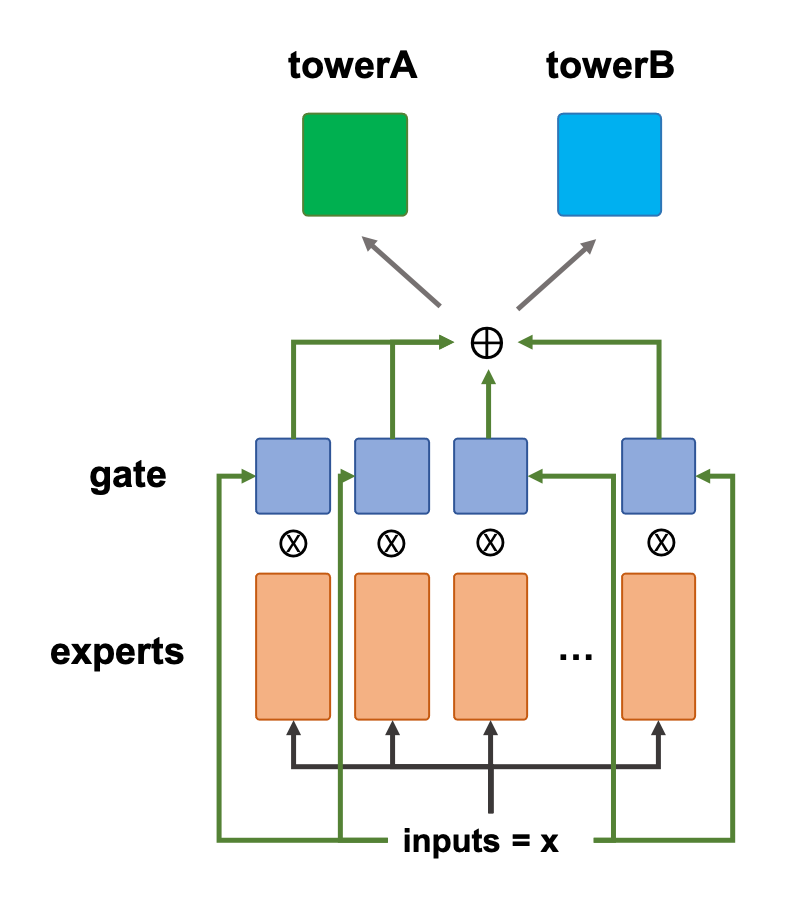
这里需要注意的是,某一个\(x\)计算的结果只会输出到某一个塔上,且不同的\(x\)会对应不同的\(G(x)\)和\(E(x)\),MOE模型中,由\(gate\)来控制\(experts\)的输出,从而动态地决定哪些\(experts\)对某一个塔比较重要,这样即使不同塔的相似较低,\(experts\)也能够学习地较好,因为每个\(expert\)的学习是相互独立的,MMOE是MOE的升级版。它的改进手段相对直观,具体来说,把原先单一\(gate\)向量变为\(M\)个\(gate\)向量,\(M\)为塔的个数,示意图如下所示:
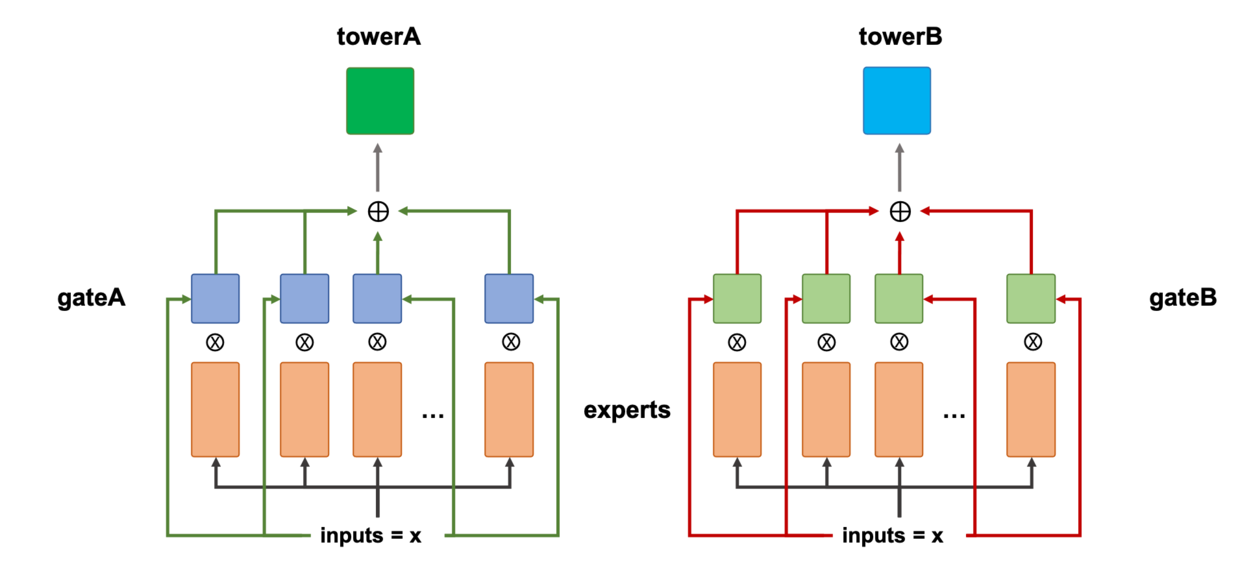
这里需要注意的是,上图中towerA和towerB所用到的experts是同一套experts。可以看出,MMOE对\(gates\)和\(experts\)做了进一步的解耦,模型对于不同相似度塔的协同学习处理的更好,而且更重要的一点在于MMOE能够得到\(x\)相对于每一个塔的得分,这是一个很大的进步
def MMOE(dnn_feature_columns, num_experts=3, expert_dnn_hidden_units=(256, 128), tower_dnn_hidden_units=(64,), gate_dnn_hidden_units=(), l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False, task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr')):
num_tasks = len(task_names)
features = build_input_features(dnn_feature_columns)
inputs_list = list(features.values())
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding, seed)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
# build expert layer
expert_outs = []
for i in range(num_experts):
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_' + str(i))(dnn_input)
expert_outs.append(expert_network)
expert_concat = Lambda(lambda x: tf.stack(x, axis=1))(expert_outs)
mmoe_outs = []
for i in range(num_tasks): # one mmoe layer: nums_tasks = num_gates
