部署Hadoop-3.0-高性能集群
一、Hadoop概述:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS分布式文件系统为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
网方网站:http://hadoop.apache.org/
Hadoop是一个由Apache基金会所开发的分布式系统基础架构
hadoop基于java开的。
Hadoop包括两大核心,分布式存储系统和分布式计算系统。
分布式存储
为什么数据需要存储在分布式的系统中哪,难道单一的计算机存储不了吗,难道现在的几个TB的硬盘装不下这些数据吗?事实上,确实装不下。比如,很多的电信通话记录就存储在很多台服务器的很多硬盘中。那么,要处理这么多数据,必须从一台一台服务器分别读取数据和写入数据,太麻烦了!
我们希望有一种文件系统,可以管辖很多服务器用于存储数据。通过这个文件系统存储数据时,感觉不到是存储到不同的服务器上的。当读取数据时,感觉不到是从不同的服务器上读取。
如图:这就是分布式文件系统。
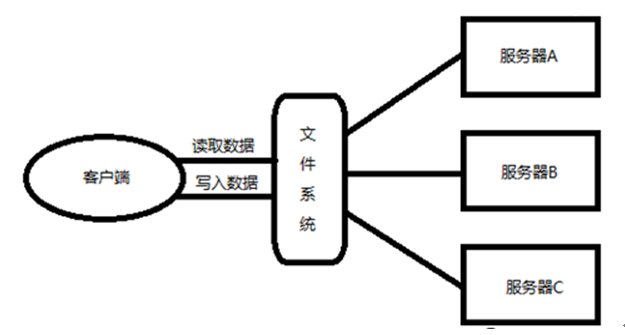
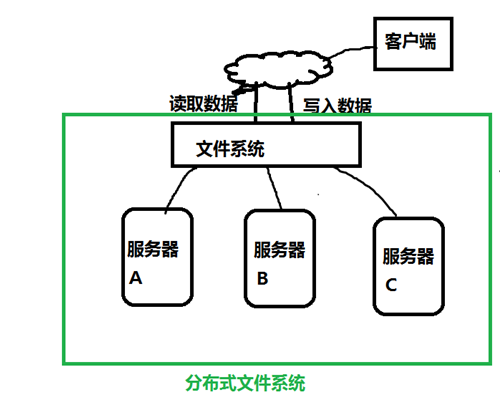
分布式文件系统管理的是一个服务器集群。在这个集群中,数据存储在集群的节点(即集群中的服务器)中,但是该文件系统把服务器的差异屏蔽了。那么,我们就可以像使用普通的文件系统一样使用,但是数据却分散在不同的服务器中。
命名空间(namespace):在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件,为了组织众多的文件,把文件可以放到不同的文件夹中,文件夹可以一级一级的包含。我们把这种组织形式称为命名空间(namespace)。命名空间管理着整个服务器集群中的所有文件。命名空间的职责与存储真实数据的职责是不一样的。
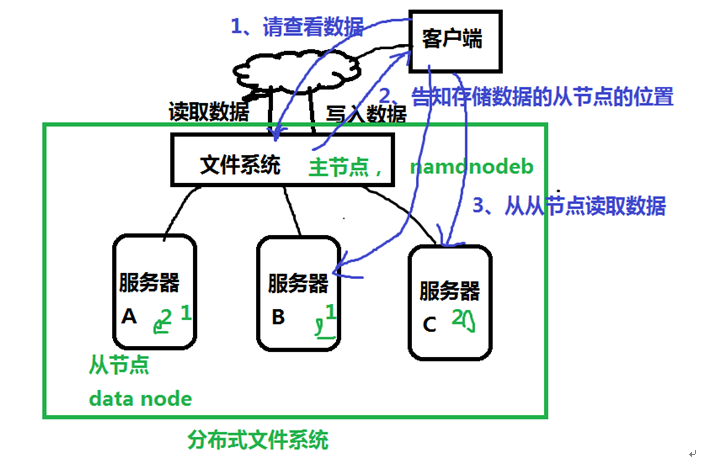
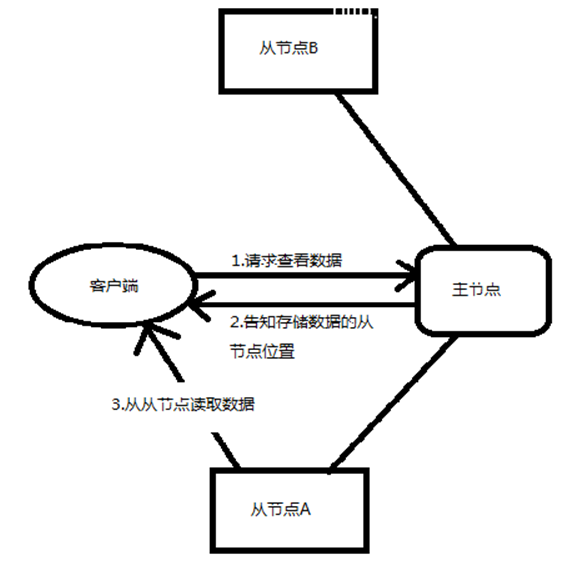
负责命名空间职责的节点称为主节点(master node),负责存储真实数据职责的节点称为从节点(slave node)。
主/从节点:主节点负责管理文件系统的文件结构,从节点负责存储真实的数据,称为主从式结构(master-slaves)。用户操作时,也应该先和主节点打交道,查询数据在哪些从节点上存储,然后再从从节点读取。在主节点,为了加快用户访问的速度,会把整个命名空间信息都放在内存中,当存储的文件越多时,那么主节点就需要越多的内存空间。
block:在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一个独立的存储文件单位,称为块(block)。
容灾: 数据存放在集群中,可能因为网络原因或者服务器硬件原因造成访问失败,最好采用副本(replication)机制,把数据同时备份到多台服务器中,这样数据就安全了,数据丢失或者访问失败的概率就小了。
如图:
工作流程图:

名词解释
(1)Hadoop:Apache开源的分布式框架。
(2)HDFS:Hadoop的分布式文件系统。
(3)NameNode:Hadoop HDFS元数据主节点服务器,负责保存DataNode 文件存储元数据信息,这个服务器是单点的。
(4)JobTracker:Hadoop的Map/Reduce调度器,负责与TaskTracker通信分配计算任务并跟踪任务进度,这个服务器也是单点的。
(5)DataNode:Hadoop数据节点,负责存储数据。
(6)TaskTracker:Hadoop调度程序,负责Map,Reduce任务的启动和执行。
Namenode记录着每个文件中各个块所在的数据节点的位置信息
Hadoop1的组件依赖关系图
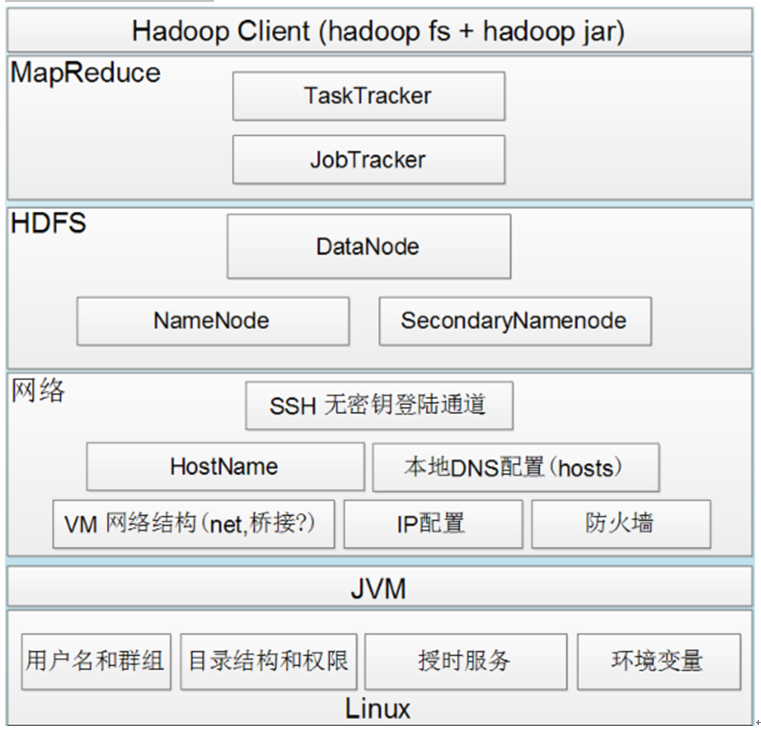
在以上的主从式结构中,由于主节点含有整个文件系统的目录结构信息,因为非常重要。另外,由于主节点运行时会把命名空间信息都放到内存中,因此存储的文件越多,主节点的内存就需要的越多。
在hadoop中,分布式存储系统称为HDFS(hadoop distributed file system)。其中,主节点称为名字节点(namenode),从节点称为数据节点(datanode)。
分布式计算:
对数据进行处理时,我们会把数据读取到内存中进行处理。如果我们对海量数据进行处理,比如数据大小是100GB,我们要统计文件中一共有多少个单词。要想把数据都加载到内存中几乎是不可能的,称为移动数据。那么是否可以把程序代码放到存放数据的服务器上哪?因为程序代码与原始数据相比,一般很小,几乎可以忽略的,所以省下了原始数据传输的时间了。现在,数据是存放在分布式文件系统中,100GB的数据可能存放在很多的服务器上,那么就可以把程序代码分发到这些服务器上,在这些服务器上同时执行,也就是并行计算,也是分布式计算。这就大大缩短了程序的执行时间。我们把程序代码移动到数据节点的机器上执行的计算方式称为移动计算。分布式计算需要的是最终的结果,程序代码在很多机器上并行执行后会产生很多的结果,因此需要有一段代码对这些中间结果进行汇总。
Hadoop中的分布式计算一般是由两阶段完成的。第一阶段负责读取各数据节点中的原始数据,进行初步处理,对各个节点中的数据求单词数。然后把处理结果传输到第二个阶段,对中间结果进行汇总,产生最终结果,求出100GB文件总共有多少个单词,如图所示:
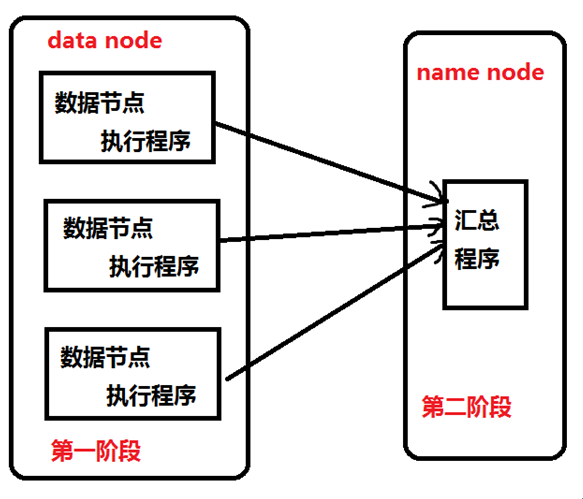
