python数据类型之字符串
python字符串
- 作用:打印信息,获取路径均为字符串,以单引号' '或双引号" "修饰
- 定义:" "内可以定义任意字符,可以通过索引查看或通过字符串方法分隔
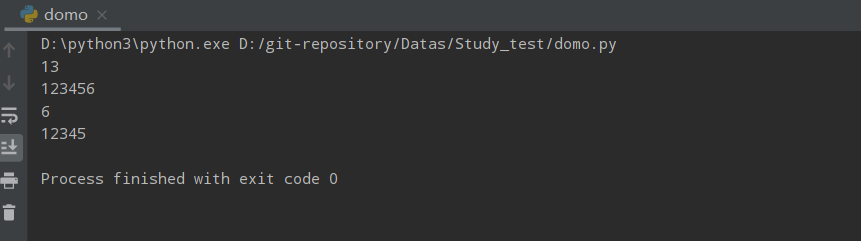
字符串索引及切片
字符串是有序的,可通过下标查看列表中的元素
str1= '123456'
str1[start,end,step] 遵循左闭右开原则(末端不包含)
start 元素下标起始位置,包含对应元素值,不传默认为首部
end 元素下标结束位置,不包含对应元素值,不传默认为最末端
step 步长,不传默认为1,下标对应往上+1,直到到结束位置查看
print(str1[:3:2])
print(str1[::])
print(str1[-1])
print(str1[:-1])
运行结果
python字符串方法
通过help()
str 可查看字符串相关的方法
或者dir(str)查看字符串相关方法
str()
将其他数据类型转为字符串类型
a = str() # 定义空字符串 等同于a = ''
print(a)
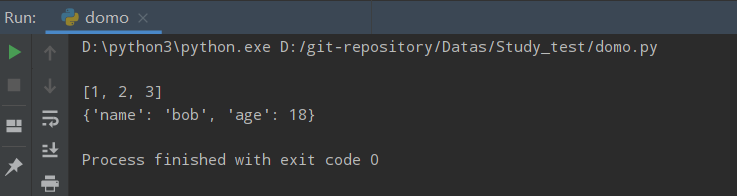
str1 = str([1,2,3])
print(str1)
dic1 = {'name':'bob','age':18}
print(str(dic1))
运行结果
capitalize()
该方法将字符串首字母改为大写
a = 'a,B'
print(a.capitalize()) # 将首字母改为大写,其他字母变小写
运行结果

casefold()
该方法将字符串所有大写字母转为小写
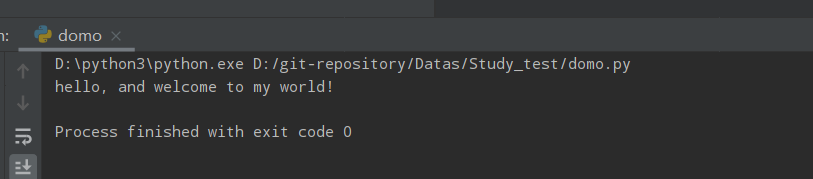
txt = "Hello, And Welcome To My World!"
