kubernetes运维管理
node的管理、label的管理、namespace的资源共享、资源配额管理、集群master高可用及集群监控
一、kubernetes集群管理工具kubectl、helm
一)kubectl
1、命令自动补全
若要马上生效,直接执行 source 的命令而不是添加到文件里面
二)helm
https://www.cnblogs.com/happy-king/p/15170507.html
1、helm自动补全
echo "source <(helm completion bash)" >> /etc/profile
二、Node管理
一)使用kubectl cordon和uncordon命令
使用kubectl子命令cordon和uncordon也可以实现Node的隔离调度和恢复调度
- 运行kubectl cordon <node_name>命令对某个Node进行隔离调度操作
- 运行kubectl uncordon <node_name>命令对某个Node进行恢复调度操作:
二)Node的扩容
在Kubernetes集群中,一个新Node的加入是非常简单的。在新的Node上安装docker、kubelet和kube-proxy服务,然后配置kubelet和kube-proxy服务的启动参数,将Master URL指定为当前Kubernetes集群Master的地址,最后启动这些服务。通过kubelet服务默认的自动注册机制,新的Node将自动加入现有的Kubernetes集群中
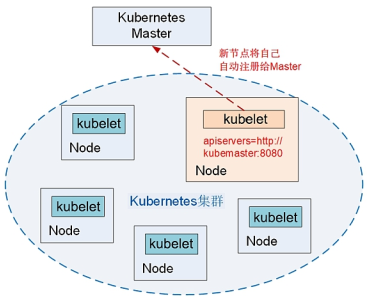
三)Node驱逐
Node控制器在节点异常后,会按照默认的速率(--node-eviction-rate=0.1,即每10秒一个节点的速率)进行 Node 的驱逐。Node 控制器按照 Zone 将节点划分为不同的组,再跟进Zone的状态进行速率调整:
Normal:所有节点都 Ready,默认速率驱逐。
PartialDisruption:即超过33% 的节点NotReady的状态。当异常节点比例大于--unhealthy-zone-threshold=0.55 时开始减慢速率:
- 小集群(即节点数量小于--large-cluster-size-threshold=50):停止驱逐
- 大集群,减慢速率为--secondary-node-eviction-rate=0.01
FullDisruption:所有节点都NotReady,返回使用默认速率驱逐。但当所有 Zone都处在FullDisruption时,停止驱逐。
三、更新资源对象的Label
Label(标签)是用户可灵活定义的对象属性,对于正在运行的资源对象,我们随时可以通过kubectl label命令进行增加、修改、删除等操作
(1)给已创建的Pod“redis-master-bobr0”添加一个Lable“role=backend”
kubectl label pod redis-master-bobr0 role=backend
(2)查看该Pod的Label
kubectl get pods -L role
(3)删除一个Label,只需在命令行最后指定Label的key名并与一个减号相连即可
kubectl label pod redis-master-bobr0 role-
(4)修改一个Label的值,需要加上--overwrite参数
kubectl label pod redis-master-bobr0 role=master --overwrite
四、Namespace:集群环境共享与隔离
在一个组织内部,不同的工作组可以在同一个Kubernetes集群中工作,Kubernetes通过Namespace(命名空间)和Context的设置对不同的工作组进行区分,使得它们既可以共享同一个Kubernetes集群的服务,也可以互不干扰
1、创建namespace
2、定义Context
通过kubectl config set-context命令定义Context,并将Context置于之前创建的命名空间中
kubectl config set-cluster kubernetes-cluster --server=https://192.168.1.128:8080 kubectl config set-context ctx-dev --namespace=development kubectl config set-context ctx-prod --namespace=production #通过kubectl config view命令查看已定义的Context
3、设置工作组在特定Context中工作
通过kubectl config use-context <context_name>命令设置当前运行环境
切换环境:kubectl config use-context cxt-prod