在hadoop中,分布式计算部分称为MapReduce。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
主节点称为作业节点(job tracker),
从节点称为任务节点(task tracker)。
在任务节点中,运行第一阶段的代码称为map任务(map task),运行第二阶段的代码称为reduce任务(reduce task)。
task [英] [tɑ:sk] 任务
tracker [英] [ˈtrækə(r)] 跟踪器
下载jdk1.8 for Linux压缩包,hadoop3.0.0压缩包。下载链接分别如下:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
http://hadoop.apache.org/releases.html
二、实战:搭建Hadoop集群:

实验环境
安装前,3台虚拟机IP及机器名称如下:
主机名 IP地址 角色
xuegod63.cn 192.168.1.63 NameNode
xuegod64.cn 192.168.1.64 DataNode1
xuegod62.cn 192.168.1.62 DataNode2
1.实验前期环境准备:
(1)三台机器上配置hosts文件,如下:
[root@xuegod63 ~]# vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.63 xuegod63.cn 192.168.1.64 xuegod64.cn 192.168.1.62 xuegod62.cn
(2)复制hosts到其它两机器:
[root@xuegod63 ~]# scp /etc/hosts root@192.168.1.64:/etc/ [root@xuegod63 ~]# scp /etc/hosts root@192.168.1.62:/etc/ 注意:在/etc/hosts中,不要把机器名字,同时对应到127.0.0.1这个地址,否则会导致数据节点连接不上namenode,报错如下: org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.1.10:9000
(3)创建运行hadoop用户账号和Hadoop目录。 尽量不用root帐号运行
xuegod63: [root@xuegod63 ~]# useradd -u 8000 hadoop #为了保障,在其它服务器上创建的hadoop用户ID保持一致,创建时,尽量把UID调大 [root@xuegod63 ~]# echo 123456 | passwd --stdin hadoop [root@xuegod64 ~]# useradd -u 8000 hadoop [root@xuegod64 ~]# echo 123456 | passwd --stdin hadoop [root@xuegod62 ~]# useradd -u 8000 hadoop [root@xuegod62 ~]# echo 123456 | passwd --stdin hadoop 注:创建用户hadoop时,不能使用参数-s /sbin/nologin ,因为稍后我们要su - hadoop 切换用户
(4)给hadoop账户增加sudo权限: vim /etc/sudoers ,增加内容:
[root@xuegod63 ~]# vim /etc/sudoers
hadoop ALL=(ALL) ALL
注意:以上对于每一台机器都要执行
配置在xuegod63上,可以ssh无密码登录机器xuegod63,xuegod64,xuegod62 ,方便后期复制文件和启动服务。因为namenode启动时,会连接到datanode上启动对应的服务。
生成公钥和私钥
注意:切换到hadoop用户再操作
[root@xuegod63 ~]# su - hadoop [hadoop@xuegod63 ~]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: b6:be:c5:0f:d5:70:52:cf:5f:7a:a4:c1:bd:26:b9:84 root@xuegod63.cn The key's randomart image is: +--[ RSA 2048]----+ | . | | o + | | o + *| | .=.=+| | S E.++oo| | . o .. +. | | . + . | | . . o | | o. . | +-----------------+ 导入公钥到其他datanode节点认证文件 [hadoop@xuegod63 ~]$ ssh-copy-id root@192.168.1.62 [hadoop@xuegod63 ~]$ ssh-copy-id root@192.168.1.64
2、配置Hadoop环境
1. xuegod63安装Java环境JDK:三台机器上都要配置
上传jdk-8u161-linux-x64.rpm软件包到xuegod63