print(txt.casefold()) # 将所有大写字母转为小写
运行结果
center()
字符串居中展示
str.center(width[, fillchar])
- width -- 字符串的总宽度。
- fillchar -- 填充字符。
str1 = '测试开发'
print(str1.center(20,'=')) # 字符居中,左右以=号填充
print(str1.center(20,' ')) # 字符串居中,左右以空格填充
print(str1.center(20)) # 字符串居中,不传填充字符,默认填充空
运行结果

count()
统计某个字符在字符串中出现的次数
str.count(sub, start= 0,end=len(string))
- sub -- 搜索的子字符串
- start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
ss = 'a测试123aaaa'
print(ss.count('a')) # 统计某个字符在字符串中出现的次数,默认从索引0开始搜索
print(ss.count('a', 1)) # 从索引1开始搜索
print(ss.count('a', 4, len(ss))) # 从索引4开始,字符串最后一位结束
运行结果

encode()
Python encode() 方法以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
str.encode(encoding='UTF-8',errors='strict')
- encoding -- 要使用的编码,如"UTF-8"。
- errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
ss = '字符编码'
utf_str = ss.encode('UTF-8', errors='strict') # 指定以utf-8格式进行编码
print(utf_str)
import base64
mm = base64.b16encode(utf_str)
print(mm.decode())
运行结果

endwith() & startwith()
Python endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。
- suffix -- 该参数可以是一个字符串或者是一个元素。
- start -- 字符串中的开始位置。
- end -- 字符中结束位置。
Python startswith() 方法用于判断字符串是否以指定前缀开头,如果以指定前缀开头返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。
- suffix -- 该参数可以是一个字符串或者是一个元素。
- start -- 字符串中的开始位置。
- end -- 字符中结束位置。
a = '文件名.json'
b = 'ini测试.json'
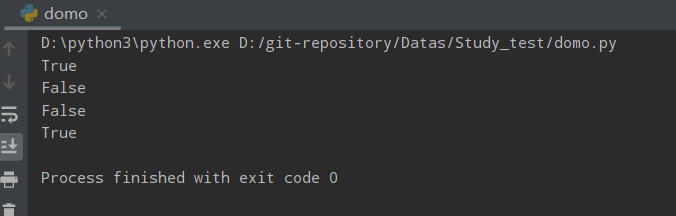
print(a.endswith('json')) # 判断字符串是否以json结尾,默认从字符串的索引为0遍历到结尾
print(a.endswith('ini')) # 判断字符串是否以ini结尾
print(a.startswith('json')) # 判断字符串是否以json开头
print(b.startswith('ini')) # 判断字符串是否以ini开头
运行结果
expandtabs()
expandtabs() 方法把字符串中的 tab 符号 \t 转为空格,tab 符号 \t 默认的空格数是 8,在第 0、8、16...等处给出制表符位置,如果当前位置到开始位置或上一个制表符位置的字符数不足 8 的倍数则以空格代替。
str.expandtabs(tabsize=8)
- tabsize -- 指定转换字符串中的 tab 符号('\t')转为空格的字符数。
f = '\t测试开发'
print("原始字符串:%s"%f)
print("转换空格字符串:%s"%f.expandtabs(8)) # 个人理解的将\t转为8个空格
print("转换空格字符串:%s"%f.expandtabs(0)) # 个人理解的将\t转为0个空格,即没有空格
运行结果

find() & index() & rfind() & rindex()
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
index()方法和该方法类似,区别在于index方法,当搜索的字符不在字符串中会报ValueError: substring not found,而find()方法,当找不到时会返回-1
rfind()方法返回字符串最后一次出现的起始索引值,找不到则返回-1
rindex()方法返回字符串最后一次出现的起始索引值,找不到则报错ValueError: substring not found
str.find(str, beg=0, end=len(sftring))
- str -- 指定检索的字符串
- beg -- 开始索引,默认为0。
- end -- 结束索引,默认为字符串的长度。
ff = "hello world ...hi!hi"
print(ff.index('hi')) # 返回字符串的第一次出现的起始索引值
print(ff.find('hi')) # 返回字符串的第一次出现的起始索引值
print(ff.rfind('hi')) # 返回字符串最后出现的起始索引值
print(ff.rindex('hi')) # 返回字符串最后出现的起始索引值
print(ff.find('xx')) # 找不到会返回-1
print(ff.index('xx')) # 找不到会报ValueError: substring not found
print(ff.rfind('xx'))
print(ff.rindex('xx')) # 找不到会报ValueError: substring not found
运行结果

format()
formatmap()
可看如下代码,format和formatmap用法区别
student = {'name': '小明', 'classname': '20190301', 'score': 597.5}
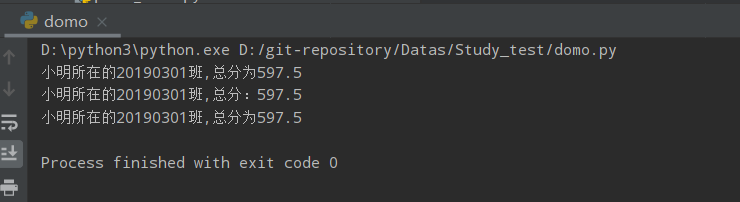
print('{name}所在的{classname}班,总分为{score}'.format(name=student['name'], classname=student['classname'],
score=student['score'])) # fomat写法1
print('{st[class]}班{st[name]}总分:{st[score]}'.format(st=student)) # format写法2
print('{name}所在的{classname}班,总分为{score}'.format_map(student)) # firmat_map写法
运行结果
isalnum()
Python isalnum() 方法检测字符串是否由字母和数字组成。如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
str = "this2009" # 字符中没有空格
print(str.isalnum())
str = "this is string example....wow!!!"