# build gate layers
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed,name='gate_' + task_names[i])(dnn_input)
gate_out = Dense(num_experts, use_bias=False, activation='softmax',name='gate_softmax_' + task_names[i])(gate_input)
gate_out = Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
# gate multiply the expert
gate_mul_expert = Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False), name='gate_mul_expert_' + task_names[i])([expert_concat, gate_out])
mmoe_outs.append(gate_mul_expert)
task_outs = []
for task_type, task_name, mmoe_out in zip(task_types, task_names, mmoe_outs):
# build tower layer
tower_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_' + task_name)(mmoe_out)
logit = Dense(1, use_bias=False)(tower_output)
output = PredictionLayer(task_type, name=task_name)(logit)
task_outs.append(output)
model = Model(inputs=inputs_list, outputs=task_outs)
return model
4.3 PLE——腾讯 PCG
PLE,主要是在MMoE的基础上,为每个任务增加了自己的specific expert,仅由本任务对其梯度更新,解决了MTL中的seesaw phenomenon(跷跷板现象)
A Novel Multi-Task Learning (MTL) Model for Personalized Recommendation——Recsys 2020
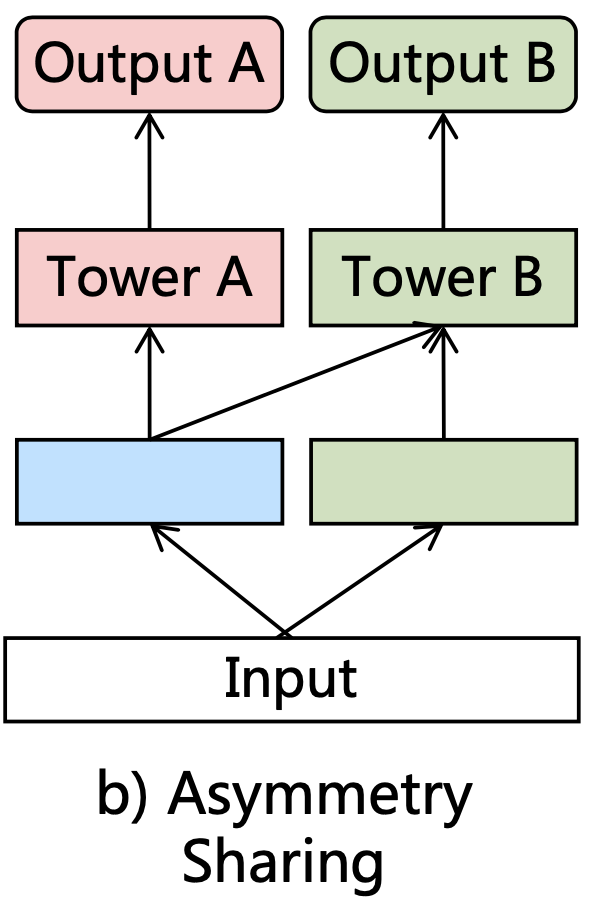
非对称参数共享(Asymmetric Sharing):在MTL中,前人做过很多工作用来处理negative-transfer问题,例如:cross-stitchnetwork,sluice network。用来学习如何把不同的task的表达(representations)线性地融合起来。这里的组合方式是偏静态的方式,比如静态权重超参数,下图是PLE基于hard-sharing的非对称参数共享结构,有一部分信息可以被共享,另一部分信息被独享。其信息融合方式包括 concatenation,sum-polling,average-pooling
