Python基础学习——文件操作、函数
一、文件操作
文件操作链接:http://www.cnblogs.com/linhaifeng/articles/5984922.html(更多内容见此链接)
编码发展史
- 美国人发明了计算机,用八位0和1的组合,一一对应英文中的字符,整出了一个表格,ASCII表。
- 计算机传入中国,中国地大物博,繁体字和简体字多,8位字节最多表示256个字符,满足不了,于是对ASCII扩展,新表叫GB2312
- 后来发现GB2312还不够用,扩充之后形成GB18030。
- 每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。
- 各自编码无法国际交流。一个国际组织一起创造了一种编码 UNICODE(Universal Multiple-Octet Coded Character Set)规定所有字符用两个字节表示,就是固定的,所有的字符就两个字节,计算机容易识别。2的16次方可以表示所有的字符了。
- UNICODE虽然解决了各自为战的问题,但是美国人不愿意了,因为美国原来的ASCII只需要一个字节就可以了。UNICODE编码却让他们的语言多了一个字节,白白浪费一个字节的存储空间。经过协商,出现了一种新的转换格式,被称为通用转换格式,也就是UTF(unicode transformation format).常见的有utf-8,utf-16。utf-8规定,先分类,美国字符一个字节,欧洲两个字符,东南亚三个字符。
encode()和decode()
- decode英文意思是 解码,encode英文原意 编码
- 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
- decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
- encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
- 总得意思:想要将其他的编码转换成utf-8必须先将其解码成unicode然后重新编码成utf-8,它是以unicode为转换媒介的 如:s='中文' 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用 decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件




''' ascii A : 00000010 8位 一个字节 unicode A : 00000000 00000001 00000010 00000100 32位 四个字节 中:00000000 00000001 00000010 00000110 32位 四个字节 utf-8 A : 00100000 8位 一个字节 中 : 00000001 00000010 00000110 24位 三个字节 gbk A : 00000110 8位 一个字节 中 : 00000010 00000110 16位 两个字节 1,各个编码之间的二进制,是不能互相识别的,会产生乱码。 2,文件的储存,传输,不能是unicode(只能是utf-8 utf-16 gbk,gb2312,asciid等) py3: str 在内存中是用unicode编码。 bytes类型 对于英文: str :表现形式:s = 'alex' 编码方式: 010101010 unicode bytes :表现形式:s = b'alex' 编码方式: 000101010 utf-8 gbk。。。。 对于中文: str :表现形式:s = '中国' 编码方式: 010101010 unicode bytes :表现形式:s = b'x\e91\e91\e01\e21\e31\e32' 编码方式: 000101010 utf-8 gbk。。。。 ''' # 编码 # 英文 # s1 = 'wzs' # # encode 编码,如何将str-->bytes # # s11 = s1.encode('utf-8') # s11 = s1.encode('gbk') # # s11 = s1.encode('gb2312') # print(s11) # 中文 s2 = '中国' # s21 = s2.encode('utf-8') #结果:b'\xe4\xb8\xad\xe5\x9b\xbd' # s21 = s2.encode('gbk') #结果 b'\xd6\xd0\xb9\xfa' s21 = s2.encode('gb2312') #结果 b'\xd6\xd0\xb9\xfa' print(s21)
一)对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过文件句柄对文件进行操作
- 关闭文件
二)文件操作
1、范例
#打开 f=open('a.txt',mode='r',encoding='utf-8') # 读/写 data=f.read() print(data) #关闭 del f #回收Python的资源 f.close() ##回收操作的资源
2、文件操作的流程分析
- 向操作系统发起系统调用
- 操作系统打开这个文件,返回一个文件句柄给应用程序
- 在应用程序中把文件句柄赋值给一个变量
3、注意两点
1、打开一个文件对应两部分,一个是Python级别的文件句柄,另一个是操作系统打开的文件(默认打开文件的编码是以操作系统的编码为准的,除非open()指定encoding='编码')
2、当文件操作完毕后,应该回收两部分资源:
del f #回收应用程序资源(Python解释器自动的垃圾回收机制已经处理完毕)
f.close #回收操作系统的资源
三)文件处理:with语句
with open('a.txt',mode='r',encoding='utf-8') as f: print(f.read())
1、文本类文件操作,操作模式t(text),可省略
1、r 是默认的文件操作模式,只读,文件不存在则报错
with open('a.txt',mode='r',encoding='utf-8') as f: print(f.readlines()) #读所有行,结果放入列表中(适用于小文件) print(f.readline(),end='') #读一行,去掉后面的换行符 print(f.read()) #读所有:bytes---->decode('utf-8')---->str
2、w 只写模式,若文件存在则清空,若文件不存在则新建
with open('b.txt',mode='w',encoding='utf-8') as f: f.write('11111\n') #写一行 :unicode---->encode(utf-8)---->bytes f.writelines(['881899\n','文件\n','qiiqwhuq']) ##写多行
