初探attention—attention原理和代码详解
attention
在正式开始探索attention之前,首先了解一下seq2seq。循环神经网络只能将一个序列信号转换为定长输出,但Seq2Seq可以实现一个序列信号转化成一个不定长的序列输出,因此seq2seq模型应用广泛,可以应用于很多不对等输入输出的场景,比如机器翻译,文本摘要,对话生成,诗词生成,代码补全等领域,当然也可以用于文本分类等任务。
以下所有内容,如有侵权,请联系删除~
seq2seq
Seq2Seq不特指具体方法,只要满足输入序列到输出序列的目的,都可以统称为Seq2Seq模型。如下图所示就是一个seq2seq模型。

seq2seq是sequence to sequence的缩写。前一个sequence称为编码器encoder,用于接收源序列。后一个sequence称为解码器decoder,用于输出预测的目标序列。
Seq2Seq模型的主要瓶颈是需要将源序列的全部内容压缩为固定大小的矢量。如果文本稍长,则很容易丢失文本的某些信息。
attention的提出
在seq2seq方法中,seq2seq中间语义向量最简单的方式是用encoder最后一层最后一个时间步的隐状态向量\(h_T\),作为中间语义向量C,或者通过激活函数变换到某个维度:
\(C=q(h_1,h_2,...,h_T)\)
这样,seq2seq无论输入长度和输出长度是多少,中间的语义编码C的长度是固定的,在文本长度较长时,会丢失很多信息。
另外,解码器从语义编码C到输出的过程,可以由下式表示:
\(Y_1=f(C)\\Y_2=f(C,Y_1)\\Y_3=f(C,Y_1,Y_2)\)
根据上式,显而易见,语义编码C这个向量的各个维度的信息对输出结果的影响力是相同的。
实际情况中,针对当前输出结果,语义编码C中的各个维度应该表现出不同的影响力。比如i have a dog,在翻译小狗的时候,dog这个词向量的影响力应该大于其他单词向量的影响力。基于这种思想,attention被提出来。
Attention,正如其名,针对语义编码C增加注意力机制。首先利用编码器得到encoder中的hidden state,编码器可以是RNN,LSTM及其变种,或者GRU。该模型在decode阶段,会在中间语义向量中选择最适合当前节点的上下文向量作为输入。
attention与传统的seq2seq的区别
encoder可以提供更多的数据给decoder,encoder会把所有的节点的hidden state提供给decoder,而不仅仅只是encoder最后一个节点的hidden state。
decoder并不是直接把所有encoder提供的hidden state全部作为输入,而是采取一种权重赋予机制,给不同的hidden state赋予不同的选择权重。
以上两点是attention与传统seq2seq的主要区别。权重的获取方式代表不同的attention模型。最简单最常用的是dot product乘积矩阵,即将解码器的输出隐状态与中间语义编码进行矩阵相乘获得权重。
attention详细步骤拆解
附一张通俗易懂的图:
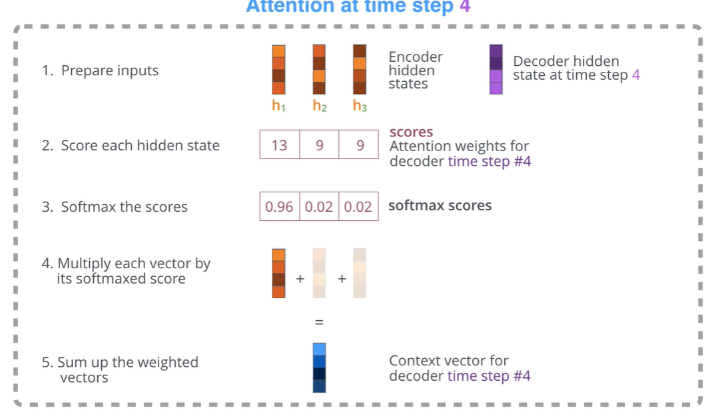
attention处理步骤主要有以下几步:
- 把encoder每一个节点的hidden states的值与decoder当前节点的上一个节点的隐状态\(h_{t-1}\)相乘(如果是第一个decoder节点,需要初始化一个hidden state)。
这样会获得time_steps个值,这些值就是语义编码C每个hidden state的分数,也就是权重分数。在不同的decoder时间步,由于decoder上一个节点的\(h_{t-1}\)是不断变化的,因而这个权重向量也是不同的;
-
归一化。把 2. 中的分数值进行softmax计算,计算之后的值就是每一个encoder节点的hidden states对于当前decoder时间步的权重。
-
把权重与语义编码C中的hidden states相乘并相加,得到的结果即是当前decoder时间步的上下文向
量。 -
将上下文向量和decoder的上一时刻的隐层状态输入decoder网络,得到当前时刻的输出。
-
decoder开始下一节点,并重复1-5;直到输出所有的结果。
抛开encoder-decoder,Attention机制其实就是注意力系数分配的过程。常见各种技术文章谈到的K,V,Q,看起来玄乎其玄,其实万变不离其宗,其原理就是上述的权重分配的过程。
可以将中间语义向量C想象成一个<K,V>对,也就是键值对。而Q是输出的某个元素。我们首先利用Q计算与K的相关性,得到key对应value的权重,然后利用权重对value加权求和,得到最终的attention值。这个过程可以分解为三个阶段:
- Q与K进行相似度计算,获得权值
- 对权值归一化
- 利用归一化的权值与value进行加权求和,得到输出值。
上述中K与V其实是相同的,不同的是Q
attention实现及讲解
首先看代码,为了对代码有一个清晰的了解,只保留了部分代码。源代码仓库:点击这里
import os
from tensorflow.keras import backend as K
from tensorflow.keras.layers import Dense, Lambda, Dot, Activation, Concatenate, Layer
class Attention(object if debug_flag else Layer):
def __init__(self, units=128, **kwargs):
super(Attention, self).__init__(**kwargs)
self.units = units
def build(self, input_shape):
input_dim = int(input_shape[-1])
with K.name_scope(self.name if not debug_flag else 'attention'):