五、kubernetes资源管理
一)计算资源管理
可以全面限制一个应用及其中的Pod所能占用的资源配额。具体包括三种方式:
- 定义每个Pod上资源配额相关的参数,比如CPU/Memory Request/Limit;
- 自动为每个没有定义资源配额的Pod添加资源配额模板(LimitRange);
- 从总量上限制一个租户(应用)所能使用的资源配额的ResourceQuota。
允许集群的资源被超额分配,以提高集群的资源利用率,同时允许用户根据业务的优先级,为不同的Pod定义相应的服务保障等级(QoS)。我们可以将Qos理解为“活命优先级”,当系统资源不足时,低等级的Pod会被操作系统自动清理,以确保高等级的Pod稳定运行。
对应到Kubernetes的Pod容器上,就是如下4个参数。
- spec.container[].resources.requests.cpu:容器初始要求的CPU数量。
- spec.container[].resources.limits.cpu:容器所能使用的最大CPU数量。
- spec.container[].resources.requests.memory:容器初始要求的内存数量。
- spec.container[].resources.limits.memory:容器所能使用的最大内存数量
是以十进制表示的字节单位,比如:
- 1 KB(KiloByte)=1000 Bytes=8000 Bits;
- 1 KiB(KibiByte)=210 Bytes=1024 Bytes=8192 Bits。
因此,128974848、129e6、129M、123Mi的内存配置是一样的。
Kubernetes的计算资源单位是大小写敏感的,因为 m可以表示千分之一单位(milli unit),而M可以表示十进制的1000,二者的含义不同;同理,小写的k不是一个合法的资源单位
基于Requests和Limits的Pod调度机制
当一个Pod创建成功时,Kubernetes调度器(Scheduler)会为该Pod选择一个节点来执行。对于每种计算资源(CPU和Memory)而言,每个节点都有一个能用于运行Pod的最大容量值。
调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值
计算资源使用情况监控
Pod的资源用量会作为Pod的状态信息一同上报给Master。如果在集群中配置了Heapster来监控集群的性能数据,那么还可以从Heapster中查看Pod的资源用量信息
二)资源配置范围管理(LimitRange)
在默认情况下,Kubernetes不会对Pod加上CPU和内存限制,这意味着Kubernetes系统中的任何Pod都可以使用其所在节点所有可用的CPU和内存。通过配置Pod的计算资源Requests和Limits,我们可以限制Pod的资源使用,但对于Kubernetes集群管理员而言,配置每一个Pod的Requests和Limits是很烦琐的,而且很受限制
对集群内Requests和Limits的配置做一个全局限制。常见的配置场景:
- 集群中的每个节点都有2GB内存,集群管理员不希望任何Pod申请超过2GB的内存,因为在整个集群中都没有任何节点能满足超过2GB内存的请求。如果某个Pod的内存配置超过2GB,那么该Pod将永远无法被调度到任何节点上执行。为了防止这种情况的发生,集群管理员希望能在系统管理功能中设置禁止Pod申请超过2GB内存。
- 集群由同一个组织中的两个团队共享,分别运行生产环境和开发环境。生产环境最多可以使用8GB内存,而开发环境最多可以使用512MB内存。集群管理员希望通过为这两个环境创建不同的命名空间,并为每个命名空间都设置不同的限制来满足这个需求。
- 用户创建Pod时使用的资源可能会刚好比整个机器资源的上限稍小,而恰好剩下的资源大小非常尴尬,不足以运行其他任务,但整个集群加起来又非常浪费。因此,集群管理员希望将每个Pod都设置为必须至少使用集群平均资源值(CPU和内存)的20%,这样集群就能够提供更好的资源一致性调度,从而减少资源浪费。
1、创建一个命名空间
2、为命名空间设置LimitRange
下面解释LimitRange中各项配置的意义和特点。
(1)不论是CPU还是内存,在LimitRange中,Pod和Container都可以设置Min、Max和Max Limit/Requests Ratio参数。Container还可以设置Default Request和Default Limit参数,而Pod不能设置Default Request和Default Limit参数。
(2)对Pod和Container的参数解释如下。
