Python生态工具、文本处理和系统管理(虚拟)
一、Python生态工具
一、Python内置小工具
1、秒级启动一个下载服务器
Python 内置了一个下载服务器就能够显著提升效率了 。 例如, 你的同事要让你传的文件位于某一个目录下,那么,你可以进入这个目 录 , 然后执行下面的命令启动一个下载服务器 :
Python2实现: python -m SimpleHTTPServer Python3实现: 在 Python 3 中,由于对系统库进行了重新整理,因此,使用方式会有不同: python -m http.server
执行上面的命令就会在当前目录下启动一个文件下载服务器, 默认打开 8000 端口 。 完成以后,只需要将 IP 和端口告诉同事,让同事自己去操作即可,非常方便高效 。
效果如下:
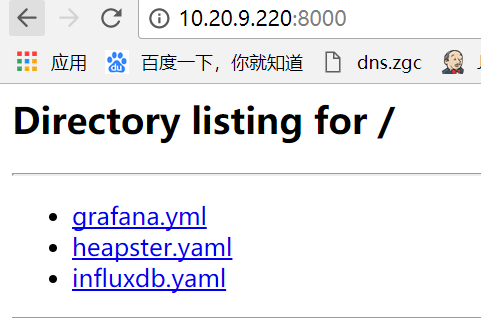
注意:如果当前目录下存在一个名为 index .html 的文件,则 默认显示该文件的内容 。 如果当前目录下不存在这样一个文件,则默认显示当前目录下的文件列表。
2、字符串转换为JSON
需求:在工作过程中,我们的系统会调用底层服务的 API。底层服务的 API一般都以 JSON 的格式返回,为了便于问题追踪,我们会将 API 返回的 JSON 转换为字符串记录到日志文件中。 当需要分析问题时,就需要将日志文件中的 JSON 字符串拿出来进行分析 。这个时候,需要将一个 JSON 字符串转换为 JSON 对象,以提高日志的可读性 。
解决:这个需求十分常见,以至于使用搜索引擎搜索 叮SON”,处于搜索结果的第一项便是“在线 JSON 格式化工具” 。 除了打开浏览器,使用在线 JSON 格式化工具以外,我们也可以使用命令行终端的 Python 解释器来解析 JSON 串,如下所示:
# echo '{" job":" developer"," name":" lmx"," s ex":"male " }' |python -m json.tool { " job": " developer", " name": " lmx", " s ex": "male " }
使用命令行解释器解析JSON 串非常方便,而且,为了便于阅读,该工具还会自动将转换的结果进行对齐和格式化。 如下所示:
# echo '{"signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes-Soulmate": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } }'|python -m json.tool { "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes-Soulmate": { "expiry": "8760h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } }
二、pip的高级用法
1、pip常用子命令
1、pip的子命令对照表

2、系统安装pip
进入https://pypi.python.org/pypi/pip,下载第二项。
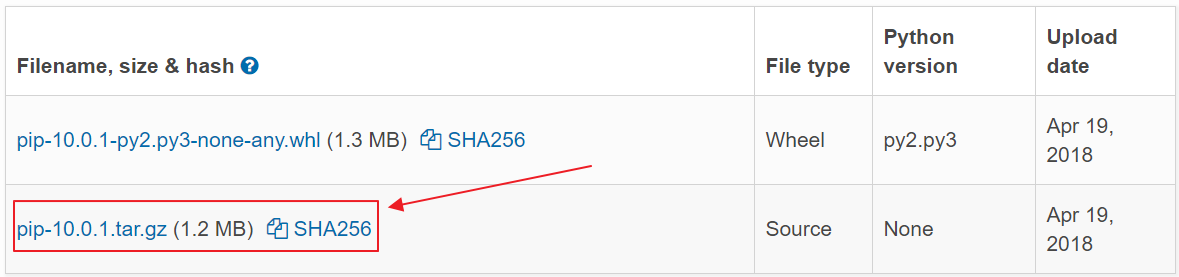
解压下载的文件(windows下只用解压工具解压如RAR,Linux下终端输入tar -xf pip-10.0.1.tar.gz,即tar -xf 文件名),进入解压后的文件夹中,调出命令行窗口或者终端
wget https://files.pythonhosted.org/packages/ae/e8/2340d46ecadb1692a1e455f13f75e596d4eab3d11a57446f08259dee8f02/pip-10.0.1.tar.gz tar xf pip-10.0.1.tar.gz cd pip-10.0.1/ ##Linux下操作用户是普通用户需要sudo授权操作 python setup.py install ##查看版本信息 pip -v
若安装报下面的错误
# python setup.py install Traceback (most recent call last): File "setup.py", line 6, in <module> from setuptools import setup, find_packages
解决办法如下(完美解决问题)
wget http://pypi.python.org/packages/2.7/s/setuptools/setuptools-0.6c11-py2.7.egg
sh setuptools-0.6c11-py2.7.egg
3、查找安装包
pip search flask
4、安装特定的安装包版本
pip install flask==0.8
5、删除/卸载安装包
pip uninstall Werkzeug
6、查看安装包的信息(-f显示安装包所在的目录)
pip show flask
7、查看安装包的依赖是否完整
pip check flask
8、列出已安装的包(有两种方法)
pip list (-o 查询可升级的包)