3、a 追加写模式,若文件存在则把光标已到文件末尾,若文件不存在则新建
with open('c.txt',mode='a',encoding='utf-8') as f: f.write('1899\n') f.writelines(['OK\n','权限\n'])
2、文本类文件操作,操作模式b类型:以bytes的形式去操作文件内容,不能指定编码(不然会报错):可以操作任何类型的文件以读取图片为例
with open('weiduoliya.jpg',mode='rb') as f: print(f.read()) with open('d.txt',mode='wb') as f: f.write('alex最牛\n'.encode('utf-8')) with open('d.txt',mode='ab') as f: f.write('engon最棒\n'.encode('utf-8'))
四)打开文件的模式
下面的模式可以自由组合
- ‘r' open for reading (default)
- ‘w' open for writing, truncating the file first
- ‘a' open for writing, appending to the end of the file if it exists
- ‘b' binary mode
- ‘t' text mode (default)
- ‘+' open a disk file for updating (reading and writing)
- ‘U' universal newline mode (for backwards compatibility; should not be used in new code)
#1. 打开文件的模式有(默认为文本模式): r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) rb wb ab 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 #3. 了解部分 "+" 表示可以同时读写某个文件 r+, 读写【可读,可写】 w+,写读【可读,可写】 a+, 写读【可读,可写】 x, 只写模式【不可读;不存在则创建,存在则报错】 x+ ,写读【可读,可写】 xb
五)操作文件的方法
#掌握 f.read() #读取所有内容,光标移动到文件末尾 f.readline() #读取一行内容,光标移动到第二行首部 f.readlines() #读取每一行内容,存放于列表中 f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符 f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符 f.writelines(['333\n','444\n']) #文件模式 f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式 #了解 f.readable() #文件是否可读
f.truncate #_ 截取文件 f.writable() #文件是否可读
f.tell() #告知光标所在的位置
f.truncate #截取文件,以字节为单位
f.seek #指定光标移动到某个位置 f.closed #文件是否关闭 f.encoding #如果文件打开模式为b,则没有该属性 f.flush() #立刻将文件内容从内存刷到硬盘 f.name
六)文件内光标移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0(文件开头),1(当前位置),2(文件末尾),其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
1、简单实践
0 文件开头seek
with open('a.txt', 'r', encoding="utf-8") as f: f.seek(3, 0) print(f.read())
1 文件当前位置seek
with open('a.txt', 'rb') as f: f.seek(-3, 1) print(f.read().decode('utf-8'))
truncate只保留部分内容
with open('access.log', 'a+', encoding='utf-8') as f: f.truncate(1)
2、实现tail -f
tailf.py
import time with open('access.log', 'rb') as f: f.seek(0, 2) while 1: line = f.readline() if line: print(line.decode('utf-8'), end='') else: time.sleep(1)
向日志文件写内容
with open('access.log', 'a', encoding='utf-8') as f: for i in range(3): f.write('info 欢迎你归来\n')
七)文件的修改
open的参数全部写上,操作多个文件时,可以换行(避免一行内容过多)
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: data=read_f.read() #全部读入内存,如果文件很大,会很卡 data=data.replace('alex','SB') #在内存中完成修改 write_f.write(data) #一次性写入新文件 os.remove('a.txt') os.rename('.a.txt.swap','a.txt')
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: for line in read_f: line=line.replace('alex','SB') write_f.write(line) os.remove('a.txt') os.rename('.a.txt.swap','a.txt')
八)实战
1、bool值 :所有数据类型都自带bool值
- 布尔值为假的情况 0 空 None
- #真默认返回True ,假默认返回False
x = 1 # print(bool(x)) if x: print('ok')
2、循环文件
with open('a.txt',encoding='utf-8') as f: #不推荐使用:消耗资源(磁盘IO) lines = f.readlines() #一下读取所有内容 for line in lines: print(line,end='') #推荐使用:读取一行,打印一行内容 for line in f: print(line,end='')
二、函数
一)函数简介
1、为什么要用函数?换句话讲不用函数,会怎么样?