print(str.isalnum())
运行结果
isalpha()
Python isalpha() 方法检测字符串是否只由字母组成。如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
str = "this2009"
str1 = 'all name' # 字符串有空格
str2 = 'allname' # 字符串没有空格
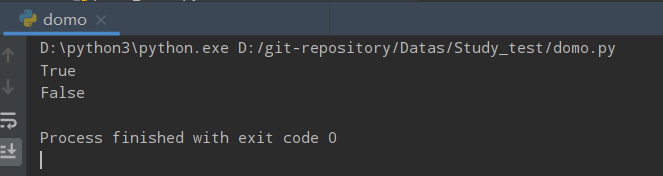
print(str.isalpha())
print(str1.isalpha())
print(str2.isalpha())
运行结果
isascii()
如果字符串为空或字符串中的所有字符都是 ASCII,则返回 True,否则返回 False。
ASCII 字符的码位在 U+0000-U+007F 范围内。可参照 https://www.cnblogs.com/happy-winds/p/14758076.html 中的ASCII码对照表
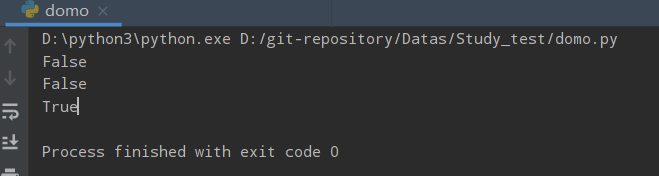
a = 'afsakjkl'
print(a.isascii())
b = ' saf afs' # 字符串有空格
print(a.isascii())
a = '中文'
print(a.isascii())
运行结果
isdecimal()
Python isdecimal() 方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。如果字符串是否只包含十进制字符返回True,否则返回False。
注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可。
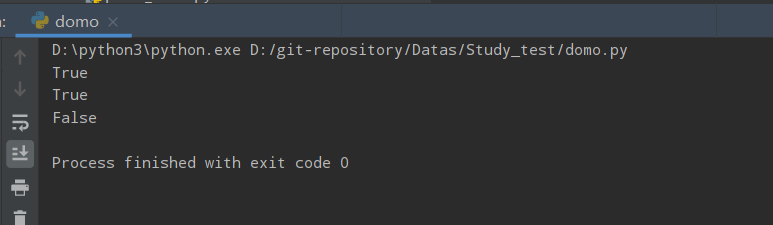
str = u"this2009"
print (str.isdecimal())
str = u"23443434"
print (str.isdecimal())
运行结果
isdigit()
Python isdigit() 方法检测字符串是否只由数字组成。如果字符串只包含数字则返回 True 否则返回 False。
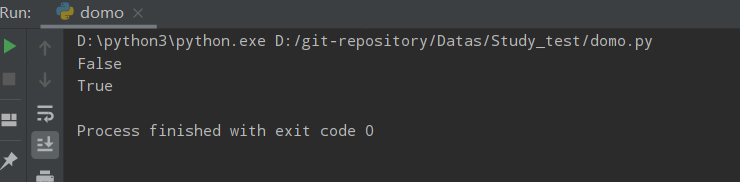
ss = '123 456' # 含空格
print(ss.isdigit())
ss1 = '123456'
print(ss1.isdigit())
运行结果
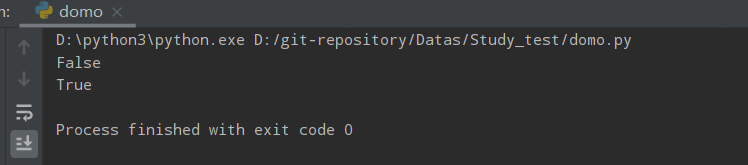
isidentifier()
判断字符串是否为有效标识符
如果字符串仅包含字母数字字母(a-z)和(0-9)或下划线(_),则该字符串被视为有效标识符。有效的标识符不能以数字开头或包含任何空格。如果字符串是有效标识符,则 isidentifier() 方法返回 True,否则返回 False。