pip freeze

9、导出系统已安装的安装包列表到 requirements 文件
pip freeze > requirements.txt
10、从requirements文件安装需要的包
pip install -r requirements.txt
11、使用pip命令补全
pip completion --bash >~/.profile
$ source ~/.profile
12、下载包不安装
pip install <包名> -d <目录> 或 pip install -d <目录> -r requirements.txt
13、打包
pip wheel <包名>
14、升级指定的包(有两种方式)
pip install -U <包名>
或:pip install <包名> --upgrade
15、升级pip
pip install -U pip
2、加速pip安装的技巧
使用Python时间比较长的话,会发现 Python 安装的一个问题,即 pypi.python.org 不是特别稳定,有时候会很慢,甚至处于完全不可用的状态。
1、使用豆瓣或者阿里云的源加速软件安装
我们国内目前有多个pypi镜像,推荐使用豆瓣的镜像源或阿里的镜像源。
国内的镜像源地址: 阿里:https://mirrors.aliyun.com/pypi/simple 豆瓣:http://pypi.douban.com/simple 中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
单次使用安装源:如果要使用第三方的源,只需要在安装时,通过 pip 命令的-i 选项指定镜像源即可。如下所示:(包名放置前后均可)
pip install -i http://pypi.douban.com/simple flask
指定全局安装源
在unix和macos,配置文件为:$HOME/.pip/pip.conf
在windows上,配置文件为:%HOME%\pip\pip.ini


[global] timeout = 6000 index-url = http://pypi.douban.com/simple
2、将软件下载到本地部署
如果需要对大批量的服务器安装软件包,并且安装包比较多或者比较大,则可以考虑将软件包下载到本地,然后从本地安装。 这对于使用脚本部署大量的服务器非常有用 ,此外,对于服务器无法连接外网的情况,也可以使用这种方法。如下所示:
下载到本地
pip install download='pwd' -r requirements.txt
本地安装
pip install --no-index -f file.//'pwd' -r requirements.txt
使用这种方式,只需要下载一次,就可以多处安装,不用担心网络不稳定的问题 。 例如,我们通过这种方式下载 Flask 到当前目录下,则 Flask 的 依赖 click 、itsdangerous 、 Jinja2、Markup Safe 和 Werkzeug 也会被下载到本地。
pip install --download='pwd' flask
三、Python编辑器
1、Linux环境:编辑Python的vim插件
vim是一个功能强大、高度可定制的文本编辑器,与Emacs一起成为Linux下最著名的文本编辑器。
vim最强大的地方在于快速移动和高度可定制,所以使用vim编写Python代码时,只需要进行简单的定制就能够大幅提高编码效率。
1、一键执行
一键执行功能不是一个插件,而是自定义的vim配置。如果我们写的Python代码是一些较为简单的脚本,那么,这个一键执行的功能会非常实用。将下面的配置放在vim的配置文件当中,编写完Python代码以后,按F5就实现了一键执行功能。该功能最实用的是编写单元测试,写完测试不用退出vim,立即执行就能看到结果,非常方便。
配置连接地址:https://blog.csdn.net/u010871058/article/details/54253774
vimPython配置版:https://www.cnblogs.com/cjy15639731813/p/5886158.html

2、代码补全插件snipmate
代码补全能够显著减少敲键的次数,将我们从琐碎的语法中解放出来。毫不夸张地说,代码补全插件能够帮我们写一半的代码。例如,使用snipmate插件,输入ifmain后按tab键将会自动生成下面的代码:

3、语法检查插件 Syntastic
Syntastic是一款强大的语法检查插件,当我们保存源文件时,它就会执行。执行完以后,会提示我们哪些代码存在语法错误,哪些代码不符合编码规范,并给出具体的提示信息。例如,Python代码风格默认设置为PEP8,即使我们不太了解PEP8的代码风格,只要使用了Syntastic插件,并根据它给出的提示进行修改,就能够写出完全符合PEP8风格的代码。
4、编程提示插件jedi-vim
jedi-vim是基于jedi的自动补全插件,与snipmate不同的是,该插件更加智能。jedi-vim更贴切的称呼是“编程提示”,而不是代码补全插件。需要注意的是,使用jedi-vim插件前需要在电脑中安装jedi。这个插件是Python的标配。
jedi是一个自动补全和静态分析的Python库,直接使用pip安装即可:
pip install jedi
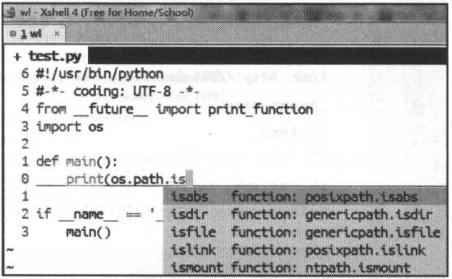
使用jedi-vim编写Python的代码效果图
2、Windows环境:Python编辑器PyCharm介绍
PyCharm是由JetBrains打造的一款功能强大的Python IDE 也是目前最流行的 Python IDE。JetBrains是捷克一家软件开发公司,该公司最为人熟知的产品是一款名为 IntelliJ IDEA的Java IDE 。IntelliJ IDEA是Eclipse最大的竞争对手,并且,不少资深的软件工程师 都认为,IntelliJ IDEA 比 Eclipse更加智能、更加好用。可以看到,JetBrains 算得上是一家历史悠久的开发编辑器的公司,正因为该公司在编辑器领域的多年沉淀、对编辑器的易用性有深刻的理解和独到的见解,使得PyCharm一经推出就受到了Python工程师的广泛关注 。
PyCharm是一款很现代的编辑器,几乎包含了所有现代编辑器应有的功能:
- 代码补全;
- 代码高亮;
- 项目管理;
- 智能提示;
- 代码风格检查;
- 集成单元测试;
- 集成版本控制工具;
- 图形界面调试;
- 方便的重构工具;
- 快捷键支持;
- 大量的插件。
四、Python代码规范检查
Python 官方给出的编码规范 PEP 8 ,然后介绍检查代码是否符合规范的工具 pycodestyle ,以及可以将代码风格格式化成 PEP 8 的 autopep8 。
1、PEP 8编码规范
1、PEP 8编码规范介绍
Python代码给人的第一印象就是颜值高、简洁优美、可读性强。这一方面是因为Python语言自身的优秀设计,如通过统一的缩进来表示代码块,通过减少多余的符号使得代码更加简洁;另一方面是因为Python代码有着较为统一的编码风格。
PEP 8本身只是编码风格方面的建议,并不强制工程师遵循。但是,由于该建议被Python工程师广泛接纳,因此,它已经成为了事实上的标准。
PEP8编码规范详细地给出了Python编码的指导,包括对齐规则、包的导人顺序、空格与注释、命名习惯和异常处理等Python编程的方方面面,并且提供了详细的示例。
2、PEP 8编码规范指导手册
官网手册:https://www.python.org/dev/peps/pep-0008/
中文手册:https://blog.csdn.net/ratsniper/article/details/78954852
3、注意事项
在Python2中,相对导入又可以分为显式相对导入和隐式相对导入,而在Python3中,已经弃用了隐式相对导入。
Python中支持相对导人和绝对导人,推荐使用绝对导人。因为绝对导人可读性更好,也不容易出锚,即使出错也会给出更加详细的错误信息。
2、使用pycodestype检查代码规范
Python官方的代码规范称为PEP8,这个检查代码风格的命令行工具叫阴间,很容易引起困惑。因此,Python之父提议将pep8这个命令行工具重命名为 pycodestyle。
1、安装相关的插件
pip install peps
pip install pycodestyle
2、对一个或多个文件运行 pycodestyle
方式一: pycodestyle --first optparse.py 方式二: pep8 optparse.py
3、显示不规范的源代码
pycodestyle --show-source --show-pep8 test.py
3、使用autopep8将代码格式化
1、autopep8简介
autopep8是一个开源的命令行工具,它能够将Python代码自动格式化为PEP8风格。autopep8使用pycodestyle工具来决定代码中的哪部分需要被格式化,这能够修复大部分pycodestyle工具中报告的排版问题。autopep8本身也是一个Python语言编写的工具。
2、安装autopep8
pip install autopep8
3、autopep8的使用
autopep8 --in-place optparse.py
--in-place参数类似于sed的-i参数,直接将修改结果保存到源文件中。若不加--in-place则只将结果输出到控制台,不修改源文件。
autopep8 还存在--aggressive选项,使用该选项会执行更多实质性的更改,可以多次使用以达到更佳的效果
五、Python工作环境管理
Python2和Python3之间存在着较大的差异,并且,由于各种原因导致了Python2和Python3的长期共存。在实际工作过程中,我们可能会同时用到Python2和Python3,因此,需要经常在Python2和Python3之间进行来回切换。
这涉及到两个工具:pyenv和virtualenv。pyenv用于管理不同的Python版本,virtualenv用于管理不同的工作环境。
部署应用:https://blog.csdn.net/lyintong/article/details/68491351
1、注意pyenv和virtualenv的区别
pyenv用以管理不同的Python版本,例如,你的系统工作时使用Python2.7.13,学习时使用Python3.6.0。
virtualenv用以隔离项目的工作环境,例如,项目A和项目B都是使用Python2.7.13,但是,项目A需要使用Flask0.8版本,项目B需要使用Flask0.9版本。
我们只要组合pyenv和virtualenv这两个工具,就能够构造Python和第三方库的任意版本组合,拥有很好的灵活性,也避免了项目之间的相互干扰。
virtualenv本身是一个独立的工具,用户可以不使用pyenv而单独使用virtualenv。但是,如果你使用了pyenv,就需要安装pyenv-virtualenv插件,而不是通过virtualenv软件使用virtualenv的功能。