- 组织结构混乱,可读性差
- 代码冗余(重复的代码比较多)
- 无法统一管理,维护难度极大
2、什么叫做函数?使用原则?
函数:具有某一功能的工具
使用原则:先定义,后调用
1 2 3 4 5 6 7 8 9 10 | #定义阶段def tell_tag(): print('===========')def tell_msg(msg): print(msg)#调用阶段tell_tag()tell_msg('hello world') |
3、函数分类
1、内置函数:Python解释器自带的函数,Python解释器启动就会定义好这些函数
例如:len(),min(),max()
2、自定义函数:根据需要用户自己定义的函数(函数名和函数体是必须有的)
1 2 3 4 | def 函数名(参数1,参数2,...): """注释""" 函数体 return 返回值 |
二)函数的定义阶段
在定义阶段,只检测语法,不执行代码
函数的定义,将相当于在定义一个变量;若没有定义而直接调用,就相当于没有在引用不存在的变量名。
1、怎么定义函数
1 def foo(): 2 xyz 3 print('111') 4 return 1 5 print('222') 6 return 2
2、函数的原则:先定义后调用
1 #测试1 2 def foo(): 3 print('from foo') 4 bar() ##bar没有定义就调用,错误 5 foo() 6 7 # 测试2 正确 8 def bar(): 9 print('from bar') 10 def foo(): 11 print('from foo') 12 bar() 13 foo() 14 15 # 测试3 下面的也不会报错, 16 ###定义阶段 17 def foo(): 18 print('from foo') 19 bar() 20 def bar(): 21 print('from bar') 22 #调用阶段 23 foo()
3、定义函数的三种形式
1 无参:应用场景——只执行一些操作,例如:打印等等 2 有参:需要根据外部传进来的参数,才能执行相应的逻辑,例如比较大小,统计数量 3 空函数:设计代码结构
1 def main(): 2 while True: 3 user=input('>>:').strip() 4 # if len(user) == 0:continue #若长度为0,下面的代码不执行 5 if not user:continue 6 password=input('>>:') 7 res=auth(user,password) 8 if res: 9 print('login sucessful') 10 else: 11 print('login error')
1 def auth(user,pwd): 2 if user == 'egon' and pwd == '123': 3 return True 4 else: 5 return False 6 7 main()
1 def select(sql): 2 #注释:输入'''''',回车自动输出下面的格式 3 ''' 4 查询功能 5 :param sql: 6 :return: 7 ''' 8 pass
三)调用函数
1、调用函数
1 2 | 函数的调用:函数名加括号 先找到名字找到函数的内存地址,然后根据名字调用代码 |
2、函数的返回值
什么时候该有返回值?
调用函数,经过一系列的操作,最后要拿到一个明确的结果,则必须要有返回值
通常有参函数需要有返回值,输入参数,经过计算,得到一个最终的结果
什么时候不需要有返回值?