1、解压到对应的文件夹 [root@xuegod63 ~]# tar zxf jdk-linux-x64.tar.gz -C /usr/local/ [root@xuegod63 ~]# vim /etc/profile #在文件的最后添加以下内容: JAVA_HOME=/usr/local/jdk1.8.0_131 PATH=$JAVA_HOME/bin:$PATH CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar export PATH JAVA_HOME CLASSPATH [root@xuegod63 ~]# source /etc/profile #使配置文件生效 验证java运行环境是否安装成功: [root@xuegod63 ~]# java -version java version "1.8.0_161" Java(TM) SE Runtime Environment (build 1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode) 如果出现安装的对应版本,说明java运行环境已经安装成功。 注:这里只是升级了jdk的版本,因为在我安装的系统中已经安装了jdk。 将jdk部署到其它两台机器上: [root@xuegod63 ~]# scp jdk-8u161-linux-x64.rpm root@192.168.1.62:/root [root@xuegod63 ~]# scp jdk-8u161-linux-x64.rpm root@192.168.1.64:/root [root@xuegod63 ~]# scp /etc/profile 192.168.1.62:/etc/profile [root@xuegod63 ~]# scp /etc/profile 192.168.1.64:/etc/profile 安装: [root@xuegod64 ~]# rpm -ivh jdk-8u161-linux-x64.rpm [root@xuegod62 ~]# rpm -ivh jdk-8u161-linux-x64.rpm 重新参加java运行环境: [root@xuegod64 ~]# source /etc/profile [root@xuegod62 ~]# source /etc/profile 测试: [root@xuegod64 ~]# java -version java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b14) Java HotSpot(TM) 64-Bit Server VM (build 24.71-b01, mixed mode) [root@xuegod62 ~]# java -version java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b14) Java HotSpot(TM) 64-Bit Server VM (build 24.71-b01, mixed mode) 三台机器关闭防火墙: [root@xuegod63 ~]# systemctl stop firewalld.service [root@xuegod63 ~]# systemctl disable firewalld.service [root@xuegod62 ~]# systemctl stop firewalld.service [root@xuegod62 ~]# systemctl disable firewalld.service [root@xuegod64 ~]# systemctl stop firewalld.service [root@xuegod64 ~]# systemctl disable firewalld.service
2.在xuegod63安装Hadoop 并配置成namenode主节点
Hadoop安装目录:/home/hadoop/hadoop-3.0.0 使用root帐号将hadoop-3.0.0.tar.gz 上传到服务器 [root@xuegod63 ~]# mv hadoop-3.0.0.tar.gz /home/hadoop/ 注意:以下步骤使用hadoop账号操作。 [root@xuegod63 ~]# su - hadoop [hadoop@xuegod63 ~]$ tar zxvf hadoop-3.0.0.tar.gz #只要解压文件就可以,不需要编译安装 创建hadoop相关的工作目录 [hadoop@xuegod63 ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp [hadoop@xuegod623 ~]$ ls dfs hadoop-3.0.0 hadoop-3.0.0.tar.gz tmp
3. 配置Hadoop:需要修改7个配置文件。
文件位置:/home/hadoop/hadoop-3.0.0/etc/hadoop/
文件名称:hadoop-env.sh、yarn-evn.sh、workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
1、配置文件hadoop-env.sh,指定hadoop的java运行环境
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/hadoop-env.sh 改:54 # export JAVA_HOME= 为:export JAVA_HOME=/usr/local/jdk1.8.0_131 注:指定java运行环境变量
2、配置文件yarn-env.sh,保存yarn框架的运行环境
该文件是yarn框架运行环境的配置,同样需要修改java虚拟机的位置。
yarn :Hadoop 的新 MapReduce 框架Yarn是Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理 。
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/yarn-env.sh 不需要修改。 查看优先规则: 21## Precedence rules: 22## 23## yarn-env.sh > hadoop-env.sh > hard-coded defaults Precedence [ˈpresɪdəns] 优先