a = "MyFolder"
b = "Demo002"
c = "2bring"
d = "my demo"
print(a.isidentifier())
print(b.isidentifier())
print(c.isidentifier())
print(d.isidentifier())
运行结果
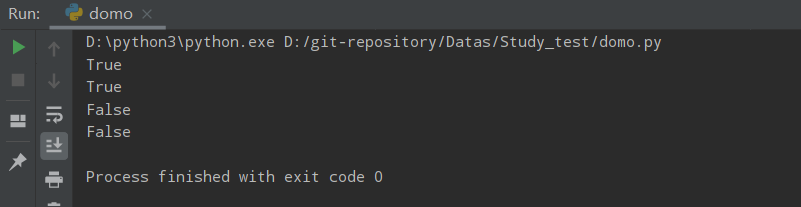
islower() & lower()
Python islower() 方法检测字符串是否由小写字母组成。
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
lower方法将字符串中的所有字母全部改为小写
a = 'HELLO WORLD!'
print(a.islower())
ff = a.casefold()
print(ff.islower())
mm = a.lower()
print(mm)
运行结果
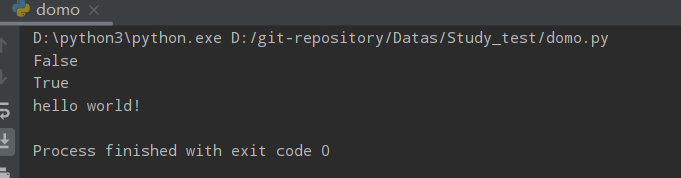
isnumeric()
Python isnumeric() 方法检测字符串是否只由数字组成。这种方法是只针对unicode对象。如果字符串中只包含数字字符,则返回 True,否则返回 False
注:定义一个字符串为Unicode,只需要在字符串前添加 'u' 前缀即可
str = u"this2009"
print(str.isnumeric())
str = u"23443434"
print(str.isnumeric())
运行结果
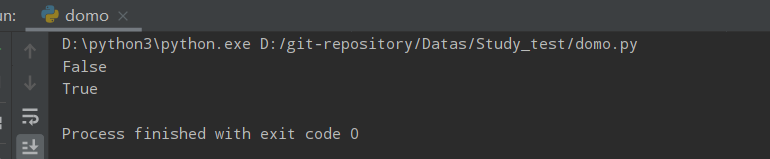
isprintable()
判断字符串是否可打印,如果所有字符都是可打印的,则 isprintable() 方法返回 True,否则返回 False。
不可打印的字符可以是回车和换行符。
ss = '\n\t测试打印'
print(ss.isprintable())
ss = "测试打印&*……¥¥#2"
print(ss.isprintable())
运行结果
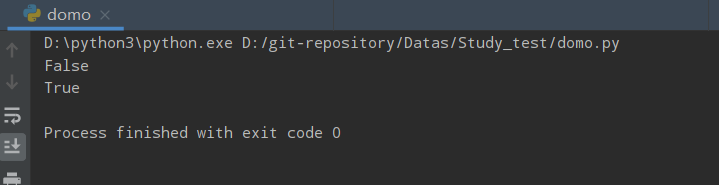
isspace()
isspace() 方法检测字符串是否只由空格组成。全部由空格组成返回True,不是则返回False
ss = '\t这里有制表符'
print(ss.isspace())
ss = ' 这里有空格'
print(ss.isspace())
ss = '\t'
print(ss.isspace())
ss = ' '
print(ss.isspace())
运行结果
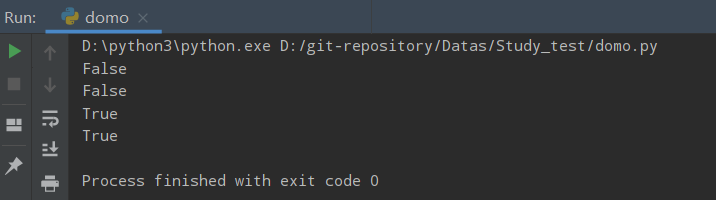
istitle()&title()
Python istitle() 方法检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回 True,否则返回 False.