- Container的Min(上面的100m和3Mi)是Pod中所有容器的Requests值下限;Container的Max(上面的2和1Gi)是Pod中所有容器的Limits值上限;Container的Default Request(上面的200m和100Mi)是Pod中所有未指定Requests值的容器的默认Requests值;Container的Default Limit(上面的300m和200Mi)是Pod中所有未指定Limits值的容器的默认Limits值。对于同一资源类型,这4个参数必须满足以下关系:Min≤Default Request≤Default Limit≤Max。
- Pod的Min(上面的200m和6Mi)是Pod中所有容器的Requests值的总和下限;Pod的Max(上面的4和2Gi)是Pod中所有容器的Limits值的总和上限。容器未指定Requests值或者Limits值时,将使用Container的Default Request值或者Default Limit值。
- Container的Max Limit/Requests Ratio(上面的5和4)限制了Pod中所有容器的Limits值与Requests值的比例上限;而Pod的Max Limit/Requests Ratio(上面的3和2)限制了Pod中所有容器的Limits值总和与Requests值总和的比例上限。
(3)如果设置了Container的Max,那么对于该类资源而言,整个集群中的所有容器都必须设置Limits,否则无法成功创建。Pod内的容器未配置Limits时,将使用Default Limit的值(本例中的300m CPU和200MiB内存),如果也未配置Default,则无法成功创建。
(4)如果设置了Container的Min,那么对于该类资源而言,整个集群中的所有容器都必须设置Requests。如果创建Pod的容器时未配置该类资源的Requests,那么在创建过程中会报验证错误。Pod里容器的Requests在未配置时,可以使用默认值defaultRequest(本例中的200m CPU和100MiB内存);如果未配置而且没有使用默认值defaultRequest,那么默认等于该容器的Limits;如果容器的Limits也未定义,就会报错。
(5)对于任意一个Pod而言,该Pod中所有容器的Requests总和都必须大于或等于6MiB,而且所有容器的Limits总和都必须小于或等于 1GiB;同样,所有容器的CPU Requests总和都必须大于或等于200m,而且所有容器的CPU Limits总和都必须小于或等于2。
(6)Pod里任何容器的Limits与Requests的比例都不能超过Container的Max Limit/Requests Ratio;Pod里所有容器的Limits总和与Requests总和的比例都不能超过Pod的Max Limit/Requests Ratio。
3、创建Pod时触发LimitRange限制
最后,让我们看看LimitRange生效时对容器的资源限制效果。
命名空间中的LimitRange只会在Pod创建或者更新时执行检查。如果手动修改LimitRange为一个新的值,那么这个新的值不会去检查或限制之前已经在该命名空间中创建好的Pod。
如果在创建Pod时配置的资源值(CPU或者内存)超出了LimitRange的限制,那么该创建过程会报错,在错误信息中会说明详细的错误原因。
三)资源服务质量管理(Resource QoS)
kubernetes中Pod的Requests和Limits资源配置有如下特点。
- 如果Pod配置的Requests值等于Limits值,那么该Pod可以获得的资源是完全可靠的。
- 如果Pod的Requests值小于Limits值,那么该Pod获得的资源可分为两部分:
1、Requests和Limits对不同计算资源类型的限制机制
- 可压缩资源
- Kubernetes目前支持的可压缩资源是CPU
- Pod可以得到Requests配置的CPU使用量,而能否使用超过Requests值的部分取决于系统的负载和调度
- 空闲的CPU资源按照容器Requests值的比例分配
- 不可压缩资源
- Kubernetes目前支持的不可压缩资源是内存
- Pod可以得到在Requests中配置的内存
- 如果Pod的内存用量超过了它的Limits设置,那么操作系统内核会“杀掉”Pod所有容器的所有进程中内存使用量最多的一个,直到内存不超过Limits时为止
2、对调度策略的影响
- Kubernetes的kube-scheduler通过计算Pod中所有容器的Requests的总和来决定对Pod的调度。
- 不管是CPU还是内存,Kubernetes调度器和kubelet都会确保节点上所有Pod的Requests总和不会超过在该节点上可分配给容器使用的资源容量上限
3、服务质量等级(QoS Classes)
Kubernetes将容器划分成3个QoS等级:Guaranteed(完全可靠的)、Burstable(弹性波动、较可靠的)和BestEffort(尽力而为、不太可靠的),这三种优先级依次递