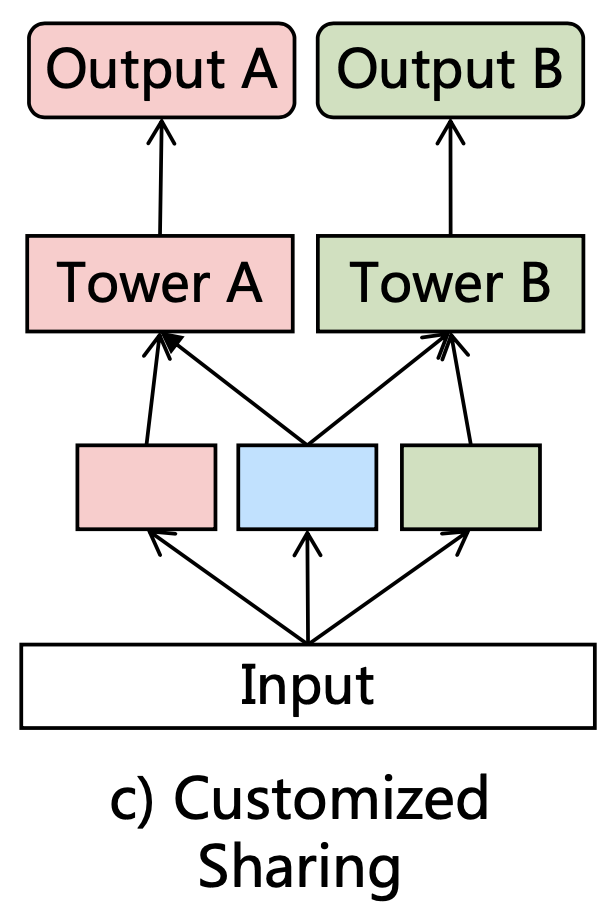
定制分享(Customized Sharing):下图的结构中,两个塔各自有一个独有的\(expert\),并且还有一个共享的\(expert\)(浅蓝色)。显式分离shared和task-specific参数来避免可能存在的内在冲突和negative transfer。对比single-task模型,增加了一个抽取共享信息的底层网络,并和task-specific层concat起来输入到各自的tower layer
定制门控网络(Customized Gate Control, CGC):CGC 是 PLE 的基础网络。CGC和上面的Customized Sharing网络的区别在于增加了一个门控网络,相似点在于也将task-common和task-specific分离。由第一节的“跷跷板现象”图中可以看到,Customized Sharing网络的结果和 Single Task 很相近,因此可以使用Customized Sharing作为基础结构,以便于体现后面提到的Task-specific的作用
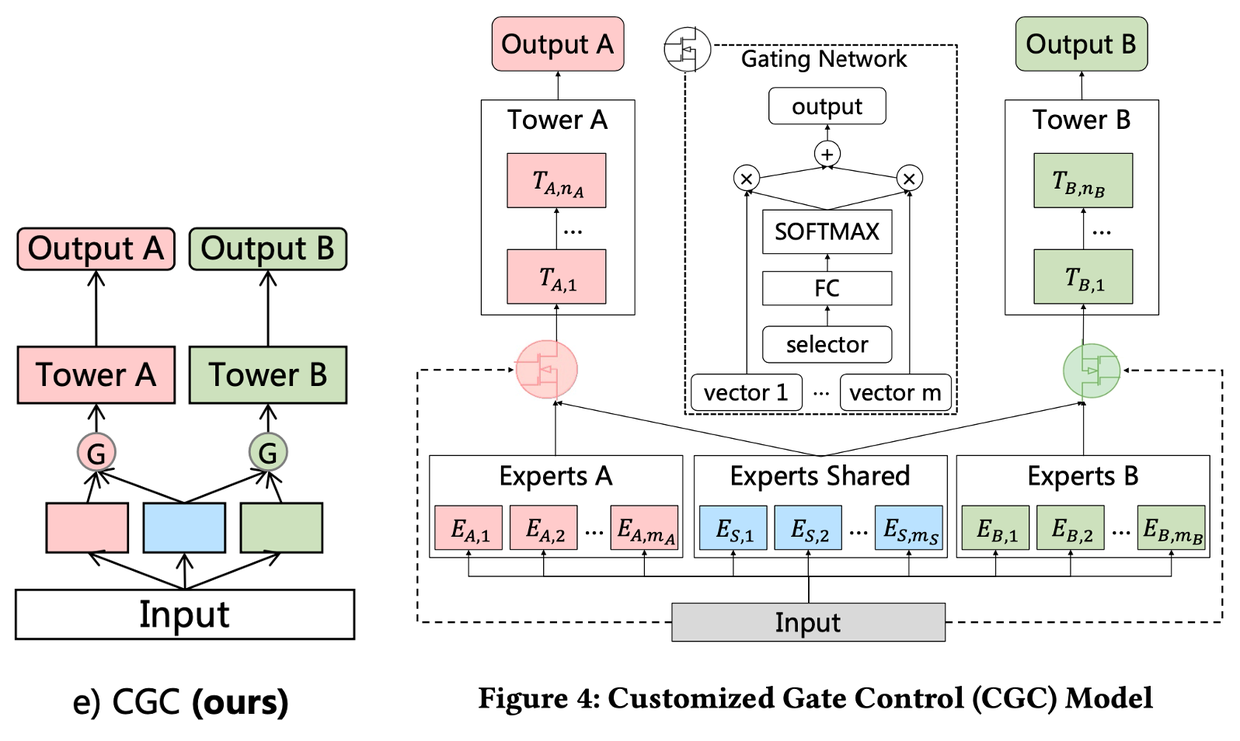
- 底层网络:包含一些expert模块, 每个expert模块由若干子网络(sub-networks)构成,这些子网络称作experts,每个模块包含多少个expert是可调节的超参。其中shared experts负责学习shared patterns,task-specific experts负责学习task-specific patterns
- 上层网络:一些task-specific塔 ,网络的宽度和深度都是可调节的超参。每个塔同时从shared experts和各自的task-specific experts中学习知识
- 门控网络:Shared experts和task-specific experts的信息通过门控网络进行融合。门控网络的结构为单层的前向网络,激活函数为softmax 函数
第\(k\)个子任务的门控网络输出为:\(g^{k}(x)=w^{k}(x) S^{k}(x)\) ,其中\(x\)是输入的向量表达(representations),\(w^k(x)=softmax(W_g^kx)\),\(W_g^k∈R^{(m_k+m_s)×d}\)。\(S^k(x)\)是一个选择矩阵,把shared experts和第\(k\)个子任务的specific experts串接(concat)起来。
最终第\(k\)个子任务的预估值为\(y^k(x)=t^k(g^k(x))\),其中\(t^k\)表示第\(k\)个子任务的上层塔网络。对比MMoE,CGC去掉了子任务塔和其他task-specific experts的连接,这就使得不同类型\(experts\)可以专注于更高效地学习不同的知识且避免不必要的交互。另外,得益于门控网络动态地融合输入,CGC可以更灵活地在不同子任务之间找到平衡且更好地处理任务之间的冲突和样本相关性问题