调用函数,仅仅只是执行一系列的操作,最后不需要得到什么结果,则无需有返回值
通常无参函数不需要有返回值
需要注意以下的第一点:
1 2 | 在调用函数的过程中,一旦执行到return,就会立刻终止函数,并且把return后的结果当做本次调用的返回值返回#函数体内可以有多个return,但是只能执行一次 |
1 def test(): 2 print('test1') 3 # return 1 4 print('test2') 5 return 2 6 print('test3') 7 return 3 8 res=test() 9 print('函数调用完毕',res)
需要注意第二点:
1 | 返回的值,可以是任意类型 |
1 #msg={'name':'wzs','sex':'male'} 2 msg=['wzs','egon'] 3 def test(): 4 print('test1') 5 return msg 6 res=test() 7 print('函数调用完毕',res)
需要注意的第三点:
没有返回值 —— 返回None 不写return 只写return:结束一个函数的继续 return None —— 不常用 返回1个值 可以返回任何数据类型 只要返回就可以接收到 如果在一个程序中有多个return,那么只执行第一个 返回多个值 用多个变量接收:有多少返回值就用多少变量接收 用一个变量接收: 得到的是一个元组(touple)
1 def test(): 2 return None 3 res=test() 4 print('函数调用完毕',res,type(res)) 5 print('函数调用完毕',res)
3、调用的三种方式
1 2 3 | 1 语句形式:foo()2 表达式形式:3*len('hello')3 当中另外一个函数的参数:range(len('hello')) |
四)函数的参数
1、形参与实参
1 2 3 | 形参:在定义阶段,括号内定义的参数。就相当于变量名实参:在调用阶段,括号内定义的参数。就相当于变量值在调用阶段,实参的值会绑定给形参,在调用结束后,解除绑定 |
2、参数的分类
1、位置参数
1 2 | 位置形参:必须被传值的参数,多少都不行位置实参:从左到右依次赋值给形参 |
1 def foo(x,y): 2 print(x,y) 3 foo(1,3)
2.关键字参数:在函数调用阶段,按照key=value的形式定义实参
1 2 3 4 5 | 特性: 1、可以不依赖位置而指明参数给形参传参 2、可以与位置实参混用,需要注意: 1)位置参数必须在位置参数前面 2)不能为一个形参重复传值 |
1 def foo(x,y): 2 print(x,y) 3 4 # foo(y=2,x=3) 5 # foo(3,y=2) 6 # foo(1,2,y=3) 错误
3、默认参数(形参):在函数定义阶段,已经为形参赋值了,意味着调用阶段可以不传值
1 2 3 4 | 注意的问题: 1、默认参数的值,只在定义阶段,赋值一次 2、位置形参应该默认参数的前面 3、默认参数的值应该是不可变类型(数字,字符串,元组) |
1 def foo(x,y): 2 print(x,y) 3 foo(1,y=3) 4 5 6 应用场景:学员注册 7 def resister(name,age,sex='male'): 8 print(name,age,sex) 9 10 resister('wzs',20) 11 resister('xiaoyu',27,'female') 12 13 x='male' 14 def resister(name,age,sex=x): 15 print(name,age,sex) 16 17 x='female' # 18 resister('wzs',20) #只在定义阶段,赋值一次 19 resister('xiaoyu',27,'female') 20 21 def resister(name,sex='male',age): #错误:位置形参必须在默认参数前面 22 print(name,age,sex) 23 24 resister('wzs',20) 25 resister('xiaoyu',27,'female')
4、可变长参数:实参值的个数是不固定的
1 2 3 | 实参定义形式有两种:1、位置实参 2、关键字实参针对这种形式的实参个数不固定,相应的,形参也要有两种解决方案位置实参:* 关键字实参:** |
针对按照位置定义的溢出的那部门实参,形参:*args *后面的是变量名,可以随便定义但以args
1 def func(a,b,c,*args): 2 print(a,b,c) 3 print(args) 4 5 func(1,2,3) 6 func(1,2,3,4,5,57) 7 func(1,2,3,*[4,5,57]) ##见到*将列表内容打散func(1,2,3,4,5,57) 8 func(*[1,2,3,4,5,57]) ##func(1,2,3,4,5,57) 9 # func([1,2,3,4,5,57]) #func(1,2,3,4,5,57) ##这个是错误的