title() 则是将字符串所有的单词拼写首字母改为大写,其他置为小写
ss = "HELLO NICE world"
print(ss.istitle())
ff = ss.capitalize() # 首字母大写
print(ff.istitle())
mm = 'Hello World '
print(mm.istitle())
print(ss.title()) # 所有单词拼音首字母大写,其他变为小写
运行结果
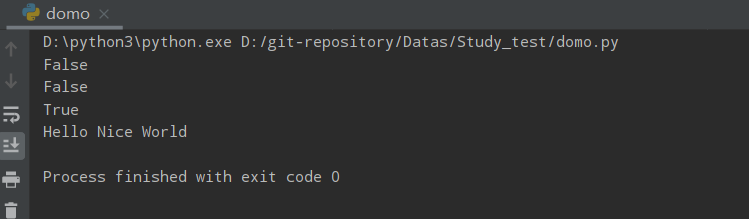
isupper()&upper()
Python isupper() 方法检测字符串中所有的字母是否都为大写。 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
upper()方法将所有字母改为大写
a = 'HELLO NICE world'
print(a.isupper())
ff = a.upper()
print(ff)
print(ff.isupper())
运行结果
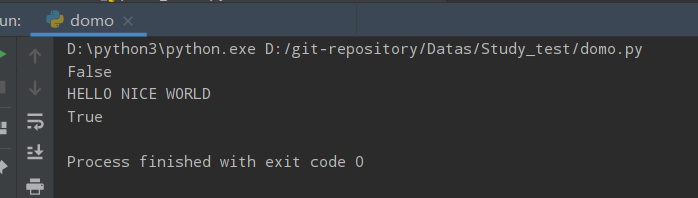
join()
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。返回通过指定字符连接序列中元素后生成的新字符串。
str.join(sequence)
- sequence -- 要连接的元素序列。
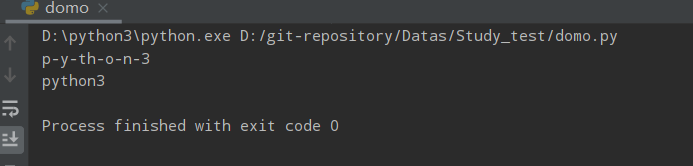
s1 = "-"
s2 = ""
seq = ("p", "y", "th", "o", "n", "3") # 字符串序列
print (s1.join( seq ))
print (s2.join( seq ))
运行结果
ljust() & rjust()
Python ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
rjust()方法返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串
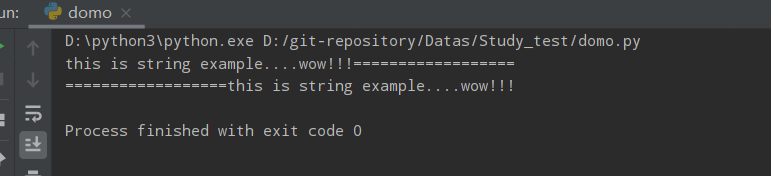
str = "this is string example....wow!!!"