2、使用pyenv管理不同的Python版本
1、pyenv简介
pyenv是一个Python版本管理工具,它能够进行全局的Python版本切换,也可以为单个项目提供对应的Python版本。使用pyenv以后,可以在服务器上安装多个不同的Python版本,也可以安装不同的Python实现。不同Python版本之间的切换也非常简单。
2、pyenv的安装
1、选择安装到$HOME/.pyenv目录 git clone https://github.com/yyuu/pyenv.git ~/.pyenv
2、配置环境变量 echo 'export PYENV_ROOT="$HOME/.pyenv"' >> /etc/profile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >>/etc/profile
3、使环境变量立即生效 source /etc/profile
3、pyenv的使用
1、查看一下有哪些版本的python 可以安装 pyenv install --list 2、安装指定版本的Python pyenv install -v 2.7.1 pyenv install -v 3.6.1 3、卸载指定版本的Python pyenv uninstall 2.7.1 4、查看所有的Python版本 pyenv versions 5、查看当前操作的Python版本 pyenv version
注意:
- system 代表当前系统的python 版本
- 全局环境下的python不会自动加载到pyenv下,一定要自己再安装一次各个版本的python
3、使用virtualenv管理不同的项目
1、virtualenv简介
virtualenv 本身是一个独立的项目,用以隔离不同项目的工作环境 。
用户需求:用户希望在项目A中使用Flask0.8这个版本,与此同时,又想在项目B中使用Flask0.9这个版本。如果我们全局安装Flask,必然无法满足用户的需求。这个时候,我们就可以使用virtualenv。
我们只要组合pyenv和virtualenv这两个工具,就能够构造Python和第三方库的任意版本组合,拥有很好的灵活性,也避免了项目之间的相互干扰。
virtualenv本身是一个独立的工具,用户可以不使用pyenv而单独使用virtualenv。但是,如果你使用了pyenv,就需要安装pyenv-virtualenv插件,而不是通过virtualenv软件使用virtualenv的功能。
2、pyenv-virualenv的安装
git clone https://github.com/yyuu/pyenv-virtualenv.git echo 'eval "$( pyenv virtualenv - init -) "'>>/etc/profile source /etc/profile
3、pyenv-virualenv的使用
有了pyenv-virtualenv以后,我们可以为同一个Python解释器,创建多个不同的工作环境。例如,我们新建两个工作环境:
pyenv virtualenv 2.7.13 first_project
pyenv virtualenv 2.7.13 second_project
使用virtualenvs指明了查看工作环境
pyenv virtualenvs
进入/退出/删除virtualenv虚拟环境
1、activate进入一个工作环境 pyenv activate first_project 2、deactivate退出一个工作环境 pyenv deactivate first_project
3、virtualenv-delete删除虚拟环境
pyenv virtualenv-delete first_project
二、文本处理
一、Jinja2
中文文档:https://www.kancloud.cn/manual/jinja2/70423
1、模板介绍
模板在Python的web开发中广泛使用,它能够有效地将业务逻辑和页面逻辑分离,使得工程师编写出可读性更好、更加容易理解和维护的代码。
web开发是最需要使用模板的地方,但是,并不是唯一可以使用模板的地方。模板使用范围比大多数工程师接触的都要广泛,因为模板适合所有基于文本的格式,如HTML,XML,CSV,LaTeX等。
使用模板能够编写出可读性更好、更容易理解和维护的代码,并且使用范围非常广泛,因此怎么使用模板主要取决于工程师的想象力和创造力。例如,本书第十章即将介绍的Ansible就使用Jinja2来管理配置文件。
作为工程师,我们也可以使用Jinja2管理工作中的配置文件。一旦学会使用模板管理配置文件,就可以摆脱无数琐碎的文本替换工作。
Python自带的模板功能非常有限,例如无法在模板中使用控制语句和表达式,不支持继承和重用等操作。这对于web开发来说远远不够,因此,出现了第三方的模板系统。目前市面上有非常多的模板系统,其中最知名的是Jinja2和Mako。
2、Jinja2语法入门
Jinja2是Flask作者开发的一个模板系统,起初是仿Django模板的一个模板引擎,为Flask提供模板支持。但是,由于其灵活、快速和安全等优点被广泛使用。
1、Jinja2模板引擎之所以使用广泛,是因为它具有以下优点:
- 相对于Template,Jinja2更加灵活,它提供了控制结构、表达式和继承等,工程师可以在模板中做更多的事情;
- 相对于Mako,Jinja2提供了仅有的控制结构,不允许在模板中编写太多的业务逻辑,避免了工程师乱用行为;
- 相对于Django模板,Jinja2的性能更好;
- Jinja2模板的可读性很好。
2、Jinja2是Flask的一个依赖,如果已经安装了Flask,Jinja2也会随之安装。当然,也可以单独安装Jinja2
pip install jinja2
3、语法块
在jinja2中,存在三种语法:
1 控制结构 {% %} 2 变量取值 {{ }} 3 注释 {# #}
范例
{% block body %}
<ul>
{% for user in users %}
<li><a href="{{ user.url }}">{{ user.username }}</a></li>
{% endfor %}
</ul>
{% endblock %}
4、变量
Jinja2模板中使用的 {{ }} 语法表示一个变量,它是一种特殊的占位符,告诉模板引擎这个位置的值在渲染模板时获取。Jinja2识别所有的Python数据类型,甚至是一些复杂的类型,如列表、字典和对象等