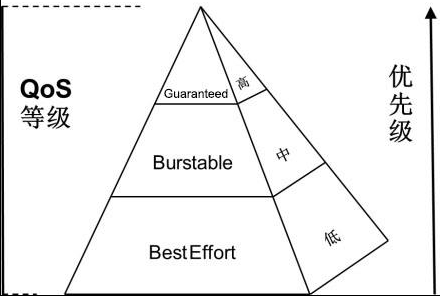
- Guaranteed(完全可靠的):容器的Limits值都和Requests值相等(且都不为0)
- Burstable(弹性波动、较可靠的)
- 第1种情况:Pod中的一部分容器在一种或多种资源类型的资源配置中定义了Requests值和Limits值(都不为0),且Requests值小于Limits值;
- 第2种情况:Pod中的一部分容器未定义资源配置(Requests和Limits都未定义)。
- 注意:在容器未定义Limits时,Limits值默认等于节点资源容量的上限。
- BestEffort(尽力而为、不太可靠的):Pod中所有容器都未定义资源配置(Requests和Limits都未定义)
4、Kubernetes QoS的工作特点
内存是不可压缩的资源,所以针对内存资源紧缺的情况,会按照以下逻辑处理。
- BestEffort Pod的优先级最低,在这类Pod中运行的进程会在系统内存紧缺时被第一优先“杀掉”。当然,从另一个角度来看,BestEffort Pod由于没有设置资源Limits,所以在资源充足时,它们可以充分使用所有闲置资源。
- Burstable Pod的优先级居中,这类Pod在初始时会被分配较少的可靠资源,但可以按需申请更多的资源。当然,如果整个系统内存紧缺,又没有BestEffort容器可以被杀掉以释放资源,那么这类Pod中的进程可能被“杀掉”。
- Guaranteed Pod的优先级最高,而且一般情况下这类Pod只要不超过其资源Limits的限制就不会被“杀掉”。当然,如果整个系统内存紧缺,又没有其他更低优先级的容器可以被“杀掉”以释放资源,那么这类Pod中的进程也可能会被“杀掉”。

四)资源配额管理(Resource Quotas)
在使用资源配额时,需要注意以下两点。
- 如果集群中总的可用资源小于各命名空间中资源配额的总和,那么可能会导致资源竞争。在发生资源竞争时,Kubernetes系统会遵循先到先得的原则。
- 不管是资源竞争还是配额修改,都不会影响已创建的资源使用对象
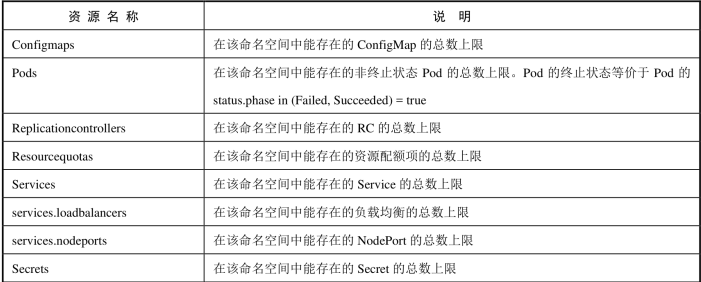
1、在Master中开启资源配额选型
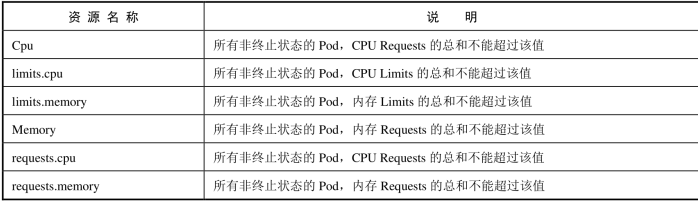
计算资源配额(Compute Resource Quota)
存储资源配额(Volume Count Quota)
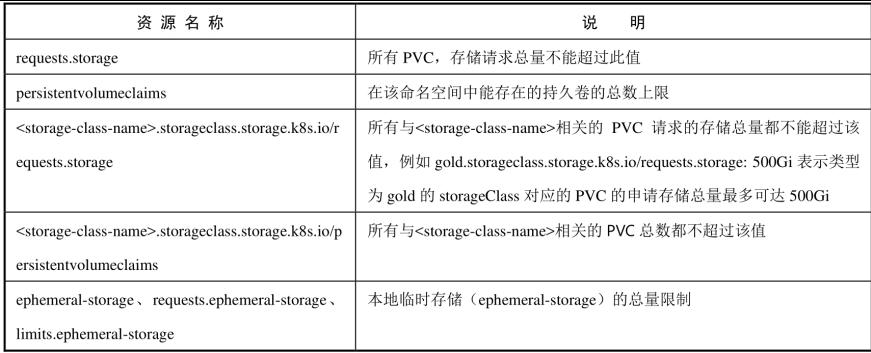
对象数量配额(Object Count Quota)
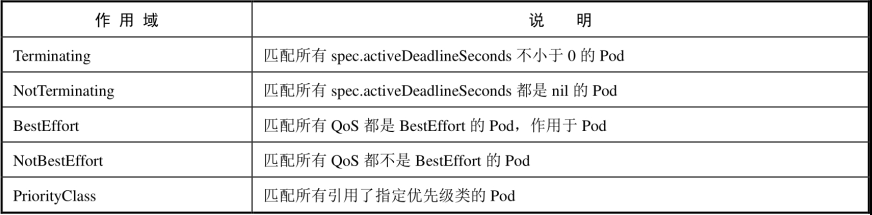
2、配额的作用域(Quota Scopes)
3、资源配额与集群资源总量的关系
资源配额与集群资源总量是完全独立的。资源配额是通过绝对的单位来配置的,这也就意味着如果在集群中新添加了节点,那么资源配额不会自动更新,而该资源配额所对应的命名空间中的对象也不能自动增加资源上限。
五)ResourceQuota和LimitRange实践
集群管理员根据集群用户的数量来调整集群配置,以达到这个目的:能控制特定命名空间中的资源使用量,最终实现集群的公平使用和成本控制
需要实现的功能如下。
- 限制运行状态的Pod的计算资源用量。
- 限制持久存储卷的数量以控制对存储的访问。
- 限制负载均衡器的数量以控制成本。
- 防止滥用网络端口这类稀缺资源
- 提供默认的计算资源Requests以便系统做出更优化的调度
六)Pod中多个容器共享进程命名空间
- 进程信息在多个容器间相互可见,这包括/proc目录下的所有信息,其中可能有包含密码类敏感信息的环境变量,只能通过UNIX文件权限进行访问控制,需要设置容器内的运行用户或组。
- 一个容器的文件系统存在于/proc/$pid/root目录下,所以不同的容器也能访问其他容器的文件系统的内容,这对于debug查错来说非常有用,但也意味着没有容器级别的安全隔离,只能通过UNIX文件权限进行访问控制,需要设置容器内的运行用户或组。
七)PID资源管理
PID(进程ID)在Linux系统中是最重要的一种基础资源,操作系统会设置一台主机可以运行的最大进程数上限。
为了使用Node级别的PID资源管理,我们首先需要在kubelet服务的启动参数中开启SupportNodePidsLimit特性开关(--feature-gates=SupportNodePidsLimit=true),开启该特性之后,系统会自动为守护进程预留一些PID资源,也会用于kubelet后续判断是否需要驱逐Pod的计算逻辑中
八)节点的CPU管理策略
CPU管理策略通过Node上的kubelet启动参数--cpu-manager-policy进行指定,目前支持两种策略。
- None策略
None策略使用默认的CPU亲和性方案,即操作系统默认的CPU调度策略。对于QoS级别为Guaranteed的Pod,会强制使用CFS Quota机制对CPU资源进行限制。