print(str.ljust(50,"="))
print(str.rjust(50,"="))
运行结果
strip() & rstrip() & lstrip()
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
rstrip()方法为移除右边指定的字符
lstrip方法为移除左边的字符
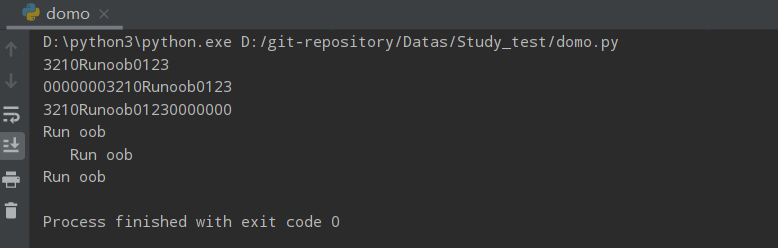
str = "00000003210Runoob01230000000"
print(str.strip('0'))
print(str.rstrip('0'))
print(str.lstrip('0'))
str2 = " Run oob "
print(str2.strip())
print(str2.rstrip())
print(str2.lstrip())
运行结果
maketrans() & translate()
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
两个字符串的长度必须相同,为一一对应的关系。
该方法需要结合translate()方法使用
translate() 方法根据参数table给出的表(包含 256 个字符)转换字符串的字符,要过滤掉的字符放到 deletechars 参数中
str.translate(table)
bytes.translate(table[, delete])
bytearray.translate(table[, delete])
- table -- 翻译表,翻译表是通过 maketrans() 方法转换而来。
- deletechars -- 字符串中要过滤的字符列表。
注:Python3.4 已经没有 string.maketrans() 了,取而代之的是内建函数: bytearray.maketrans()、bytes.maketrans()、str.maketrans() 。
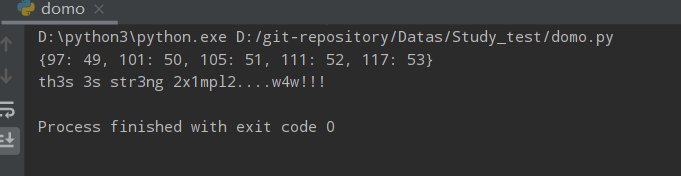
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab)
print(trantab)
str = "this is string example....wow!!!"
print (str.translate(trantab))
partition()& rpartition()
partition() 方法用来根据指定的分隔符将字符串进行分割。
如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
rpartition() 方法类似于 partition() 方法,只是该方法是从目标字符串的末尾也就是右边开始搜索分割符。
str.partition(str)
- str : 指定的分隔符
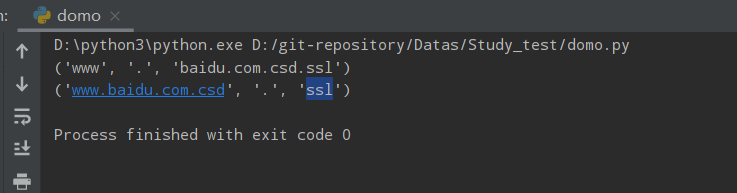
ss = 'www.baidu.com.csd.ssl'
print(ss.partition('.'))
print(ss.rpartition('.'))