5、Jinja2的过滤器
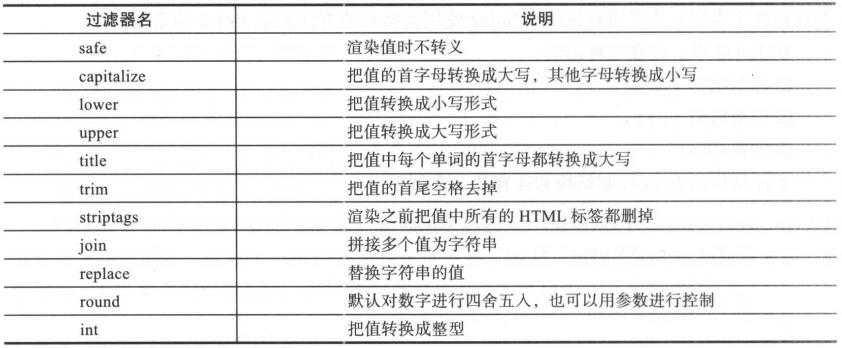
变量可以通过“过滤器”进行修改,过滤器可以理解为是Jinja2里面的内置函数和字符串处理函数。
Jinja2比较常用的过滤器:
在Jinja2中,变量可以通过“过滤器”修改,过滤器与变量用管道(|)分割。多个过滤器可以链式调用,前一个过滤器的输出会作为后一个过滤器的输入。如下所示:

6、Jinja2的控制结构
Jinja2中的if语句类似于Python中的if语句,但是,需要使用endif语句作为条件判断的结束。我们可以使用if语句判断一个变量是否定义,是否为空,是否为真值。与Python中的if语句一样,也可以使用elif和else构建多个分支,如下所示:

7、Jinja的for循环
Jinja2中的for语句可用于迭代Python的数据类型,包括列表、元组和字典。在Jinja2中不存在while循环,这也符合了Jinja2的“提供仅有的控制结构,不允许在模板中编写太多的业务逻辑,避免了工程师乱用行为”设计原则。

除了基本的for循环使用以外,Jinja2还提供了一些特殊的变量,我们不用定义就可以直接使用这些变量。列出了Jinja2循环中可以直接使用的特殊变量。
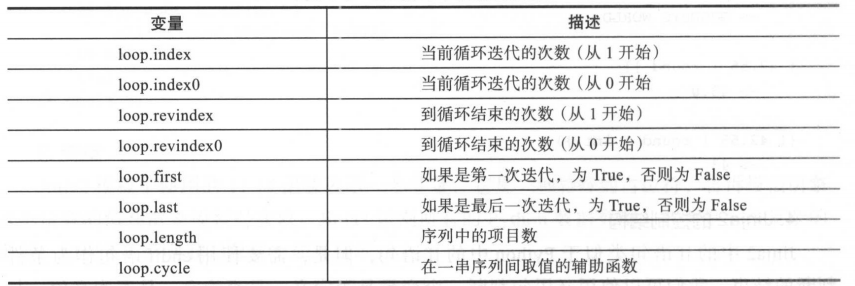
6、Jinja2的宏
Jinja2宏的简单使用:http://makaidong.com/printN/3301_768547.html
Jinja2宏问题解决:https://blog.csdn.net/qq_34062683/article/details/78234695
宏类似于语言中的函数,用于将行为抽象成可重复调用的代码块。与函数一样。宏分为定义与调用两个阶段。

在宏的定义中,使用macro关键字定义一个宏,input是宏的名称。它有三个参数,分别是name,type和value,其中type和value参数有默认值。可以看到宏的定义与Python的函数定义非常相似,此外,它与Jinja2中的for循环和if语句一样,不需要使用复合语句的冒号,使用endmacro结束宏的定义。
下面是宏的调用,与函数调用类似:

import jinja2 rules={ "name":"xxxxxxx", "rules":[ { "alert": "z1", "expr": "up == 0", "duration": "1m", "enable": 1, "labels":{"labels1":"label1","label2":"label2"}, "annotations":{"annotations":"annotations"} }, { "alert": "z2", "expr": "up == 0", "duration": "1m", "enable": 1, "labels":{"label1":"label1","label2":"label2"}, "annotations":{"annotation1":"annotation1", "annotation2":"annotation2"} } ], "desc":"group DESC NEW1" } RENDER_RULES_TEMPLATE = """groups: - name: {{ rules.name }} rules: {%- for alert in rules.rules %} - alert: {{ alert.alert }} expr: {{ alert.expr}} for: {{ alert.duration }} labels: {%- for item in alert.labels %} {{ item }}: {{ alert.labels[item] }} {%- endfor %} annotations: {%- for item in alert.annotations %} {{ item }}: {{ alert.annotations[item] }} {%- endfor %} {% endfor %} """ result = jinja2.Template(source=RENDER_RULES_TEMPLATE).render(rules=rules) with open('result.yml','w') as fp: fp.write(result)
9、Jinja2的集成和super函数
若只是使用Jinja2进行配置文件管理,基本用不到Jinja2的继承功能。若使用Jinja2进行web开发。
Jinja2中最强大的部分就是模板继承。模块继承允许你构建一个包含站点共同元素的基本模板“骨架”,并定义子模块可以覆盖的块。
三、Linux系统管理
一、文件读写
1、Python内置的open函数
文件打开的模式