3、配置文件core-site.xml,指定访问hadoop web界面访问路径
这个是hadoop的核心配置文件,这里需要配置的就这两个属性,fs.default.name配置了hadoop的HDFS系统的命名,位置为主机的9000端口;
hadoop.tmp.dir配置了hadoop的tmp目录的根位置。这里使用了一个文件系统中没有的位置,所以要先用mkdir命令新建一下。
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/core-site.xml
改:
19 <configuration>
20 </configuration>
注: 在<configuration>和</configuration>中间插入以一下红色和蓝色标记内容:
为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://xuegod63.cn:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>13107</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
注:property 财产 [ˈprɒpəti]
io.file.buffer.size 的默认值 4096 。这是读写 sequence file 的 buffer size, 可减少 I/O 次数。在大型的 Hadoop cluster,建议可设定为 65536
4、配置文件hdfs-site.xml
这个是hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置;
dfs.replication配置了文件块的副本数,一般不大于从机的个数。
[root@xuegod63 ~]# vim /home/hadoop/hadoop-3.0.0/etc/hadoop/hdfs-site.xml
改:19 <configuration>
20
21 </configuration>
注: 在<configuration>和</configuration>中间插入以一下红色和蓝色标记内容:
为:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xuegod63.cn:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
注:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xuegod63.cn:9001</value> # 通过web界面来查看HDFS状态
</property>
<property>
<name>dfs.replication</name>
<value>2</value> #每个Block有2个备份。
</property>
6、配置文件mapred-site.xml
这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数,同时指定:Hadoop的历史服务器historyserver,Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器
$ /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
historyserverWARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
WARNING: /home/hadoop/hadoop-3.0.0/logs does not exist. Creating.
这样我们就可以在相应机器的19888端口上打开历史服务器的WEB UI界面。可以查看已经运行完的作业情况。
修改mapred-site.xml
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/mapred-site.xml
改:19 <configuration>
20
21 </configuration>
注: 在<configuration>和</configuration>中间插入以一下红色和蓝色标记内容:
为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
7、配置节点yarn-site.xml
该文件为yarn框架的配置,主要是一些任务的启动位置
[hadoop@xuegod63 hadoop-3.0.0]$ vim /home/hadoop/hadoop-3.0.0/etc/hadoop/yarn-site.xml
# 修改configuration内容如下:
改:
<configuration>
<!-- Site specific YARN configuration properties -->
</configuration>
注: 在<configuration>和</configuration>中间插入以一下红色和蓝色标记内容:
为:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>xuegod63.cn:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>xuegod63.cn:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>xuegod63.cn:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>xuegod63.cn:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>xuegod63.cn:8088</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/home/hadoop/hadoop-3.0.0/etc/hadoop:/home/hadoop/hadoop-3.0.0/share/hadoop/common/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/common/*:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/*:/home/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/* </value>
</property>
</configuration>
8、编辑datanode节点host
[hadoop@xuegod63 hadoop]$ vim workers xuegod62.cn xuegod64.cn 复制到其他datanode节点: xuegod64和xuegod62 [hadoop@xuegod63 hadoop-3.0.0]$ scp core-site.xml hadoop-env.sh hdfs-site.xml mapred-site.xml yarn-site.xml workers 192.168.1.62:/home/hadoop/hadoop-3.0.0/etc/hadoop/ [hadoop@xuegod63 hadoop-3.0.0]$ scp core-site.xml hadoop-env.sh hdfs-site.xml mapred-site.xml yarn-site.xml workers 192.168.1.64:/home/hadoop/hadoop-3.0.0/etc/hadoop/
在xuegod63上启动Hadoop
切换到hadoop用户
[root@xuegod63 ~]# su - hadoop
(3)格式化
hadoop namenode的初始化,只需要第一次的时候初始化,之后就不需要了
查看格式化后,生成的文件:
[root@xuegod63 ~]# rpm -ivh /mnt/Packages/tree-1.6.0-10.el7.x86_64.rpm [hadoop@xuegod63 ~]$ tree /home/hadoop/dfs/ /home/hadoop/dfs/ ├── data └── name └── current ├── fsimage_0000000000000000000 ├── fsimage_0000000000000000000.md5 ├── seen_txid └── VERSION 生成基于hadoop用户的不输入密码登录:因为后期使用hadoop用户启动datanode节点使用需要直接登录到对应的服务器上启动datanode相关服务。 [hadoop@xuegod63 hadoop-3.0.0]$ ssh-keygen [hadoop@xuegod63 hadoop-3.0.0]$ ssh-copy-id 192.168.1.64 [hadoop@xuegod63 hadoop-3.0.0]$ ssh-copy-id 192.168.1.62 [hadoop@xuegod63 hadoop-3.0.0]$ ssh-copy-id 192.168.1.63
(4)启动hdfs: ./sbin/start-dfs.sh,即启动HDFS分布式存储
[root@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/start-dfs.sh Starting namenodes on [xuegod63.cn] xuegod63.cn: starting namenode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-namenode-xuegod63.cn.out xuegod64.cn: starting datanode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-datanode-xuegod64.cn.out xuegod62.cn: starting datanode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-datanode-xuegod62.cn.out Starting secondary namenodes [xuegod63.cn] xuegod63.cn: starting secondarynamenode, logging to /home/hadoop/hadoop-3.0.0/logs/hadoop-root-secondarynamenode-xuegod63.cn.out 注:如果报错,如: xuegod64.cn: Host key verification failed. 解决: [hadoop@xuegod63 ~]$ ssh 192.168.1.64 #确认可以不输入密码直接连接上xuegod64 关闭后再重启: [root@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/stop-dfs.sh [root@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/start-dfs.sh