self.attention_score_vec = Dense(input_dim, use_bias=False, name='attention_score_vec')
self.h_t = Lambda(lambda x: x[:, -1, :], output_shape=(input_dim,), name='last_hidden_state')
self.attention_score = Dot(axes=[1, 2], name='attention_score')
self.attention_weight = Activation('softmax', name='attention_weight')
self.context_vector = Dot(axes=[1, 1], name='context_vector')
self.attention_output = Concatenate(name='attention_output')
self.attention_vector = Dense(self.units, use_bias=False, activation='tanh', name='attention_vector')
# noinspection PyUnusedLocal
def call(self, inputs, training=None, **kwargs):
"""
Many-to-one attention mechanism for Keras.
@param inputs: 3D tensor with shape (batch_size, time_steps, input_dim).
@param training: not used in this layer.
@return: 2D tensor with shape (batch_size, units)
@author: felixhao28, philipperemy.
"""
if debug_flag:
self.build(inputs.shape)
# 第一步
score_first_part = self.attention_score_vec(inputs)
# 第二步
h_t = self.h_t(inputs)
# 第三步
score = self.attention_score([h_t, score_first_part])
# 第四步
attention_weights = self.attention_weight(score)
# 第五步
context_vector = self.context_vector([inputs, attention_weights])
# 第六步
pre_activation = self.attention_output([context_vector, h_t])
attention_vector = self.attention_vector(pre_activation)
return attention_vector
这个版本的attention的计算步骤为:
第一步:将隐状态序列进行一次线性变换,隐状态的shape为:(batch_size, time_steps, hidden_size),权重W的维度为(hidden_size, hidden_size),二者相乘得到的shape为:(batch_size, time_steps, hidden_size)。为什么要加线性变换?
第二步:获取decoder的初始节点的上一时刻隐状态变量\(h_{t-1}\),此处直接使用encoder隐状态序列的最后一个隐状态\(h_t^{encoder}\)。
第三步:获取当前节点的权重分数,通过使\(h_{t-1}^{decoder}\) dot score_first_part。经过线性变换的隐状态序列的shape为:(batch_size, time_steps, hidden_size) ,\(h_{t-1}^{decoder}\)的shape为:(batch_size, hidden_size),输出结果的shape为:(batch_size, time_steps)。
第四步:利用softmax归一化权重分数
第五步:利用权重和输入的隐状态序列获得attention的当前节点输入。encoder输出的隐状态序列shape为:(batch_size, time_steps, hidden_size),权重shape为:(batch_size, time_steps),二者相乘获得的结果shape为: (batch_size, hidden_size),此结果作为输入送进decoder网络,假设此结果变量名为context_vector。
第六步:利用\(h_{t-1}\)和context_vector,推理出当前时刻的输出,最后经过全连接层获得此节点的最终输出。
使用attention
那么如何使用attention呢,作者也给出了详细的例程:
import numpy as np
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.models import load_model, Model
from attention import Attention
def fun():
model_input = Input(shape=(time_steps, input_dim))
x = LSTM(64, return_sequences=True)(model_input)
x = Attention(units=32)(x) # 这里用到attention
x = Dense(1)(x)
model = Model(model_input, x)
model.compile(loss='mae', optimizer='adam')
model.summary()
attention暂时到这~
参考:
https://imzhanghao.com/2021/09/01/attention-mechanism/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号