PLE(Progressive Layer Extraction):PLE是CGC的一个多层拓展,还利用了一个新颖的progressive seperation routing机制
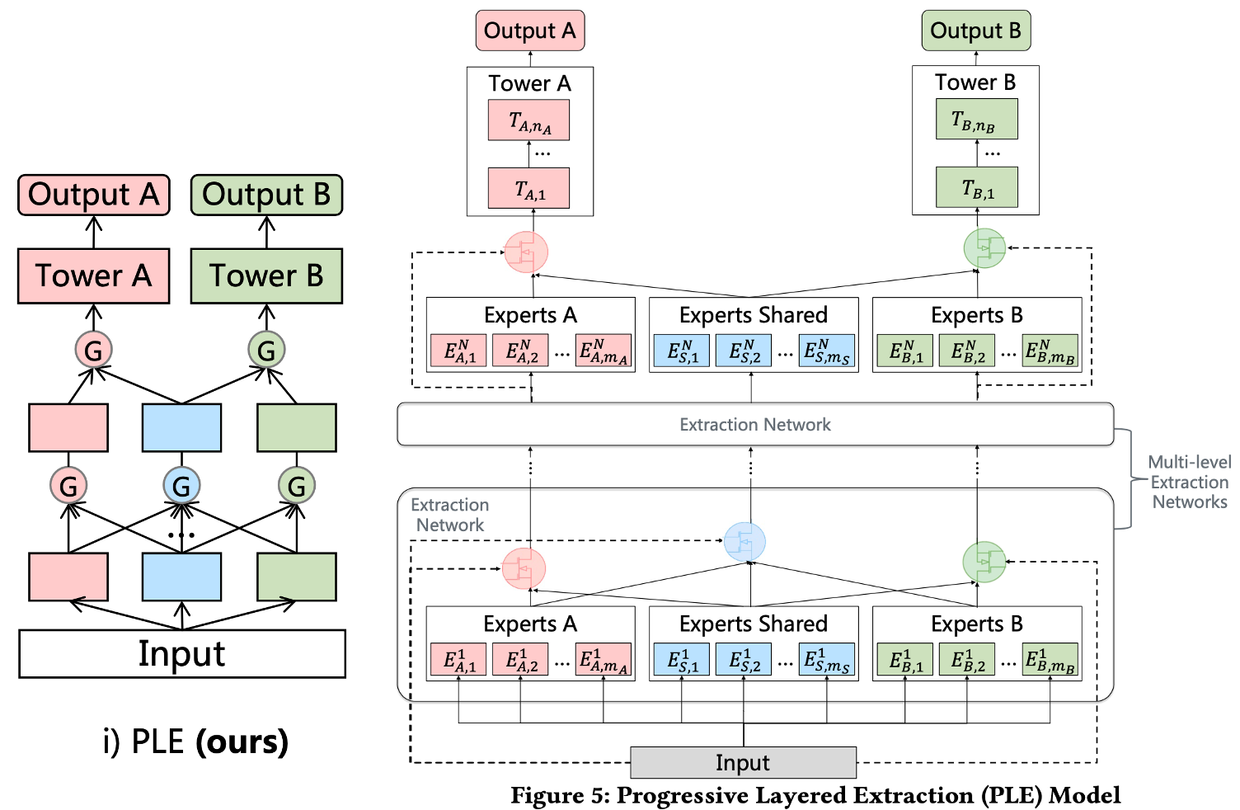
PLE利用多层网络抽取高阶的共享信息。除了 task-specific experts 有门控网络,抽取网络也对当前层所有的 experts 利用门控网络来融合得到新的 shared experts。因此,PLE的 early 层没有完全把子任务的参数区分开,而是在 upper 层逐渐地分离。底层的抽取网络对于高层的抽取网络来说,是代替CGC中原始输入的存在,而这个替代可以带来更多的信息有助于更高层网络的学习。
PLE 的第\(k\)个子任务的第\(j\)个提取网络中门控网络的定义:\(g^{k,j}(x)=w^{k,j}(g^{k,j−1}(x))S^{k,j}(x)\),计算完所有的门控网络和\(experts\),PLE的第\(k\)个子任务的最终输出为:\(y^k(x)=t^k(g^{k,N}(x))\)。正因为有了多层的\(experts\)和gating networks,PLE 可以抽取并融合每个子任务更深的表达来提升泛化性。
Routing 策略在MMoE中是全连接层,在CGC中是early separation。PLE采用一种渐进式分离routing的方案来从所有的底层\(experts\)中获取信息,抽取成高阶的共享知识,并逐渐分离task-specific参数
损失函数:一般来说,MTL的损失函数的设计方式是,针对不同的子任务,设置不同的权重,而后再把所有子任务的损失按照权重加权得到。\(L(θ_1,……,θ_K,θ_s)=\sum_{k=1}^Kω_kL_k(θ_k,θ_s)\),其中\(θ_s\)表示共享参数(shared parameters),\(K\)是子任务的个数。\(L_{k},\omega_{k},\theta_{k}\)分别表示第\(k\)个任务的损失函数、损失函数的权重、task-specific 的参数
-
解决样本空间不一致的问题。用户的行为有序列性导致样本空间是异构的,比如用户只有点击后才能进行分享和评论。解决样本空间不一致的问题,而本文则是在 Loss 上进行一定的优化,联合训练这些任务,在计算每个任务的损失时需要把样本空间相同的合并,并忽略不在自己样本空间的样本,即不同的任务仍使用其各自样本空间中的样本。\(L_k(θ_k,θ_s)=\frac{1}{\sum_i\delta_{k}^{i}}\sum _i\delta_{k}^{i}loss_k(\hat y_k^i(θ_k,θ_s),y_k^i)\),其中\(\delta_{k}^{i}\)取值为0或1,表示第$i \(个样本是否属于第\)k $个任务的样本空间
-
其次是不同任务之间权重的优化。MTL 模型的效果在训练过程中对损失的权重(loss weight)的选择敏感。不同子任务可能在不同的训练阶段有不同的重要性。关于MTL的权重设置,最常见的是人工设置,这需要不断的尝试来探索最优的权重组合,另一种则是阿里提出的通过帕累托最优来计算优化不同任务的权重。本文则使用动态调整的方式,首先对第\(k\)个子任务设置一个初始值,之后每一步根据跟新率\(\gamma_k\)更新它的损失的权重(loss weight)\(ω_k^{(t)}=ω_{k,0}×γ_k^t\),其中\(t\)表示训练的 epoch,其他两个都是超参