- Static策略
Static策略针对具有特定CPU资源需求的Pod。对于QoS级别为Guaranteed的Pod,如果其Container设置的CPU Request为大于等于1的整数,Kubernetes就能允许容器绑定节点上的一个或多个CPU核独占运行。这种独占是使用cpuset cgroup控制器来实现的。
六、资源紧缺时的Pod驱逐机制
Kubernetes设计和实现了一套自动化的Pod驱逐机制,该机制会自动从资源紧张的节点上驱逐一定数量的Pod,以保证在该节点上有充足的资源
一)驱逐时机
1、在磁盘资源不足时会触发Pod的驱逐行为
Kubernetes包括两种文件系统:nodefs和imagefs。
- nodefs是kubelet用于存储卷系统、服务程序日志等的文件系统;
- imagefs是容器运行时使用的可选文件系统,用于存储容器镜像和容器可写层数据。
cAdvisor提供了这两种文件系统的相关统计指标
- available:表示该文件系统中可用的磁盘空间。
- inodesFree:表示该文件系统中可用的inode数量(索引节点数量)
默认情况下,kubelet检测到下面的任意条件满足时,就会触发Pod的驱逐行为。
- nodefs.available<10%。
- nodefs.inodesFree<5%。
- imagefs.available<15%。
- imagefs.available<15%。
2、当节点的内存不足时也会触发Pod的驱逐行为
memory.available代表当前节点的可用内存
默认情况下,memory.available<100Mi时会触发Pod的驱逐行为。
驱逐Pod的过程:
- kubelet从cAdvisor中定期获取相关的资源使用量指标数据,通过配置的阈值筛选出满足驱逐条件的Pod;
- kubelet对这些Pod进行排序,每次都选择一个Pod进行驱逐。
3、kubelet在驱逐Pod的过程中不会参考Pod的QoS等级
从Kubernetes 1.9版本开始,kubelet在驱逐Pod的过程中不会参考Pod的QoS等级,只根据Pod的nodefs使用量进行排序,并选择使用量最多的Pod进行驱逐。所以即使是QoS等级为Guaranteed的Pod,在这个阶段也有可能被驱逐(例如nodefs使用量最大)
二)驱逐阈值
kubelet可以定义驱逐阈值,一旦超出阈值,就会触发kubelet的资源回收行为
驱逐软阈值由一个驱逐阈值和一个管理员设定的宽限期共同定义。当系统资源消耗达到软阈值时,在这一状况的持续时间达到宽限期之前,kubelet不会触发驱逐动作。如果没有定义宽限期,则kubelet会拒绝启动。
软阈值的定义包括以下几个参数。
- --eviction-soft:描述驱逐阈值(例如memory.available<1.5GiB),如果满足这一条件的持续时间超过宽限期,就会触发对Pod的驱逐动作。
- --eviction-soft-grace-period:驱逐宽限期(例如memory.available=1m30s),用于定义达到软阈值之后持续时间超过多久才进行驱逐。
- --eviction-max-pod-grace-period:在达到软阈值后,终止Pod的最大宽限时间(单位为s)。
硬阈值没有宽限期,如果达到了硬阈值,则kubelet会立即“杀掉”Pod并进行资源回收
硬阈值的定义包括参数--eviction-hard:驱逐硬阈值,一旦达到阈值,就会触发对Pod的驱逐操作。
三)回收Node级别的资源
kubelet在驱逐用户Pod之前,会尝试回收Node级别的资源。在观测到磁盘压力时,基于服务器是否为容器运行时定义了独立的imagefs,会有不同的资源回收过程。
1、有Imagefs时
- 如果nodefs文件系统达到了驱逐阈值,则kubelet会删掉已停掉的Pod和容器来清理空间。
- 如果imagefs文件系统达到了驱逐阈值,则kubelet会删掉所有无用的镜像来清理空间。
2、没有Imagefs时
如果nodefs文件系统达到了驱逐阈值,则kubelet会这样清理空间:首先删除已停掉的Pod、容器;然后删除所有无用的镜像。
四)驱逐用户的Pod
kubelet如果无法在节点上回收足够的资源,就会开始驱逐用户的Pod。
1、kubelet会按照下面的标准对Pod的驱逐行为进行判断。
- Pod要求的服务质量。
- Pod对紧缺资源的消耗量(相对于资源请求Request)。
2、kubelet会按照下面的顺序驱逐Pod。
- BestEffort:紧缺资源消耗最多的Pod最先被驱逐。
- Burstable:根据相对请求来判断,紧缺资源消耗最多的Pod最先被驱逐,如果没有Pod超出它们的请求,则策略会瞄准紧缺资源消耗量最大的Pod。
- Guaranteed:根据相对请求来判断,紧缺资源消耗最多的Pod最先被驱逐,如果没有Pod超出它们的请求,则策略会瞄准紧缺资源消耗量最大的Pod