运行结果
replace()
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
str.replace(old, new[, max])
- old -- 将被替换的子字符串。
- new -- 新字符串,用于替换old子字符串。
- max -- 可选字符串, 替换不超过 max 次
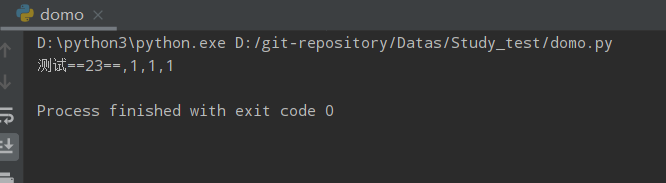
ss = '测试1231,1,1,1'
print(ss.replace('1','==',2))
运行结果
split() & rsplit()
split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。返回分割后的字符串列表。
str.split(str="", num=string.count(str))
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。默认为 -1, 即分隔所有。
rsplit()方法同split方法一致,区别在于rsplit()是从右往左开始分割,split是从左往右开始分割
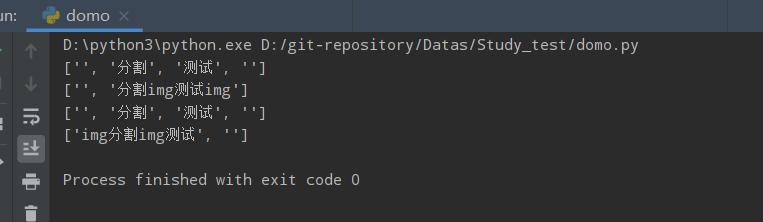
ff = 'img分割img测试img'
print(ff.split('img')) # 默认分割所有,默认值为-1,从左往右开始分割
print(ff.split('img', 1)) # 分割一次
print(ff.rsplit('img')) # 从右往左分割
print(ff.rsplit('img', 1)) # 从右往左分割,分割一次
运行结果
splitlines()
Python splitlines() 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
str.splitlines([keepends])
- keepends -- 在输出结果里是否去掉换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符。
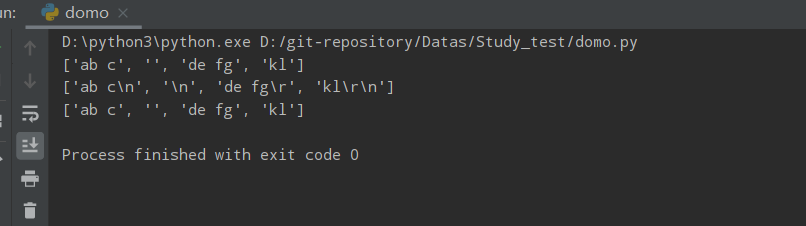
ff = 'ab c\n\nde fg\rkl\r\n'
print(ff.splitlines()) # 默认为False,不保留换行符
print(ff.splitlines(True)) # 为True保留换行符
print(ff.splitlines(False))
运行结果
swapcase()
swapcase() 方法用于对字符串的大小写字母进行转换。即将大写转换为小写,小写转换为大写,返回大小写字母转换后生成的新字符串。
str = "this is string example....wow!!!"
ff = str.swapcase()
print(ff)
print(ff.swapcase())
str = "This Is String Example....WOW!!!"
print (str.swapcase())
运行结果
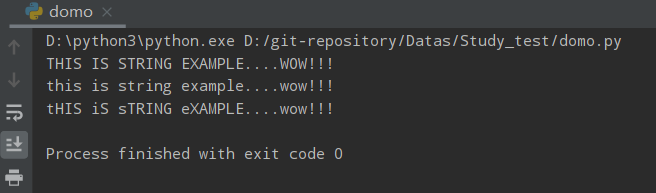
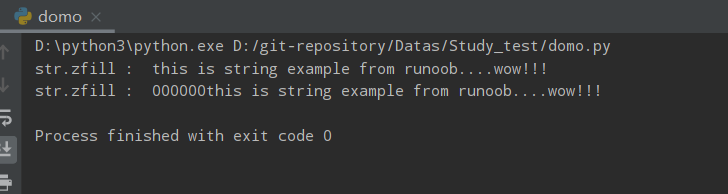
zfill()
Python zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。返回指定长度的字符串。
str.zfill(width)
- width -- 指定字符串的长度。原字符串右对齐,前面填充0。
str = "this is string example from runoob....wow!!!"
print ("str.zfill : ",str.zfill(40))
print ("str.zfill : ",str.zfill(50))
运行结果