def PLE(dnn_feature_columns, shared_expert_num=1, specific_expert_num=1, num_levels=2, expert_dnn_hidden_units=(256,), tower_dnn_hidden_units=(64,), gate_dnn_hidden_units=(), l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False, task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr')):
num_tasks = len(task_names)
features = build_input_features(dnn_feature_columns)
inputs_list = list(features.values())
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding, seed)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
# single Extraction Layer
def cgc_net(inputs, level_name, is_last=False):
# inputs: [task1, task2, ... taskn, shared task]
specific_expert_outputs = []
# build task-specific expert layer
for i in range(num_tasks):
for j in range(specific_expert_num):
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name + 'task_' + task_names[i] + '_expert_specific_' + str(j))(inputs[i])
specific_expert_outputs.append(expert_network)
# build task-shared expert layer
shared_expert_outputs = []
for k in range(shared_expert_num):
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name + 'expert_shared_' + str(k)) inputs[-1])
shared_expert_outputs.append(expert_network)
# task_specific gate (count = num_tasks)
cgc_outs = []
for i in range(num_tasks):
# concat task-specific expert and task-shared expert
cur_expert_num = specific_expert_num + shared_expert_num
# task_specific + task_shared
cur_experts = specific_expert_outputs[ i * specific_expert_num:(i + 1) * specific_expert_num] + shared_expert_outputs
expert_concat = Lambda(lambda x: tf.stack(x, axis=1))(cur_experts)
# build gate layers
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name + 'gate_specific_' + task_names[i])( inputs[i]) # gate[i] for task input[i]
gate_out = Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name + 'gate_softmax_specific_' + task_names[i])(gate_input)
gate_out = Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
# gate multiply the expert
gate_mul_expert = Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False), name=level_name + 'gate_mul_expert_specific_' + task_names[i])( [expert_concat, gate_out]) cgc_outs.append(gate_mul_expert)
# task_shared gate, if the level not in last, add one shared gate
if not is_last:
cur_expert_num = num_tasks * specific_expert_num + shared_expert_num
cur_experts = specific_expert_outputs + shared_expert_outputs # all the expert include task-specific expert and task-shared expert
expert_concat = Lambda(lambda x: tf.stack(x, axis=1))(cur_experts)
# build gate layers
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name + 'gate_shared')(inputs[-1]) # gate for shared task input
gate_out = Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name + gate_softmax_shared')(gate_input)
gate_out = Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
# gate multiply the expert
gate_mul_expert = Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False),name=level_name + 'gate_mul_expert_shared')([expert_concat, gate_out])
cgc_outs.append(gate_mul_expert)
return cgc_outs
# build Progressive Layered Extraction
ple_inputs = [dnn_input] * (num_tasks + 1) # [task1, .. taskn, shared task]
ple_outputs = []
for i in range(num_levels):
if i == num_levels - 1: # the last level
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_' + str(i) + '_', is_last=True)
else:
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_' + str(i) + '_', is_last=False)
ple_inputs = ple_outputs
task_outs = []
for task_type, task_name, ple_out in zip(task_types, task_names, ple_outputs):
# build tower layer
tower_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed,
name='tower_' + task_name)(ple_out)
logit = Dense(1, use_bias=False)(tower_output)
output = PredictionLayer(task_type, name=task_name)(logit)
task_outs.append(output)
model = Model(inputs=inputs_list, outputs=task_outs)
return model
本文来自博客园,作者:晓柒NLP,转载请注明原文链接:https://www.cnblogs.com/happyNLP/p/16880714.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号