针对有Imagefs和没有Imagefs的两种情况,说明kubelet在驱逐Pod时选择Pod的排序算法,然后按顺序对Pod进行驱逐
3、有Imagefs的情况
- 如果nodefs触发了驱逐,则kubelet会根据nodefs的使用情况(以Pod中所有容器的本地卷和日志所占的空间进行计算)对Pod进行排序。
- 如果imagefs触发了驱逐,则kubelet会根据Pod中所有容器消耗的可写入层的使用空间进行排序。
4、没有Imagefs的情况
如果nodefs触发了驱逐,则kubelet会对各个Pod中所有容器的总体磁盘消耗(以本地卷+日志+所有容器的写入层所占的空间进行计算)进行排序
五)资源最少回收量
配置的效果如下:
- 当memory.available超过阈值并触发了驱逐操作时,kubelet会启动资源回收,并保证memory.available至少有500MiB。
- 当nodefs.available超过阈值并触发了驱逐操作时,kubelet会恢复nodefs.available到至少1.5GiB。
- 当imagefs.available超过阈值并触发了驱逐操作时,kubelet会保证imagefs.available恢复到至少102GiB。
在默认情况下,所有资源的eviction-minimum-reclaim都为0。
七、Pod Disruption Budget(主动驱逐保护)
一)目前主要针对以下两种场景
- 节点维护或升级时(kubectl drain)。
- 对应用的自动缩容操作(autoscaling down)。
作为对比,由于节点不可用(Not Ready)导致的Pod驱逐就不能被称为主动了,但是Pod的主动驱逐行为可能导致某个服务对应的Pod实例全部或大部分被“消灭”,从而引发业务中断或业务SLA降级,而这是违背Kubernetes的设计初衷的
二)下面这些场景,PodDisruptionBudget机制完全无效
- 后端节点物理机的硬件发生故障。
- 集群管理员错误地删除虚拟机(实例)。
- 云提供商或管理程序发生故障,使虚拟机消失。
- 内核恐慌(kernel panic)。
- 节点由于集群网络分区而从集群中消失。
- 由于节点资源不足而将容器逐出。
- dDisruptionBudget的定义包括如下几个关键参数。
- Label Selector:用于筛选被管理的Pod。
- minAvailable:指定驱逐过程中需要保障的最少Pod数量。minAvailable可以是一个数字,也可以是一个百分比,例如100%就表示不允许进行主动驱逐。
- maxUnavailable:要保证最大不可用的Pod数量或者比例。
- minAvailable和maxUnavailable不能被同时定义。
八、kubernetes集群监控
在Kubernetes新的监控体系中,Metrics Server用于提供核心指标(Core Metrics),包括Node、Pod的CPU和内存使用指标。对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成
1、使用Metrics Server监控Node和Pod的CPU和内存使用数据
Metrics Server提供的数据既可以用于基于CPU和内存的自动水平扩缩容(HPA)功能,也可以用于自动垂直扩缩容(VPA)功能
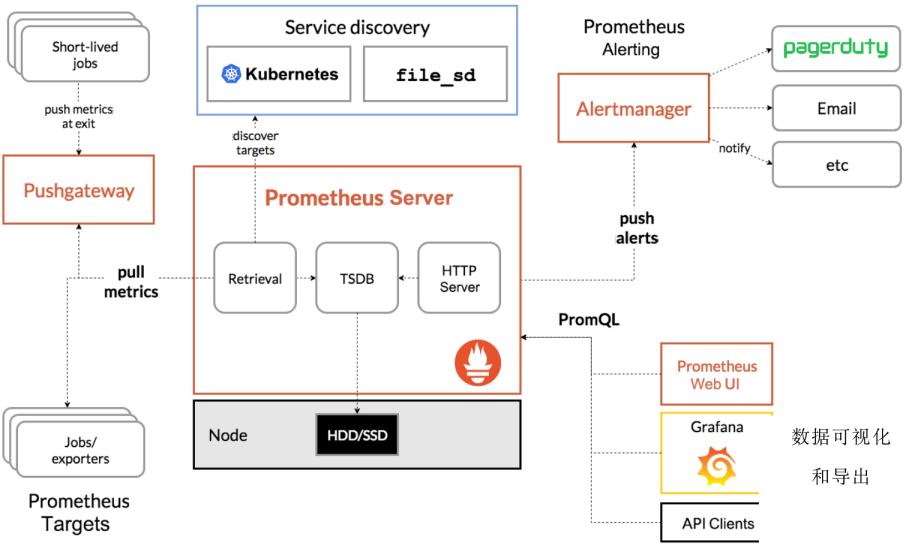
2、Prometheus+Grafana集群性能监控平台搭建
九、kubernetes集群日志管理
容器具有不稳定性,在发生故障时可能被Kubernetes重新调度,Node也可能由于故障无法使用,造成日志丢失,这就要求管理员对容器和系统组件生成的日志进行统一规划和管理
一)容器应用和系统组件输出日志的各种场景
1、容器应用输出日志的场景
容器应用可以选择将日志输出到不同的目标位置:
- 输出到标准输出和标准错误输出;
- 输出到某个日志文件;
- 输出到某个外部系统。
需要将日志持久化存储时,容器可以选择使用Kubernetes提供的某种存储卷(Volume),例如hostpath(保存在Node上)、nfs(保存在NFS服务器上)、PVC(保存在某种网络共享存储上)。保存在共享存储卷中的日志要求容器应用确保文件名或子目录名称不冲突。
某些容器应用也可能将日志直接输出到某个外部系统中,例如通过一个消息队列(如Kafka)转发到一个后端日志存储中心。在这种情况下,外部系统的搭建方式和应用程序如何将日志输出到外部系统,应由容器应用程序的运维人员负责,不应由Kubernetes负责
2、系统组件输入日志的场景
Kubernetes从1.19版本开始,开始引入对结构化日志的支持,使日志格式统一,便于日志中字段的提取、保存和后续处理。结构化日志以JSON格式保存。