(5)查看进程,此时master有进程:namenode和 secondarynamenode进程:
[root@xuegod63 ~]# ps -axu | grep namenode --color Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 8214 4.1 9.5 1882176 110804 ? Sl 17:39 0:17 /usr/java/jdk1.8.0_161/bin/java -Dproc_namenode -Xmx1000m 。。。 -Dhadoop.log.dir=/home/hadoop/hadoop-3.0.0/logs -Dhadoop.log.file=hadoop-root-secondarynamenode-xuegod63.cn.log xuegod64和xuegod62上有进程:DataNode [root@xuegod64 ~]# ps -axu | grep datanode --color Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 5749 8.8 5.2 1851956 60656 ? Sl 17:55 0:06 /usr/java/jdk1.8.0_161/bin/java -Dproc_datanode -Xmx1000m 。。。
(6)在xuegod63上启动yarn: ./sbin/start-yarn.sh 即,启动分布式计算
[hadoop@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-3.0.0/logs/yarn-root-resourcemanager-xuegod63.cn.out xuegod62.cn: starting nodemanager, logging to /home/hadoop/hadoop-3.0.0/logs/yarn-root-nodemanager-xuegod62.cn.out xuegod64.cn: starting nodemanager, logging to /home/hadoop/hadoop-3.0.0/logs/yarn-root-nodemanager-xuegod64.cn.out
(7)查看进程:
查看xuegod63上的ResourceManager进程,xuegod62和xuegod64上的进程:DataNode NodeManager
[root@xuegod63 ~]# ps -axu | grep resourcemanager --color Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 9664 0.2 11.0 2044624 128724 pts/3 Sl 17:58 0:27 /usr/java/jdk1.8.0_161/bin/java -Dproc_resourcemanager -Xmx1000m [root@xuegod62 ~]# ps -axu | grep nodemanager --color Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ hadoop 5486 31.8 7.8 1913012 91692 ? Sl 23:01 0:20 /usr/java/jdk1.8.0_161/bin/java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/home/hadoop/hadoop-3.0.0/logs [root@xuegod64 ~]# ps -axu | grep nodemanager --color Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ hadoop 2872 20.8 7.9 1913144 92860 ? Sl 21:42 0:15 /usr/java/jdk1.8.0_161/bin/java -Dproc_nodemanager -Xmx1000m 注:start-dfs.sh 和 start-yarn.sh 这两个脚本可用start-all.sh代替。 [hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/start-all.sh 关闭: [hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/stop-all.sh 启动: jobhistory服务,查看mapreduce运行状态 [hadoop@xuegod63 hadoop-3.0.0]# /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /home/hadoop/hadoop-3.0.0/logs/mapred-root-historyserver-xuegod63.cn.out 在主节点上启动存储服务和资源管理主服务。使用命令: [hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务 [hadoop@xuegod63 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务 登录从结点:启动存储从服务和资源管理从服务 [hadoop@xuegod62 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务 [hadoop@xuegod62 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务 [hadoop@xuegod64 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务 [hadoop@xuegod64 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务