操作示例
f = open('data1.txt','w',encoding='utf-8') # print(f.read()) f.write('hello, world') f.close()
2、避免文件句柄泄露:使用try....finally
使用try....finally
try: f = open('data.txt',encoding='utf-8') print(f.read()) finally: f.close()
对于文件打开、处理、再关闭的逻辑,使用上下文管理器的代码(使用with语句):
with open('data.txt',encoding='utf-8') as f: print(f.read())
3、常见的文件操作函数
Python的文件对象有多种类型的函数,如刷新缓存的flush函数,获取文件位置的tell函数,改变文件读取偏移量的seek函数。
1、Python中读的相关函数
- read :读取文件中的所有内容 ;
- readline : 一次读取一行;
- readlines :将文件内容存到一个列表中,列表中的每一行对应于文件中的一行 。
read 函数和 readlines 函数都是一次就将所有内容读入到内存中 。处理的是小文件还是可以的,若大文件,占用内存太多,甚至会出现Out-Of-Memory错误。所以避免这样操作。
2、Python中写的相关函数
- write:写字符串到文件中,并返回写入的字符数;
- writelines:写一个字符串列表到文件中。
在Python中,除了使用文件对象的write函数和writelines函数向文件写入数据以外,也可以使用print函数将输出结果输出到文件中。print函数比write和writelines函数更加灵活。
# 导入功能模块
from __future__ import print_function with open('data.txt','w') as f: print(1, 2, 'hello world', sep=",", file=f)
4、Python的文件是一个可迭代对象
Python的for循环不但可以遍历如字符串、列表、元组这样的可迭代徐磊,还可以使用迭代器协议遍历可迭代对象。Python的文件对象实现了迭代器协议。
with open('data.txt') as inf: for line in inf: print(line.upper())
5、案例:将文件中所有单词的首字母变成大写
1、实现方式一:with语句
with open('data.txt') as inf, open('out.txt', 'w') as outf: for line in inf: outf.write(" ".join([word.capitalize() for word in line.split()])) outf.write("\n")
2、实现方式二:print函数来简化输出语句
from __future__ import print_function with open('data.txt') as inf, open('out_print.txt', 'w') as outf: for line in inf: print(*[word.capitalize() for word in line.split()], file=outf)
二、文件与文件路径管理
1、知识点连接
详情见Python的os模块:http://www.cnblogs.com/happy-king/p/7704487.html#_label4
2、案例:打印最常用的10条Linux命令
当我们在Shell中输入命令并执行时,有非常多的快捷键可以提高我们的工作效率。例如,我们可以在Bash中使用ctrl+r搜索曾经执行过的Linux命令,之所以可以使用ctrl+r搜索曾经执行过的Linux命令是因为Bash跟踪用户之前输入过的命令,并将其保存在~./bash_history文件中。我们可以使用history命令或者直接读取~./bash_history文件的内容来查看命令历史。
搜索历史命令的快捷键:ctrl+r
统计每条命令的出现次数,然后找出出现次数最多的10条命令。
1 import os 2 from collections import Counter 3 4 c = Counter() 5 with open(os.path.expanduser('~/.bash_history')) as f: 6 for line in f: 7 cmd = line.strip().split() 8 if cmd: 9 c[cmd[0]] += 1 10 11 12 CmdCount=c.most_common(10) 13 print(CmdCount)
三、文件内容管理
系统管理员在管理服务器时,可能会有这样的疑问:
- 两个目录中的文件到底有什么差别
- 系统中有多少重复文件存在
- 如何找到并删除系统中的重复文件
1、目录和文件比较:filecmp模块
1、cmp函数
filecmp模块最简单的函数是cmp函数,该函数用来比较两个文件是否相同,如果文件相同,返回True,否则返回False。
2、cmpfiles函数
cmpfiles函数用来同时比较两个不同目录下的多个文件,并且返回一个三元组,分别包含相同的文件、不同的文件和无法比较的文件。
cmpfiles函数用来同时比较两个目录下的文件,也可以使用该函数比较两个目录。但是,在比较两个目录时需要通过参数指定所有可能的文件,显然比较繁琐。
3、dircmp函数
调用dircmp函数以后会返回一个dircmp类的对象,该对象保存了诸多属性,工程师可以通过读取这些属性的方式获取目录之间的差异。
filecmp 模块的 dircmp 函数仅仅比较目录下面的文件和子目录 ,但是,并不会递归比较子目录的内容 。 对于目录, dircmp 函数也仅仅是比较函数的名称 ,不会去比较子目录里面的内容。
2、使用Python管理压缩包
shutil模块:http://www.cnblogs.com/happy-king/p/7704487.html#_label6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号