目前kube-apiserver、kube-controller-manager、kube-scheduler和kubelet这4个服务都支持通过启动参数--logging-format=json设置JSON格式的日志,需要注意的是,JSON格式的日志在启用systemd的系统中将被保存到journald中,在未使用systemd的系统中将在/var/log目录下生成*.log文件,不能再通过--log-dir参数指定保存目录
3、审计日志
(1)对于输出到主机(Node)上的日志,管理员可以考虑在每个Node上都启动一个日志采集工具,将日志采集后汇总到统一日志中心,以供日志查询和分析,具体做法如下。
- 对于容器输出到stdout和stderr的日志:管理员应该配置容器引擎(例如Docker)对日志的轮转(rotate)策略,以免文件无限增长,将主机磁盘空间耗尽。
- 对于系统组件输出到主机目录上(如/var/log)的日志,管理员应该配置各系统组件日志的轮转(rotate)策略,以免文件无限增长等将主机磁盘空间耗尽。
- 对于容器应用使用hostpath输出到Node上的日志:管理员应合理分配主机目录,在满足容器应用存储空间需求的同时,可以考虑使用采集工具将日志采集并汇总到统一的日志中心,并定时清理Node的磁盘空间。
(2)对于输出到容器内的日志,容器应用可以将日志直接输出到容器环境内的某个目录下,这可以减轻应用程序在共享存储中管理不同文件名或子目录的复杂度。在这种情况下,管理员可以为应用容器提供一个日志采集的sidecar容器,对容器的日志进行采集,并将其汇总到某个日志中心,供业务运维人员查询和分析
二)Fluentd+Elasticsearch+Kibana日志系统部署
三)部署日志采集sidecar工具采集容器日志
以为业务应用容器配置一个日志采集sidecar容器,对业务容器生成的日志进行采集并汇总到某个日志中心,供业务运维人员查询和分析,这通常用于业务日志的采集和汇总。
日志采集sidecar工具也有多种选择,常见的开源软件包括Fluentd、Filebeat、Flume等,在下例中使用Fluentd进行说明
十、kubernetes审计机制
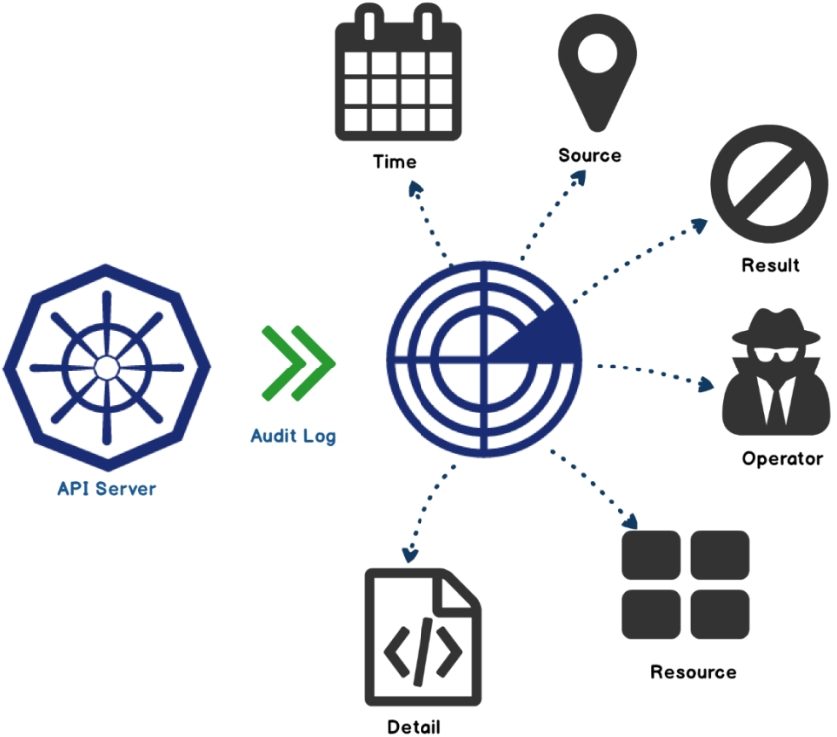
Kubernetes为了加强对集群操作的安全监管,从1.4版本开始引入审计机制,主要体现为审计日志(Audit Log)。
审计日志按照时间顺序记录了与安全相关的各种事件,这些事件有助于系统管理员快速、集中了解发生了什么事情、作用于什么对象、在什么时间发生、谁(从哪儿)触发的、在哪儿观察到的、活动的后续处理行为是怎样的
从Kubernets 1.8版本开始,该参数--feature-gates=AdvancedAuditing为true可以自定义审计策略(选择记录哪些事件)和审计后端存储(日志和Webhook)等
对于审计日志的采集和存储,一种常见做法是,将审计日志以本地日志文件方式保存,然后使用日志采集工具(例如Fluentd)采集该日志并存储到Elasticsearch中,用Kibana等UI界面对其进行展示和查询。另一种常见做法是用Logstash采集Webhook后端的审计事件,通过Logstash将来自不同用户的事件保存为文件或者将数据发送到后端存储(例如Elasticsearch)。
十一、使用Web UI(dashboard)管理集群
一)Kubernetes Dashboard
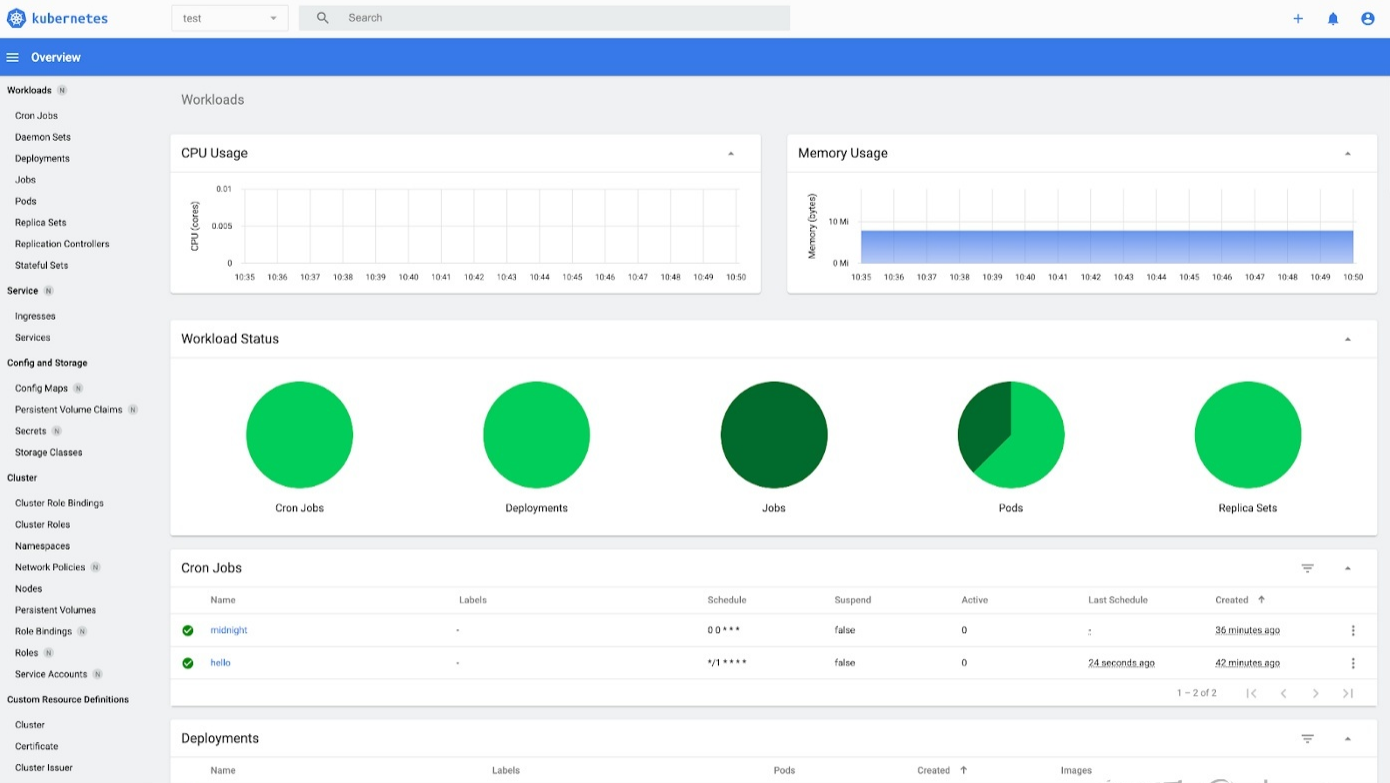
Web UI 仪表板概述了在远程 Kubernetes 集群上运行的容器化应用程序,以及管理主要 Kubernetes 资源(如部署、服务、作业等)的能力
部署在 Kubernetes 集群中,它提供了操作员可以期望的所有功能:
集中式 UI 以团队形式管理 Kubernetes。简单的用户界面来管理任何资源。对容器日志访问、指标、SSH 连接等功能进行故障排除。
有关该项目的更多信息,请参阅这些外部链接: Github 存储库 https://github.com/kubernetes/dashboard
项目网站 https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
二)Lens
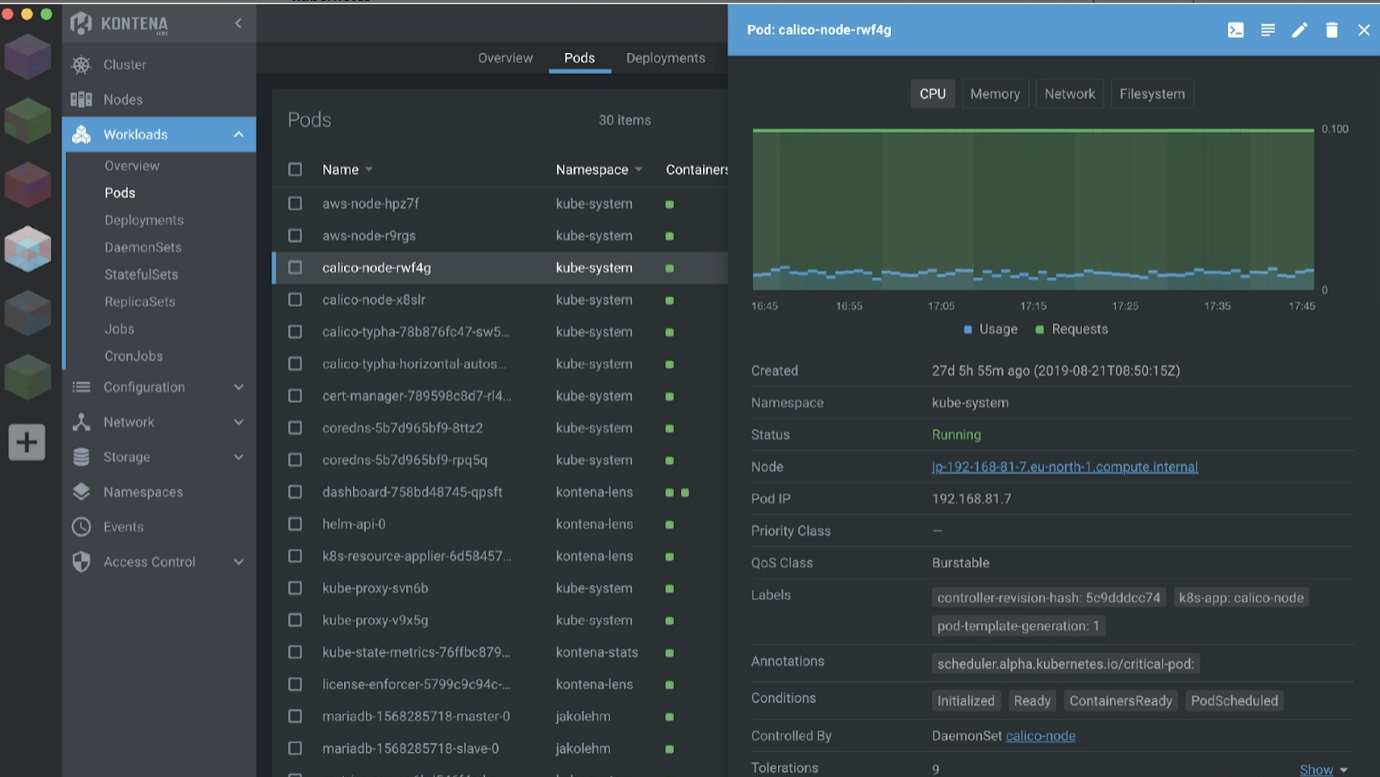
Lens是一个基于 Electron 的应用程序(支持 Windows、macOS、Linux)。它最初由 Kontena 开发,并在 Mirantis 收购后作为开源项目发布。
在某种程度上,Lens 与 kube-dashboard 截然相反。它是一个可以替代 Kubectl 的客户端应用程序。
它提供与 Kubernetes Dashboard 项目相同的功能,以及其他有用的功能,例如:
自定义资源定义 (CRD) 管理,现在有几个项目正在将它们作为插件与Lens集成,以快速访问所有信息,而无需任何 Kubeclt 命令。
Helm 集成可轻松管理部署的任何 Helm 版本。Kustomize 资源和集成概述。可以替换 Kubectl,因为 Lens 能够处理集群设置并运行任何 Kubectl 命令。
这个项目可能是当今运行 Kubernetes 项目最强大的 GUI,但它需要管理特定的身份验证/授权,因为它不是一个集中的工具。
Github 存储库 https://github.com/lensapp/lens
项目网站 https://k8slens.dev/
Lens扩展 https://github.com/lensapp/lens-extensions
三)Rancher
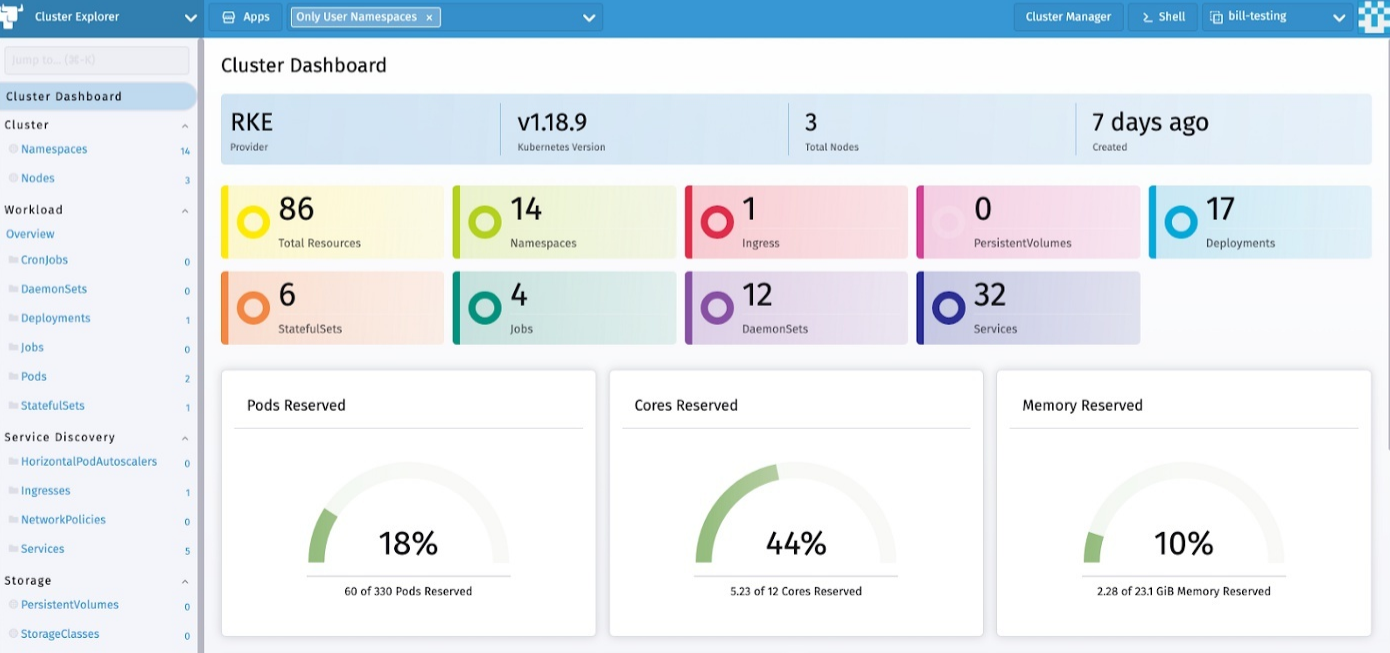
Rancher 是完整的企业计算平台,可在本地、云端或边缘运行 Kubernetes 集群。所以是的,Rancher 并不是真正的 Kubernetes 仪表板,但它具有相同的功能,管理一些 Kubernetes 资源的生命周期,它可以收集容器化应用程序的日志和指标等……
与其他项目一样,Rancher 可以连接到现有集群,但也可以创建新集群。这就是为什么 Rancher 可能不在这个范围内,因为它可以管理整个集群的生命周期,而不仅仅是资源。 但是 Rancher 仍然有一个仪表板 UI,可以轻松访问任何 Kubernetes 集群并快速获得见解。
集成与其他集成不同,因为它需要在远程集群上部署代理或云集成来管理 Kubernetes。Rancher 可以是任何具有强大身份验证机制(如企业 LDAP)的团队的集中端点管理。
有关该项目的更多信息,请参阅这些外部链接:
Github 存储库 https://github.com/rancher/rancher
项目网站 https://rancher.com/
四)Kuboard
http://press.demo.kuboard.cn/overview/
1、简述kuboard
经过可视化管理后台, 管理 Kubernetes 会更方便. 除了官方的Dashboard以外, 还有许多其余第三方开源的管理后. 其中 Kuboard 是一款比较优秀的国内开源管理后台, 相比于 Kubernetes Dashboard:html
- 无需手工编写 YAML 文件
- 微服务参考架构
- 上下文相关的监控
-
场景化的设计git
- 导出配置
- 导入配置
另外 Kuboard 还支持:github
- GitLab/GitHub 单点登陆集成
- RBAC 权限管理
- 工做负载编辑器
- 名称空间导出/导入
2、前提条件
安装 Kuboard 时, 咱们已经有一个 Kubernetes 集群. 如下任何形式安装的集群均可以:浏览器
- kubeadm 安装(或者基于 kubeadm 的衍生工具, 如 Sealos等);
- 二进制安装;
- 阿里云、腾讯云等公有云托管集群;
- 其余。
3、安装
经过如下命令:bash
kubectl apply -f [https://kuboard.cn/install-script/kuboard.yaml](https://kuboard.cn/install-script/kuboard.yaml)
kubectl apply -f [https://addons.kuboard.cn/metrics-server/0.3.7/metrics-server.yaml](https://addons.kuboard.cn/metrics-server/0.3.7/metrics-server.yaml)
kubectl get pods -l http://k8s.kuboard.cn/name=kuboard -n kube-system查看 Kuboard 运行状态:架构
$ kubectl get pods -l k8s.kuboard.cn/name=kuboard -n kube-system NAME READY STATUS RESTARTS AGE kuboard-7bb89b4cc4-p5l2p 1/1 Running 0 179m
若是为Running, 表示已成功启动. 不然使用kubectl describe查看失败缘由. app
4、访问
获取tocken
echo $(kubectl -n kube-system get secret $(kubectl -n kube-system get secret | grep kuboard-user | awk '{print $1}') -o go-template='{{.data.token}}' | base64 -d)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2017-09-05 Python基础学习——概述、基本数据类型、流程控制