针对按照关键字定义的溢出的那部分实参,形参:**kwargs
1 def foo(x,y,**kwargs): #kwargs={'a':1,'z':3,'b':2} 2 print(x,y) 3 print(kwargs) 4 5 foo(y=2,x=1,z=3,a=1,b=2) 6 # foo(1,2,3,z=3,a=1,b=2) #赋值不全 7 foo(y=1,x=2,**{'a':1,'b':2,'c':3}) #foo(x=2,y=1,c=3,b=2,a=1) 8 # foo(**{'x':1,'a':1,'b':2,'c':3}) #foo(x=1,c=3,b=2,a=1) #少一个y 9 10 def foo(x,y,z): 11 print(x,y,z) 12 13 dic={'x':1,'y':3,'z':1} 14 foo(**dic) #foo(x=1,y=3,a=1) 15 16 def home(name,age,sex): 17 print('from home====>',name,age,sex) 18 19 def wrapper(*args,**kwargs): #args=(1,2,3,4,5,6,7),kwargs={'c':3,'b':2,'a':1} 20 home(*args,**kwargs) 21 # home(*(1,2,3,4,5,6,7),**{'c':3,'b':2,'a':1}) 22 #home(1,2,3,4,5,7,a=1,b=2,c=3) 23 24 # wrapper(1,2,3,4,5,6,7,a=1,b=2,c=3) 25 wrapper('egon',sex='male',age=19)
5、命名关键字参数(了解)
1 2 | 形参中,在*后定义的参数特性:传值时,必须按照关键字实参的形式传值 |
1 def func(a,b=100,*args,c=1,d): 2 print(a,b,c,d) 3 print(args) 4 5 func(10000,d=10) 6 func(10,10000,1,45,555,c=1100,d=8999)
这五种参数的排列顺序为:位置参数,默认参数,*args,命名关键字参数,**kwargs
五)函数对象
函数是第一类对象:函数可以当做数据来使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # 1、可以对调用def func(): print('from func')f=funcprint(f) ##返回函数的内存地址f()# 2、可以当做参数传入一个函数def wrapper(x): print(x) x()wrapper(func)# 3、可以当做函数的返回值def wrapper(): return funcf1=wrapper()print(f1 is func)# 4、可以当做容器类型的一个元素l=[func,1,2] ##当列表的一和元素print(l) #打印列表print(l[0]()) ##取出函数这个元素,并执行函数 |
通过此特性可以取代if..elif ...else
1 def insert(sql): 2 print('insert功能: ', sql) 3 4 def update(sql): 5 print('update功能: ', sql) 6 7 def delete(sql): 8 print('delete功能: ', sql) 9 10 def alter(sql): 11 print('alter功能:',sql) 12 13 func_dic={ 14 'select':select, 15 'update':update, 16 'insert':insert, 17 'delete':delete, 18 'alter':alter 19 } 20 21 def main(): 22 while True: 23 inp=input('>>: ').strip() 24 if not inp:continue 25 sql=inp.split() 26 cmd=sql[0] 27 # if cmd == 'select': 28 # select(sql) 29 # elif cmd == 'update': 30 # update(sql) 31 # elif cmd == 'insert': 32 # insert(sql) 33 # elif cmd == 'delete': 34 # delete(sql) 35 if cmd in func_dic: 36 func_dic[cmd](sql) 37 else: 38 print('command not found') 39 40 main()
六)嵌套函数