(8)查看HDFS分布式文件系统状态:
[hadoop@xuegod63 hadoop-3.0.0]$ /home/hadoop/hadoop-3.0.0/bin/hdfs dfsadmin -report 。。。 ------------------------------------------------- Datanodes available: 1 (1 total, 0 dead) Live datanodes: Name: 192.168.1.62:50010 (xuegod62.cn) Hostname: xuegod62.cn Decommission Status : Normal Configured Capacity: 10320982016 (9.61 GB) DFS Used: 24576 (24 KB) Non DFS Used: 4737789952 (4.41 GB) DFS Remaining: 5583167488 (5.20 GB) DFS Used%: 0.00% DFS Remaining%: 54.10% Last contact: Sun May 31 21:58:00 CST 2015 Name: 192.168.1.64:50010 (xuegod64.cn) Hostname: xuegod64.cn Decommission Status : Normal Configured Capacity: 10320982016 (9.61 GB) DFS Used: 24576 (24 KB) Non DFS Used: 5014945792 (4.67 GB) DFS Remaining: 5306011648 (4.94 GB) DFS Used%: 0.00% DFS Remaining%: 51.41% Last contact: Mon Aug 03 23:00:03 CST 2015
(9)查看文件块组成部分:
[hadoop@xuegod63 hadoop-3.0.0]$ ./bin/hdfs fsck / -files -blocks
或:
http://192.168.1.63:9870/dfshealth.html#tab-datanode

(10)通过web界面来查看HDFS状态: http://192.168.1.63:9001/status.html
(11)通过Web查看hadoop集群状态: http://192.168.1.63:8088
(12)查看JobHistory的内容:
http://192.168.1.63:19888/jobhistory
(13)设置HADOOP_HOME环境变量,方便后期调用命令。
[root@xuegod63 ~]# vim /etc/profile #添加追加以下内容: export HADOOP_HOME=/home/hadoop/hadoop-3.0.0 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH [root@xuegod63 ~]# source /etc/profile [root@xuegod63 ~]# start #输入start 按两下tab键,测试命令补齐
测试:
运行Hadoop计算任务,Word Count 字数统计
[hadoop@xuegod63 ~]$ source /etc/profile (1)/home/hadoop目录下有两个文本文件file01.txt和file02.txt,文件内容分别为: [hadoop@xuegod63 ~]$ vim file01.txt man kong man Hello World mk [hadoop@xuegod63 ~]$ vim file02.txt mk www.xuegod.cn cd cat man (2)将这两个文件放入hadoop的HDFS中: [hadoop@xuegod63 ~]$ hadoop fs -ls //查看hdfs目录情况 ls: `.': No such file or directory [hadoop@xuegod63 ~]$ hadoop fs -mkdir -p input [hadoop@xuegod63 ~]$ hadoop fs -put /home/hadoop/file*.txt input [hadoop@xuegod63 ~]$ hadoop fs -cat input/file01.txt //查看命令 man kong man Hello World mk (3)计执行 wordCount单词统计汇总并查看结果: [hadoop@xuegod63 ~] hadoop jar hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount input output 查看运行之后产生的文件 hadoop fs -ls output 查看运行结果 hadoop fs -cat output/part-r-00000 可以看到数据都已经被统计出来了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号