1、函数的嵌套调用:在调用一个函数的过程中,又调用另外一个函数
#比较四个数字,找出最大值(两两比较大小)
1 2 3 4 5 6 7 8 9 10 11 12 13 | def max2(x,y): if x > y: return x else: return ydef max4(x,y,z,o): res1=max2(x,y) res2=max2(res1,z) res3=max2(res2,o) return res3res=max4(100,111,222,9888)print(res) |
2、函数的嵌套定义:在定义一个函数内部,又定义一个函数(函数只能同级调用)
def f1(): def f2(): x = 2 def f3(): x = 3 print(f'from f{x}') f3() print(f'from f{x}') x = 1 f2() print(f'from f{x}') f1()
三、名称空间和作用域
一)名称空间:存放名字与值绑定关系的地方
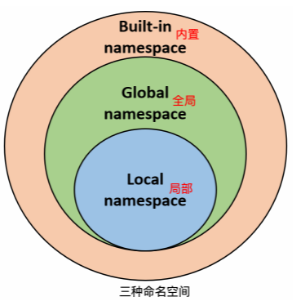
内置名称空间
存放的是:内置的名字和值的绑定关系:内置函数len
生效:Python解释器启动
失效:Python解释器关闭
全局名称空间(文件级别)
存放的是:文件级别定义的名字和值的绑定关系
生效:执行Python文件时,将该文件级别定义的名字和值的绑定关系存在
失效:文件执行完毕
局部名称空间
存放的是:函数内部定义的名字和值的绑定关系
生效:调用函数时,临时生效??
失效:函数调用结束
加载顺序:
先内置,再全局,最后局部
查找名字的顺序:
先局部,再全局,最后内置
二)作用域
作用域:http://www.cnblogs.com/z360519549/p/5172020.html
全局作用域:
包含内置名称空间的名字与全局名称空间的名字
特点:全局存活,全局有效
局部作用域:
包含局部名称空间的名字
特点:临时存活,局部有效
1 x=99009999 2 def f1(a): 3 y='abcdefg' 4 print(locals()) 5 print(globals()) 6 7 8 ##在全局作用域 locals() is globals() 9 print(globals()) 10 print(locals() is globals()) 11 # f1(1)
作用域关系:
在函数定义时,已经固定,与调用无关
1 x=1000000000 2 def f1(): 3 def f2(): 4 x=819892011921818 5 print(x) 6 # f2() #全局变量,局部临时生效 7 return f2 8 f=f1() 9 # print(f) 10 # print(x) ##返回变量的值是全局的定义值 11 12 def func(): 13 x=123 14 # f() 15 x='hello' 16 func()
1、global与nonlocal
#全局不可变类型,要改需要加上global(但是要避免这么做) x=1 def f1(): global x x=2 f1() print(x) #全局可变类型,直接进行修改即可 l=[] def f2(): l.append('f2') f2() print(l) ##nonlocal
x=0
def f1():
x=1
def f2():
# nonlocal x
x=2
def f3():
# nonlocal x ##跳出当前一层,改的他的上层变量
x=3
print("f3",x)
f3()
print("f2", x)
f2()
print("f1", x)
f1()
print("global", x)
2、查看作用域 global(),local()
名字查找顺序:locals -> enclosing function -> globals -> __builtins__
python引用变量的顺序: 当前作用域局部变量->外层作用域变量->当前模块中的全局变量->python内置变量 。 locals 是函数内的名字空间,包括局部变量和形参 enclosing 外部嵌套函数的名字空间(闭包中常见) globals 全局变量,函数定义所在模块的名字空间 builtins 内置模块的名字空间
1 global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字 2 声明全局变量,如果在局部要对全局变量修改,需要在局部也要先声明该全局变量:(使用global) 3 在局部如果不声明全局变量,并且不修改全局变量。则可以正常使用全局变量 4 nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量 :只能用于局部变量,找离当前函数最近一层的局部变量


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具